目录
- 0. nltk的分类器介绍
- 0.1分类器示例
- 0.2 基于上下文的词性标注器
- 1.信息抽取
- 2.分块
- 2.1关于命名实体识别
- 2.2 基于正则的匹配
- 2.3 处理递归
- 2.4基于分类的分块器
- 2.5 命名实体识别
- 2.6 关系抽取
参考链接1
参考链接2
0. nltk的分类器介绍
在NLTK中提供了NaiveBayesClassifier,DecisionTreeClassifier,MaxentClassifier三种类型的分类器。分类器都提供了类方法可以训练出一个分类器实例,有了这个实例,便能对新的样本进行分类预测,以及其进行准确度评测。
| 方法 | 说明 |
|---|---|
| train(train_set) | 类方法,用于生成一个分类器实例 |
| classify(feature) | 实例方法,基于训练的模型对输入特征进行分类 |
| show_most_informative_features() | 实例方法,显示训练过程中最有效的特性统计 |
nltk.classify包的工具类提供了下列的方法辅助训练及优化过程
| 方法 | 说明 |
|---|---|
| accuracy(classifier,test_set) | 评估分类器在测试集上的准确度 |
| apply_feature(func,data) | 将特征函数func应用到data上,类似于map操作 |
0.1分类器示例
下面基于nltk的movie_reviews语料库的正负向标注数据训练一个简单的分类器,用来预测评论的正负向。PS:语料库文本被分两类,pos与neg。
代码先统计出最常用2000个词,简单假设这些词的使用情况可以决定一篇评论的正负向情感。针对每篇文档,特征提取器计算其在这2000个词上出现的情况,若出现则在特性中标记为True,否则标记为False。
import random
import nltk
from nltk.corpus import movie_reviews
docs = [(list(movie_reviews.words(fileid)),category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(docs)
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
most_common_word = [word for (word,_) in all_words.most_common(2000)]
def doc_feature(doc):
doc_words = set(doc)
feature = {}
for word in most_common_word:
feature[word] = (word in doc_words)
return feature
train_set = nltk.apply_features(doc_feature,docs[:100])
test_set = nltk.apply_features(doc_feature,docs[100:])
classifier = nltk.NaiveBayesClassifier.train(train_set)
print nltk.classify.accuracy(classifier,test_set) #0.735
classifier.show_most_informative_features()
'''
Most Informative Features
hard = True neg : pos = 8.6 : 1.0
worst = True neg : pos = 7.1 : 1.0
giant = True neg : pos = 7.1 : 1.0
unlike = True pos : neg = 6.8 : 1.0
