Linux 进程复制与替换
- 1. 主函数参数介绍
- 2. printf函数输出问题
- 3. 复制进程fork
- (1)fork方法
- (2)fork练习
- 4. 僵死进程及处理方法
- 5. 操作文件的系统调用
- (1)文件的读写
- (2)完成对普通文件的复制
- 6. 系统调用和库函数的区别
- 7. 进程替换
- 8. 写时拷贝技术如何实现?
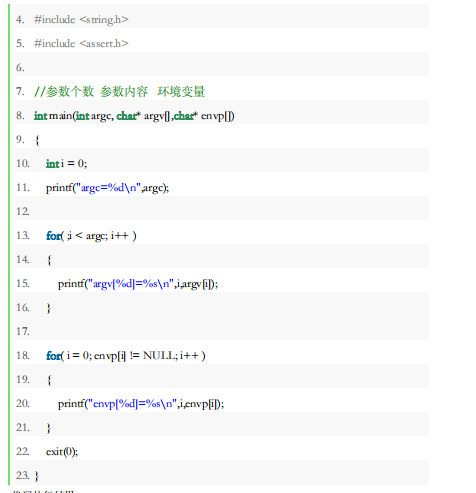
1. 主函数参数介绍
int main( int argc, char* argv[], char* envp[])
(1) argc 参数个数
(2) argv 参数内容
(3) envp 环境变量

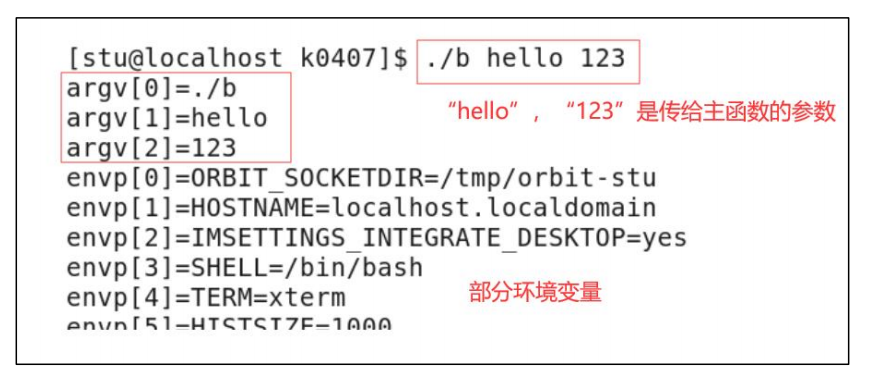
代码执行结果
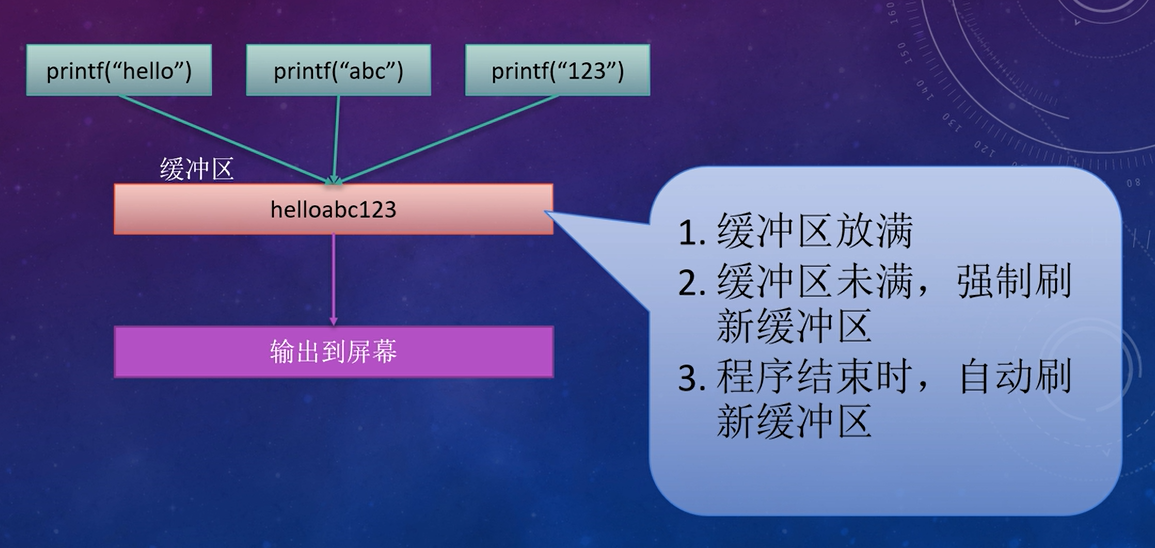
2. printf函数输出问题
printf 函数并不会直接将数据输出到屏幕,而是先放到缓冲区中,只有以下三种情况满足,才会输出到屏幕。
- 缓冲区满
- 强制刷新缓冲区 fflush
- 程序结束时

3. 复制进程fork
(1)fork方法
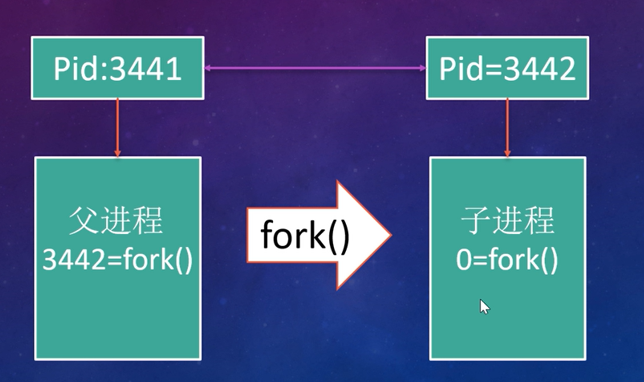
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<assert.h>
int main(int argc,char* argv[],char* envp[])
{
char *s=NULL;
int n=0;
pid_t pid=fork();
assert(pid!=-1);
if(pid==0)
{
s="child";
n=3;
}
else
{
s="parent";
n=7;
}
for(int i=0;i<n;i++)
{
printf("s=%s,pid=%d,ppid=%dn",s,getpid(),getppid());
sleep(1);
}
}
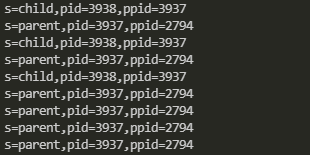
父子进程中变量 n 的物理地址是不是在同一块内存空间上,参考运行结果分析为什么?
在。这个一样的地址是线性地址,每个进程的相同的线性地址都可以映射到不同的物理地址上。在fork的时候,子进程从父进程copy了task_struct结构,其中task_struct里的mm就是线性地址的使用情况,mm也会被copy给子进程,所以在fork之前声明的变量,在fork后在父进程和子进程里的线性地址是一样的。
