1、3.3编程实现对率回归
- 1、数据集
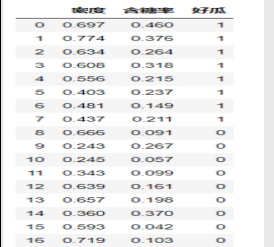
西瓜书89页数据集3.0a
- 2、代码
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression #对率回归
from sklearn import metrics
dataset = pd.read_csv('watermelon3a.csv',encoding='utf-8')
#数据预处理
X = dataset[['密度','含糖率']]
Y = dataset['好瓜']
good_melon = dataset[dataset['好瓜'] == 1]
bad_melon = dataset[dataset['好瓜'] == 0]
#绘制图片
f1 = plt.figure(1)
plt.title('watermelon_3a')
plt.xlabel('density') #x轴坐标密度
plt.ylabel('radio_sugar') #y轴坐标含糖率
plt.xlim(0,1) #范围0-1
plt.ylim(0,1) #范围0-1
plt.scatter(bad_melon['密度'],bad_melon['含糖率'],marker='*',color='r',s=50,label='bad') #散点图
plt.scatter(good_melon['密度'],good_melon['含糖率'],marker='*',color='b',s=50,label='good')
plt.legend(loc='upper right')
#分割训练集和验证集
X_train,X_test,Y_train,Y_test = model_selection.train_test_split(X,Y,test_size=0.3,random_state=0) #选择30%为测试集
#训练
log_model = LogisticRegression() #封装好的对率函数
log_model.fit(X_train,Y_train)
#验证
Y_pred = log_model.predict(X_test)
#汇总结果
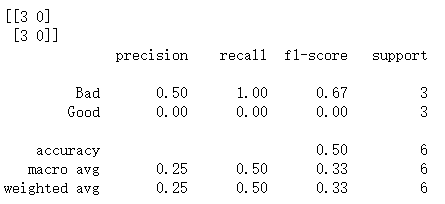
print(metrics.confusion_matrix(Y_test, Y_pred)) #该模块均为sklearn中,计算预测中正确的个数和错误的个数
print(metrics.classification_report(Y_test, Y_pred, target_names=['Bad','Good']))#可以得到准确率、查全率、F1值等
#从上面可以看出好瓜正确率为0,坏瓜准确率为0.67,3个中对了2个
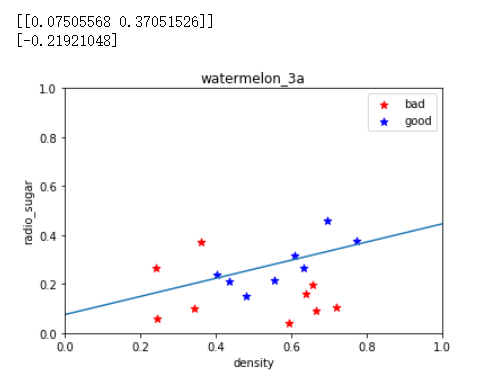
print(log_model.coef_) #w1,w2的值
print(log_model.intercept_) #b
theta1, theta2 = log_model.coef_[0][0], log_model.coef_[0][1]
X_pred = np.linspace(0,1,100)
line_pred = theta1 + theta2 * X_pred
plt.plot(X_pred, line_pred)
plt.show()
- 3、输出结果
预测中正确的个数和错误的个数
准确率、查全率、F1值
系数值与最终的图形
2、3.5线性判别分析
- 1、数据集
西瓜书89页数据集3.0a - 2、理论

- 3、代码复现
#1、输出查全率、f1值等
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis #线性判别分析
from sklearn import model_selection
from sklearn import metrics
dataset = pd.read_csv('watermelon3a.csv',encoding='utf-8')
