主机名 ip 系统 DRBD磁盘
server-00 192.168.103.85 centos6.864bit /dev/sdb1
server-01 192.168.103.86 centos6.8 64bit /dev/sdb1
测试环境介绍(两台一样)
(如下所示,均已关闭防火墙及selinux,生产环境自行开放端口)
关闭防火墙:
service iptables stop
chkconfig iptables off关闭SELinux:
sed -i -e"s/=enforcing/=disabled/g" /etc/selinux/config
setenforce 0
yum install -y make gcc gcc-c++ kernelkernel-devel kernel-headers perl flex telnet重启服务器
安装drbd源码包(两台一样)
将图中的文件通过xftp放入/目录下(自行下载相应包)
tar xf /drbd-8.4.2.tar.gz
cd drbd-8.4.2
./configure --prefix=/usr/local/drbd--with-km #--with-km是启用内核模块
make KDIR=/usr/src/kernels/`uname -r`/ # 自动识别内核版本
make install
mkdir -p /usr/local/drbd/var/run/drbd
cp /usr/local/drbd/etc/rc.d/init.d/drbd/etc/rc.d/init.d
chmod 755 /etc/init.d/drbd#安装drbd模块
#drbd是作为内核模块运行的,但是我们在安装的时候程序并没有创建相应的内核模块,故需要我另行创建drbd模块,并载入内核。
cd drbd
make clean
make KDIR=/usr/src/kernels/`uname -r`/
cp drbd.ko /lib/modules/`uname-r`/kernel/lib/
modprobe drbd #执行命令加载drbd模块到内核检查是否加载了drbd模块

DRBD配置,配置之前需要先使用fdisk对 /dev/sdb进行分区
fdisk /dev/sdb
n
p
1
w在/etc/fstab里面注释一项:

要保证两个节点之间可以相互解析,在两台节点上分别配置hosts文件
修改/etc/hosts文件,两台服务器操作一样。
vim /etc/hosts
如果主机名与测试的主机名不一至,会报错,所以需要先改主机名。修改主机名的方法如下:
1、首先有一个治标不治本的方法,就是执行:hostname 新名称
ok logout 后在进入 主机名就换了,但是这个方法是临时修改的,重启后名称就会恢复回去
2、永久修改主机名
第一步:
#hostname secondNamenode第二步:
修改/etc/sysconfig/network中的hostname
第三步:
修改/etc/hosts文件
# uname -n 查看当前的主机名vim /usr/local/drbd/etc/drbd.d/global_common.confvim /usr/local/drbd/etc/drbd.d/global_common.conf
写入:
global {
usage-count no;
}
common { syncer { rate 30M; } }
resource r0 {
protocol C;
startup {
}
disk{
on-io-error detach;
}
net {
cram-hmac-alg"sha1";
shared-secret"abc";
}
onserver-00 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.103.85:7888;
meta-disk internal;
}
onserver-01 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.103.86:7888;
meta-disk internal;
}
}然后:
dd if=/dev/zero of=/dev/sdb1 bs=1M count=100
drbdadm create-md r0DRBD的启动与状态查看(分别在两台服务器启动)
[root@192.168.103.85 ~]# /etc/init.d/drbd start
Starting DRBD resources: [
create res: r0
prepare disk: r0
adjust disk: r0
adjust net: r0
]
.....
[root@192.168.103.86 ~]# /etc/init.d/drbd start
Starting DRBD resources: [
create res: r0
prepare disk: r0
adjust disk: r0
adjust net: r0
]
.查看drbd的状态:
[root@192.168.103.85 ~]# /etc/init.d/drbd status
drbd driver loaded OK; device status:
version: 8.4.2 (api:1/proto:86-101)
GIT-hash: 7ad5f850d711223713d6dcadc3dd48860321070c build by root@db-server-01, 2014-04-18 21:15:57
m:res cs ro ds p mounted fstype
0:r0 Connected Secondary/Secondary Inconsistent/Inconsistent C将85设为主机,85上执行指令:
drbdadm -- --overwrite-data-of-peer primary all
mount /dev/drbd0 /data/注意:在drbd从服务器上只需要创建挂载目录即可,不能同时进行挂载,否则会报错。即只有drbd的主服务器挂载目录,从不挂载,在进行故障迁移升级为主时才需要挂载。等待同步完成。
源码重装mysql(两台一样)
tar xf /mysql-5.5.37-linux2.6-x86_64.tar.gz -C /usr/local/
cd /usr/local/
ln -s mysql-5.5.37-linux2.6-x86_64/ mysql
groupadd mysql
useradd -r -g mysql mysql
cd mysql
chown -R mysql .
chgrp -R mysql .
mkdir /data/mysql
chown -R mysql.mysql /data/mysql/
/usr/local/mysql/scripts/mysql_install_db --user=mysql --datadir=/data/mysql/ --basedir=/usr/local/mysql
chown -R root .
