圈圈
1. relu:用极简的方式实现非线性激活,还缓解了梯度消失
x = max(x, 0)
2. normalization:提高网络训练稳定性
x = (x - x.mean()) / x.std()
3. gradient clipping:直击靶心 避免梯度爆炸hhh
grad [grad > THRESHOLD] = THRESHOLD # THRESHOLD是设定的最大梯度阈值
4. dropout:随机丢弃,抑制过拟合,提高模型鲁棒性
x = torch.nn.functional.dropout(x, p=p, training=training) # 哈哈哈调皮了,因为实际dropout还有很多其他操作
# 不够仅丢弃这一步确实可以一行搞定
x = x * np.random.binomial(n=1, p=p, size=x.shape) # 这里p是想保留的概率,上面那是丢弃的概率
5. skip connection(residual learning):提供恒等映射的能力,保证模型不会因网络变深而退化
F(x) = F(x) + x
6. focal loss:用预测概率对不同类别的loss进行加权,缓解类别不平衡问题
loss = -np.log(p) # 原始交叉熵损失, p是模型预测的真实类别的概率,
loss = (1-p)**GAMMA * loss # GAMMA是调制系数
7. attention mechanism:用query和原始特征的相似度对原始特征进行加权,关注想要的信息
attn = torch.softmax(torch.matmul(q, k), dim) #用Transformer里KQV那套范式为例
v = torch.matmul(attn, v)
8. subword embedding(char或char ngram):基本解决OOV(out of vocabulary)问题、分词问题。这个对encode应该比较有效,但对decode不太友好
x = [char for char in sentence] # char-level
Smarter
前面两位高赞的回答的很好了,我就补充一下自己知道的。尽量避开优化器、激活函数、数据增强等改进。。
Deep Learning: Cyclic LR、Flooding
Image classification: ResNet、GN、Label Smoothing、ShuffleNet
Object Detection: Soft-NMS、Focal Loss、GIOU、OHEM
Instance Segmentation: PointRend
Domain Adaptation: BNM
GAN: Wasserstein GAN
Deep Learning
Standard LR -> Cyclic LR
SNAPSHOT ENSEMBLES: TRAIN 1, GET M FOR FREE
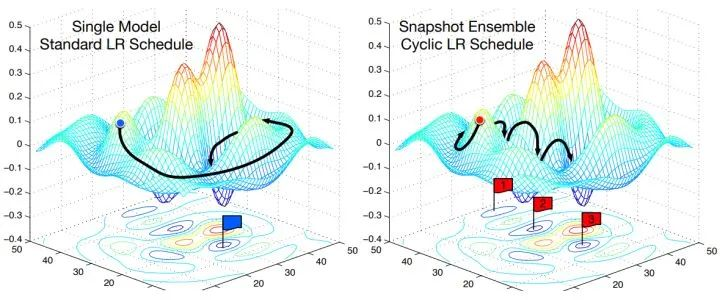
每隔一段时间重启学习率,这样在单位时间内能收敛到多个局部最小值,可以得到很多个模型做集成。
#CYCLE=8000, LR_INIT=0.1, LR_MIN=0.001
scheduler = lambda x: ((LR_INIT-LR_MIN)/2)*(np.cos(PI*(np.mod(x-1,CYCLE)/(CYCLE)))+1)+LR_MINWithout Flooding -> With Flooding
Do We Need Zero Training Loss After Achieving Zero Training Error?
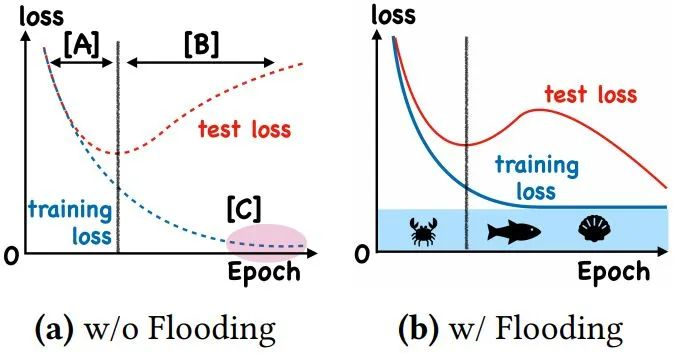
Flooding方法:当training loss大于一个阈值时,进行正常的梯度下降;当training loss低于阈值时,会反过来进行梯度上升,让training loss保持在一个阈值附近,让模型持续进行“random walk”,并期望模型能被优化到一个平坦的损失区域,这样发现test loss进行了double decent!