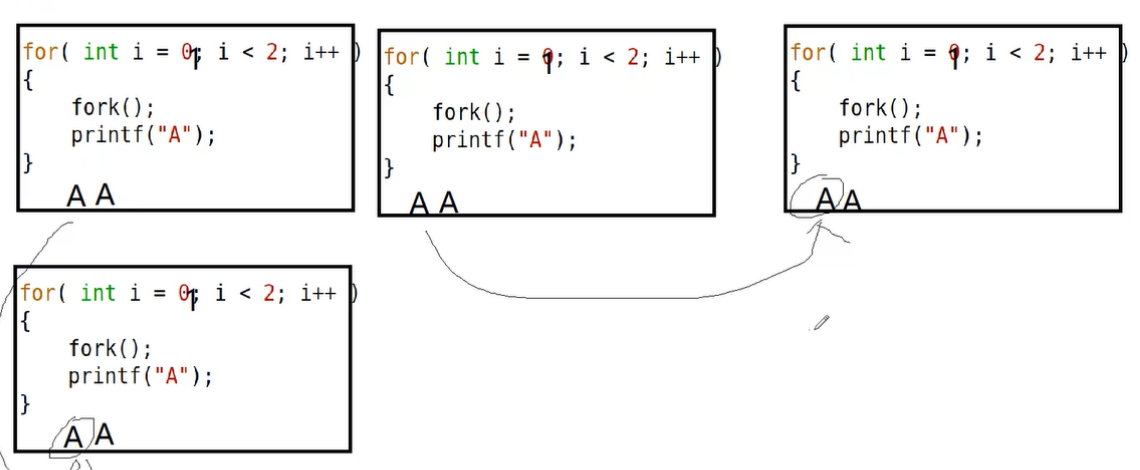
(2)fork练习
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<assert.h>
int main(int argc,char* argv[],char* envp[])
{
for(int i=0;i<2;i++)
{
fork();
printf("An");
}
exit(0);
}
打印6个A
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<assert.h>
int main(int argc,char* argv[],char* envp[])
{
for(int i=0;i<2;i++)
{
fork();
printf("A");
}
exit(0);
}
打印8个A
没有n:把缓冲区放满或者程序结束时才打印
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<assert.h>
int main(int argc,char* argv[],char* envp[])
{
fork()||fork();
printf("An");
exit(0);
}
输出3个A
4. 僵死进程及处理方法
-
孤儿进程:是指一个父进程退出后,而它的一个或多个子进程还在运行,那么这些进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并且由init进程对它们完整状态做收集工作。
-
僵死进程:是指一个进程使用fork函数创建进程,如果子进程退出,而父进程没有调用wait()或者waitpid()系统调用取得子进程的终止状态,那么子进程的进程描述符仍然保存在系统中,占用系统资源,这种进程成为僵死进程。
-
解决方法:
- 一般,为了防止产生僵死进程,在fork子进程之后我们都要及时使用wait系统调用;同时,当子进程退出的时候,内核都会给父进程一个SIGCHILD信号,所以我们可以建立一个捕获SIGCHILD信号的信号处理函数,在函数体中调用wait(或waitpid),就可以清理推出的子进程已达到防止僵死进程的目的。
- 使用kill命令
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<assert.h>