entire = True pos : neg = 5.6 : 1.0
headed = True neg : pos = 5.6 : 1.0
gun = True neg : pos = 5.6 : 1.0
attempt = True neg : pos = 5.2 : 1.0
small = True pos : neg = 5.0 : 1.0
'''
可以看到出现hard,worst,giant词的文档通常是neg的,出现entire,small词的文档通常是正向的。基于特征词的分类器在测试集上达到了73.5%的正确率。精心构造的对于当前任务透彻理解的特性,通常可以显著提高分类的正确性。
nltk.sentiment包提供了两个情感分析器的实现,使用示例见这里。
| 类名 | 说明 |
|---|---|
| SentimentAnalyzer | 实现和上面代码的思想一致,只是简单做了些封装,支持传入不同的分类器和使用串联的多个特征提取器。可以直接使用此类进行中文的情感分析。 |
| SentimentIntensityAnalyzer | 实现基于《VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text》这篇文章,思想是基于词典对词进行打分,得到了个分值来表示句子情感的极性。这个类由于规则词典的词都是英文,如果想使用它处理中文,需要自己统计提取中文极性词并打分,以替换掉英文词典。 |
0.2 基于上下文的词性标注器
在上一篇文章中,主要介绍了N-gramTagger的词性标注器的使用方法,其主要思想是基于词的词性的历史出现次数进行推测。下面介绍实现一种基于分类器的词性标注器,它借助词本身,词的上下文,标注信息的上下文等特征来训练一个词性分类器,从而实现词性标注。
import nltk
from nltk.corpus import brown
def pos_feature_use_hist(sentence,i,history):
features = {
'suffix-1': sentence[i][-1:],
'suffix-2': sentence[i][-2:],
'suffix-3': sentence[i][-3:],
'pre-word': 'START',
'prev-tag': 'START'
}
if i>0:
features['prev-word'] = sentence[i-1],
features['prev-tag'] = history[i-1]
return features
class ContextPosTagger(nltk.TaggerI):
def __init__(self,train):
train_set = []
for tagged_sent in train:
untagged_sent = nltk.tag.untag(tagged_sent)
history = []
for i,(word,tag) in enumerate(tagged_sent):
features = pos_feature_use_hist(untagged_sent,i,history)
train_set.append((features,tag))
history.append(tag)
print train_set[:10]
self.classifier = nltk.NaiveBayesClassifier.train(train_set)
def tag(self,sent):
history = []
for i,word in enumerate(sent):
features = pos_feature_use_hist(sent,i,history)
tag = self.classifier.classify(features)
history.append(tag)