flood = (loss - b).abs() + bImage classification
VGGNet -> ResNet
Deep Residual Learning for Image Recognition
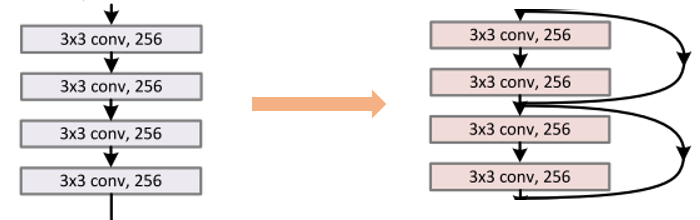
ResNet相比于VGGNet多了一个skip connect,网络优化变的更加容易
H(x) = F(x) + xBN -> GN
Group Normalization
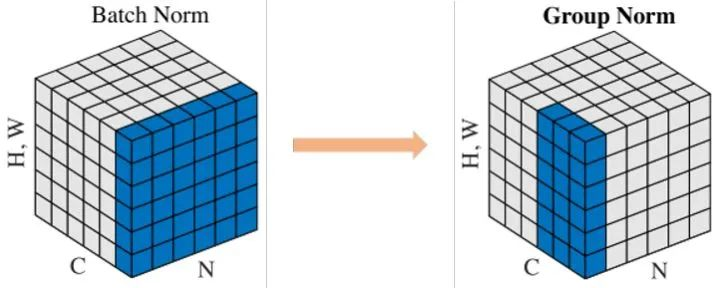
在小batch size下BN掉点严重,而GN更加鲁棒,性能稳定。
x = x.view(N, G, -1)
mean, var = x.mean(-1, keepdim=True), x.var(-1, keepdim=True)
x = (x - mean) / (var + self.eps).sqrt()
x = x.view(N, C, H, W)Hard Label -> Label Smoothing
Bag of Tricks for Image Classification with Convolutional Neural Networks
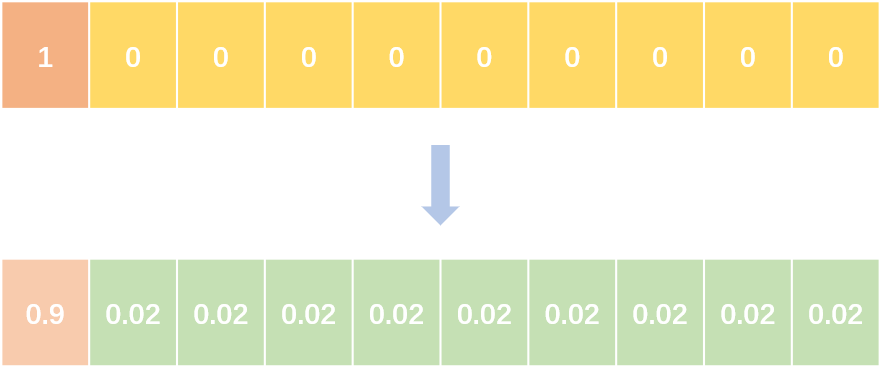
label smoothing将hard label转变成soft label,使网络优化更加平滑。
targets = (1 - label_smooth) * targets + label_smooth / num_classesMobileNet -> ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
