1.file
a.打开文件方式(读写两种方式)
Python内置的open()函数打开一个文件,创建一个file对象,然后调用相关的方法才可以它进行读写。
格式: file object = open(file_name [, access_mode][, buffering])各个参数的细节如下:
- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
读和写的区别在于access_mode的不同,总共有下面几种常用的:
t 文本模式 (默认)。 b 二进制模式。 + 打开一个文件进行更新(可读可写)。 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 r+ 打开一个文件用于读写。文件指针将会放在文件的开头。 rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
b.文件对象的操作方法
file对象相关的所有属性:
属性 描述 file.closed 返回true如果文件已被关闭,否则返回false。用 close()方法关闭文件是一个很好的习惯。 file.mode 返回被打开文件的访问模式。 file.name 返回文件的名称。 file.softspace 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 write()方法
write()方法可将任何字符串写入一个打开的文件,并且不会在字符串的结尾添加换行符('n') read()方法
read()方法从一个打开的文件中读取一个字符串。
c.学习对excel及csv文件进行操作
2.os模块
Python os模块包含普遍的操作系统功能
1 #这里列举在os模块中关于文件/目录常用的函数使用方法 2 3 #这里需要注意下,在使用这些方法前记得导入os模块 4 import os #导入os模块 5 """ 6 os对象方法: 7 os.getcwd() #返回当前工作目录 8 os.chdir(path) #改变工作目录 9 os.listdir(path=".") #列举指定目录中的文件名("."表示当前目录,“..”表示上一级目录) 10 os.mkdir(path) #创建建单层目录,如果该目录已存在则抛出异常 11 os.makedirs(path) #递归创建多层目录,如该目录已存在抛出异常, 12 os.remove(path) #删除文件 13 os.rmdir(path) #删除单层目录,如该目录非空则抛出异常 14 os.removedirs(path) #递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常 15 os.rename(old,new) #将文件old重命名为new 16 os.system(command) #运行系统shell命令 17 os.walk(top) #遍历top路径以下所有子目录,返回一个三元组:(路径,[包含目录],[包含文件]) 18 os.curdir #属性,表示当前目录 19 os.pardir #属性,表示上一级目录 20 os.sep #属性,输出操作系统特定的路径分隔符(win下为'\',Linux下为'/') 21 os.linesep #属性,当前平台使用的行终止符(Win下为‘rn’,Linux下为'n') 22 os.name #属性,指待当前使用的操作系统 23 24 os.path对象方法: 25 os.path.basename(path) #去掉目录路径,单独返回文件名 26 os.path.dirname(path) #去掉文件名,单独返回目录路径 27 os.path.join(path1[,],path2[,...]) #将path1,path2各部分组成一个路径名 