#数据预处理
X = dataset[['密度','含糖率']]
Y = dataset['好瓜']
#分割训练集和验证集
X_train,X_test,Y_train,Y_test = model_selection.train_test_split(X,Y,test_size=0.3,random_state=0)#仍选取30%作为测试集
#训练
LDA_model = LinearDiscriminantAnalysis()
LDA_model.fit(X_train,Y_train)
#验证
Y_pred = LDA_model.predict(X_test) #同之前的方法类似
#汇总结果
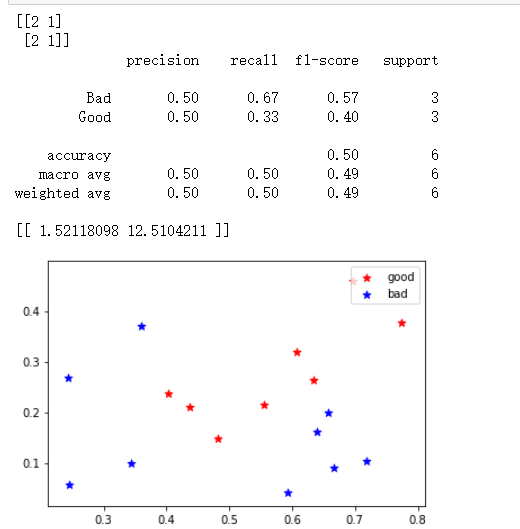
print(metrics.confusion_matrix(Y_test, Y_pred))
print(metrics.classification_report(Y_test, Y_pred, target_names=['Bad','Good']))
print(LDA_model.coef_)
#画图
good_melon = dataset[dataset['好瓜'] == 1]
bad_melon = dataset[dataset['好瓜'] == 0]
plt.scatter(good_melon['密度'],good_melon['含糖率'],marker='*',color='r',s=50,label='good')#注意此处与3.3的颜色有所调换
plt.scatter(bad_melon['密度'],bad_melon['含糖率'],marker='*',color='b',s=50,label='bad')
plt.legend(loc='upper right') #标签
plt.show()
- 输出结果
预测中正确的个数和错误的个数
准确率、查全率、F1值
系数值与最终的图形
#2、线性判别分析(二分类问题),求解w,并绘制相应图片
import numpy as np
import matplotlib.pyplot as plt
data = [[0.697, 0.460, 1],
[0.774, 0.376, 1],
[0.634, 0.264, 1],
[0.608, 0.318, 1],
[0.556, 0.215, 1],
[0.403, 0.237, 1],
[0.481, 0.149, 1],
[0.437, 0.211, 1],
[0.666, 0.091, 0],
[0.243, 0.267, 0],
[0.245, 0.057, 0],
[0.343, 0.099, 0],
[0.639, 0.161, 0],
[0.657, 0.198, 0],
[0.360, 0.370, 0],
[0.593, 0.042, 0],
[0.719, 0.103, 0]]
#数据集按瓜好坏分类
data = np.array([i[:-1] for i in data])
X0 = np.array(data[:8]) #好瓜
X1 = np.array(data[8:]) #坏瓜
#求正反例均值
miu0 = np.mean(X0, axis=0).reshape((-1, 1))
miu1 = np.mean(X1, axis=0).reshape((-1, 1))
#求协方差
cov0 = np.cov(X0, rowvar=False)
cov1 = np.cov(X1, rowvar=False)
#求出w
S_w = np.mat(cov0 + cov1) #类内散度矩阵
Omiga = S_w.I * (miu0 - miu1) #求逆在与均值差相乘
#画出点、直线
plt.scatter(X0[:, 0], X0[:, 1], marker='+',color='r',s=50,label='good')
plt.scatter(X1[:, 0], X1[:, 1], marker='_',color='b',s=50,label='bad')