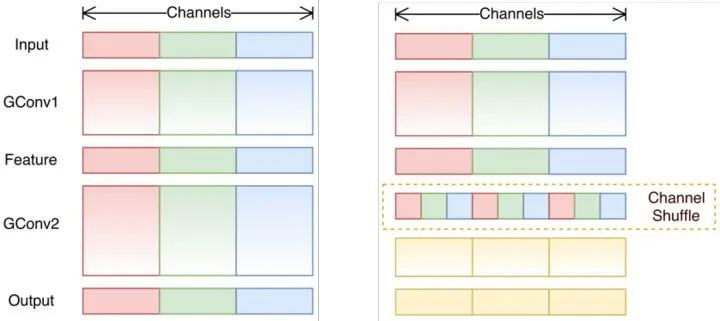
将组卷积的输出feature map的通道顺序打乱,增加不同组feature map的信息交互。
channels_per_group = num_channels // groups
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(batch_size, -1, height, width)Object Detection
NMS -> Soft-NMS
Improving Object Detection With One Line of Code
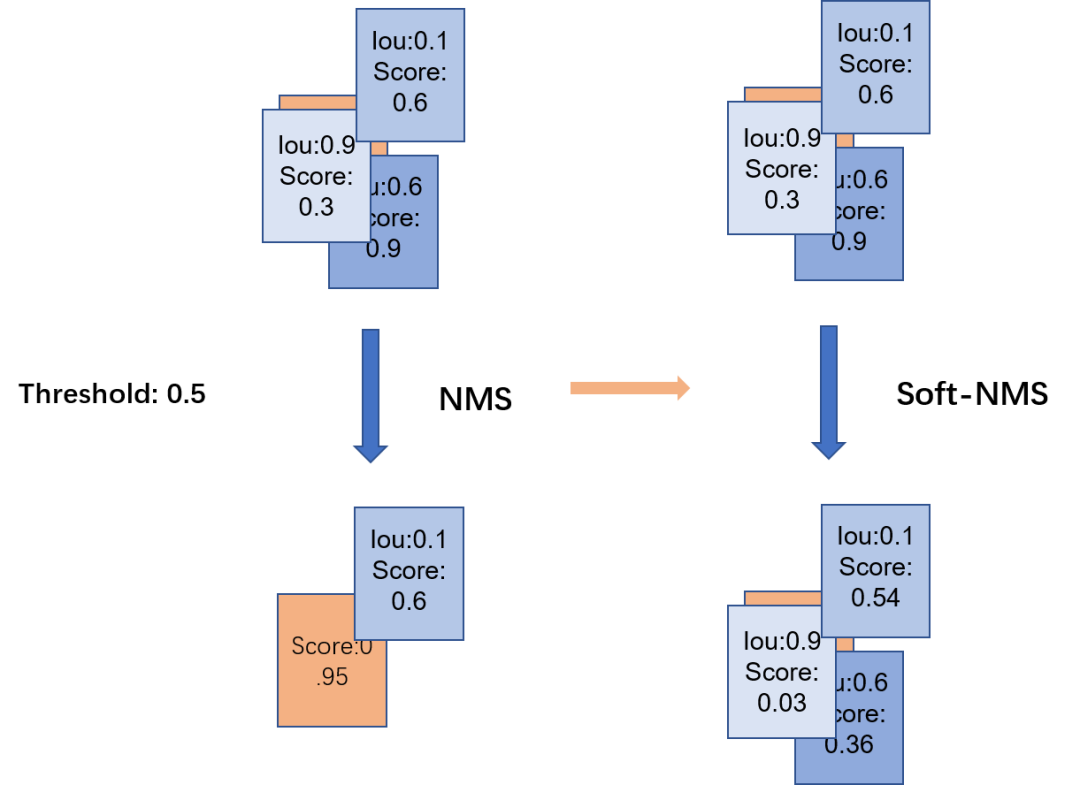
Soft-NMS将重叠率大于设定阈值的框分类置信度降低,而不是直接置为0,可以增加召回率。
#以线性降低分类置信度为例
if iou > threshold:
weight = 1 - iouCE Loss -> Focal Loss
Focal Loss for Dense Object Detection
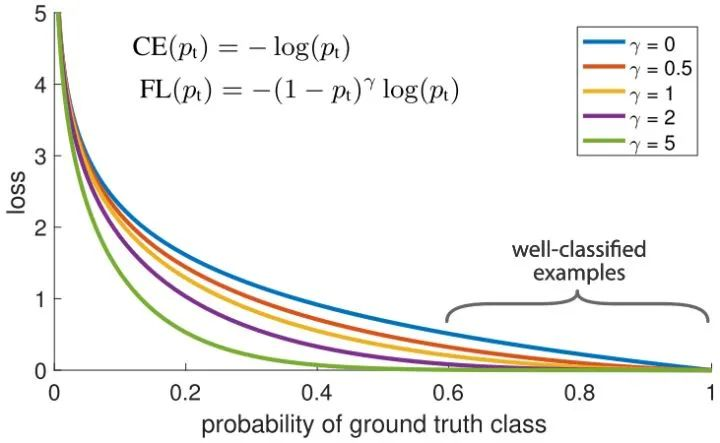
Focal loss对CE loss增加了一个调制系数来降低容易样本的权重值,使得训练过程更加关注困难样本。
loss = -np.log(p) # 原始交叉熵损失, p是模型预测的真实类别的概率,
loss = (1-p)**GAMMA * loss # GAMMA是调制系数IOU -> GIOU
Generalized Interp over Union: A Metric and A Loss for Bounding Box Regression
