命名实体识别NER是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要的地位。
本文介绍了O2O搜索场景下NER任务的特点及技术选型,详述了在实体词典匹配和模型构建方面的探索与实践。
1. 背景
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。在美团搜索场景下,NER是深度查询理解(Deep Query Understanding,简称 DQU)的底层基础信号,主要应用于搜索召回、用户意图识别、实体链接等环节,NER信号的质量,直接影响到用户的搜索体验。
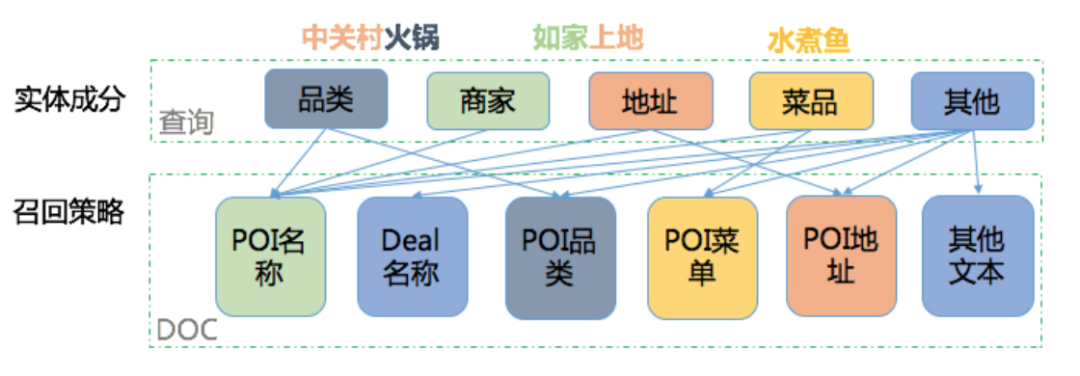
下面将简述一下实体识别在搜索召回中的应用。在O2O搜索中,对商家POI的描述是商家名称、地址、品类等多个互相之间相关性并不高的文本域。如果对O2O搜索引擎也采用全部文本域命中求交的方式,就可能会产生大量的误召回。
我们的解决方法如下图1所示,让特定的查询只在特定的文本域做倒排检索,我们称之为“结构化召回”,可保证召回商家的强相关性。举例来说,对于“海底捞”这样的请求,有些商家地址会描述为“海底捞附近几百米”,若采用全文本域检索这些商家就会被召回,显然这并不是用户想要的。而结构化召回基于NER将“海底捞”识别为商家,然后只在商家名相关文本域检索,从而只召回海底捞品牌商家,精准地满足了用户需求。
有别于其他应用场景,美团搜索的NER任务具有以下特点:
-
新增实体数量庞大且增速较快:本地生活服务领域发展迅速,新店、新商品、新服务品类层出不穷;用户Query往往夹杂很多非标准化表达、简称和热词(如“牵肠挂肚”、“吸猫”等),这对实现高准确率、高覆盖率的NER造成了很大挑战。
-
领域相关性强:搜索中的实体识别与业务供给高度相关,除通用语义外需加入业务相关知识辅助判断,比如“剪了个头发”,通用理解是泛化描述实体,在搜索中却是个商家实体。
-
性能要求高:从用户发起搜索到最终结果呈现给用户时间很短,NER作为DQU的基础模块,需要在毫秒级的时间内完成。近期,很多基于深度网络的研究与实践显著提高了NER的效果,但这些模型往往计算量较大、预测耗时长,如何优化模型性能,使之能满足NER对计算时间的要求,也是NER实践中的一大挑战。
2. 技术选型
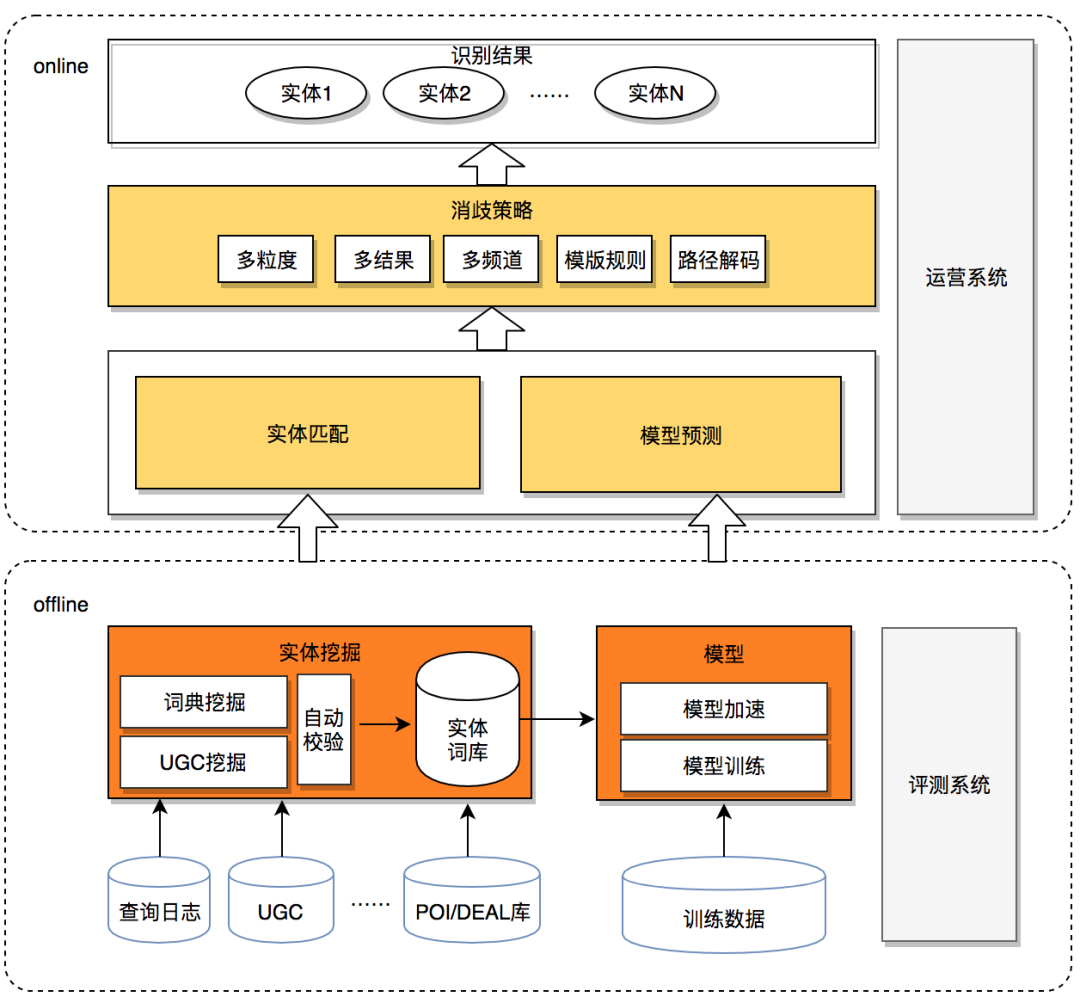
针对O2O领域NER 任务的特点,我们整体的技术选型是“实体词典匹配+模型预测”的框架,如图下2所示。实体词典匹配和模型预测两者解决的问题各有侧重,在当前阶段缺一不可。下面通过对三个问题的解答来说明我们为什么这么选。
为什么需要实体词典匹配?
