经过摸索,学习,仿照大佬们的代码,终于折腾出自己的结果。
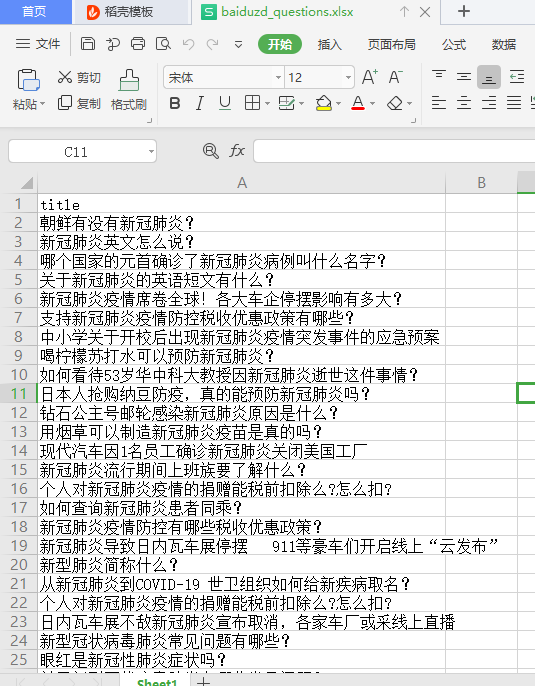
我要处理的文件是这样的:
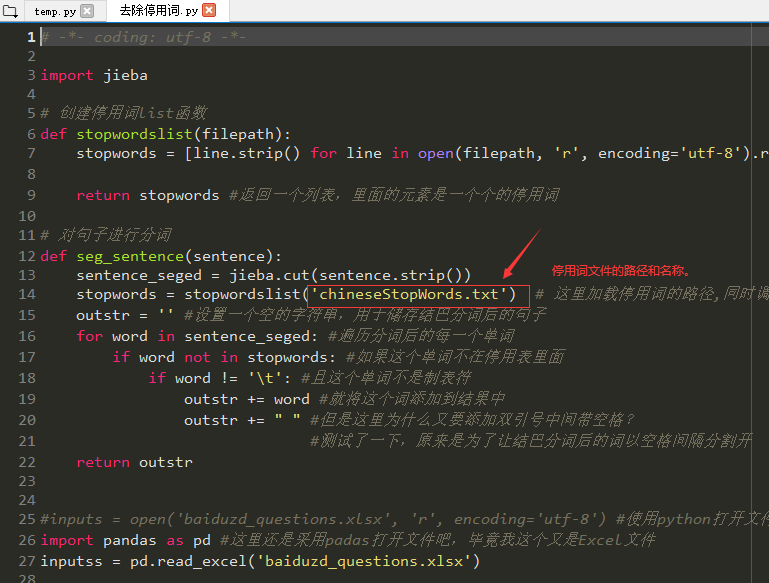
运行无bug的代码放上
import jieba
# 创建停用词list函数
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()] #分别读取停用词表里的每一个词,
#因为停用词表里的布局是一个词一行
return stopwords #返回一个列表,里面的元素是一个个的停用词
# 对句子进行分词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('chineseStopWords.txt') # 这里加载停用词的路径,同时调用上面的stopwordslist()函数
outstr = '' #设置一个空的字符串,用于储存结巴分词后的句子
for word in sentence_seged: #遍历分词后的每一个单词
if word not in stopwords: #如果这个单词不在停用表里面
if word != 't': #且这个单词不是制表符
outstr += word #就将这个词添加到结果中
outstr += " " #但是这里为什么又要添加双引号中间带空格?
#测试了一下,原来是为了让结巴分词后的词以空格间隔分割开
return outstr
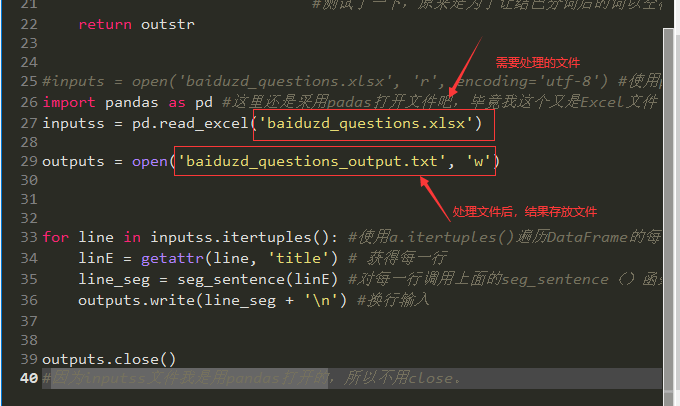
#inputs = open('baiduzd_questions.xlsx', 'r', encoding='utf-8') #使用python打开文件我总会出错,不明白编码的问题是什么>_<
import pandas as pd #这里还是采用padas打开文件吧,毕竟我这个又是Excel文件
inputss = pd.read_excel('baiduzd_questions.xlsx')
outputs = open('baiduzd_questions_output.txt', 'w')
for line in inputss.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, 'title') # 获得每一行
line_seg = seg_sentence(linE) #对每一行调用上面的seg_sentence()函数,返回值是字符串
outputs.write(line_seg + 'n') #换行输入
outputs.close()
#因为inputss文件我是用pandas打开的,所以不用close。
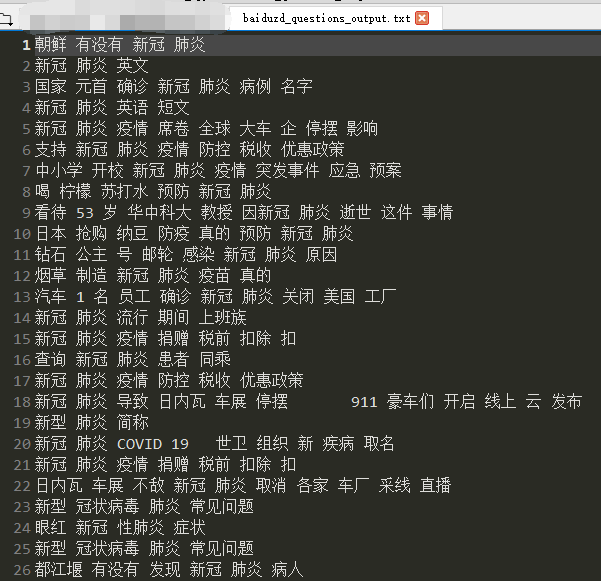
结果如下:
全程下来,需要注意的可能就是python的open函数那里,需要注意下,如果读取失败,则要将txt文件重新保存一次,保存时的编码方式要改为utf-8。
参考博文:https://blog.csdn.net/sinat_26811377/article/details/101691336
最后
以上就是感性斑马最近收集整理的关于文本预处理---批量去除停用词—小白代码详细解释的全部内容,更多相关文本预处理---批量去除停用词—小白代码详细解释内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复