前言:本篇文章主要介绍一下如何使用ShardingJDBC做分库分表。
什么是分库分表
比较传统的小型应用通常是一个项目使用一个数据库进行数据存储,这样的架构模式在数据量日益增长的情况下,数据库势必会成为性能瓶颈。几百万数据还可以通过数据库优化,索引优化等手段勉强支持,但是上千万,上亿的数据再怎么优化索引都无济于事。所以我们的优化手段可以是分库分表。
垂直分库分表
垂直拆分是比较简单的,在数据库设计层面就可以实现。垂直分库通常是按照业务模块或其他方式把一个数据库中的表拆分到多个数据库中。比如:把用户相关维度的表放到user库,把商品相关维度的表放到product库。这样我们的应用就可以根据不同的业务连接不同的数据库,这通常是微服务项目的做法,通常每个微服务都会有自己独立的数据库。这样的好处是多个数据库分担流量整体上是提高了查询速度。
一个数据库处理不了请求就可以考虑使用多个mysql服务来分担压力,垂直分库就是把一个数据库中的N张表,按照模块/业务 划分到多个数据库,每个数据库都有自己的服务器,进行分布式部署。
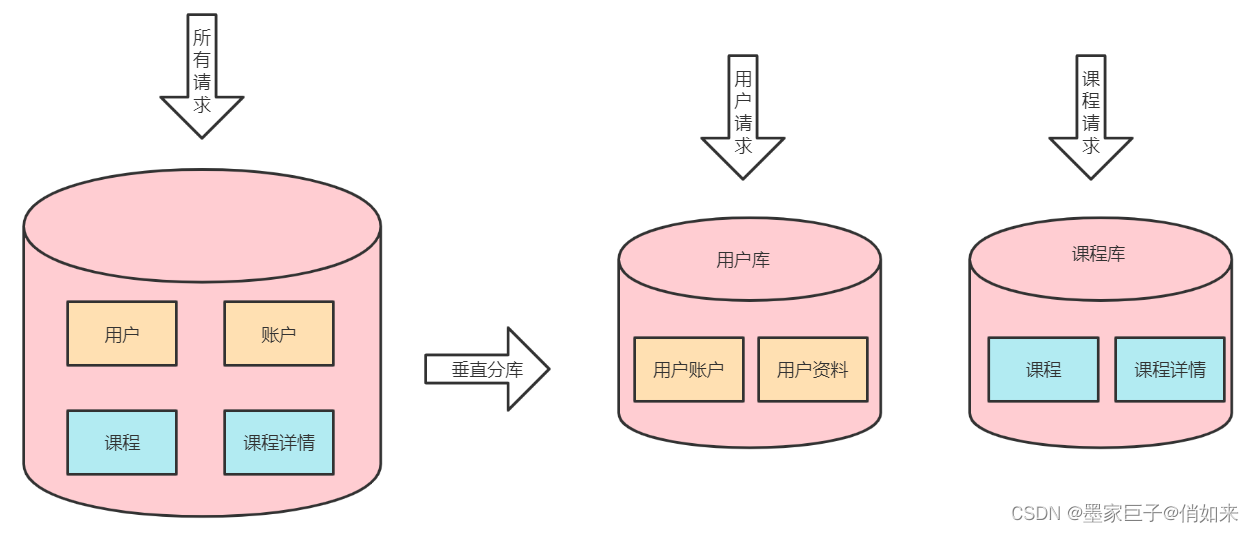
而垂直分表指的是把一个大表中的字段拆分成多个小表。比如:把用户基本信息放到userinfo表,把用户账户放到useraccount表。然后使用外键进行关联,我们也经常把大字段(长文本)专门抽表来优化查询。这样的好处是表结构变得清晰可维护外,查询上也能得到一定的性能优化。
下面是一张超大的用户表