答:主要有以下四个原因:
一是搜索中用户查询的头部流量通常较短、表达形式简单,且集中在商户、品类、地址等三类实体搜索,实体词典匹配虽简单但处理这类查询准确率也可达到 90%以上。
二是NER领域相关,通过挖掘业务数据资源获取业务实体词典,经过在线词典匹配后可保证识别结果是领域适配的。
三是新业务接入更加灵活,只需提供业务相关的实体词表就可完成新业务场景下的实体识别。
四是NER下游使用方中有些对响应时间要求极高,词典匹配速度快,基本不存在性能问题。
有了实体词典匹配为什么还要模型预测?
答:有以下两方面的原因:
一是随着搜索体量的不断增大,中长尾搜索流量表述复杂,越来越多OOV(Out Of Vocabulary)问题开始出现,实体词典已经无法满足日益多样化的用户需求,模型预测具备泛化能力,可作为词典匹配的有效补充。
二是实体词典匹配无法解决歧义问题,比如“黄鹤楼美食”,“黄鹤楼”在实体词典中同时是武汉的景点、北京的商家、香烟产品,词典匹配不具备消歧能力,这三种类型都会输出,而模型预测则可结合上下文,不会输出“黄鹤楼”是香烟产品。
实体词典匹配、模型预测两路结果是怎么合并输出的?
答:目前我们采用训练好的CRF权重网络作为打分器,来对实体词典匹配、模型预测两路输出的NER路径进行打分。在词典匹配无结果或是其路径打分值明显低于模型预测时,采用模型识别的结果,其他情况仍然采用词典匹配结果。
在介绍完我们的技术选型后,接下来会展开介绍下我们在实体词典匹配、模型在线预测等两方面的工作,希望能为大家在O2O NER领域的探索提供一些帮助。
3. 实体词典匹配
传统的NER技术仅能处理通用领域既定、既有的实体,但无法应对垂直领域所特有的实体类型。在美团搜索场景下,通过对POI结构化信息、商户评论数据、搜索日志等独有数据进行离线挖掘,可以很好地解决领域实体识别问题。经过离线实体库不断的丰富完善累积后,在线使用轻量级的词库匹配实体识别方式简单、高效、可控,且可以很好地覆盖头部和腰部流量。目前,基于实体库的在线NER识别率可以达到92%。
3.1 离线挖掘
美团具有丰富多样的结构化数据,通过对领域内结构化数据的加工处理可以获得高精度的初始实体库。例如:从商户基础信息中,可以获取商户名、类目、地址、售卖商品或服务等类型实体。从猫眼文娱数据中,可以获取电影、电视剧、艺人等类型实体。然而,用户搜索的实体名往往夹杂很多非标准化表达,与业务定义的标准实体名之间存在差异,如何从非标准表达中挖掘领域实体变得尤为重要。
现有的新词挖掘技术主要分为无监督学习、有监督学习和远程监督学习。无监督学习通过频繁序列产生候选集,并通过计算紧密度和自由度指标进行筛选,这种方法虽然可以产生充分的候选集合,但仅通过特征阈值过滤无法有效地平衡精确率与召回率,现实应用中通常挑选较高的阈值保证精度而牺牲召回。先进的新词挖掘算法大多为有监督学习,这类算法通常涉及复杂的语法分析模型或深度网络模型,且依赖领域专家设计繁多规则或大量的人工标记数据。远程监督学习通过开源知识库生成少量的标记数据,虽然一定程度上缓解了人力标注成本高的问题。然而小样本量的标记数据仅能学习简单的统计模型,无法训练具有高泛化能力的复杂模型。
我们的离线实体挖掘是多源多方法的,涉及到的数据源包括结构化的商家信息库、百科词条,半结构化的搜索日志,以及非结构化的用户评论(UGC)等。使用的挖掘方法也包含多种,包括规则、传统机器学习模型、深度学习模型等。UGC作为一种非结构化文本,蕴含了大量非标准表达实体名。下面我们将详细介绍一种针对UGC的垂直领域新词自动挖掘方法,该方法主要包含三个步骤,如下图3所示:
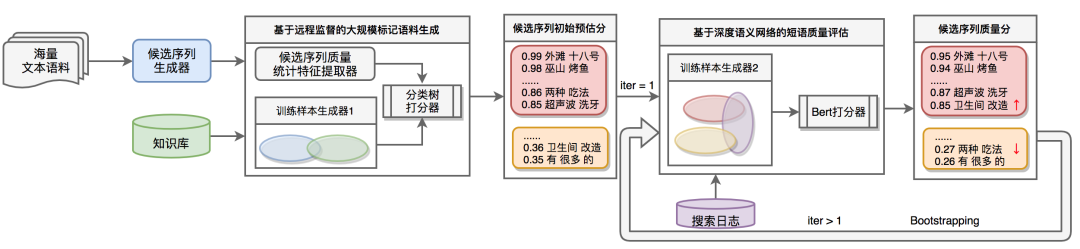
Step1:候选序列挖掘。频繁连续出现的词序列,是潜在新型词汇的有效候选,我们采用频繁序列产生充足候选集合。
