问题原因:编码问题
1、测试code
import chardet
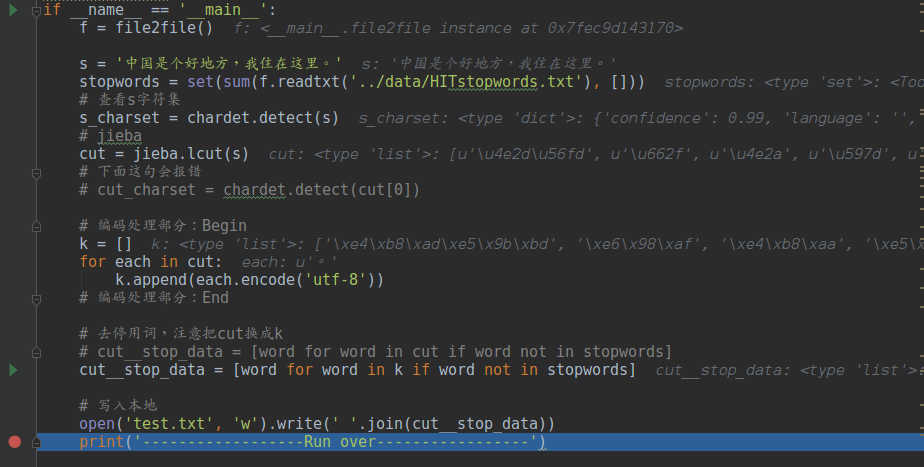
if __name__ == '__main__':
f = file2file()
s = '中国是个好地方,我住在这里。'
stopwords = set(sum(f.readtxt('../data/HITstopwords.txt'), []))
# 查看s字符集
s_charset = chardet.detect(s)
# jieba
cut = jieba.lcut(s)
# 下面这句一直会报错
# cut_charset = chardet.detect(cut[0])
# # 编码处理部分:Begin
# k =[]
# for each in cut:
# k.append(each.encode('utf-8'))
# # 编码处理部分:End
# 去停用词,注意把cut换成k
cut__stop_data = [word for word in cut if word not in stopwords]
# cut__stop_data = [word for word in k if word not in stopwords]
# 写入本地
open('test.txt', 'w').write(' '.join(cut__stop_data))
print('------------------Run over-----------------')
2、code说明
- 如果不去掉注释“编码处理部分”,cut_stop_data中的停用词是去不掉的。写入本地也会报错
