Bert:
BERT是一种预训练语言表示的方法,这意味着我们在大型文本语料库(例如Wikipedia)上训练通用的“语言理解”模型,然后将该模型用于我们关心的下游NLP任务,BERT优于之前的方法,因为它是第一个用于预训练NLP的无监督,深度双向系统。
相关论文:
《Attention Is All You Need》
《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》
之后可能会出一篇详解bert原理的文章。
一、环境搭建:
Tensorflow>=1.11.0 我使用的1.12.0
Python 3.6.8
使用GPU训练(官网说显存要求大于12g)
服务器:1080Ti 32G
二、下载模型:
下载bert:https://github.com/google-research/bert
下载bert预训练模型:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
三、数据准备:
将你的语料分成3个文件,分别为train.csv,test.csv,dev.csv三个(我使用的是csv文件,它与tsv区别就是分隔符号的不同,我直接将csv的分隔符‘,’转成‘t’),放入新建data文件夹下。
具体操作:
我的语料来自于情感分析比赛的,是判断新闻标题情感积极消极还是中性,首先使用pandas对语料进行处理,最终处理成“label+content”的格式。如图所示:

将语料分割成三个文件:我分割的比例是8:1:1,可以按照自己的比例进行分割。
#!/usr/bin/env python
import os
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
def train_valid_test_split(x_data, y_data,
validation_size=0.1, test_size=0.1, shuffle=True):
x_, x_test, y_, y_test = train_test_split(x_data, y_data, test_size=test_size, shuffle=shuffle)
valid_size = validation_size / (1.0 - test_size)
x_train, x_valid, y_train, y_valid = train_test_split(x_, y_, test_size=valid_size, shuffle=shuffle)
return x_train, x_valid, x_test, y_train, y_valid, y_test
if __name__ == '__main__':
path = "data/"
pd_all = pd.read_csv(os.path.join(path, "outcleanfile.csv"))
pd_all = shuffle(pd_all)
x_data, y_data = pd_all.title, pd_all.label
x_train, x_valid, x_test, y_train, y_valid, y_test =
train_valid_test_split(x_data, y_data, 0.1, 0.1)
train = pd.DataFrame({'label': y_train, 'x_train': x_train})
train.to_csv("data/train.csv", index=False, encoding='utf-8',sep='t')
valid = pd.DataFrame({'label': y_valid, 'x_valid': x_valid})
valid.to_csv("data/dev.csv", index=False, encoding='utf-8',sep='t')
test = pd.DataFrame({'label': y_test, 'x_test': x_test})
test.to_csv("data/test.csv", index=False, encoding='utf-8',sep='t')最终文件结构如图:
四、修改代码:
1.新定义处理类:
class NewsProcessor(DataProcessor):
"""Processor for the WeiBo data set ."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.csv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.csv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.csv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1", "2"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
# All sets have a header
if i == 0: continue
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples2.处理类注册:
在bert文件夹下的run_classifier.py中的def main(_):函数中将processors的内容增加为:
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"news": NewsProcessor
}五、训练模型:
网上很多使用shell脚本运行,但是我试了n次总是传不进去参数,直接修改了python文件里的参数,不过还是把脚本放在这了,知道问题的小伙伴可以告知一声。执行脚本或python文件前新建output文件用于训练输出。
export DATA_DIR=数据所在的路径
export BERT_BASE_DIR=预训练模型所在的路径
python run_classifier.py
--task_name=news
--do_train=true
--do_eval=true
--data_dir=$DATA_DIR/
--vocab_file=$BERT_BASE_DIR/vocab.txt
--bert_config_file=$BERT_BASE_DIR/bert_config.json
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt
--max_seq_length=128
--train_batch_size=32
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir=/output内存不足调整这两个参数:
max_seq_length:发布的模型经过训练,序列长度最大为512,但是您可以使用更短的最大序列长度进行微调,以节省大量内存。train_batch_size:内存使用也与批处理大小成正比。
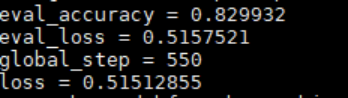
训练时长根据配置及数据情况而定,我的应该几个小时就跑完了。训练结果保存在output的eval_results.txt。如下:
六、分类预测
将刚才的脚本文件修改为如下:
python run_classifier.py
--task_name=news
--do_predict=true
--data_dir=./glue
--vocab_file=./uncased/uncased_L-12_H-768_A-12/vocab.txt
--bert_config_file=./uncased/uncased_L-12_H-768_A-12/bert_config.json
--init_checkpoint=./tmp/emotion/bert_model.ckpt
--max_seq_length=128
--output_dir=./output/emotion_out/
或者直接更改run_classifier.py中的参数,将do_predict改为True,do_train和do_eval改为False。
最终得到一个tsv文件,文件中每一条是预测各个类(0、1、2)的概率,如下图所示:

显然,概率并不是我们想要的,我们需要将概率最终转换成类别:
import os
import pandas as pd
if __name__ == '__main__':
path = "output/emotion_out/"
pd_all = pd.read_csv(os.path.join(path, "test_results.tsv") ,sep='t',header=None)
data = pd.DataFrame(columns=['polarity'])
print(pd_all.shape)
for index in pd_all.index:
neutral_score = pd_all.loc[index].values[0]
positive_score = pd_all.loc[index].values[1]
negative_score = pd_all.loc[index].values[2]
if max(neutral_score, positive_score, negative_score) == neutral_score:
# data.append(pd.DataFrame([index, "neutral"],columns=['id','polarity']),ignore_index=True)
data.loc[index+1] = ["neutral"]
elif max(neutral_score, positive_score, negative_score) == positive_score:
#data.append(pd.DataFrame([index, "positive"],columns=['id','polarity']),ignore_index=True)
data.loc[index+1] = [ "positive"]
else:
#data.append(pd.DataFrame([index, "negative"],columns=['id','polarity']),ignore_index=True)
data.loc[index+1] = [ "negative"]
#print(negative_score, positive_score, negative_score)
data.to_csv(os.path.join(path, "pre_sample.tsv"),sep = 't')
#print(data)最终得到预测结果:
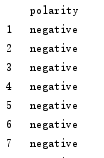
最后数据可能因为不是均匀分布,导致结果有些不准确,接下来从数据入手,整理下数据集。
参考链接:
https://github.com/google-research/bert
https://blog.csdn.net/qq874455953/article/details/90276116
最后
以上就是内向哈密瓜最近收集整理的关于基于BERT做中文文本分类(情感分析)的全部内容,更多相关基于BERT做中文文本分类(情感分析)内容请搜索靠谱客的其他文章。







![【Pre-Training】超细节的 BERT/Transformer 知识点1.不考虑多头的原因,self-attention 中词向量不乘 QKV 参数矩阵,会有什么问题?2.为什么 BERT 选择 mask 掉 15% 这个比例的词,可以是其他的比例吗?3.使用 BERT 预训练模型为什么最多只能输入 512 个词,最多只能两个句子合成一句?4.为什么 BERT 在第一句前会加一个 [CLS] 标志?5.Self-Attention 的时间复杂度是怎么计算的?6.Transformer 在](https://www.shuijiaxian.com/files_image/reation/bcimg22.png)
发表评论 取消回复