Step2:基于远程监督的大规模有标记语料生成。频繁序列随着给定语料的变化而改变,因此人工标记成本极高。我们利用领域已有累积的实体词典作为远程监督词库,将Step1中候选序列与实体词典的交集作为训练正例样本。同时,通过对候选序列分析发现,在上百万的频繁Ngram中仅约10%左右的候选是真正的高质新型词汇。因此,对于负例样本,采用负采样方式生产训练负例集[1]。针对海量UGC语料,我们设计并定义了四个维度的统计特征来衡量候选短语可用性:
-
频率:有意义的新词在语料中应当满足一定的频率,该指标由Step1计算得到。
-
紧密度:主要用于评估新短语中连续元素的共现强度,包括T分布检验、皮尔森卡方检验、逐点互信息、似然比等指标。
-
信息度:新发现词汇应具有真实意义,指代某个新的实体或概念,该特征主要考虑了词组在语料中的逆文档频率、词性分布以及停用词分布。
-
完整性:新发现词汇应当在给定的上下文环境中作为整体解释存在,因此应同时考虑词组的子集短语以及超集短语的紧密度,从而衡量词组的完整性。
在经过小样本标记数据构建和多维度统计特征提取后,训练二元分类器来计算候选短语预估质量。由于训练数据负例样本采用了负采样的方式,这部分数据中混合了少量高质量的短语,为了减少负例噪声对短语预估质量分的影响,可以通过集成多个弱分类器的方式减少误差。对候选序列集合进行模型预测后,将得分超过一定阈值的集合作为正例池,较低分数的集合作为负例池。
Step3: 基于深度语义网络的短语质量评估。在有大量标记数据的情况下,深度网络模型可以自动有效地学习语料特征,并产出具有泛化能力的高效模型。BERT通过海量自然语言文本和深度模型学习文本语义表征,并经过简单微调在多个自然语言理解任务上刷新了记录,因此我们基于BERT训练短语质量打分器。为了更好地提升训练数据的质量,我们利用搜索日志数据对Step2中生成的大规模正负例池数据进行远程指导,将有大量搜索记录的词条作为有意义的关键词。我们将正例池与搜索日志重合的部分作为模型正样本,而将负例池减去搜索日志集合的部分作为模型负样本,进而提升训练数据的可靠性和多样性。此外,我们采用Bootstrapping方式,在初次得到短语质量分后,重新根据已有短语质量分以及远程语料搜索日志更新训练样本,迭代训练提升短语质量打分器效果,有效减少了伪正例和伪负例。
在UGC语料中抽取出大量新词或短语后,参考AutoNER[2]对新挖掘词语进行类型预测,从而扩充离线的实体库。
3.2 在线匹配
原始的在线NER词典匹配方法直接针对Query做双向最大匹配,从而获得成分识别候选集合,再基于词频(这里指实体搜索量)筛选输出最终结果。这种策略比较简陋,对词库准确度和覆盖度要求极高,所以存在以下几个问题:
-
当Query包含词库未覆盖实体时,基于字符的最大匹配算法易引起切分错误。例如,搜索词“海坨山谷”,词库仅能匹配到“海坨山”,因此出现“海坨山/谷”的错误切分。
-
粒度不可控。例如,搜索词“星巴克咖啡”的切分结果,取决于词库对“星巴克”、“咖啡”以及“星巴克咖啡”的覆盖。
-
节点权重定义不合理。例如,直接基于实体搜索量作为实体节点权重,当用户搜索“信阳菜馆”时,“信阳菜/馆”的得分大于“信阳/菜馆”。
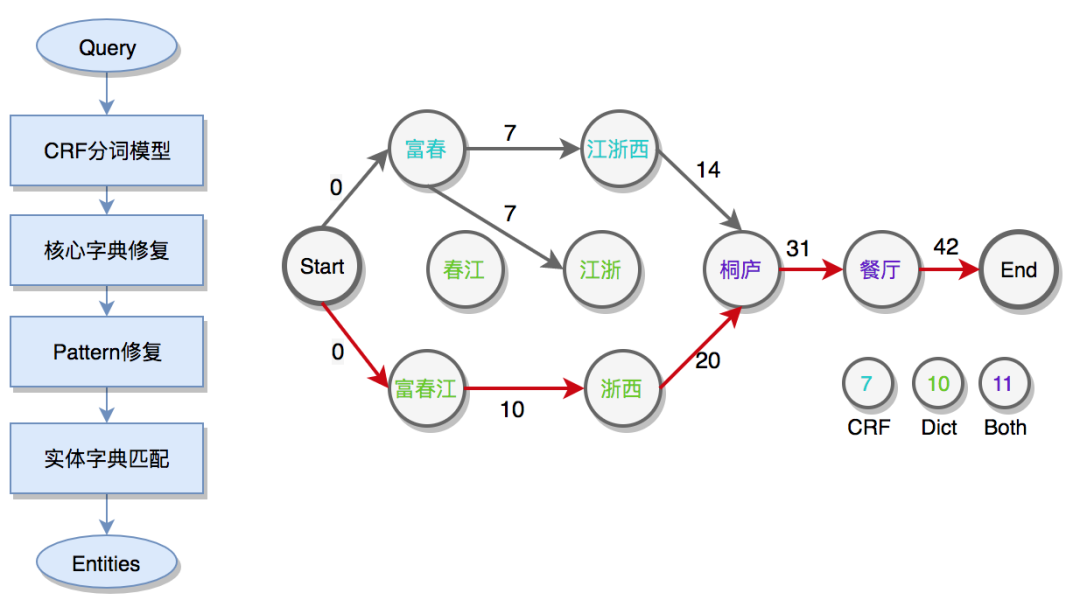
为了解决以上问题,在进行实体字典匹配前引入了CRF分词模型,针对垂直领域美团搜索制定分词准则,人工标注训练语料并训练CRF分词模型。同时,针对模型分词错误问题,设计两阶段修复方式:
-
结合模型分词Term和基于领域字典匹配Term,根据动态规划求解Term序列权重和的最优解。
-
基于Pattern正则表达式的强修复规则。最后,输出基于实体库匹配的成分识别结果。
4. 模型在线预测
