OkHttp源码解析
一、简介
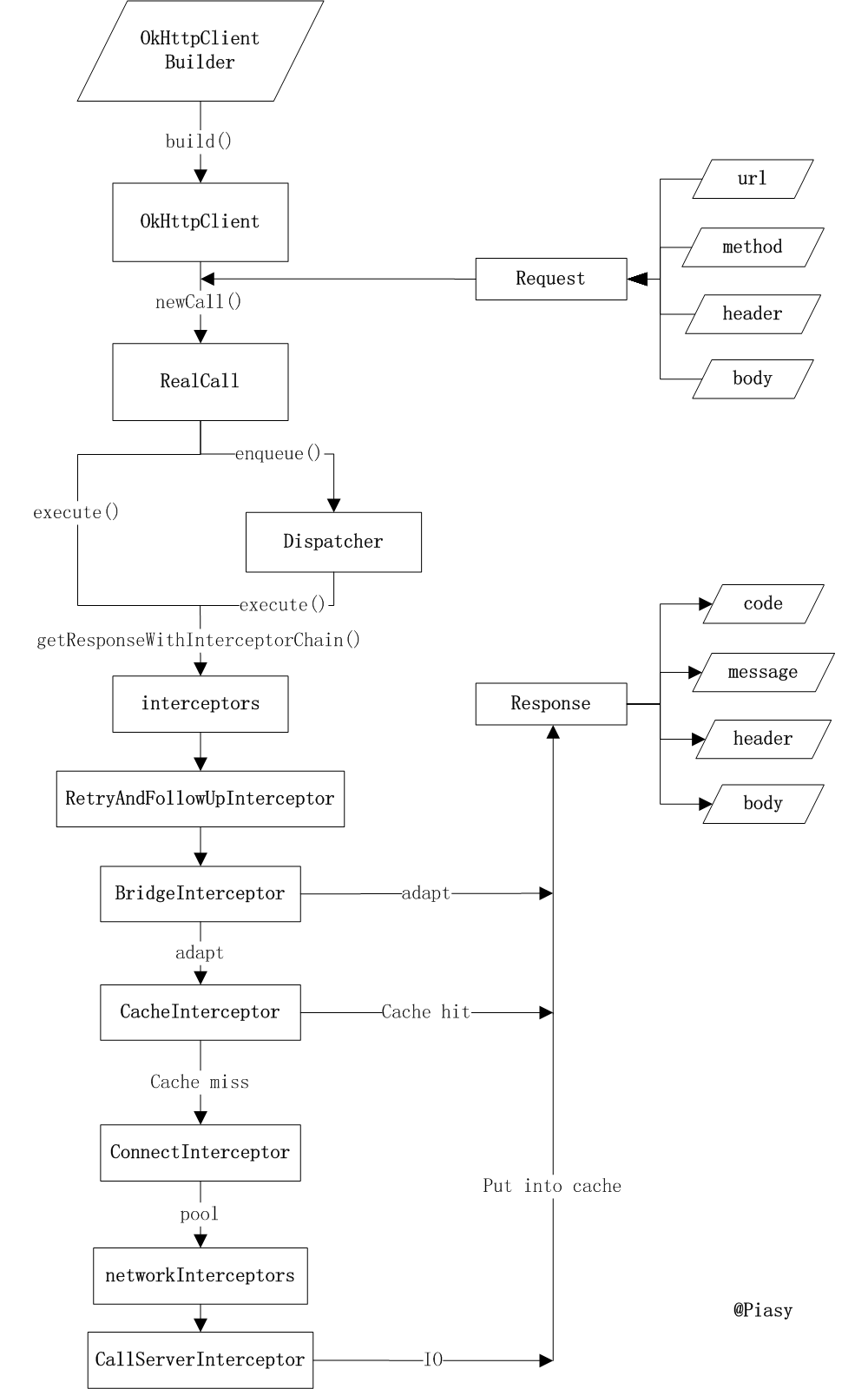
Okhttp是一个高性能的处理网络请求的框架,由Square公司开发。其初始流程为下图所示:
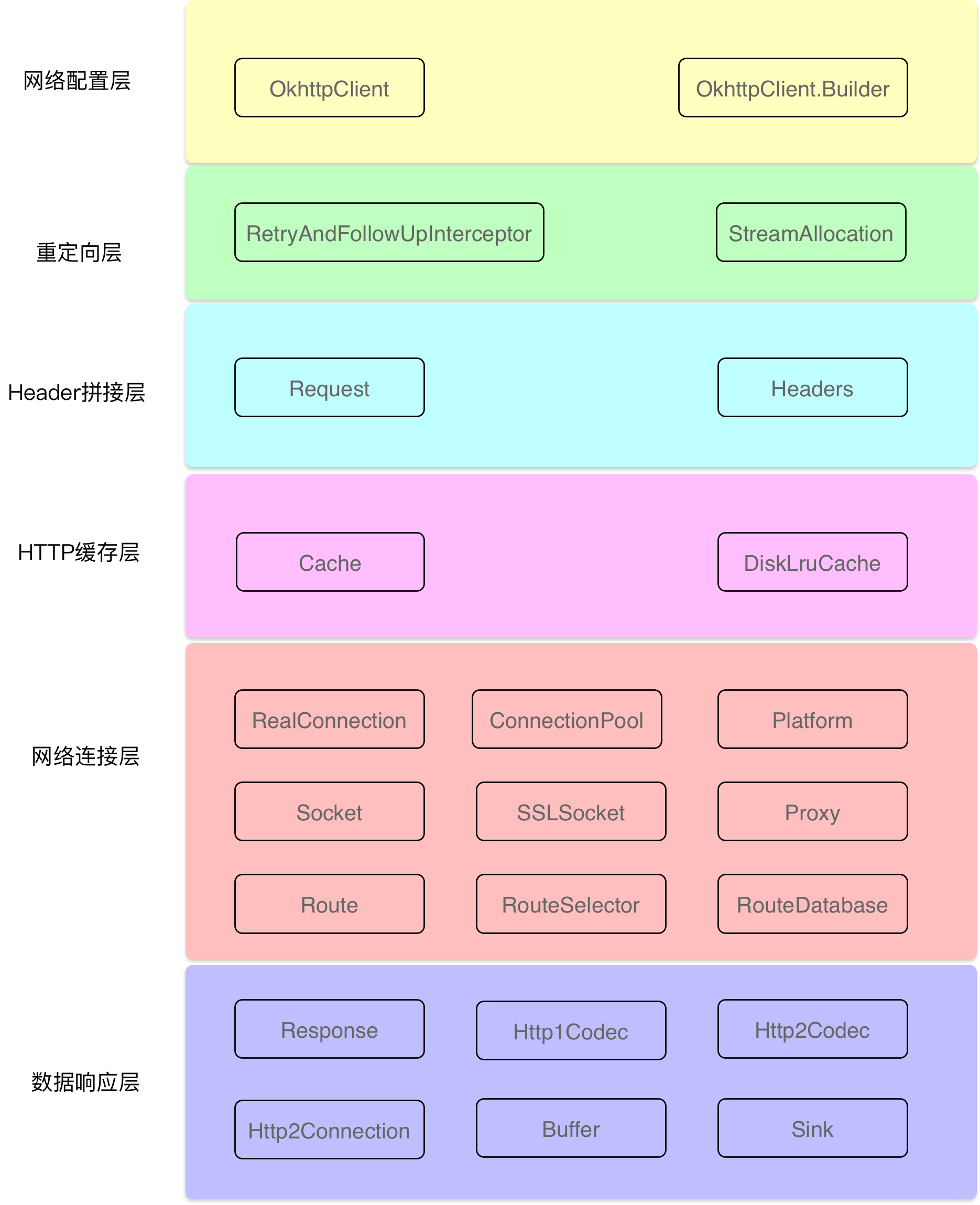
Okhttp的子系统层级结构如下图:
-
网络配置层:利用Builder模式配置各种参数,例如:超时时间、拦截器等,这些参数都会由Okhttp分发给各个需要的子系统。
重定向层:负责重定向。 -
**Header拼接层:**负责把用户构造的请求转换为发送给服务器的请求,把服务器返回的响应转换为对用户友好的响应。
-
HTTP缓存层:负责读取缓存以及更新缓存。
-
连接层:连接层是一个比较复杂的层级,它实现了网络协议、内部的拦截器、安全性认证,连接与连接池等功能,但这一层还没有发起真正的连接,它只是做了连接器一些参数的处理。
-
数据响应层:负责从服务器读取响应的数据。
二、基本使用
2.1 创建 OkHttpClient 对象
/**创建OkHttpClient的使用代码*/
OkHttpClient client = new OkHttpClient();
/**创建的源码如下*/
public OkHttpClient() {
this(new Builder()); //调用内部的Builder方法创建相关数据
}
public Builder() {
dispatcher = new Dispatcher();
protocols = DEFAULT_PROTOCOLS;
connectionSpecs = DEFAULT_CONNECTION_SPECS;
proxySelector = ProxySelector.getDefault();
cookieJar = CookieJar.NO_COOKIES;
socketFactory = SocketFactory.getDefault();
hostnameVerifier = OkHostnameVerifier.INSTANCE;
certificatePinner = CertificatePinner.DEFAULT;
proxyAuthenticator = Authenticator.NONE;
authenticator = Authenticator.NONE;
connectionPool = new ConnectionPool();
dns = Dns.SYSTEM;
followSslRedirects = true;
followRedirects = true;
retryOnConnectionFailure = true;
connectTimeout = 10_000;
readTimeout = 10_000;
writeTimeout = 10_000;
}
2.2 发起 HTTP 请求
String run(String url) throws IOException {
Request request = new Request.Builder()
.url(url)
.build();
Response response = client.newCall(request).execute();
return response.body().string();
}
OkHttpClient实现了Call.Factory,负责根据请求创建新的Call。下面我们来看看它是如何创建 Call 的:
/**
* Prepares the {@code request} to be executed at some point in the future.
*/
@Override public Call newCall(Request request) {
return new RealCall(this, request); //调用new RealCall(this, request)创建的Call
}
-
同步网络请求