plt.plot([0, 1], [0, Omiga[0] / Omiga[1]], label='y')
plt.xlabel('密度', fontproperties='SimHei', fontsize=15, color='green');
plt.ylabel('含糖率', fontproperties='SimHei', fontsize=15, color='green');
plt.title(r'LinearDiscriminantAnalysis', fontproperties='SimHei', fontsize=25);
plt.legend()
plt.show()
- 结果为:
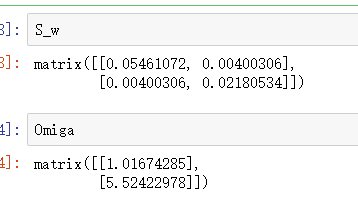
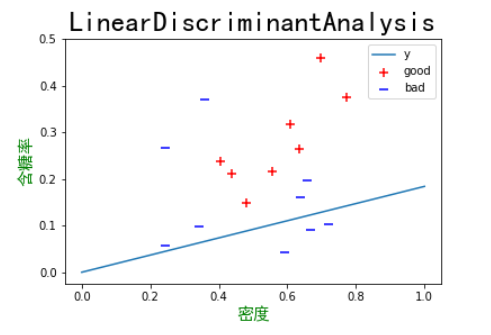
从这两种方法可以看出,线性判别方法比对率回归准确率稍高一些,效果较好,但由于数据量较少的原因,最终的效果并不是特别理想。
第五章 神经网络
3、5.5标准BP与累积BP算法
- 1、数据集
西瓜书数据集3.0
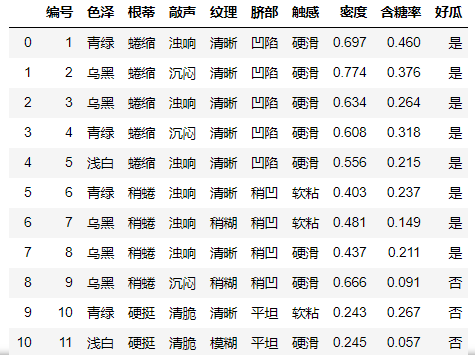
在这里参考某文章,未直接调用数据集。 - 2、理论

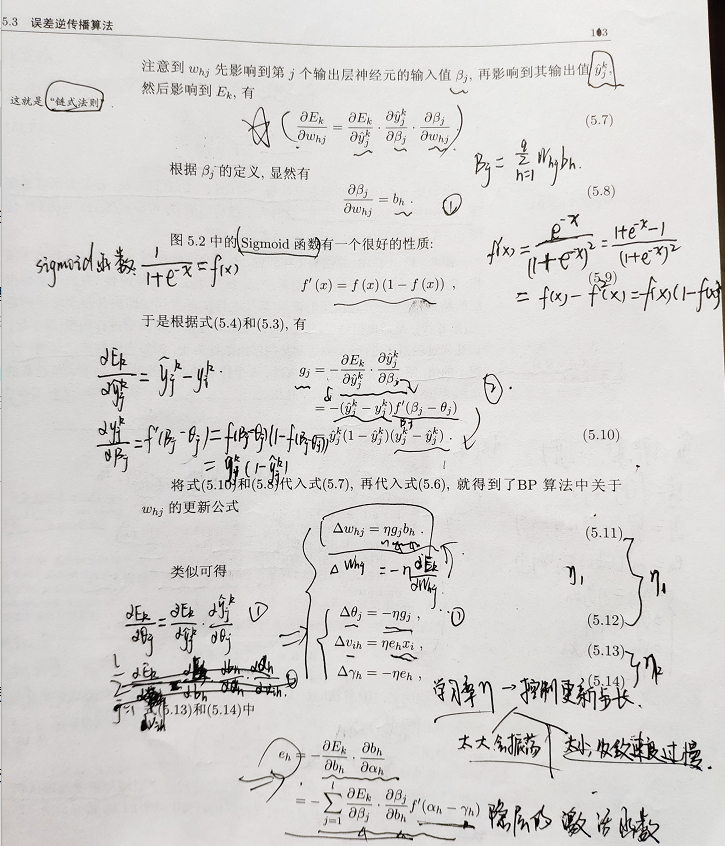

- 3、代码
import numpy as np
def dataSet():
# 西瓜数据集离散化
X = np.mat('2,3,3,2,1,2,3,3,3,2,1,1,2,1,3,1,2;
1,1,1,1,1,2,2,2,2,3,3,1,2,2,2,1,1;
2,3,2,3,2,2,2,2,3,1,1,2,2,3,2,2,3;
3,3,3,3,3,3,2,3,2,3,1,1,2,2,3,1,2;
1,1,1,1,1,2,2,2,2,3,3,3,1,1,2,3,2;
1,1,1,1,1,2,2,1,1,2,1,2,1,1,2,1,1;
0.697,0.774,0.634,0.668,0.556,0.403,0.481,0.437,0.666,0.243,0.245,0.343,0.639,0.657,0.360,0.593,0.719;
0.460,0.376,0.264,0.318,0.215,0.237,0.149,0.211,0.091,0.267,0.057,0.099,0.161,0.198,0.370,0.042,0.103
').T
X = np.array(X) # 样本属性集合,行表示一个样本,列表示一个属性
Y = np.mat('1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0') #判断西瓜好坏,1为好瓜,0为坏瓜
Y = np.array(Y).T # 每个样本对应的标签
return X, Y
# print(X,Y)
# print(type(X))
def sigmod(x):
return 1.0/(1.0+np.exp(-x)) #激活函数选择sigmod(),p98
#1、标准BP就是对每一个输入的X个体,都要更新一下网络
def bpstand(hideNum): # 标准的反向传播算法(误差逆传播算法,BP)
X,Y = dataSet()
V = np.random.rand(X.shape[1],hideNum) # 权值及偏置初始化(输入层—隐层) (8×hideNum)的矩阵
V_b = np.random.rand(1,hideNum) #1×hideNum
W = np.random.rand(hideNum,Y.shape[1]) #(隐层—输出层)hideNum×1
W_b = np.random.rand(1,Y.shape[1])
#初始化
rate = 0.1 #学习率
error = 0.001 #误差阈值
maxTrainNum = 1000000
trainNum = 0
loss = 10 #总损失