对于长尾、未登录查询,我们使用模型进行在线识别。NER模型的演进经历了如下图5所示的几个阶段,目前线上使用的主模型是BERT[3]以及BERT+LR级联模型,另外还有一些在探索中模型的离线效果也证实有效,后续我们会综合考虑性能和收益逐步进行上线。搜索中NER线上模型的构建主要面临三个问题:
-
性能要求高:NER作为基础模块,模型预测需要在毫秒级时间内完成,而目前基于深度学习的模型都有计算量大、预测时间较长的问题。
-
领域强相关:搜索中的实体类型与业务供给高度相关,只考虑通用语义很难保证模型识别的准确性。
-
标注数据缺乏:NER标注任务相对较难,需给出实体边界切分、实体类型信息,标注过程费时费力,大规模标注数据难以获取。
针对性能要求高的问题,我们的线上模型在升级为BERT时进行了一系列的性能调优;针对NER领域相关问题,我们提出了融合搜索日志特征、实体词典信息的知识增强NER方法;针对训练数据难以获取的问题,我们提出一种弱监督的NER方法。下面我们详细介绍下这些技术点。
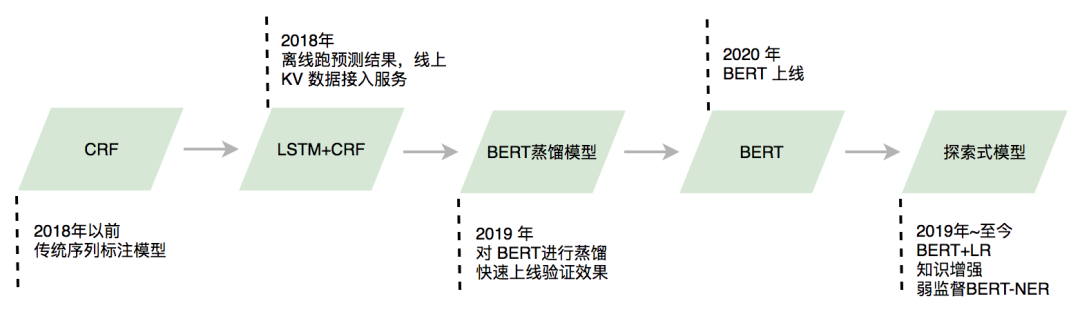
4.1 BERT模型
BERT是谷歌于2018年10月公开的一种自然语言处理方法。该方法一经发布,就引起了学术界以及工业界的广泛关注。在效果方面,BERT刷新了11个NLP任务的当前最优效果,该方法也被评为2018年NLP的重大进展以及NAACL 2019的best paper[4,5]。BERT和早前OpenAI发布的GPT方法技术路线基本一致,只是在技术细节上存在略微差异。两个工作的主要贡献在于使用预训练+微调的思路来解决自然语言处理问题。以BERT为例,模型应用包括2个环节:
-
预训练(Pre-training),该环节在大量通用语料上学习网络参数,通用语料包括Wikipedia、Book Corpus,这些语料包含了大量的文本,能够提供丰富的语言相关现象。
-
微调(Fine-tuning),该环节使用“任务相关”的标注数据对网络参数进行微调,不需要再为目标任务设计Task-specific网络从头训练。
将BERT应用于实体识别线上预测时面临一个挑战,即预测速度慢。我们从模型蒸馏、预测加速两个方面进行了探索,分阶段上线了BERT蒸馏模型、BERT+Softmax、BERT+CRF模型。
4.1.1 模型蒸馏
我们尝试了对BERT模型进行剪裁和蒸馏两种方式,结果证明,剪裁对于NER这种复杂NLP任务精度损失严重,而模型蒸馏是可行的。模型蒸馏是用简单模型来逼近复杂模型的输出,目的是降低预测所需的计算量,同时保证预测效果。Hinton在2015年的论文中阐述了核心思想[6],复杂模型一般称作Teacher Model,蒸馏后的简单模型一般称作Student Model。Hinton的蒸馏方法使用伪标注数据的概率分布来训练Student Model,而没有使用伪标注数据的标签来训练。作者的观点是概率分布相比标签能够提供更多信息以及更强约束,能够更好地保证Student Model与Teacher Model的预测效果达到一致。在2018年NeurIPS的Workshop上,[7]提出一种新的网络结构BlendCNN来逼近GPT的预测效果,本质上也是模型蒸馏。BlendCNN预测速度相对原始GPT提升了300倍,另外在特定任务上,预测准确率还略有提升。关于模型蒸馏,基本可以得到以下结论:
-
模型蒸馏本质是函数逼近。针对具体任务,笔者认为只要Student Model的复杂度能够满足问题的复杂度,那么Student Model可以与Teacher Model完全不同,选择Student Model的示例如下图6所示。举个例子,假设问题中的样本(x,y)从多项式函数中抽样得到,最高指数次数d=2;可用的Teacher Model使用了更高指数次数(比如d=5),此时,要选择一个Student Model来进行预测,Student Model的模型复杂度不能低于问题本身的复杂度,即对应的指数次数至少达到d=2。
