requests项目实战--抓取百度热搜
发布时间:2020-08-21 13:47:38编辑:admin阅读(801)
一、概述
目标urlhttps://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=123
注意:123是搜索关键字。这不是重点,因为必须要搜索,才能在网页右侧出现百度热搜。
需求
提取标题,链接,点击量。
环境说明
python 3.7
安装依赖pip3 install requests
pip3 install lxml
二、抓取分析
XPath Helper插件
请确保谷歌浏览器安装了XPath Helper插件。
使用时,打开一个网页,点击右侧的图标

它会弹出一个黑框

左侧输入xpath语法,右侧显示匹配结果。
提取表格每一行
可以发现,百度热搜,是在一个table表格里面,class属性为:c-table opr-toplist1-table
表格的每一行,就是一条新闻信息。
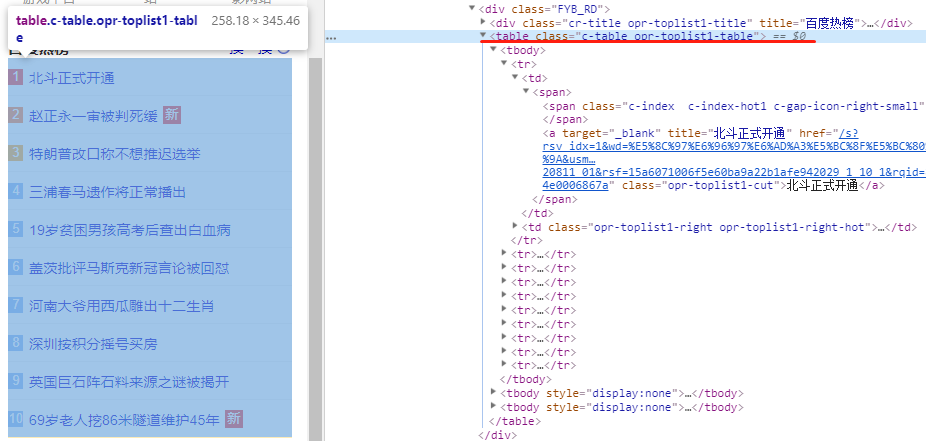
获取每一行内容,xpath规则为://table[@class='c-table opr-toplist1-table']/tbody/tr
效果如下:

提取标题
标题是在一个a标签里面,class='opr-toplist1-cut',提取text()即可
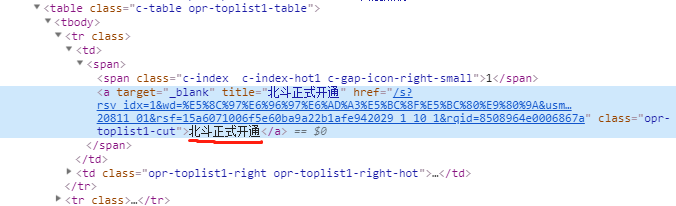
xpath规则为://a[@class='opr-toplist1-cut']/text()
效果如下:

提取链接
链接也是在一个a标签里面,class='opr-toplist1-cut',提取href属性即可
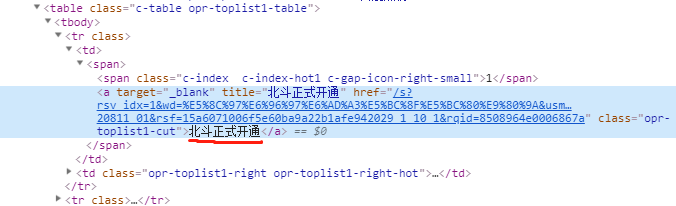
xpath规则为://a[@class='opr-toplist1-cut']/@href
效果如下:

提取点击量
点击量在一个td里面,class='opr-toplist1-right opr-toplist1-right-hot',提取text()即可
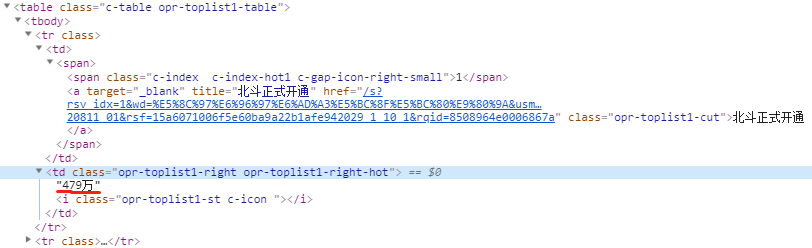
xpath规则为://td[@class='opr-toplist1-right opr-toplist1-right-hot']/text()
效果如下:

三、完整代码
import requests
from lxml import etree
import time
import json
class Item:
id = None # id
title = None # 标题
url = None # 链接
hits = None # 点击量
class GetBaiduHotSearch:
def get_html(self, url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
if response.status_code == 200:
return response.text
return None
except Exception:
return None
def get_content(self, html):
items = []
# normalize-space 去空格,换行符
content = etree.HTML(html)
all_list = content.xpath("//table[@class='c-table opr-toplist1-table']/tbody/tr")
# 初始id
id = 0
for i in all_list:
item = Item()
id += 1 # 自增1
item.id = id
item.title = i.xpath("normalize-space(.//a[@class='opr-toplist1-cut']/text())")
item.url = 'https://www.baidu.com' + i.xpath("normalize-space(.//a[@class='opr-toplist1-cut']/@href)")
item.hits = i.xpath("normalize-space(.//td[@class='opr-toplist1-right opr-toplist1-right-hot']/text())")
items.append(item)
return items
def write_to_txt(self, items):
content_dict = {
'id': None,
'title': None,
'url': None,
'hits': None,
}
# 写入到文件中
with open('result.txt', 'a', encoding='utf-8') as f:
for item in items:
content_dict['id'] = item.id
content_dict['title'] = item.title
content_dict['url'] = item.url
content_dict['hits'] = item.hits
print(content_dict)
f.write(json.dumps(content_dict, ensure_ascii=False) + 'n')
def main(self):
url = 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=123'
html = self.get_html(url)
items = self.get_content(html)
self.write_to_txt(items)
if __name__ == '__main__':
st = GetBaiduHotSearch().main()
运行结果:

文本结果:

文本参考链接:
关键字:
最后
以上就是优秀发箍最近收集整理的关于php采集百度热搜,requests项目实战--抓取百度热搜的全部内容,更多相关php采集百度热搜内容请搜索靠谱客的其他文章。



![[C#图文教程] c#从0开始写采集软件 第五弹 获取子匹配文本并添加到listView](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)




发表评论 取消回复