- chardet.detect源码,这也是为什么code中那一行会一直报错:
def detect(byte_str):
"""
Detect the encoding of the given byte string.
:param byte_str: The byte sequence to examine.
:type byte_str: ``bytes`` or ``bytearray``
"""
if not isinstance(byte_str, bytearray):
if not isinstance(byte_str, bytes):
raise TypeError('Expected object of type bytes or bytearray, got: '
'{0}'.format(type(byte_str)))
else:
byte_str = bytearray(byte_str)
detector = UniversalDetector()
detector.feed(byte_str)
return detector.close()
3、debug查看上述测试code中的问题
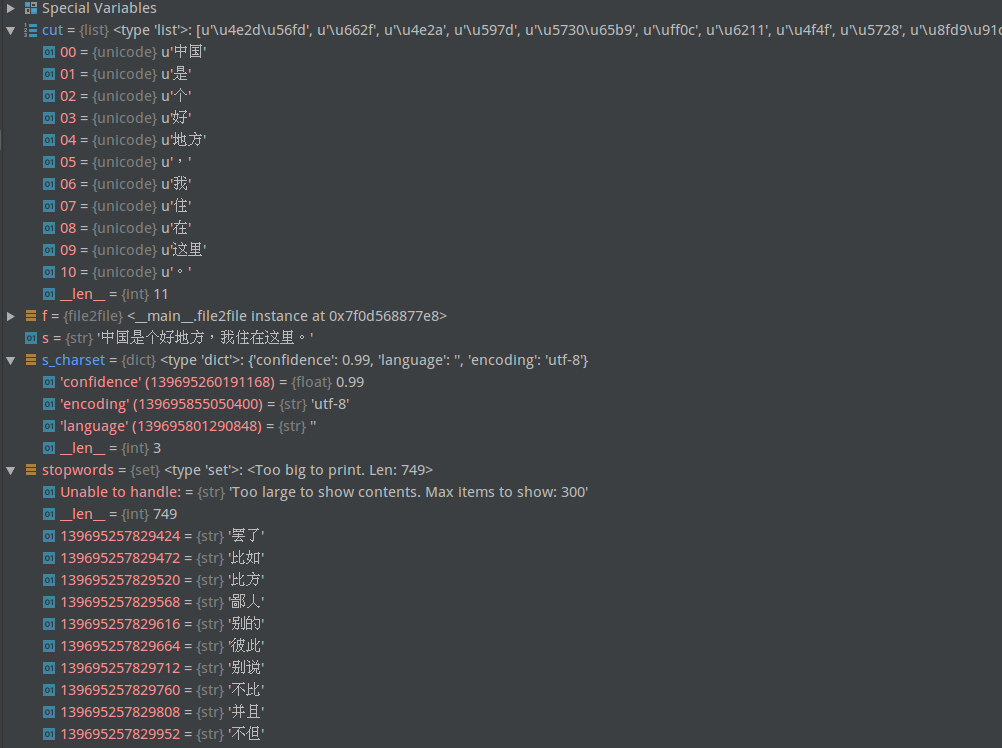
pic1:cut中每个都是unicode,停用词list中则是str,所以无法去掉cut中的停用词
 pic2:jieba后,cut元素为unicode,所以“cut_charset = chardet.detect(cut[0])
pic2:jieba后,cut元素为unicode,所以“cut_charset = chardet.detect(cut[0])