return zip(sent,history)
tagged_sents = brown.tagged_sents(categories='news')
size = int(len(tagged_sents)*0.8)
train_sents,test_sents = tagged_sents[0:size],tagged_sents[size:]
#tagger = nltk.ClassifierBasedPOSTagger(train=train_sents) # 0.881
tagger = ContextPosTagger(train_sents) #0.78
tagger.classifier.show_most_informative_features()
print tagger.evaluate(test_sents)
这个简单只考虑前一个词及前一个词的词性的标注器,在测试集上有约78%的准确度,尚没有上节的组合N-gram标注器的正确率高,这主要是例子中的特征提取器考虑十分简单的缘故。nltk默认实现了一个ClassifierBasedPOSTagger类,可以实现约88%的标注准确度。
例子中实现存在的问题是一旦一个词的词定下来,那么后面就无法修改,即使是后面发现前面判断出了错。解决这个问题有两种方法:一种是采用转换策略,即Brill标注器。另一种对所有的词性标记序列打分,选择总分最高的序列。隐含马尔可夫模型即实现此方法,此外更高级的如最大熵马尔可夫模型,线性条件随机场模型。
1.信息抽取
从数据库中抽取信息是容易的,但对于从自然文本中抽取信息则不那么直观。通常信息抽取的流程如下图:
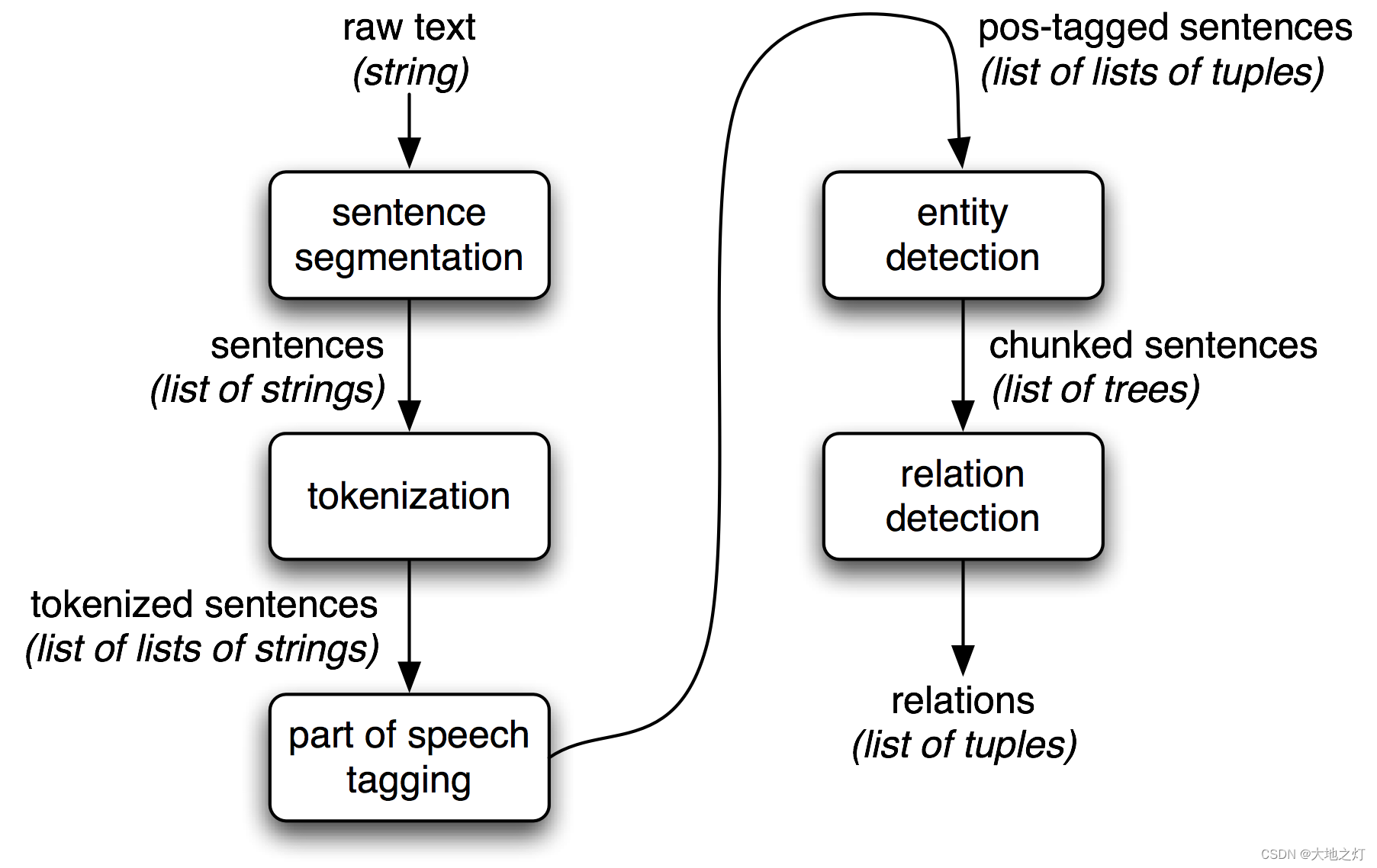
它开始于分句,分词。接下来进行词性标注,识别其中的命名实体,最后使用关系识别搜索相近实体间的可能的关系。
2.分块
分块是实体识别(NER)使用的基本技术,词性标注是分块所需的最主要信息。本节以名词短语(NP)为例,展示如何分块。类似的还可以对动词短语,介词短语等进行分块。下图展示了NP分块的概念。
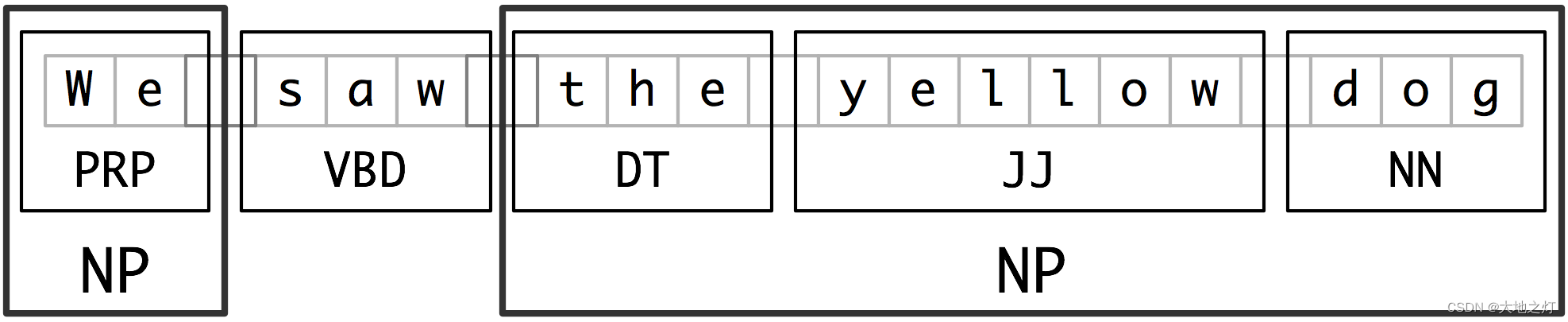
分块可以简单的基于经验,使用正则表达式来匹配,也可以使用基于统计的分类算法来实现。主节先介绍NLTK提供的正则分块器。
2.1关于命名实体识别
命名实体识别是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位。一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
通常包括两部分:(1)实体边界识别;(2) 确定实体类别(人名、地名、机构名或其他)。英语中的命名实体具有比较明显的形式标志(即实体中的每个词的第一个字母要大写),所以实体边界识别相对容易,任务的重点是确定实体的类别。和英语相比,汉语命名实体识别任务更加复杂,而且相对于实体类别标注子任务,实体边界的识别更加困难。
(1)汉语文本没有类似英文文本中空格之类的显式标示词的边界标示符,命名实体识别的第一步就是确定词的边界,即分词;(2)汉语分词和命名实体识别互相影响;(3)除了英语中定义的实体,外国人名译名和地名译名是存在于汉语中的两类特殊实体类型;(4)现代汉语文本,尤其是网络汉语文本,常出现中英文交替使用,这时汉语命名实体识别的任务还包括识别其中的英文命名实体;(5)不同的命名实体具有不同的内部特征,不可能用一个统一的模型来刻画所有的实体内部特征。
2.2 基于正则的匹配
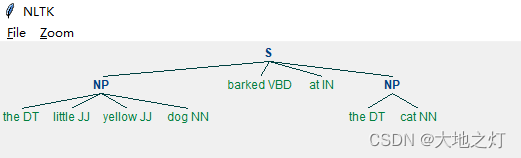
NLTK提供了一个基于词性的正则解析器RegexpParser,可以通过正则表达式匹配特定标记的词块。每条正则表达式由一系列词性标签组成,标签以尖括号为单位用来匹配一个词性对应的词。例如用于匹配句子中出现的名词,由于名词还有细分的如NNP,NNS等,可以用<NN.*>来表示所有名词的匹配。下面的代码演示了匹配上图中冠词-形容词-名词构成的短语块。