cp support-files/my-medium.cnf /etc/my.cnf
cp support-files/mysql.server /etc/init.d/mysqld
chmod 755 /etc/init.d/mysqld
vim /etc/my.cnf写入:
datadir=/data/mysql
basedir=/usr/local/mysql 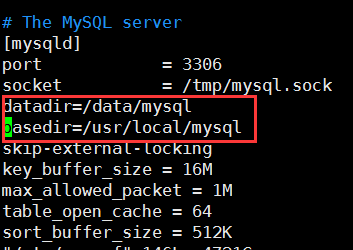
yum install mysql-libs -yHeartbeat安装(两台服务器)
rpm -ivh epel-release-6-8.noarch.rpm
yum install heartbeat -y创建DRBD脚本文件drbddisk:(两台服务器)
vim /etc/ha.d/resource.d/drbddisk写入:
#!/bin/bash
#
# This script is inteded to be used as resource script by heartbeat
#
# Copright 2003-2008 LINBIT Information Technologies
# Philipp Reisner, Lars Ellenberg
#
###
DEFAULTFILE="/etc/default/drbd"
DRBDADM="/sbin/drbdadm"
if [ -f $DEFAULTFILE ]; then
. $DEFAULTFILE
fi
if [ "$#" -eq 2 ]; then
RES="$1"
CMD="$2"
else
RES="all"
CMD="$1"
fi
## EXIT CODES
# since this is a "legacy heartbeat R1 resource agent" script,
# exit codes actually do not matter that much as long as we conform to
# http://wiki.linux-ha.org/HeartbeatResourceAgent
# but it does not hurt to conform to lsb init-script exit codes,
# where we can.
# http://refspecs.linux-foundation.org/LSB_3.1.0/
#LSB-Core-generic/LSB-Core-generic/iniscrptact.html
####
drbd_set_role_from_proc_drbd()
{
local out
if ! test -e /proc/drbd; then
ROLE="Unconfigured"
return
fi
dev=$( $DRBDADM sh-dev $RES )
minor=${dev#/dev/drbd}
if [[ $minor = *[!0-9]* ]] ; then
# sh-minor is only supported since drbd 8.3.1
minor=$( $DRBDADM sh-minor $RES )
fi
if [[ -z $minor ]] || [[ $minor = *[!0-9]* ]] ; then
ROLE=Unknown
return
fi
if out=$(sed -ne "/^ *$minor: cs:/ { s/:/ /g; p; q; }" /proc/drbd); then
set -- $out
ROLE=${5%/**}
: ${ROLE:=Unconfigured} # if it does not show up
else
ROLE=Unknown
fi
}
case "$CMD" in
start)
# try several times, in case heartbeat deadtime
# was smaller than drbd ping time
try=6
while true; do
$DRBDADM primary $RES && break
let "--try" || exit 1 # LSB generic error
sleep 1
done
;;
stop)
# heartbeat (haresources mode) will retry failed stop
# for a number of times in addition to this internal retry.
try=3
while true; do
$DRBDADM secondary $RES && break
# We used to lie here, and pretend success for anything != 11,
# to avoid the reboot on failed stop recovery for "simple
# config errors" and such. But that is incorrect.
# Don't lie to your cluster manager.
# And don't do config errors...
let --try || exit 1 # LSB generic error
sleep 1
done
;;
status)
if [ "$RES" = "all" ]; then
echo "A resource name is required for status inquiries."
exit 10
fi
ST=$( $DRBDADM role $RES )
ROLE=${ST%/**}
case $ROLE in
Primary|Secondary|Unconfigured)
# expected
;;
*)
# unexpected. whatever...
# If we are unsure about the state of a resource, we need to
# report it as possibly running, so heartbeat can, after failed
# stop, do a recovery by reboot.
# drbdsetup may fail for obscure reasons, e.g. if /var/lock/ is
# suddenly readonly. So we retry by parsing /proc/drbd.
drbd_set_role_from_proc_drbd
esac
case $ROLE in
Primary)
echo "running (Primary)"
exit 0 # LSB status "service is OK"
;;
Secondary|Unconfigured)
echo "stopped ($ROLE)"
exit 3 # LSB status "service is not running"
;;
*)