”一直报错
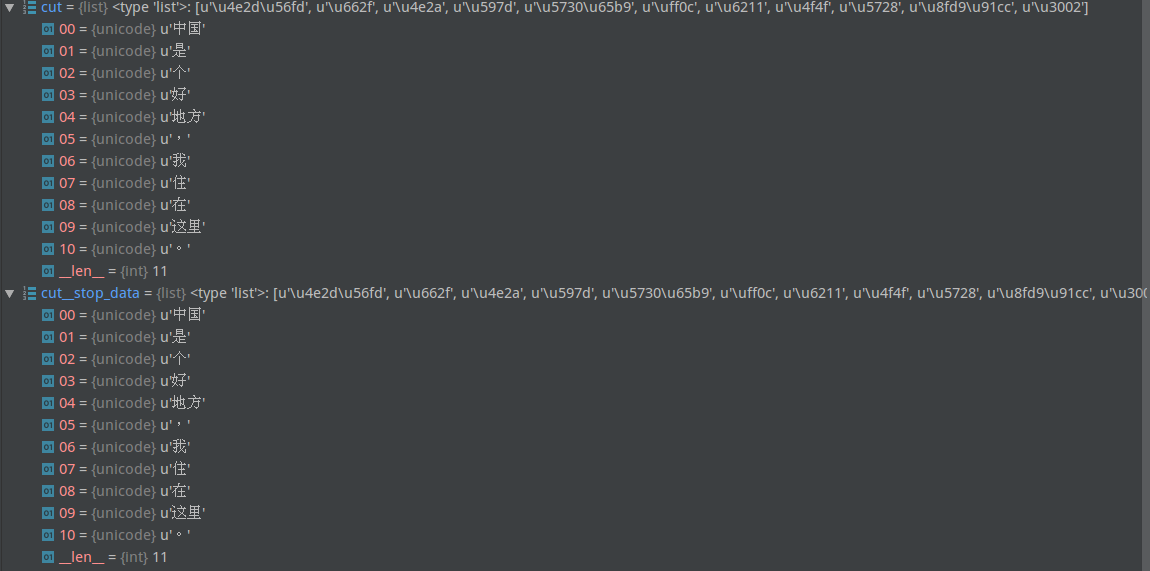 pic3:对比cut和cut_stop_data,停用词确实没有去掉
pic3:对比cut和cut_stop_data,停用词确实没有去掉
 pic4:写入文件时也会报错
pic4:写入文件时也会报错

pic5:去掉注释“编码处理部分”,处理cut中的每一项后,成功去掉了停用词,写入文件也正常
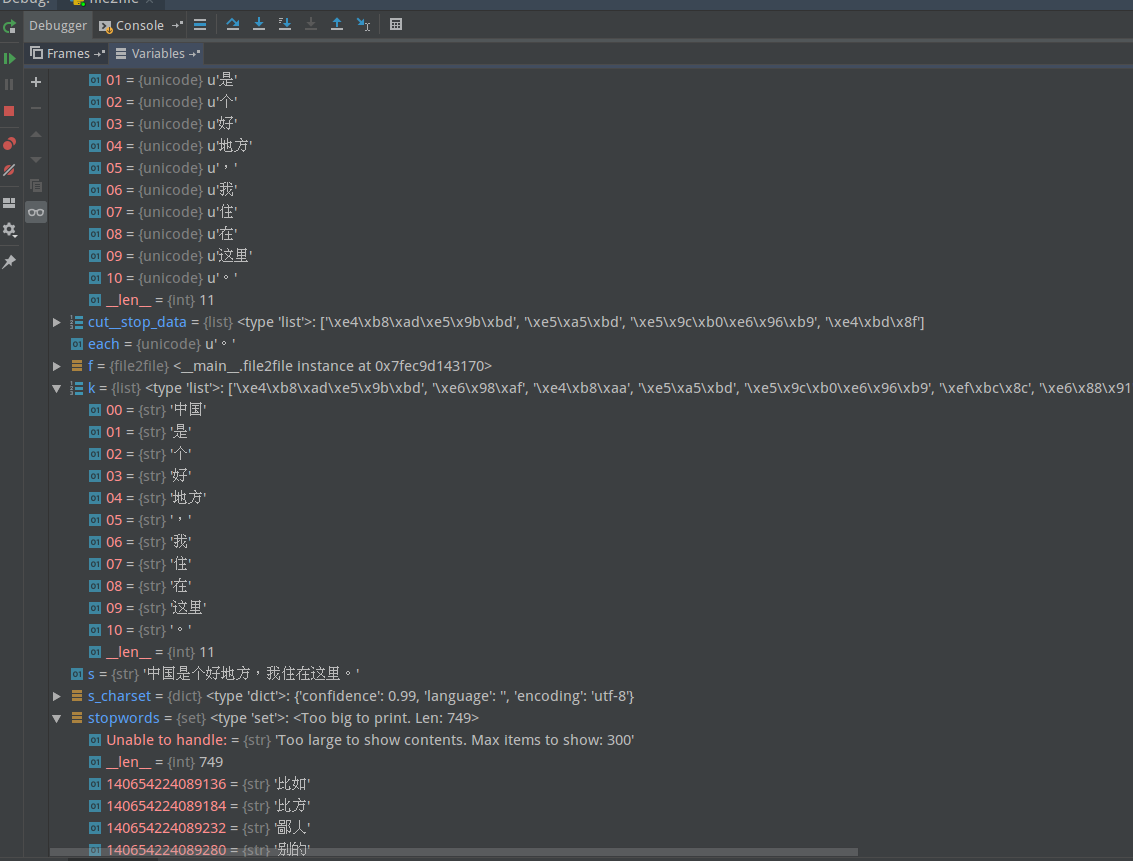 pic6:“编码处理部分”代码效果:
pic6:“编码处理部分”代码效果:
cut–stopwords:去除失败;k–stopwords:去除成功
4、问题根源
分词后,cut中每个都是unicode对象,而不是str对象(见pic7),从上面debug中可见,stopwords中每个都是str对象。
这两个对象,无法比较,所以不处理cut的话,就无法去除cut中的停用词。
这也是写入文件失败的原因。
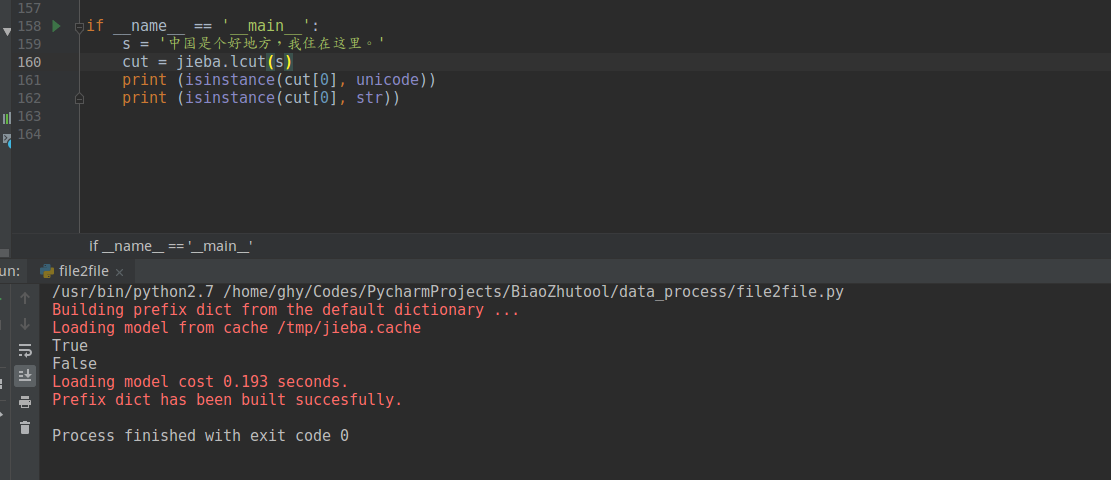 pic7:查看cut元素所属类。结果是unicode,而非str
pic7:查看cut元素所属类。结果是unicode,而非str
5、无误代码截图(去掉上述测试code相应注释即可)
最后
以上就是活力板栗最近收集整理的关于(九)jieba分词后,无法去除停用词的解决方法问题原因:编码问题的全部内容,更多相关(九)jieba分词后,无法去除停用词内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复