import nltk
sent = sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
grammer = 'NP:{<DT>*<JJ>*<NN>+}'
cp = nltk.RegexpParser(grammer)
tree = cp.parse(sent)
print(tree)
tree.draw()
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
2.3 处理递归
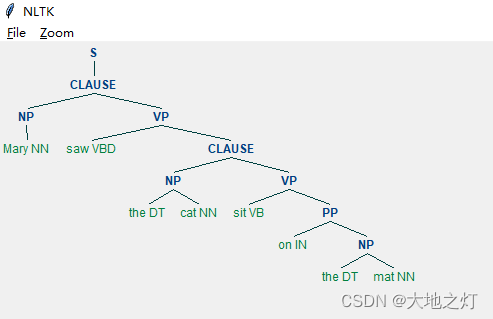
为了支持语言结构的递归,匹配规则是支持引用自身的,如下面的代码,先定义了NP的规则,而在VP和CLAUSE的定义中,互相进行了引用。
import nltk
grammar = r"""
NP: {<DT|JJ|NN.*>+}
PP: {<IN><NP>}
VP: {<VB.*><NP|PP|CLAUSE>+$}
CLAUSE: {<NP><VP>}
"""
cp = nltk.RegexpParser(grammar,loop=2)
sentence = [("Mary", "NN"), ("saw", "VBD"), ("the", "DT"), ("cat", "NN"),("sit", "VB"), ("on", "IN"), ("the", "DT"), ("mat", "NN")]
tree = cp.parse(sentence)
print(tree)
tree.draw()
(S
(CLAUSE
(NP Mary/NN)
(VP
saw/VBD
(CLAUSE
(NP the/DT cat/NN)
(VP sit/VB (PP on/IN (NP the/DT mat/NN)))))))
2.4基于分类的分块器
本节将使用nltk.corpus的conll2000语料来训练一个分块器。conll语料使用IOB格式对分块进行了标注,IOB是Inside,Outside,Begin的缩写,用来描述一个词与块的关系,下图是一个示例。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HHfDOuBY-1651665292746)(attachment:206f1ef59b4a0b52c00249c708ac2cd4_chunk-tagrep.png)]
语料库中有两个文件:train.txt,test.txt。另外语料库提供了NP,VP和PP的块标注类型。下表对此语料类的方法进行解释:
| 方法 | 作用 |
|---|---|
| tagged_sents(fileid) | 返回词性标注的句子列表,列表元素(word,pos_tag) |
| chunked_sents(fileid,chunk_types) | 返回IOB标记的语树tree,树的节点元素(word,pos_tag,iob_tag) |
下表对nltk.chunk包提供工具方法进行介绍:
| 方法 | 作用 |
|---|---|
| tree2conlltags(tree) | 将conll IOB树转化为三元列表 |
| conlltags2tree(sents) | 上面方法的逆,将三元组列表转为树 |
下面的代码使用最大熵分类器训练一个iob标记分类器,然后利用标记进行分块。分类器的训练数据格式为((word,pos_tag),iob_tag),经过学习,分类器就可以对新见到的(word,pos_tag)对进行iob分类,从而打上合适的标签。
import nltk
from nltk.corpus import conll2000
# 基于pos和prevpos定义特征
def npchunk_features(sentence,i,history):