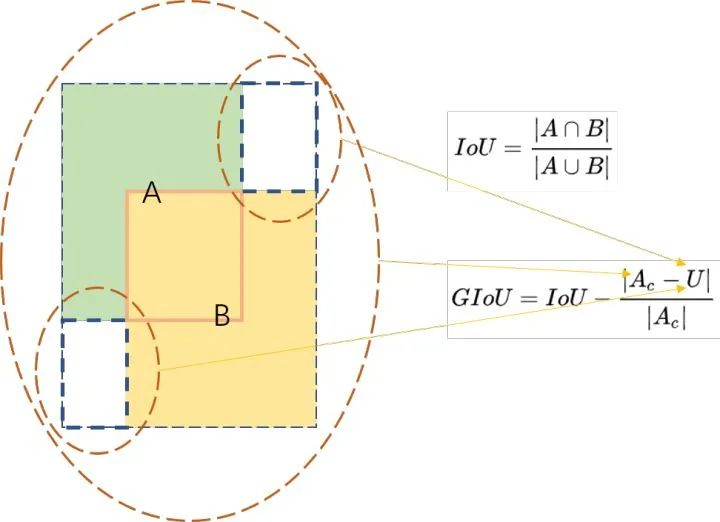
GIOU loss避免了IOU loss中两个bbox不重合时Loss为0的情况,解决了IOU loss对物体大小敏感的问题。
#area_C闭包面积,add_area并集面积
end_area = (area_C - add_area)/area_C #闭包区域中不属于两个框的区域占闭包区域的比重
giou = iou - end_areaHard Negative Mining -> OHEM
Training Region-based Object Detectors with Online Hard Example Mining
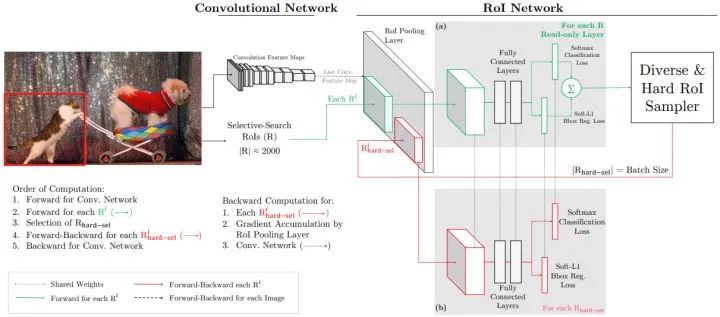
OHEM通过选择损失较大的候选ROI进行梯度更新解决类别不平衡问题。
#只对难样本产生的loss更新
index = torch.argsort(loss.sum(1))[int(num * ohem_rate):]
loss = loss[index, :]Instance Segmentation
Mask R-CNN -> PointRend
PointRend: Image Segmentation as Rendering
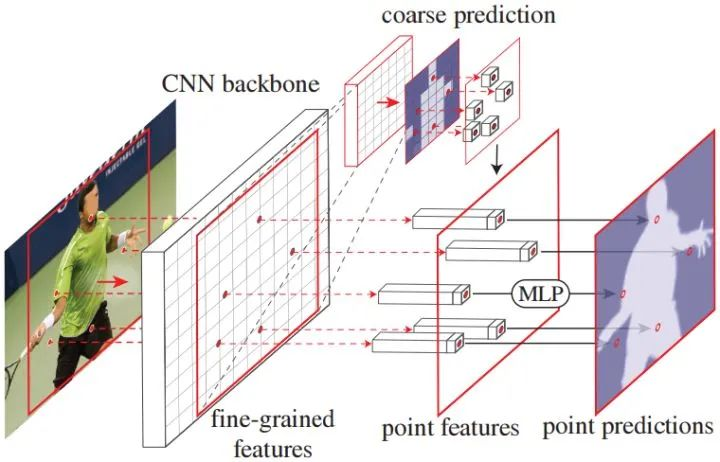
每次从粗粒度预测出来的mask中选择TopN个最不确定的位置进行细粒度预测,以非常的少的计算代价下获得巨大的性能提升。
points = sampling_points(out, x.shape[-1] // 16, self.k, self.beta)
coarse = point_sample(out, points, align_corners=False)