#include<sys/wait.h>
int main(int argc,char* argv[],char* envp[])
{
char *s=NULL;
int n=0;
pid_t pid=fork();
assert(pid!=-1);
if(pid==0)
{
s="child";
n=3;
}
else
{
s="parent";
n=7;
int val=0;
wait(&val);
if(WIFEXITED(val))//判断程序是不是正常结束
{
printf("child exit code=%dn",WEXITSTATUS(val));//提前退出码
}
}
for(int i=0;i<n;i++)
{
printf("s=%s,pid=%d,ppid=%dn",s,getpid(),getppid());
sleep(1);
}
}
5. 操作文件的系统调用
(1)文件的读写
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<assert.h>
#include<fcntl.h>
int main()
{
int fw=open("a.txt",O_WRONLY|O_CREAT,0600);
assert(fw!=-1);
write(fw,"hello",5);
close(fw);
int fr=open("a.txt",O_RDONLY);
assert(fr!=-1);
char buff[128]={0};
int n=read(fr,buff,127);
printf("buff=%s,n=%dn",buff,n);
close(fr);
}

(2)完成对普通文件的复制
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<assert.h>
#include<fcntl.h>
int main(int argc,char* argv[])
{
if(argc!=3)
{
printf("arg errn");
return 0;
}
char *filename=argv[1];
char *newfilename=argv[2];
int fdr=open(filename,O_RDONLY);
int fdw=open(newfilename,O_WRONLY|O_CREAT,0600);
if(fdr==-1||fdw==-1)
{