拆分之后 - 登录表

拆分之后-基本信息表

拆分之后-账户表

水平分库分表
水平分表指的是把一个表中的数据拆分到多个表中,垂直分表可以认为是按列(字段)分,而水平分表可以认为是按行(记录)分。比如一个表中的数据量一千万行,查询注定慢,我们可以把这个表中的数据拆分成10个小表,每个表一百万行数据,水平分表后,每个小表拥有相同的列,如:t_course
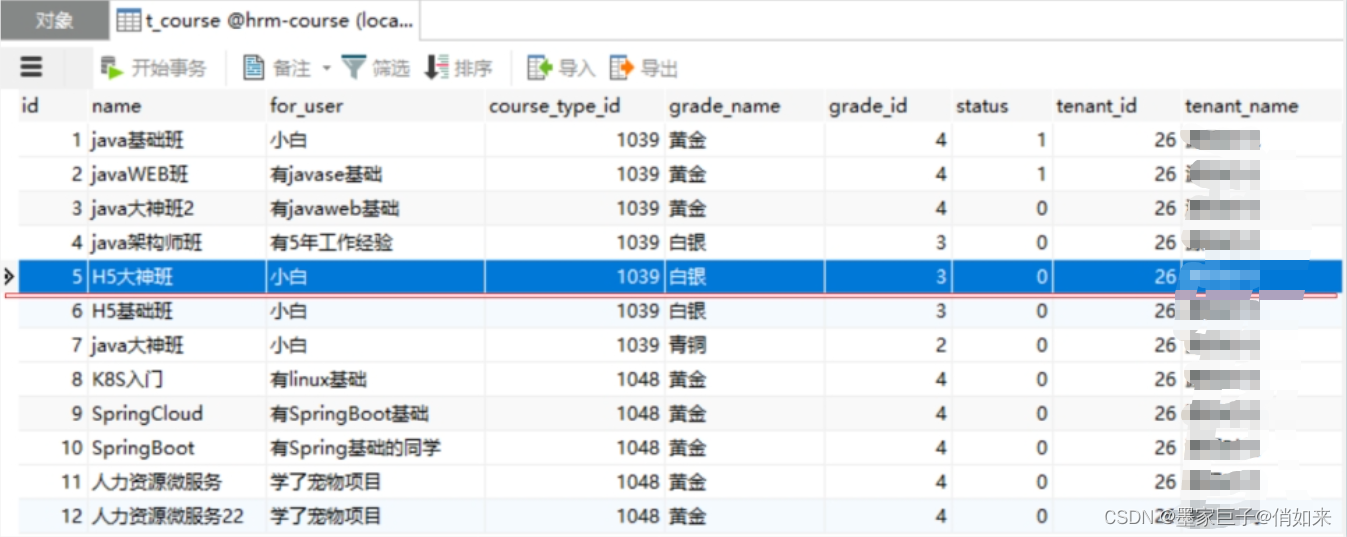
可以水平分表为 t_course1
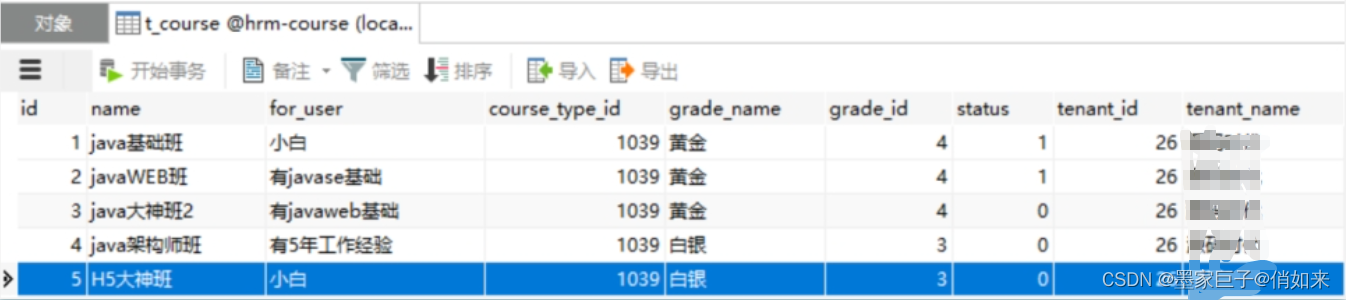
以及t_course2
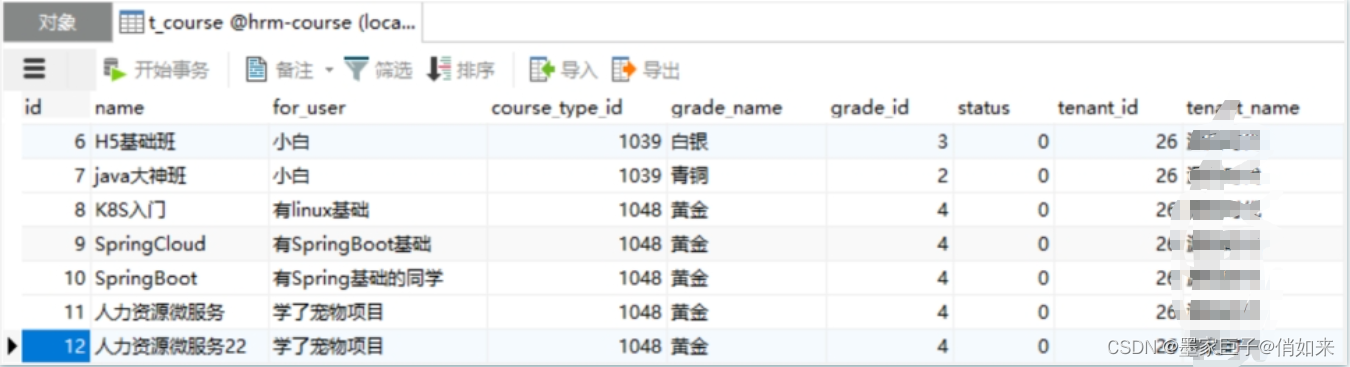
水平分表的规则很多比如
1.按照区间范围分表 : 上面的分表方式就是按照数据范围来分,比如user表有300W数据,
-
table_1 user_id从1~100w
-
table_2 user_id从101~200w
-
table_3 user_id从201~300w
所以这样的分表应该具备ID全局唯一,而不是简单的自增长,否则ID会重复。
2.按照时间分表
比如一个月分一个表,那么一年也就分12张表 ,这种方式适用于时效性很强的场景,比如登录日志,或者账户流水,一般都是看最近一个月的日志,很少去看一月前的,或者一年前的。甚至更老旧的数据可以直接删掉。
3.使用Hash算法
使用Hash算法又有多种,比如:Hash取余;一致性哈希分片 ; 虚拟槽分片 (redis集群分片),这里介绍一个最简单的Hash取余分片。找到一个列比如表的ID列,通过一定的hash算法计算出数据存储表的表名,然后访问相应的表,这种方法比较通用
比如:准备好100个表 : t_course_01 , t_course_02, … ,t_course_100
