文本提取及处理
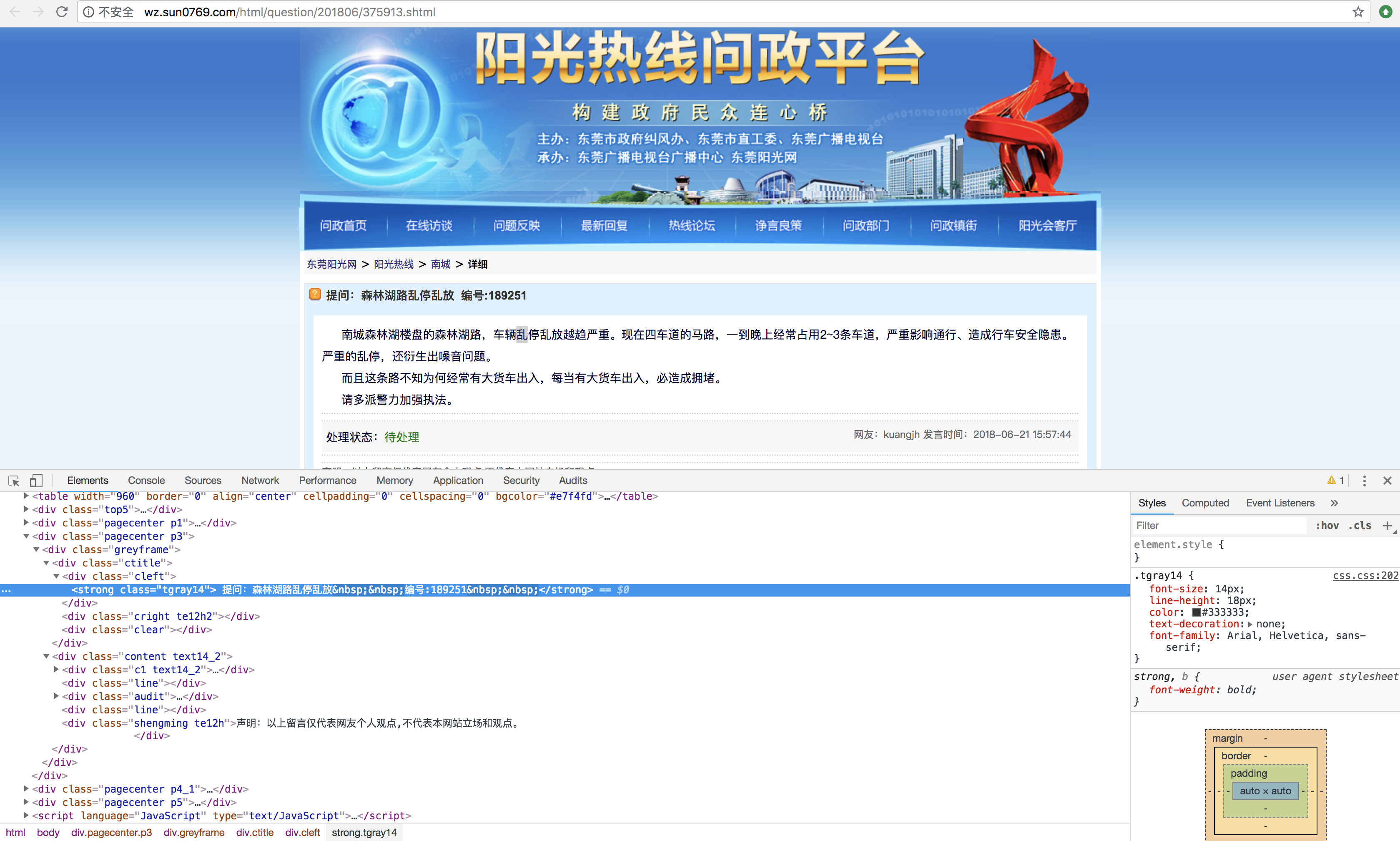
标题提取:
1 wljdeMacBook-Pro:Desktop wlj$ scrapy shell "http://wz.sun0769.com/html/question/201806/375913.shtml" 2 2018-06-21 23:44:36 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: scrapybot) 3 2018-06-21 23:44:36 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.6.5 (default, Apr 25 2018, 14:23:58) - [GCC 4.2.1 Compatible Apple LLVM 9.1.0 (clang-902.0.39.1)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Darwin-17.5.0-x86_64-i386-64bit 4 2018-06-21 23:44:36 [scrapy.crawler] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0} 5 2018-06-21 23:44:36 [scrapy.middleware] INFO: Enabled extensions: 6 ['scrapy.extensions.corestats.CoreStats', 7 'scrapy.extensions.telnet.TelnetConsole', 8 'scrapy.extensions.memusage.MemoryUsage'] 9 2018-06-21 23:44:36 [scrapy.middleware] INFO: Enabled downloader middlewares: 10 ['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 11 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 12 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 13 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 14 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 15 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 16 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 17 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 18 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 19 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 20 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 21 2018-06-21 23:44:36 [scrapy.middleware] INFO: Enabled spider middlewares: 22 ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 23 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 24 'scrapy.spidermiddlewares.referer.RefererMiddleware', 25 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 26 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 27 2018-06-21 23:44:36 [scrapy.middleware] INFO: Enabled item pipelines: 28 [] 29 2018-06-21 23:44:36 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 30 2018-06-21 23:44:36 [scrapy.core.engine] INFO: Spider opened 31 2018-06-21 23:44:36 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://wz.sun0769.com/html/question/201806/375913.shtml> (referer: None) 32 [s] Available Scrapy objects: 33 [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) 34 [s] crawler <scrapy.crawler.Crawler object at 0x102d30c88> 35 [s] item {} 36 [s] request <GET http://wz.sun0769.com/html/question/201806/375913.shtml> 37 [s] response <200 http://wz.sun0769.com/html/question/201806/375913.shtml> 38 [s] settings <scrapy.settings.Settings object at 0x103b276d8> 39 [s] spider <DefaultSpider 'default' at 0x103ddfc18> 40 [s] Useful shortcuts: 41 [s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed) 42 [s] fetch(req) Fetch a scrapy.Request and update local objects 43 [s] shelp() Shell help (print this help) 44 [s] view(response) View response in a browser 45 >>> response.url 46 'http://wz.sun0769.com/html/question/201806/375913.shtml' 47 >>> from scrapy.linkextractors import LinkExtractor 48 >>> response.xpath('//div[@class="pagecenter p3"]//strong/text()').extract()[0] 49 ' 提问:森林湖路乱停乱放xa0xa0编号:189251xa0xa0' 50 >>>