上面介绍到Call的创建是由RealCall完成的,下面介绍RealCall#execute:
@Override public Response execute() throws IOException { synchronized (this) { if (executed) throw new IllegalStateException("Already Executed"); // (1) executed = true; } try { client.dispatcher().executed(this); // (2) Response result = getResponseWithInterceptorChain(); // (3) if (result == null) throw new IOException("Canceled"); return result; } finally { client.dispatcher().finished(this); // (4) } }(1) 检查这个Call是否被执行,每个Call只能被执行一次,如果想要完全一样的Call,可以利用Call#clone方法来进行克隆。
(2) 利用
client.dispatcher().executed(this)来进行实际执行dispatcher是刚才看到的OkHttpClient.Builder的成员之一,它的文档说自己是异步 HTTP 请求的执行策略,现在看来,同步请求它也有掺和。(3) 调用
getResponseWithInterceptorChain()函数获取 HTTP 返回结果,从函数名可以看出,这一步还会进行一系列“拦截”操作。(4) 最后还要通知
dispatcher自己已经执行完毕。dispatcher 这里我们不过度关注,在同步执行的流程中,涉及到 dispatcher 的内容只不过是告知它我们的执行状态,比如开始执行了(调用
executed),比如执行完毕了(调用finished),在异步执行流程中它会有更多的参与。真正发出网络请求,解析返回结果的,还是
getResponseWithInterceptorChain:private Response getResponseWithInterceptorChain() throws IOException { // Build a full stack of interceptors. List<Interceptor> interceptors = new ArrayList<>(); interceptors.addAll(client.interceptors()); interceptors.add(retryAndFollowUpInterceptor); interceptors.add(new BridgeInterceptor(client.cookieJar())); interceptors.add(new CacheInterceptor(client.internalCache())); interceptors.add(new ConnectInterceptor(client)); if (!retryAndFollowUpInterceptor.isForWebSocket()) { interceptors.addAll(client.networkInterceptors()); } interceptors.add(new CallServerInterceptor( retryAndFollowUpInterceptor.isForWebSocket())); Interceptor.Chain chain = new RealInterceptorChain( interceptors, null, null, null, 0, originalRequest); return chain.proceed(originalRequest); }在上述方法中,我们应该可以看出Interceptor这个东西很重要,不要误以为它只负责拦截请求进行一些额外的处理(例如 cookie),实际上它把实际的网络请求、缓存、透明压缩等功能都统一了起来,每一个功能都只是一个