-
根据无标注数据的规模,蒸馏使用的约束可以不同。如图7所示,如果无标注数据规模小,可以采用值(logits)近似进行学习,施加强约束;如果无标注数据规模中等,可以采用分布近似;如果无标注数据规模很大,可以采用标签近似进行学习,即只使用Teacher Model的预测标签来指导模型学习。
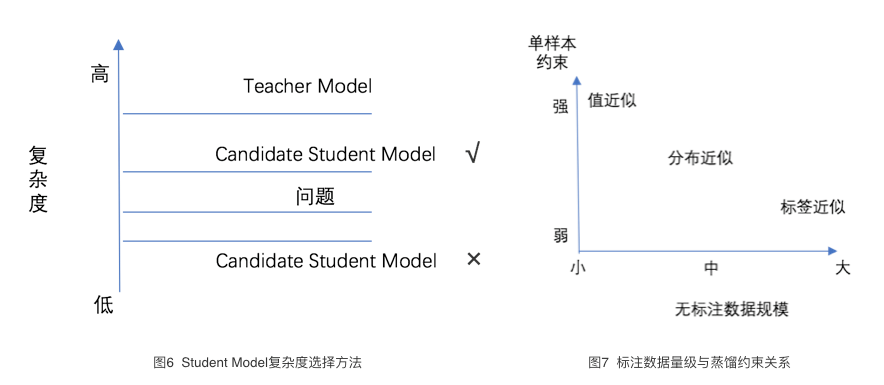
有了上面的结论,我们如何在搜索NER任务中应用模型蒸馏呢?首先先分析一下该任务。与文献中的相关任务相比,搜索NER存在有一个显著不同:作为线上应用,搜索有大量无标注数据。用户查询可以达到千万/天的量级,数据规模上远超一些离线测评能够提供的数据。据此,我们对蒸馏过程进行简化:不限制Student Model的形式,选择主流的推断速度快的神经网络模型对BERT进行近似;训练不使用值近似、分布近似作为学习目标,直接使用标签近似作为目标来指导Student Model的学习。
我们使用IDCNN-CRF来近似BERT实体识别模型,IDCNN(Iterated Dilated CNN)是一种多层CNN网络,其中低层卷积使用普通卷积操作,通过滑动窗口圈定的位置进行加权求和得到卷积结果,此时滑动窗口圈定的各个位置的距离间隔等于1。高层卷积使用膨胀卷积(Atrous Convolution)操作,滑动窗口圈定的各个位置的距离间隔等于d(d>1)。通过在高层使用膨胀卷积可以减少卷积计算量,同时在序列依赖计算上也不会有损失。在文本挖掘中,IDCNN常用于对LSTM进行替换。实验结果表明,相较于原始BERT模型,在没有明显精度损失的前提下,蒸馏模型的在线预测速度有数十倍的提升。
4.1.2 预测加速
BERT中大量小算子以及Attention计算量的问题,使得其在实际线上应用时,预测时长较高。我们主要使用以下三种方法加速模型预测,同时对于搜索日志中的高频Query,我们将预测结果以词典方式上传到缓存,进一步减少模型在线预测的QPS压力。下面介绍下模型预测加速的三种方法:
1. 算子融合:通过降低Kernel Launch次数和提高小算子访存效率来减少BERT中小算子的耗时开销。我们这里调研了Faster Transformer的实现。平均时延上,有1.4x~2x左右加速比;TP999上,有2.1x~3x左右的加速比。该方法适合标准的BERT模型。开源版本的Faster Transformer工程质量较低,易用性和稳定性上存在较多问题,无法直接应用,我们基于NV开源的Faster Transformer进行了二次开发,主要在稳定性和易用性进行了改进:
-
易用性:支持自动转换,支持Dynamic Batch,支持Auto Tuning。
-
稳定性:修复内存泄漏和线程安全问题。
2. Batching:Batching的原理主要是将多次请求合并到一个Batch进行推理,降低Kernel Launch次数、充分利用多个GPU SM,从而提高整体吞吐。在max_batch_size设置为4的情况下,原生BERT模型,可以在将平均Latency控制在6ms以内,最高吞吐可达1300 QPS。该方法十分适合美团搜索场景下的BERT模型优化,原因是搜索有明显的高低峰期,可提升高峰期模型的吞吐量。
3. 混合精度:混合精度指的是FP32和FP16混合的方式,使用混合精度可以加速BERT训练和预测过程并且减少显存开销,同时兼顾FP32的稳定性和FP16的速度。在模型计算过程中使用FP16加速计算过程,模型训练过程中权重会存储成FP32格式,参数更新时采用FP32类型。利用FP32 Master-weights在FP32数据类型下进行参数更新,可有效避免溢出。混合精度在基本不影响效果的基础上,模型训练和预测速度都有一定的提升。