28 os.path.split(path) #分割文件名和路径,返回一个(f_path,f_name)元组,如果完全使用目录,它也会将最后一个目录作为文件名分离 29 os.path.splitext(path) #分离文件名和后缀名,返回(f_name,f_extension)元组,如果完全使用目录,它也会将最后一个目录作为文件名分离 30 os.path.getsize(file) #返回指定文件的尺寸,单位是字节 31 os.path.getatime(file) #返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) 32 os.path.getctime(file) #返回指定文件的创建时间 33 os.path.getmtime(file) #返回指定文件最新的修改时间 34 os.path.exists(path) #判断指定路径是否存在(目录或者文件) 35 os.path.isabs(path) #判断是否为绝对路径 36 os.path.isdir(path) #判断指定路径是否存在且是一个目录 37 os.path.isfile(path) #判断指定路径是否存在且是一个文件 38 os.path.islink(path) #判断指定路径是否存在且是一个符号链接 39 os.path.ismount(path) #判断指定路径是否存在且是一个挂载点 40 os.path.samefile(path1,path2) #判断path1,path2是否指向同一个文件 41 42 """
3.datetime模块
datetime模块的对象有如下:
- timedelta
- date
- datetime
- time
- tzinfo
还包含以下两个常量:
- datetime.MINYEAR (它返回的是1)
- datetime.MAXYEAR(它返回的是9999)
datetime对象
构造方法: class datetime.datetime(year, month, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]])
year, month 和 day 参数是必须的,其他参数可选, 参数tzinfo表示可选的时区信息,一般我们也用不到。
from datetime import datetime as dt t=dt(2017,6,1,hour=13,minute=17,second=30) print(type(t)) print(t) 输出: <type 'datetime.datetime'> 2017-06-01 13:17:30 如果我们只传参数year, month, day,那么时间会默认变成00:00:00datetime对象的几个方法:
- datetime.today() 返回本地当前的时间
- datetime.now([tz]) 返回本地当前的日期和时间。如果可选的参数 tz 为 None 或者没有指定,就如同today()
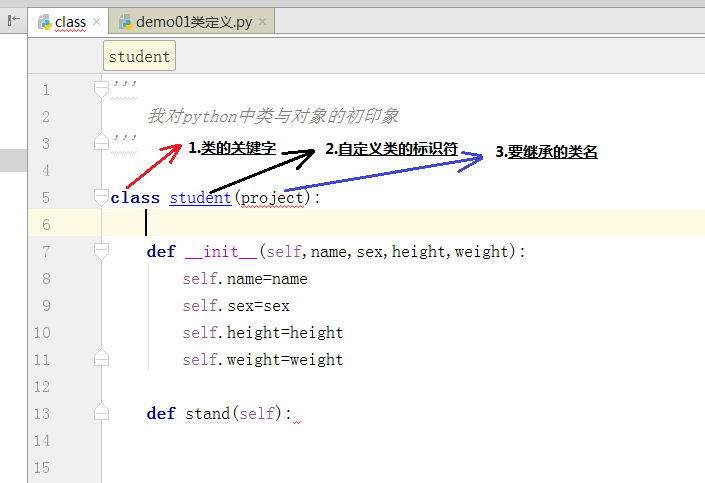
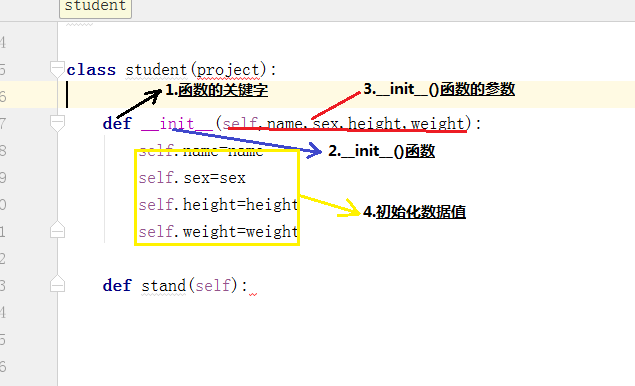
4.类和对象
类:
定义类是通过
class关键字:
二:类中对象初始化:
对象:
对象(实类)是根据类创建出来的一个个具体的“实类”,每个对象都拥有相同的方法,但各自的数据可能不同(初始化不同)。
5.正则表达式
正则表达式定义: 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
python正则表达式: re模块使python语言拥有全部的正则表达式功能。为什么使用正则表达式?