Interceptor,它们再连接成一个Interceptor.Chain,环环相扣,最终圆满完成一次网络请求。从
getResponseWithInterceptorChain函数我们可以看到Interceptor.Chain的分布依次是:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mjyEHZQ6-1597375077966)(https://blog.piasy.com/img/201607/okhttp_interceptors.png “okhttp_interceptors”)]
- 在配置
OkHttpClient时设置的interceptors; - 负责失败重试以及重定向的
RetryAndFollowUpInterceptor; - 负责把用户构造的请求转换为发送到服务器的请求、把服务器返回的响应转换为用户友好的响应的
BridgeInterceptor; - 负责读取缓存直接返回、更新缓存的
CacheInterceptor; - 负责和服务器建立连接的
ConnectInterceptor; - 配置
OkHttpClient时设置的networkInterceptors; - 负责向服务器发送请求数据、从服务器读取响应数据
CallServerInterceptor。
在这里,位置决定了功能,最后一个 Interceptor 一定是负责和服务器实际通讯的,重定向、缓存等一定是在实际通讯之前的。
责任链模式在这个
Interceptor链条中得到了很好的实践。它包含了一些命令对象和一系列的处理对象,每一个处理对象决定它能处理哪些命令对象,它也知道如何将它不能处理的命令对象传递给该链中的下一个处理对象。该模式还描述了往该处理链的末尾添加新的处理对象的方法。
对于把
Request变成Response这件事来说,每个Interceptor都可能完成这件事,所以我们循着链条让每个Interceptor自行决定能否完成任务以及怎么完成任务(自力更生或者交给下一个Interceptor)。这样一来,完成网络请求这件事就彻底从RealCall类中剥离了出来,简化了各自的责任和逻辑。两个字:优雅!责任链模式在安卓系统中也有比较典型的实践,例如 view 系统对点击事件(TouchEvent)的处理。
回到 OkHttp,在这里我们先简单分析一下
ConnectInterceptor和CallServerInterceptor,看看 OkHttp 是怎么进行和服务器的实际通信的。建立连接:
ConnectInterceptor@Override public Response intercept(Chain chain) throws IOException { RealInterceptorChain realChain = (RealInterceptorChain) chain; Request request = realChain.request(); StreamAllocation streamAllocation = realChain.streamAllocation(); // We need the network to satisfy this request. Possibly for validating a conditional GET. boolean doExtensiveHealthChecks = !request.method().equals("GET"); HttpCodec httpCodec = streamAllocation.newStream(client, doExtensiveHealthChecks); RealConnection connection = streamAllocation.connection(); return realChain.proceed(request, streamAllocation, httpCodec, connection); }实际上建立连接就是创建了一个