# NOTE the "running" in below message.
# this is a "heartbeat" resource script,
# the exit code is _ignored_.
echo "cannot determine status, may be running ($ROLE)"
exit 4 # LSB status "service status is unknown"
;;
esac
;;
*)
echo "Usage: drbddisk [resource] {start|stop|status}"
exit 1
;;
esac
exit 0chmod 755 /etc/ha.d/resource.d/drbddisk
Authkerys的配置(两台服务器配置一样)
vim /etc/ha.d/authkeys写入:
auth 2 # 采用何种加密方式
#1 crc # 无加密
2 sha1 HI! # 启用sha1的加密方式
#3 md5 Hello! # 采用md5的加密方式 chmod 600 /etc/ha.d/authkeysha.cf的配置(两台机器稍微有点区别),Primary(192.168.103.85)如下:
vim /etc/ha.d/ha.cf写入:
debugfile /var/log/ha-debug #调试日志文件
logfile /var/log/ha-log #系统运行日志文件
logfacility local0 #日志记录等级
keepalive 2
#心跳频率,2表示2秒;200ms则表示200毫秒
deadtime 15
#节点死亡时间,就是过了15秒后还没有收到心跳就认为主节点死亡
#bcast eth1 #采用udp广播播来通知心跳,建议在备用节点不只一台时使用
#mcast eth1 225.0.0.1 694 1 0 #采用udp多播来通知心跳,建议在备用节点不只一台时使用
#ucast eth1 10.0.0.64 #采用udp单播来通知心跳,注意:这一项在2个节点IP
ucast eth0 192.168.103.86
#采用单播的方式,IP地址指定为对方IP
auto_failback off
#当Primary机器发生故障切换到Secondary机器后Primary恢复后是否进行切回操作 (最好是我们根据需求手动进行切换)
node server-00 #主节点名称,与uname -n显示必须一致,不是域名
node server-01 #备用节点名称Secondary(192.168.103.86)如下:
vim /etc/ha.d/ha.cf写入:
logfile /var/log/ha-log
#定义Heartbeat的日志名字及位置
logfacility local0
keepalive 2
#设定心跳(监测)时间为2秒
deadtime 15
#设定死亡时间为15秒
ucast eth1 192.168.103.85
#采用单播的方式,IP地址指定为对方IP
auto_failback off
#当Primary机器发生故障切换到Secondary机器后Primary恢复后是否进行切回操作(一般我们可以看需求,否则不用自动切换)
node server-00
node server-01haresources的配置(两台机器配置一样):
vim /etc/ha.d/haresources写入:
server-00 192.168.103.90 drbddisk::r0 Filesystem::/dev/drbd0::/data::ext4 mysqld tomcat通过xftp将图中三个文件放入/etc/ha.d/resource.d目录下
修改权限: chmod 755 mysqld
chmod 755 tomcat
chmod 755 ywproxy.sh
然后需要做如下操作(两台服务器):
chkconfig mysqld off
chkconfig heartbeat off
chkconfig drbd off
vim /etc/rc.local
#/start_proxy.sh
末尾写入:
modprobe drbd #必须先加载模块,这也是因为将启动命令放在这里的原因
/etc/init.d/drbd start
/etc/init.d/heartbeat start监控mysql脚本:
对于mysqld服务挂掉的情况无法实现自动切换,所以需要一个脚本来帮助我们完成,我这里有个简单的脚本,能实现当mysqld服务不可用时进行自动切换,当进行切换时发送邮件等。该脚本放在主服务器执行,也就是运行mysqld服务的服务器上执行。
vim mysqlmon.sh
写入:
#!/bin/bash
trap 'echo PROGRAM INTERRUPTED; exit 1' INT
username=root
password=123456
n=0
log='/var/log/mysqlmon.log'
while true
do
if /usr/local/mysql/bin/mysql -u${username} -p${password} -e "use test" >&/dev/null
then
echo "`date +"%Y-%m-%d %H:%M:%S"` mysqld is alive! " >> ${log}
n=0
else
echo "`date +"%Y-%m-%d %H:%M:%S"` mysqld cannot be connected!" >> ${log}
n=$[n + 1]
if [ $n -eq 3 ]
then
/etc/init.d/heartbeat stop
echo "`date +"%Y-%m-%d %H:%M:%S"` mysqld switched to backup!" >> ${log}
break
fi
fi
sleep 10
done
挂在后台执行:
chmod 755 mysqlmon.sh
setsid ./mysqlmon.sh &监控tomcat脚本:
vim tomcatmon.sh
写入:
#!/bin/bash
n=0
log='/var/log/tomcatmon.log'
while true
do
tomcat=`ps -ef |grep tomcat |awk '{if($3==1)print $3}'`
if [ "$tomcat" = "" ];then
n=$[n + 1]
echo "`date +"%Y-%m-%d %H:%M:%S"` tomcat cannot be connected!" >> ${log}
/etc/init.d/heartbeat stop
elif [ "$tomcat" = "1" ];then
n=$[n + 1]
echo "`date +"%Y-%m-%d %H:%M:%S"` tomcat cannot be connected!" >> ${log}
/etc/init.d/heartbeat stop
else
n=0
echo "`date +"%Y-%m-%d %H:%M:%S"` tomcat is alive! " >> ${log}
fi
sleep 10
done
挂在后台执行:
chmod 755 tomcatmon.sh
setsid ./tomcatmon.sh &测试
两台机器重启setsid ./mysqlmon.sh &
setsid ./tomcatmon.sh &
ip addr | grep eth0
关闭主机的mysql服务
/etc/init.d/mysqld stop发现备机启动了mysql、tomcat,即为成功。
最后
以上就是欢喜项链最近收集整理的关于heartbeat+drbd+mysql双机热备部署文档测试环境介绍(两台一样)安装drbd源码包(两台一样)源码重装mysql(两台一样)Heartbeat安装(两台服务器)监控tomcat脚本:测试的全部内容,更多相关heartbeat+drbd+mysql双机热备部署文档测试环境介绍(两台一样)安装drbd源码包(两台一样)源码重装mysql(两台一样)Heartbeat安装(两台服务器)监控tomcat脚本内容请搜索靠谱客的其他文章。








发表评论 取消回复