通过使用正则表达式,可以:
(1)测试字符串内的模式。例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。
(2)替换文本。可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。
(3)基于模式匹配从字符串中提取子字符串。可以查找文档内或输入域内特定的文本。使用步骤:
(1)使用compile()函数将正则表达式的字符串编译成一个pattern对象
(2)通过pattern对象的一些方法对文本进行匹配,匹配结果是一个match对象
(3)用match对象的方法,对结果进行操作正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
(1)字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
(2)多数字母和数字前加一个反斜杠时会拥有不同的含义。
(3)标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
(4)反斜杠本身需要使用反斜杠转义。
(5)由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r’t’,等价于 ‘t’)匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。5.贪婪与非贪婪模式
模式 描述 ^ 匹配字符串的开头 $ 匹配字符串的末尾 . 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符 […] 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ [^…] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符 re* 匹配0个或多个的表达式 re+ 匹配1个或多个的表达式 re? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 re{ n} 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 “Bob” 中的 “o”,但是能匹配 “food” 中的两个 o。 re{ n,} 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。“o{1,}” 等价于 “o+”。“o{0,}” 则等价于 “o*”。 re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 (re) 匹配括号内的表达式,也表示一个组 (?imx) 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域 (?-imx) 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域 (?: re) 类似 (…), 但是不表示一个组 (?imx: re) 在括号中使用i, m, 或 x 可选标志 (?-imx: re) 在括号中不使用i, m, 或 x 可选标志 (?#…) 注释. (?= re) 前向肯定界定符 (?! re) 前向否定界定符 (?> re) 匹配的独立模式,省去回溯 w 匹配字母数字及下划线 W 匹配非字母数字及下划线 s 匹配任意空白字符,等价于 [tnrf] S 匹配任意非空字符 d 匹配任意数字,等价于 [0-9] D 匹配任意非数字 A 匹配字符串开始 Z 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 z 匹配字符串结束 G 匹配最后匹配完成的位置 b 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘erb’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 B 匹配非单词边界。‘erB’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 n, t, 等. 匹配一个换行符。匹配一个制表符。等 1…9 匹配第n个分组的内容 10 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式
(1)贪婪模式:在整个表达式匹配成功的前提下, 尽可能多的匹配
(2)非贪婪模式:在整个表达式匹配成功的前提下, 尽可能少的匹配( 多加个?)
(3)python里面数量词默认是 贪婪模式
6.re模块
结合上面的正则表达式: re模块使python语言拥有全部的正则表达式功能。
re模块常用的方法:
(1)re.match: 从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:re.match(pattern, string, flags=0)
函数参数说明:pattern:匹配的正则表达;string:要匹配的字符串;flags:标志位,用于控制正则表达式的匹配方式我们可以使用
group(num)或groups()匹配对象函数来获取匹配表达式。
匹配对象方法 描述 group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 实例代码:
##正则化 import re print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配 print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配结果为:
(0, 3) None(2)re.search:从任何位置开始查找,返回第一个成功的匹配。匹配成功re.search方法返回一个匹配的对象,否则返回None。
函数语法:re.search(pattern, string, flags=0)
函数参数说明:pattern:匹配的正则表达;string:要匹配的字符串;flags:标志位,用于控制正则表达式的匹配方式实例代码:
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配 print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配结果为:
(0, 3) (11, 14)re.match与re.search的区别: re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配 整个字符串 ,直到找到一个匹配。
(3)re.sub: Python 的 re 模块提供了re.sub用于替换字符串中的匹配项
函数语法:re.sub(pattern, repl, string, count=0, flags=0)
函数参数说明:pattern:正则中的模式字符串;repl:替换的字符串,也可为一个函数;string:要被查找替换的原始字符串;count:模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。实例代码:
##re.sub用于替换字符串中的匹配项。 import re phone = "2004-959-559 # 这是一个国外电话号码" # 删除字符串中的 Python注释 num = re.sub(r'#.*$', "", phone) print("电话号码是: ", num) # 删除非数字(-)的字符串 num = re.sub(r'D', "", phone) print("电话号码是 : ", num)结果为:
电话号码是: 2004-959-559 电话号码是 : 2004959559(4)re.compile 函数: compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
函数语法:re.compile(pattern[, flags])
函数参数说明:pattern:一个字符串形式的正则表达式;flags:可选,表示匹配模式,比如忽略大小写,多行模式等。(5)re.findall函数: 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次, findall 匹配所有。
函数语法:findall(string[, pos[, endpos]])
函数参数说明:string:待匹配的字符串;pos:可选参数,指定字符串的起始位置,默认为 0;endpos:可选参数,指定字符串的结束位置,默认为字符串的长度。实例代码:
## findall 匹配所有 pattern = re.compile(r'd+') # 查找数字 result1 = pattern.findall('runoob 123 google 456') result2 = pattern.findall('run88oob123google456', 0, 10) print(result1) print(result2)结果为:
['123', '456'] ['88', '12'](6)re.finditer函数: 和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
函数语法:re.finditer(pattern, string, flags=0)
函数参数说明:pattern:匹配的正则表达式;string:要匹配的字符串;flags:标志位,用于控制正则表达式的匹配方式。实例代码:
import re it = re.finditer(r"d+","12a32bc43jf3") for match in it: print (match.group() )输出结果:
12 32 43 3(7)re.split函数: split 方法按照能够匹配的子串将字符串分割后返回列表
函数语法:re.split(pattern, string[, maxsplit=0, flags=0])
函数参数说明:pattern:匹配的正则表达式;string:要匹配的字符串;maxsplit:分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数;flags:标志位,用于控制正则表达式的匹配方式。代码实例:
##split分割 a = re.split('W+', 'runoob, runoob, runoob.')##W 匹配非字母数字及下划线 print(a)输出结果:
['runoob', 'runoob', 'runoob', '']
7.http请求
HTTP和HTTPS分别是什么?