HttpCodec对象,它将在后面的步骤中被使用,那它又是何方神圣呢?它是对 HTTP 协议操作的抽象,有两个实现:Http1Codec和Http2Codec,顾名思义,它们分别对应 HTTP/1.1 和 HTTP/2 版本的实现。在
Http1Codec中,它利用Okio对Socket的读写操作进行封装,Okio 以后有机会再进行分析,现在让我们对它们保持一个简单地认识:它对java.io和java.nio进行了封装,让我们更便捷高效的进行 IO 操作。而创建
HttpCodec对象的过程涉及到StreamAllocation、RealConnection,代码较长,这里就不展开,这个过程概括来说,就是找到一个可用的RealConnection,再利用RealConnection的输入输出(BufferedSource和BufferedSink)创建HttpCodec对象,供后续步骤使用。发送和接收数据:
CallServerInterceptor@Override public Response intercept(Chain chain) throws IOException { HttpCodec httpCodec = ((RealInterceptorChain) chain).httpStream(); StreamAllocation streamAllocation = ((RealInterceptorChain) chain).streamAllocation(); Request request = chain.request(); long sentRequestMillis = System.currentTimeMillis(); httpCodec.writeRequestHeaders(request); if (HttpMethod.permitsRequestBody(request.method()) && request.body() != null) { Sink requestBodyOut = httpCodec.createRequestBody(request, request.body().contentLength()); BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut); request.body().writeTo(bufferedRequestBody); bufferedRequestBody.close(); } httpCodec.finishRequest(); Response response = httpCodec.readResponseHeaders() .request(request) .handshake(streamAllocation.connection().handshake()) .sentRequestAtMillis(sentRequestMillis) .receivedResponseAtMillis(System.currentTimeMillis()) .build(); if (!forWebSocket || response.code() != 101) { response = response.newBuilder() .body(httpCodec.openResponseBody(response)) .build(); } if ("close".equalsIgnoreCase(response.request().header("Connection")) || "close".equalsIgnoreCase(response.header("Connection"))) { streamAllocation.noNewStreams(); } // 省略部分检查代码 return response; }我们抓住主干部分:
- 向服务器发送 request header;
- 如果有 request body,就向服务器发送;
- 读取 response header,先构造一个
Response对象; - 如果有 response body,就在 3 的基础上加上 body 构造一个新的
Response对象;
这里我们可以看到,核心工作都由
HttpCodec对象完成,而HttpCodec实际上利用的是 Okio,而 Okio 实际上还是用的Socket,所以没什么神秘的,只不过一层套一层,层数有点多。其实
Interceptor的设计也是一种分层的思想,每个Interceptor就是一层。为什么要套这么多层呢?分层的思想在 TCP/IP 协议中就体现得淋漓尽致,分层简化了每一层的逻辑,每层只需要关注自己的责任(单一原则思想也在此体现),而各层之间通过约定的接口/协议进行合作(面向接口编程思想),共同完成复杂的任务。简单应该是我们的终极追求之一,尽管有时为了达成目标不得不复杂,但如果有另一种更简单的方式,我想应该没有人不愿意替换。
- 在配置
-
异步网络请求
client.newCall(request).enqueue(new Callback() { @Override public void onFailure(Call call, IOException e) { } @Override public void onResponse(Call call, Response response) throws IOException { System.out.println(response.body().string()); } }); // RealCall#enqueue @Override public void enqueue(Callback responseCallback) { synchronized (this) { if (executed) throw new IllegalStateException("Already Executed"); executed = true; } client.dispatcher().enqueue(new AsyncCall(responseCallback)); } // Dispatcher#enqueue synchronized void enqueue(AsyncCall call) { if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) { runningAsyncCalls.add(call); executorService().execute(call); } else { readyAsyncCalls.add(call); } }这里我们就能看到 dispatcher 在异步执行时发挥的作用了,如果当前还能执行一个并发请求,那就立即执行,否则加入
readyAsyncCalls队列,而正在执行的请求执行完毕之后,会调用promoteCalls()函数,来把readyAsyncCalls队列中的AsyncCall“提升”为runningAsyncCalls,并开始执行。这里的
AsyncCall是RealCall的一个内部类,它实现了Runnable,所以可以被提交到ExecutorService上执行,而它在执行时会调用getResponseWithInterceptorChain()函数,并把结果通过responseCallback传递给上层使用者。这样看来,同步请求和异步请求的原理是一样的,都是在
getResponseWithInterceptorChain()函数中通过Interceptor链条来实现的网络请求逻辑,而异步则是通过ExecutorService实现。
2.3 返回数据的获取