正文提取:
1 >>> response.xpath('//div[@class="c1 text14_2"]/text()').extract()[0] 2 'xa0xa0xa0xa0 南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。' 3 >>> response.xpath('//div[@class="c1 text14_2"]/text()').extract() 4 ['xa0xa0xa0xa0 南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。', 'xa0xa0xa0xa0 而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。', 'xa0xa0xa0xa0 请多派警力加强执法。'] 5 >>>
python3中处理:
1 wljdeMacBook-Pro:~ wlj$ python3 2 Python 3.6.5 (default, Apr 25 2018, 14:23:58) 3 [GCC 4.2.1 Compatible Apple LLVM 9.1.0 (clang-902.0.39.1)] on darwin 4 Type "help", "copyright", "credits" or "license" for more information. 5 >>> strs = ' 提问:森林湖路乱停乱放xa0xa0编号:189251xa0xa0' 6 >>> strs.split(' ')[-1].split(":")[-1] 7 '189251xa0xa0' 8 >>> strs.split(' ')[-1].split(":")[-1].strip() 9 '189251' 10 >>> lists = ['xa0xa0xa0xa0 南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的 停,还衍生出噪音问题。', 'xa0xa0xa0xa0 而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。', 'xa0xa0xa0xa0 请多派警力加强执法。'] 11 >>> lists 12 ['xa0xa0xa0xa0 南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。', 'xa0xa0xa0xa0 而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。', 'xa0xa0xa0xa0 请多派警力加强执法。'] 13 >>> string = "".join(lists) 14 >>> string 15 'xa0xa0xa0xa0 南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。xa0xa0xa0xa0 而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。xa0xa0xa0xa0 请多派警力加强执法。' 16 >>> string = "*****".join(lists) 17 >>> string 18 'xa0xa0xa0xa0 南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。*****xa0xa0xa0xa0 而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。*****xa0xa0xa0xa0 请多派警力加强执法。' 19 >>> string = "".join(lists) 20 >>> string 21 'xa0xa0xa0xa0 南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。xa0xa0xa0xa0 而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。xa0xa0xa0xa0 请多派警力加强执法。' 22 >>> string.replace(" ","") 23 'xa0xa0xa0xa0南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。xa0xa0xa0xa0而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。xa0xa0xa0xa0请多派警力加强执法。' 24 >>> string.strip() 25 '南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。xa0xa0xa0xa0 而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。xa0xa0xa0xa0 请多派警力加强执法。' 26 >>> string.lstrip() 27 '南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。xa0xa0xa0xa0 而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。xa0xa0xa0xa0 请多派警力加强执法。' 28 >>> string.rstrip() 29 'xa0xa0xa0xa0 南城森林湖楼盘的森林湖路,车辆乱停乱放越趋严重。现在四车道的马路,一到晚上经常占用2~3条车道,严重影响通行、造成行车安全隐患。严重的乱停,还衍生出噪音问题。xa0xa0xa0xa0 而且这条路不知为何经常有大货车出入,每当有大货车出入,必造成拥堵。xa0xa0xa0xa0 请多派警力加强执法。' 30 >>>
转载于:https://www.cnblogs.com/wanglinjie/p/9211566.html
最后
以上就是自由爆米花最近收集整理的关于文本提取及处理的全部内容,更多相关文本提取及处理内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复