HTTP协议(超文本传输协议): 是一种发布和接收HTML页面的方法,其设计目的是保证客户机与服务器之间的通信,是客户机与服务器之间的请求-应答协议。
HTTPS: 简单讲就是HTTP的安全版,在HTTP下加入SSL层。
HTTP 的常用两种请求方法:get 和 post
get - 用于从服务器上获取数据;get产生一个TCP数据包;对于get方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
post - 用于向服务器传送数据;post产生两个TCP数据包;对于post,浏览器先发送header,服务器响应100(continue),然后再发送data,服务器响应200(返回数据)。
http申请状态码:
状态代码由三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。
5xx:服务器端错误–服务器未能实现合法的请求。常见状态代码、状态描述的说明如下。
200 OK:客户端请求成功。
400 Bad Request:客户端请求有语法错误,不能被服务器所理解。
401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用。
403 Forbidden:服务器收到请求,但是拒绝提供服务。
404 Not Found:请求资源不存在,举个例子:输入了错误的URL。
500 Internal Server Error:服务器发生不可预期的错误。
503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常。
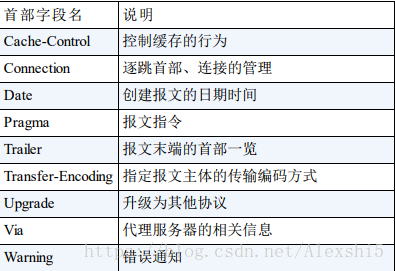
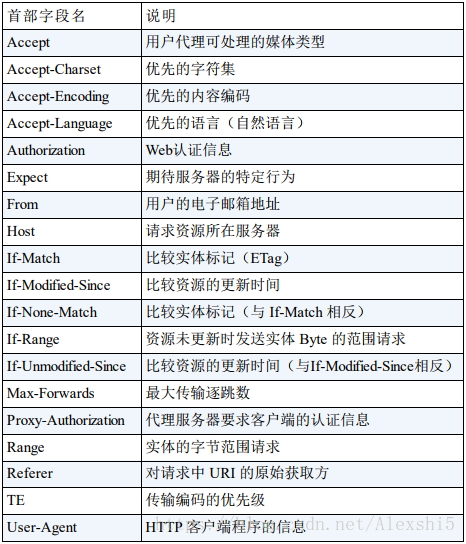
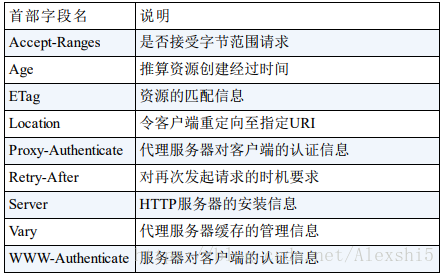
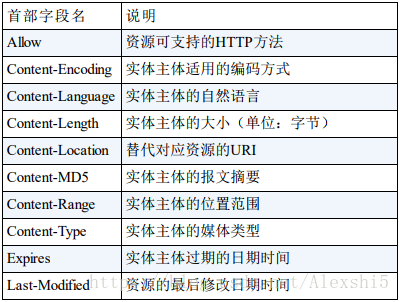
HTTP首部字段
通用首部字段
请求首部字段
响应首部字段
实体首部字段
来源于博客:图解HTTP(六)—— HTTP请求头(首部)
最后
以上就是大胆钢铁侠最近收集整理的关于python基础打卡 第五次1.file的全部内容,更多相关python基础打卡内容请搜索靠谱客的其他文章。








发表评论 取消回复