在上述同步(Call#execute()执行之后)或者异步(Callback#onResponse()回调中)请求完成之后,我们就可以从Response对象中获取到响应数据了,包括 HTTP status code,status message,response header,response body 等。这里 body 部分最为特殊,因为服务器返回的数据可能非常大,所以必须通过数据流的方式来进行访问(当然也提供了诸如string()和bytes()这样的方法将流内的数据一次性读取完毕),而响应中其他部分则可以随意获取。
响应 body 被封装到ResponseBody类中,该类主要有两点需要注意:
- 每个 body 只能被消费一次,多次消费会抛出异常;
- body 必须被关闭,否则会发生资源泄漏;
在2.2.1.2.发送和接收数据:CallServerInterceptor小节中,我们就看过了 body 相关的代码:
if (!forWebSocket || response.code() != 101) {
response = response.newBuilder()
.body(httpCodec.openResponseBody(response))
.build();
}
由HttpCodec#openResponseBody提供具体 HTTP 协议版本的响应 body,而HttpCodec则是利用 Okio 实现具体的数据 IO 操作。
这里有一点值得一提,OkHttp 对响应的校验非常严格,HTTP status line 不能有任何杂乱的数据,否则就会抛出异常,在我们公司项目的实践中,由于服务器的问题,偶尔 status line 会有额外数据,而服务端的问题也毫无头绪,导致我们不得不忍痛继续使用 HttpUrlConnection,而后者在一些系统上又存在各种其他的问题,例如魅族系统发送 multi-part form 的时候就会出现没有响应的问题。
2.4 HTTP 缓存
在2.2.1.同步网络请求小节中,我们已经看到了Interceptor的布局,在建立连接、和服务器通讯之前,就是CacheInterceptor,在建立连接之前,我们检查响应是否已经被缓存、缓存是否可用,如果是则直接返回缓存的数据,否则就进行后面的流程,并在返回之前,把网络的数据写入缓存。
这块代码比较多,但也很直观,主要涉及 HTTP 协议缓存细节的实现,而具体的缓存逻辑 OkHttp 内置封装了一个Cache类,它利用DiskLruCache,用磁盘上的有限大小空间进行缓存,按照 LRU 算法进行缓存淘汰,这里也不再展开。
我们可以在构造OkHttpClient时设置Cache对象,在其构造函数中我们可以指定目录和缓存大小:
public Cache(File directory, long maxSize);
而如果我们对 OkHttp 内置的Cache类不满意,我们可以自行实现InternalCache接口,在构造OkHttpClient时进行设置,这样就可以使用我们自定义的缓存策略了。
三、总结
OkHttp 还有很多细节部分没有在本文展开,例如 HTTP2/HTTPS 的支持等,但建立一个清晰的概览非常重要。对整体有了清晰认识之后,细节部分如有需要,再单独深入将更加容易。
OkHttpClient实现Call.Factory,负责为Request创建Call;RealCall为具体的Call实现,其enqueue()异步接口通过Dispatcher利用ExecutorService实现,而最终进行网络请求时和同步execute()接口一致,都是通过getResponseWithInterceptorChain()函数实现;getResponseWithInterceptorChain()中利用Interceptor链条,分层实现缓存、透明压缩、网络 IO 等功能;
最后
以上就是怡然玫瑰最近收集整理的关于OkHttp基本概念以及源码解析OkHttp源码解析的全部内容,更多相关OkHttp基本概念以及源码解析OkHttp源码解析内容请搜索靠谱客的其他文章。








发表评论 取消回复