printf("open file failedn");
return 0;
}
char buff[512]={0};
int n=0;
while((n=read(fdr,buff,512))>0)
{
write(fdw,buff,n);
}
close(fdr);
close(fdw);
}
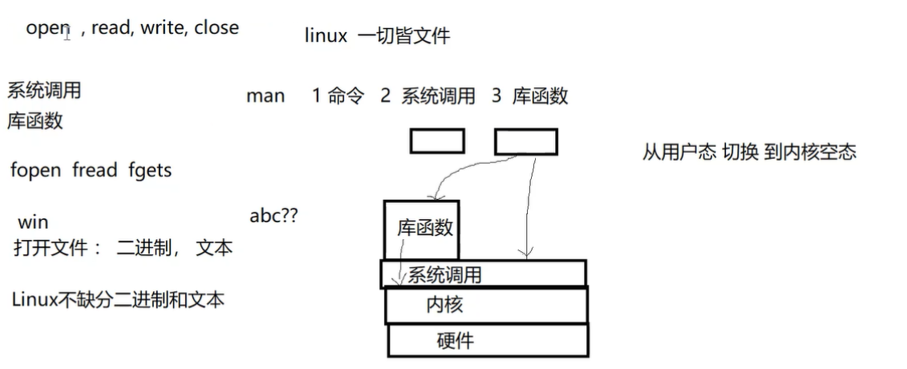
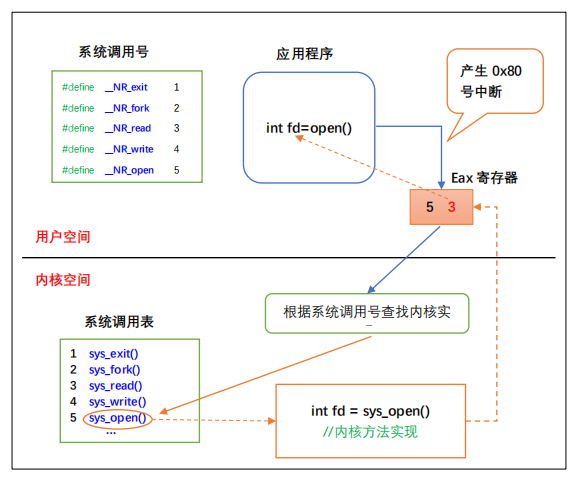
6. 系统调用和库函数的区别
- 系统调用
系统调用是通向操作系统本身的接口,是面向底层硬件的。通过系统调用,可以使得用户态运行的进程与硬件设备(如CPU、磁盘、打印机等)进行交互,是操作系统留给应用程序的一个接口。 - 区别: 系统调用的实现在内核中,属于内核空间,库函数的实现在函数库中,属于用户空间。
- 系统调用是最底层的应用,是面向硬件的。而库函数的调用是面向开发的,相当于应用程序的API(即预先定义好的函数)接口;
- 各个操作系统的系统调用是不同的,因此系统调用一般是没有跨操作系统的可移植性,而库函数的移植性良好(c库在Windows和Linux环境下都可以操作);
- 库函数属于过程调用,调用开销小;系统调用需要在用户空间和内核上下文环境切换,开销较大;
- 库函数调用函数库中的一段程序,这段程序最终还是通过系统调用来实现的;系统调用调用的是系统内核的服务。
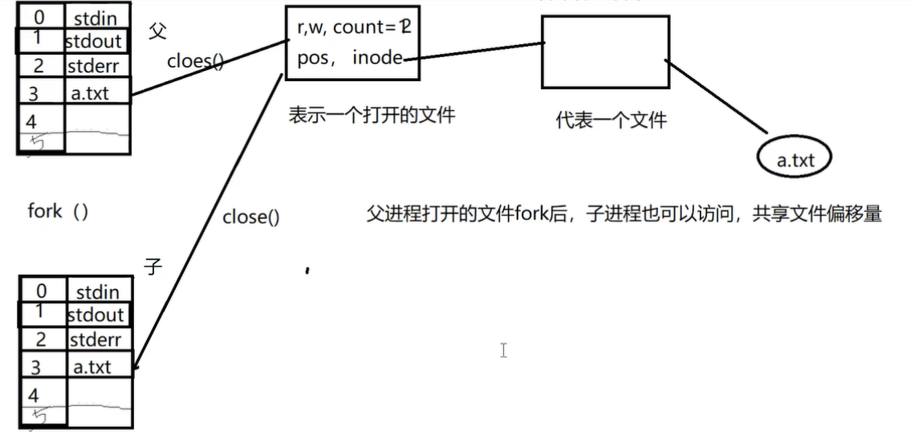
每个进程都有自己的文件表,程序只要启动起来,默认情况下打开了三个文件:标准输入、标准输出和标准错误输出。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<assert.h>
#include<fcntl.h>
int main(int argc,char* argv[])
{
int fd=open("file.txt",O_RDONLY);
assert(fd!=-1);
pid_t pid=fork();
assert(pid!=-1);
char buff[32]={0};
if(pid==0)
{
read(fd,buff,1);
printf("buff=%sn",buff);
sleep(1);
read(fd,buff,1);
printf("buff=%sn",buff);
}
else
{
read(fd,buff,1);
printf("buff=%sn",buff);