4.2 知识增强的NER
如何将特定领域的外部知识作为辅助信息嵌入到语言模型中,一直是近些年的研究热点。K-BERT[8]、ERNIE[9]等模型探索了知识图谱与BERT的结合方法,为我们提供了很好的借鉴。美团搜索中的NER是领域相关的,实体类型的判定与业务供给高度相关。因此,我们也探索了如何将供给POI信息、用户点击、领域实体词库等外部知识融入到NER模型中。
4.2.1 融合搜索日志特征的Lattice-LSTM
在O2O垂直搜索领域,大量的实体由商家自定义(如商家名、团单名等),实体信息隐藏在供给POI的属性中,单使用传统的语义方式识别效果差。Lattice-LSTM[10]针对中文实体识别,通过增加词向量的输入,丰富语义信息。我们借鉴这个思路,结合搜索用户行为,挖掘Query 中潜在短语,这些短语蕴含了POI属性信息,然后将这些隐藏的信息嵌入到模型中,在一定程度上解决领域新词发现问题。与原始Lattice-LSTM方法对比,识别准确率千分位提升5个点。
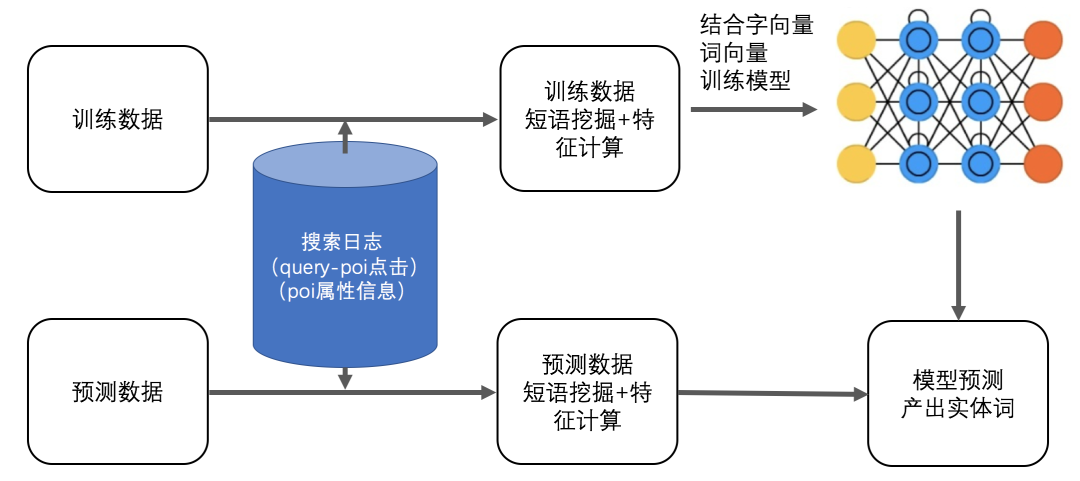
(1)短语挖掘及特征计算
该过程主要包括两步:匹配位置计算、短语生成,下面详细展开介绍。
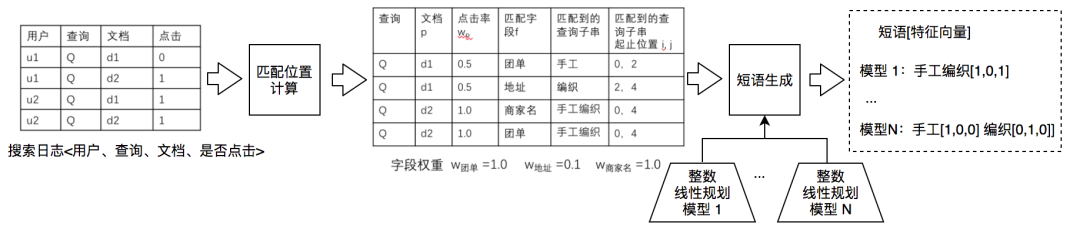
Step1:匹配位置计算。对搜索日志进行处理,重点计算查询与文档字段的详细匹配情况以及计算文档权重(比如点击率)。如图9所示,用户输入查询是“手工编织”,对于文档d1(搜索中就是POI),“手工”出现在字段“团单”,“编织”出现在字段“地址”。对于文档2,“手工编织”同时出现在“商家名”和“团单”。匹配开始位置、匹配结束位置分别对应有匹配的查询子串的开始位置以及结束位置。
Step2:短语生成。以Step1的结果作为输入,使用模型推断候选短语。可以使用多个模型,从而生成满足多个假设的结果。我们将候选短语生成建模为整数线性规划(Integer Linear Programmingm,ILP)问题,并且定义了一个优化框架,模型中的超参数可以根据业务需求进行定制计算,从而获得满足不用假设的结果。
对于一个具体查询Q,每种切分结果都可以使用整数变量xij来表示:xij=1表示查询i到j的位置构成短语,即Qij是一个短语,xij=0表示查询i到j的位置不构成短语。优化目标可以形式化为:在给定不同切分xij的情况下,使收集到的匹配得分最大化。
优化目标及约束函数如图10所示,其中p:文档,f:字段,w:文档p的权重,wf:字段f的权重。xijpf:查询子串Qij是否出现在文档p的f字段,且最终切分方案会考虑该观测证据,Score(xijpf):最终切分方案考虑的观测得分,w(xij):切分Qij对应的权重,yijpf : 观测到的匹配,查询子串Qij出现在文档p的f字段中。χmax:查询包含的最大短语数。这里,χmax、wp、wf 、w(xij)是超参数,在求解ILP问题前需要完成设置,这些变量可以根据不同假设进行设置:可以根据经验人工设置,另外也可以基于其他信号来设置,设置可参考图10给出的方法。最终短语的特征向量表征为在POI各属性字段的点击分布。

(2)模型结构
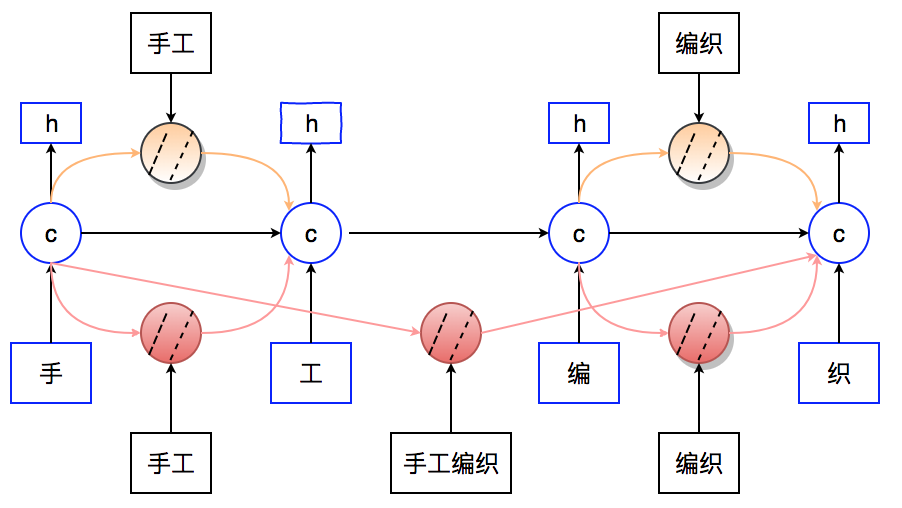
模型结构如图11所示,蓝色部分表示一层标准的LSTM网络(可以单独训练,也可以与其他模型组合),输入为字向量,橙色部分表示当前查询中所有词向量,红色部分表示当前查询中的通过Step1计算得到的所有短语向量。对于LSTM的隐状态输入,主要由两个层面的特征组成:当前文本语义特征,包括当前字向量输入和前一时刻字向量隐层输出;潜在的实体知识特征,包括当前字的短语特征和词特征。下面介绍当前时刻潜在知识特征的计算以及特征组合的方法。(下列公式中,σ表示sigmoid函数,⊙表示矩阵乘法)