fine = point_sample(res2, points, align_corners=False)
feature_representation = torch.cat([coarse, fine], dim=1)Domain Adaptation
EntMin -> BNM
Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations
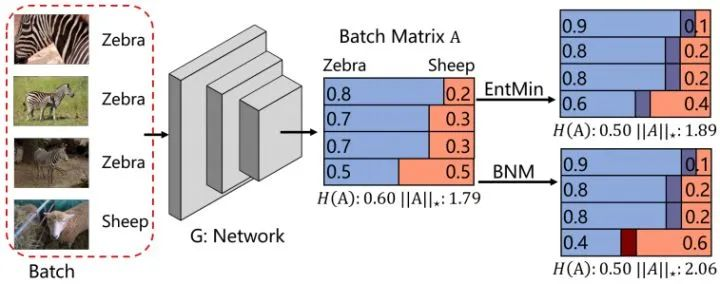
类别预测的判别性与多样性同时指向矩阵的核范数,可以通过最大化矩阵核范数(BNM)来提升预测的性能。
L_BNM = -torch.norm(X,'nuc')GAN
GAN -> Wasserstein GAN
Wasserstein GAN
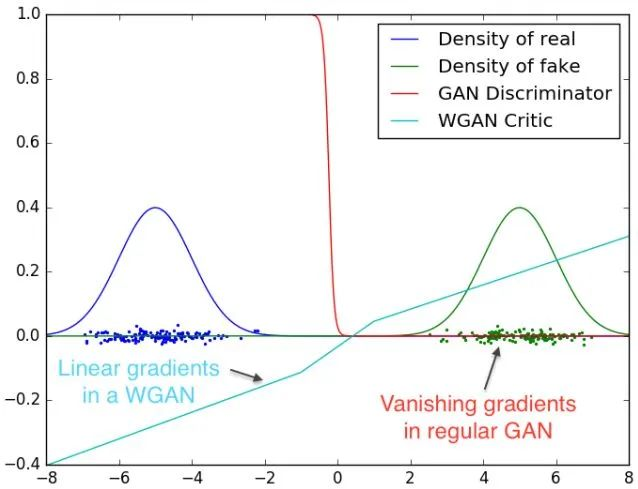
WGAN引入了Wasserstein距离,既解决了GAN训练不稳定的问题,也提供了一个可靠的训练进程指标,而且该指标确实与生成样本的质量高度相关。
Wasserstein GAN相比GAN只改了四点:
判别器最后一层去掉sigmoid
生成器和判别器的loss不取对数
每次更新把判别器参数的绝对值按阈值截断
使用RMSProp或者SGD优化器
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码:
最后
以上就是老实哈密瓜最近收集整理的关于简单有效!在CV/NLP/DL领域中,有哪些修改一行代码或者几行代码提升性能的算法?...的全部内容,更多相关简单有效!在CV/NLP/DL领域中,有哪些修改一行代码或者几行代码提升性能内容请搜索靠谱客的其他文章。








发表评论 取消回复