sleep(1);
read(fd,buff,1);
printf("buff=%sn",buff);
}
}
执行结果:
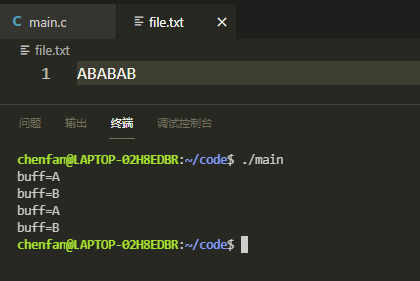
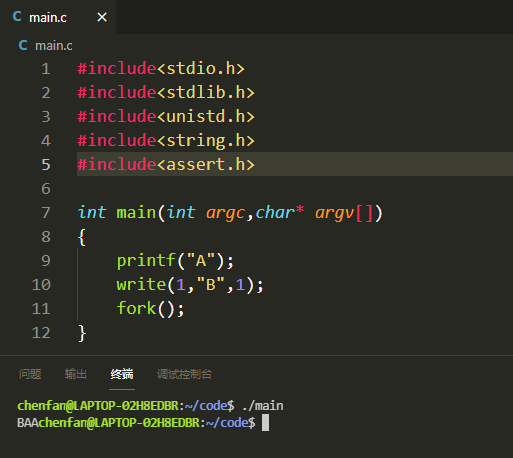
分析:见到printf我们就想到printf缓冲区的问题,A放到缓冲区没有打印,等程序结束时再系统调用write()函数。而write是系统调用,直接将B打印到stdout(屏幕上),这时候进行fork()会将缓冲区中的A也进行复制,程序结束后会打印出来AA。所以运行结果是BAA。
7. 进程替换
fork 和 exec 联合使用创建一个全新的进程
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<assert.h>
int main(int argc,char* argv[],char* envp)
{
char* myenvp[10]={"STR=hello"};
char* myargv[10]={"ps","-f"};
printf("main pid=%dn",getpid());
//execl 执行成功不返回,直接从新程序的主函数开始执行,只有失败才返回错误码
//execl("/usr/bin/ps","ps","-f",(char*)0);
//execlp("ps","ps","-f",(char*)0);
//execle("/usr/bin/ps","ps","-f",(char*)0,envp);
//execv("/usr/bin/ps",myargv);
//execvp("ps",myargv);
execve("/usr/bin/ps",myargv,envp);
printf("execl errn");
}
8. 写时拷贝技术如何实现?
可以推迟甚至免除拷贝数据。内核此时并不复制整个进程地址空间,而是让父进程和子进程共享一个拷贝。只有在需要写入的时候,数据才会被复制,从而使各个进程拥有各自的拷贝。也就是说,资源的复制只有在需要写入的时候才进行,在此之前,只是以只读方式共享。这种优化可以避免拷贝大量根本就不会被使用的数据。
写时拷贝技术以页为单位进行复制,可以加速fork复制过程,提高fork复制的效率。
最后
以上就是甜甜纸鹤最近收集整理的关于Linux进程复制与替换的全部内容,更多相关Linux进程复制与替换内容请搜索靠谱客的其他文章。








发表评论 取消回复