4.2.2 融合实体词典的两阶段NER
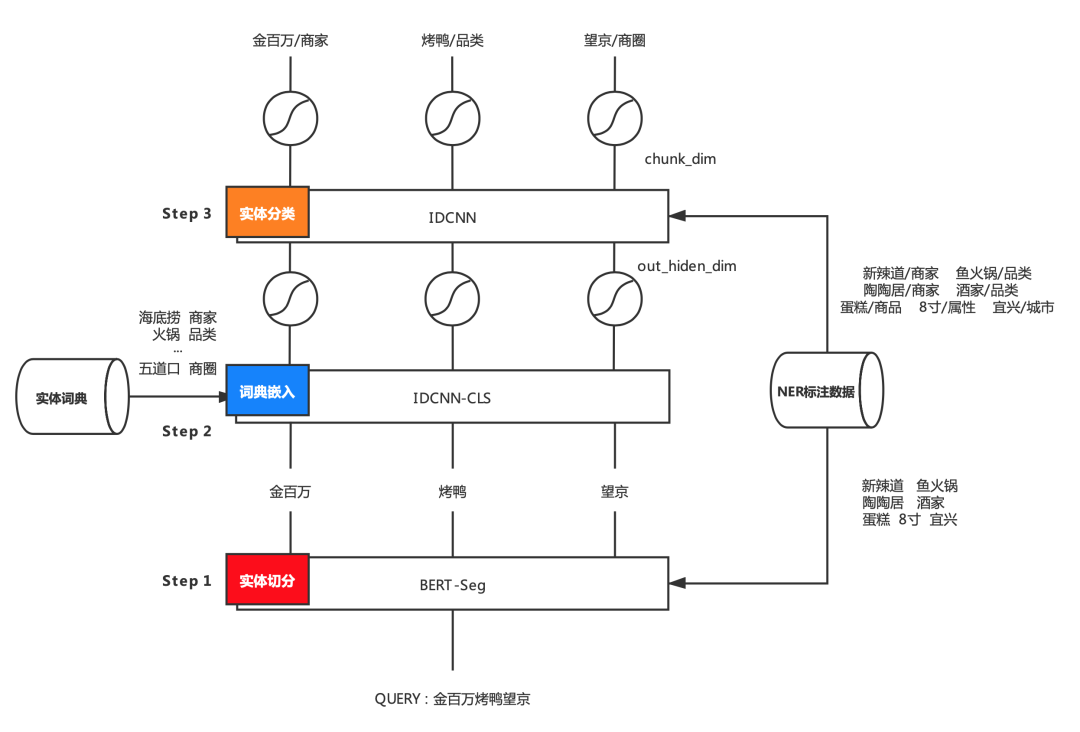
我们考虑将领域词典知识融合到模型中,提出了两阶段的NER识别方法。该方法是将NER任务拆分成实体边界识别和实体标签识别两个子任务。相较于传统的端到端的NER方法,这种方法的优势是实体切分可以跨领域复用。另外,在实体标签识别阶段可以充分使用已积累的实体数据和实体链接等技术提高标签识别准确率,缺点是会存在错误传播的问题。
在第一阶段,让BERT模型专注于实体边界的确定,而第二阶段将实体词典带来的信息增益融入到实体分类模型中。第二阶段的实体分类可以单独对每个实体进行预测,但这种做法会丢失实体上下文信息,我们的处理方法是:将实体词典用作训练数据训练一个IDCNN分类模型,该模型对第一阶段输出的切分结果进行编码,并将编码信息加入到第二阶段的标签识别模型中,联合上下文词汇完成解码。基于Benchmark标注数据进行评估,该模型相比于BERT-NER在Query粒度的准确率上获得了1%的提升。这里我们使用IDCNN主要是考虑到模型性能问题,大家可视使用场景替换成BERT或其他分类模型。
4.3 弱监督NER
针对标注数据难获取问题,我们提出了一种弱监督方案,该方案包含两个流程,分别是弱监督标注数据生成、模型训练。下面详细描述下这两个流程。
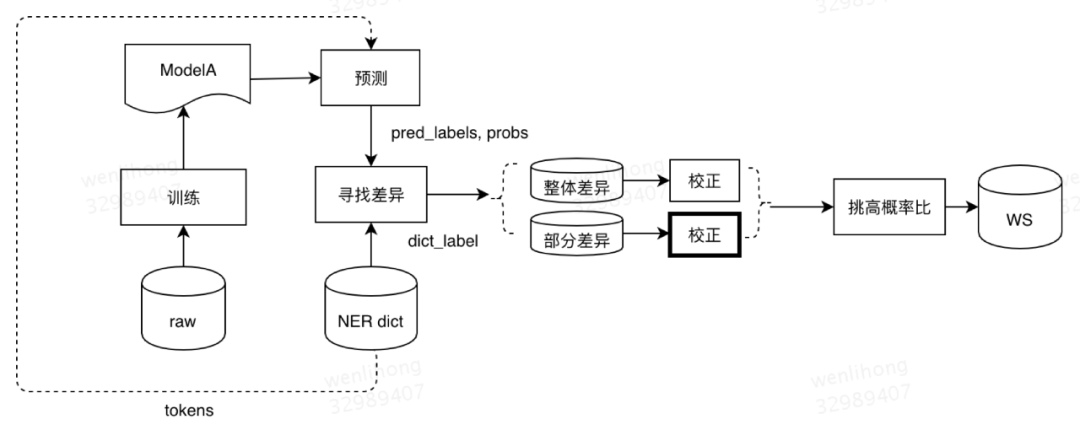
图13 弱监督标注数据生成流程
Step1:弱监督标注样本生成
(1)初版模型:利用已标注的小批量数据集训练实体识别模型,这里使用的是最新的BERT模型,得到初版模型ModelA。
(2)词典数据预测:实体识别模块目前沉淀下百万量级的高质量实体数据作为词典,数据格式为实体文本、实体类型、属性信息。用上一步得到的ModelA预测改词典数据输出实体识别结果。
(3)预测结果校正:实体词典中实体精度较高,理论上来讲模型预测的结果给出的实体类型至少有一个应该是实体词典中给出的该实体类型,否则说明模型对于这类输入的识别效果并不好,需要针对性地补充样本,我们对这类输入的模型结果进行校正后得到标注文本。校正方法我们尝试了两种,分别是整体校正和部分校正,整体校正是指整个输入校正为词典实体类型,部分校正是指对模型切分出的单个Term 进行类型校正。举个例子来说明,“兄弟烧烤个性diy”词典中给出的实体类型为商家,模型预测结果为修饰词+菜品+品类,没有Term属于商家类型,模型预测结果和词典有差异,这时候我们需要对模型输出标签进行校正。校正候选就是三种,分别是“商家+菜品+品类”、“修饰词+商家+品类”、“修饰词+菜品+商家”。我们选择最接近于模型预测的一种,这样选择的理论意义在于模型已经收敛到预测分布最接近于真实分布,我们只需要在预测分布上进行微调,而不是大幅度改变这个分布。那从校正候选中如何选出最接近于模型预测的一种呢?我们使用的方法是计算校正候选在该模型下的概率得分,然后与模型当前预测结果(当前模型认为的最优结果)计算概率比,概率比计算公式如公式2所示,概率比最大的那个就是最终得到的校正候选,也就是最终得到的弱监督标注样本。在“兄弟烧烤个性diy”这个例子中,“商家+菜品+品类”这个校正候选与模型输出的“修饰词+菜品+品类”概率比最大,将得到“兄弟/商家 烧烤/菜品 个性diy/品类”标注数据。

图14 标签校正

Step2:弱监督模型训练
弱监督模型训练方法包括两种:一是将生成的弱监督样本和标注样本进行混合不区分重新进行模型训练;二是在标注样本训练生成的ModelA基础上,用弱监督样本进行Fine-tuning训练。这两种方式我们都进行了尝试。从实验结果来看,Fine-tuning效果更好。