word,pos = sentence[i]
if i == 0:
prevword,prevpos = "<START>","<START>"
else:
prevword,prevpos = sentence[i-1]
return {"pos":pos,"prevpos":prevpos}
# 使用pos信息的基于分类器的标记器
class ContextNPChunkTagger(nltk.TaggerI):
def __init__(self, train_sents):
train_set = []
for tagged_sent in train_sents:
untagged_sent = nltk.tag.untag(tagged_sent)
history = []
for i, (word, tag) in enumerate(tagged_sent):
featureset = npchunk_features(untagged_sent, i, history)
train_set.append((featureset, tag))
history.append(tag)
self.classifier = nltk.MaxentClassifier.train(train_set)
def tag(self, sentence):
history = []
for i, word in enumerate(sentence):
featureset = npchunk_features(sentence, i, history)
tag = self.classifier.classify(featureset)
history.append(tag)
return zip(sentence, history)
# 包装标记器来标记句子
class ContextNPChunker(nltk.ChunkParserI):
def __init__(self, train_sents):
tagged_sents = [[((w, t), c) for (w, t, c) in nltk.chunk.tree2conlltags(sent)]
for sent in train_sents]
self.tagger = ContextNPChunkTagger(tagged_sents)
def parse(self, sentence):
tagged_sents = self.tagger.tag(sentence)
conlltags = [(w, t, c) for ((w, t), c) in tagged_sents]
return nltk.chunk.conlltags2tree(conlltags)
test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])
train_sents = conll2000.chunked_sents('train.txt', chunk_types=['NP'])
chunker = ContextNPChunker(train_sents)
print(chunker.evaluate(test_sents))
''' output
ChunkParse score:
IOB Accuracy: 93.6%%
Precision: 82.0%%
Recall: 87.2%%
F-Measure: 84.6%%
'''
==> Training (100 iterations)
Iteration Log Likelihood Accuracy
---------------------------------------
1 -1.09861 0.441
2 -0.24505 0.933
3 -0.16970 0.932
...