while (loss>error) and (trainNum < maxTrainNum):
for k in range(X.shape[0]): # 标准bp方法一次只处理一个样本
H = sigmod(X[k,:].dot(V)-V_b) # 因为书上一直给出的是减去阈值,所以这里用减号。
Y_ = sigmod(H.dot(W)-W_b) # 其实大部分情况下人们都用的是加上偏置b这种表达方式
loss = sum((Y[k]-Y_)**2)*0.5 # 改成加号后只需要在下面更新参数时也用加号即可 (5.4)
g = Y_*(1-Y_)*(Y[k]-Y_) # 计算相应的梯度,及更新参数。 此处特别注意维度的正确对应关系(5.10)
e = H*(1-H)*g.dot(W.T) # (5.15)
W += rate*H.T.dot(g) # (5.11)
W_b -= rate*g # (5.12)
V += rate*X[k].reshape(1,X[k].size).T.dot(e) # (5.13)
V_b -= rate*e # (5.14)
trainNum += 1
print("总训练次数:",trainNum)
print("最终损失:",loss)
print("V:",V)
print("V_b:",V_b)
print("W:",W)
print("W_b:",W_b)
# 2、而累积BP就是把整个X集合都跑一遍,把各种要变化的值累加起来,再更新,
# 累积BP类似于随机梯度下降法,每跑一遍整个集合,更新一次。
def bpAccum(hideNum): # 累积bp算法
X,Y = dataSet()
V = np.random.rand(X.shape[1],hideNum)
V_b = np.random.rand(1,hideNum)
W = np.random.rand(hideNum,Y.shape[1])
W_b = np.random.rand(1,Y.shape[1])
#同上初始化
rate = 0.1
error = 0.001
maxTrainNum = 1000000
trainNum = 0
loss = 10
while (loss>error) and (trainNum<maxTrainNum):
H = sigmod(X.dot(V)-V_b)
Y_ = sigmod(H.dot(W)-W_b)
loss = 0.5*sum((Y-Y_)**2)/X.shape[0] # (5.16)
g = Y_*(1-Y_)*(Y-Y_) # 对应元素相乘,类似于matlab中的点乘
e = H*(1-H)*g.dot(W.T)
W += rate*H.T.dot(g)
W_b -= rate*g.sum(axis=0)
V += rate*X.T.dot(e)
V_b -= rate*e.sum(axis=0)
trainNum += 1
print("总训练次数:",trainNum)
print("最终损失:",loss)
print("V:",V)
print("V_b:",V_b)
print("W:",W)
print("W_b:",W_b)
if __name__ == '__main__':
bpstand(8) #调用BP
bpAccum(8) #调用累积BP
#果然大佬用函数封装,便利多了
- 4、结果:
BP:
总训练次数: 69887
最终损失: [0.00099978]

累积BP:
总训练次数: 5479
最终损失: [0.0009997]
对照次数可以看出:累积BP算法比BP训练的次数要少的多
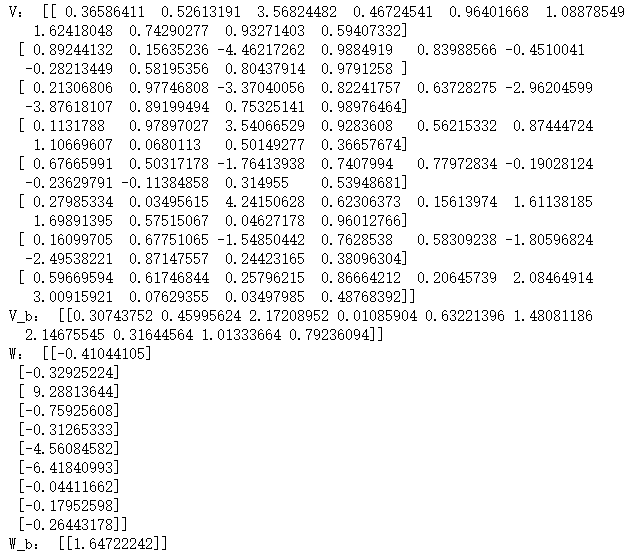
系数差别还是挺大的。
最后
以上就是可爱犀牛最近收集整理的关于西瓜书第三章、第五章课后答案—3.3、3.5、5.51、3.3编程实现对率回归第五章 神经网络的全部内容,更多相关西瓜书第三章、第五章课后答案—3.3、3.5、5.51、3.3编程实现对率回归第五章内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复