5. 总结和展望
本文介绍了O2O搜索场景下NER任务的特点及技术选型,详述了在实体词典匹配和模型构建方面的探索与实践。
实体词典匹配针对线上头腰部流量,离线对POI结构化信息、商户评论数据、搜索日志等独有数据进行挖掘,可以很好的解决领域实体识别问题,在这一部分我们介绍了一种适用于垂直领域的新词自动挖掘方法。除此之外,我们也积累了其他可处理多源数据的挖掘技术,如有需要可以进行约线下进行技术交流。
模型方面,我们围绕搜索中NER模型的构建的三个核心问题(性能要求高、领域强相关、标注数据缺乏)进行了探索。针对性能要求高采用了模型蒸馏,预测加速的方法, 使得NER 线上主模型顺利升级为效果更好的BERT。在解决领域相关问题上,分别提出了融合搜索日志、实体词典领域知识的方法,实验结果表明这两种方法可一定程度提升预测准确率。针对标注数据难获取问题,我们提出了一种弱监督方案,一定程度缓解了标注数据少模型预测效果差的问题。
未来,我们会在解决NER未登录识别、歧义多义、领域相关问题上继续深入研究,欢迎业界同行一起交流。
6. 参考资料
[1] Automated Phrase Mining from Massive Text Corpora. 2018.
[2] Learning Named Entity Tagger using Domain-Specific Dictionary. 2018.
[3] Bidirectional Encoder Representations from Transformers. 2018
[4] https://www.jiqizhixin.com/articles/2018-12-30
[5] https://naacl2019.org/blog/best-papers/
[6] Hinton et al.Distilling the Knowledge in a Neural Network. 2015.
[7] Yew Ken Chia et al. Transformer to CNN: Label-scarce distillation for efficient text classification. 2018.
[8] K-BERT:Enabling Language Representation with Knowledge Graph. 2019.
[9] Enhanced Language Representation with Informative Entities. 2019.
[10] Chinese NER Using Lattice LSTM. 2018.
7. 作者简介
丽红,星池,燕华,马璐,廖群,志安,刘亮,李超,张弓,云森,永超等,均来自美团搜索与NLP部。
---------- END ----------
招聘信息
美团搜索部,长期招聘搜索、推荐、NLP算法工程师,坐标北京。欢迎感兴趣的同学发送简历至:tech@meituan.com(邮件标题注明:搜索与NLP部)
也许你还想看
| 智能搜索模型预估框架的建设与实践
| Transformer 在美团搜索排序中的实践
| BERT在美团搜索核心排序的探索和实践

最后
以上就是眼睛大小天鹅最近收集整理的关于美团搜索中NER技术的探索与实践的全部内容,更多相关美团搜索中NER技术内容请搜索靠谱客的其他文章。






![[春秋云镜]CVE-2014-3529声明:⽂中所涉及的技术、思路和⼯具仅供以安全为⽬的的学习交流使⽤,任何⼈不得将其⽤于⾮法⽤途以及盈利等⽬的,否则后果⾃⾏承担。所有渗透都需获取授权!靶场介绍](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)

发表评论 取消回复