52 -0.10519 0.937
53 -0.10512 0.937
54 -0.10505 0.937
55 -0.10499 0.937
Training stopped: keyboard interrupt
Final -0.10493 0.937
ChunkParse score:
IOB Accuracy: 93.6%%
Precision: 82.0%%
Recall: 87.2%%
F-Measure: 84.5%%
2.5 命名实体识别
命名实体识别系统的目标是识别文字提及的命名实体。可以分解成两个子任务:确定NE的边界和确定其类型。
命名实体识别也是适合基于分类器类型的方法来处理。通常标注语料库会标注下列的命名实体:[‘LOCATION’, ‘ORGANIZATION’, ‘PERSON’, ‘DURATION’,‘DATE’, ‘CARDINAL’, ‘PERCENT’, ‘MONEY’, ‘MEASURE’, ‘FACILITY’, ‘GPE’]
NLTK提供了一个训练好的NER分类器,nltk.chunk.named_entify.py源码展示了基于ace_data训练一个命名实体识注器的方法。[浏览源码]
下面代码使用nltk.chunk.ne_chunk()进行NE的识别。
import nltk
tagged = nltk.corpus.brown.tagged_sents()[0]
entity = nltk.chunk.ne_chunk(tagged)
print(entity)
(S
The/AT
Fulton/NP-TL
County/NN-TL
Grand/JJ-TL
(PERSON Jury/NN-TL)
said/VBD
Friday/NR
an/AT
investigation/NN
of/IN
Atlanta's/NP$
recent/JJ
primary/NN
election/NN
produced/VBD
``/``
no/AT
evidence/NN
''/''
that/CS
any/DTI
irregularities/NNS
took/VBD
place/NN
./.)
2.6 关系抽取
一旦文本中的命名实体被识别,就可以提取其间的关系,通常是寻找所有(e1,relation,e2)(e1,relation,e2)形式的三元组。
在nltk.sem.extract.py中实现对语料库ieer,ace,conll2002文本的关系提取。所以下面的代码可以使用正则表达式r’.*bpresidentb’来提取某组织主席(PER president ORG)的信息。
import re
import nltk
def open_ie():
PR = re.compile(r'.*presidentb')
for doc in nltk.corpus.ieer.parsed_docs():
for rel in nltk.sem.extract_rels('PER', 'ORG', doc, corpus='ieer', pattern=PR):
return nltk.sem.rtuple(rel)
print open_ie()
'''output
[PER: u'Kiriyenko'] u'became president of the' [ORG: u'NORSI']
[PER: u'Bill Gross'] u', president of' [ORG: u'Idealab']
[PER: u'Abe Kleinfield'] u', a vice president at' [ORG: u'Open Text']
[PER: u'Kaufman'] u', president of the privately held' [ORG: u'TV Books LLC']
[PER: u'Lindsay Doran'] u', president of' [ORG: u'United Artists']
[PER: u'Laura Ziskin'] u', president of' [ORG: u'Fox 2000']
[PER: u'Tom Rothman'] u', president of production at' [ORG: u'20th Century Fox']
[PER: u'John Wren'] u', the president and chief executive at' [ORG: u'Omnicom']
[PER: u'Ken Kaess'] u', president of the' [ORG: u'DDB Needham']
[PER: u'Jack Ablin'] u', president of' [ORG: u'Barnett Capital Advisors Inc.']
[PER: u'Lloyd Kiva New'] u', president emeritus of the' [ORG: u'Institute of American Indian Art']
[PER: u'J. Jackson Walter'] u', who served as president of the' [ORG: u'National Trust for Historic Preservation']
[PER: u'Bill Gamba'] u', senior vice president and manager of bond trading at' [ORG: u'Cowen & Co.']
'''
最后
以上就是傲娇老虎最近收集整理的关于NLTK3:文本分类与文本信息抽取0. nltk的分类器介绍1.信息抽取2.分块的全部内容,更多相关NLTK3:文本分类与文本信息抽取0.内容请搜索靠谱客的其他文章。








发表评论 取消回复