然后计算:hash(商品id) % 100 ,余数就对应表的下标了。
水平分库
做水平分表是把一个大表中的数据拆分到多个小表中,每个表的数据量较少,从而提高查询速度,即使做了水平分表,如果一个库中的表太多,那么这个库还是会承担太多的请求,也会影响数据库的效率,水平分库指定是把一个数据库中的表分到多个数据库中,数据库采用分布式部署,比如电商平台针对于商品库我们可以按照商户来分,如下:
把商品表水平分表后形成 商品表1,商品表2 … ; 这是水平分表,然后再把 商品表1,商品表2 拆分到不同的数据库,商品库1,商品库2…中。注意:多个不同库中的表存储的可是不同的数据哦。

那么做了水平分库分表后,数据应该存储到哪个位置呢?这个时候我们需要找到2个路由规则,一个是分库规则,一个是分表规则,比如上图,假如我们使用商家ID来分库,使用商品ID来分表。如下:
- 比如我有一个商品对商家Hash计算后进行取模后: hash(商家) = 2 ; 2 % 2个库 = 0 ;那么这条数据应该放到索引为 0 的 库,也就是 商品库1 中。
- 比如我对这条商品数据编号,进行Hash计算进行取模后: hash(商品) = 7 ;7 % 2 = 1 ;那么这条数据库应该放到下标为 1 的表,也就是商品表2中。
那么这条数据应该放到 第一个库中的第二个表,不知道你是否看懂上面的案例呢?
分库分表后遗症
记住:能不水平分库分表就一定不要分,很麻烦特别是老数据的处理. . .,也不要会点皮毛就开始去搞你们公司的那个数据库。
那么分库分表后会带来哪些问题呢?
1.第一个是分布式事务问题,因为分库了,难免会出现一个操作涉及到多个数据库写操作,好在现在分布式事务解决方案也比较成熟,ShardingJDBC也支持分布式事务方案,所以这个不用太过担心。
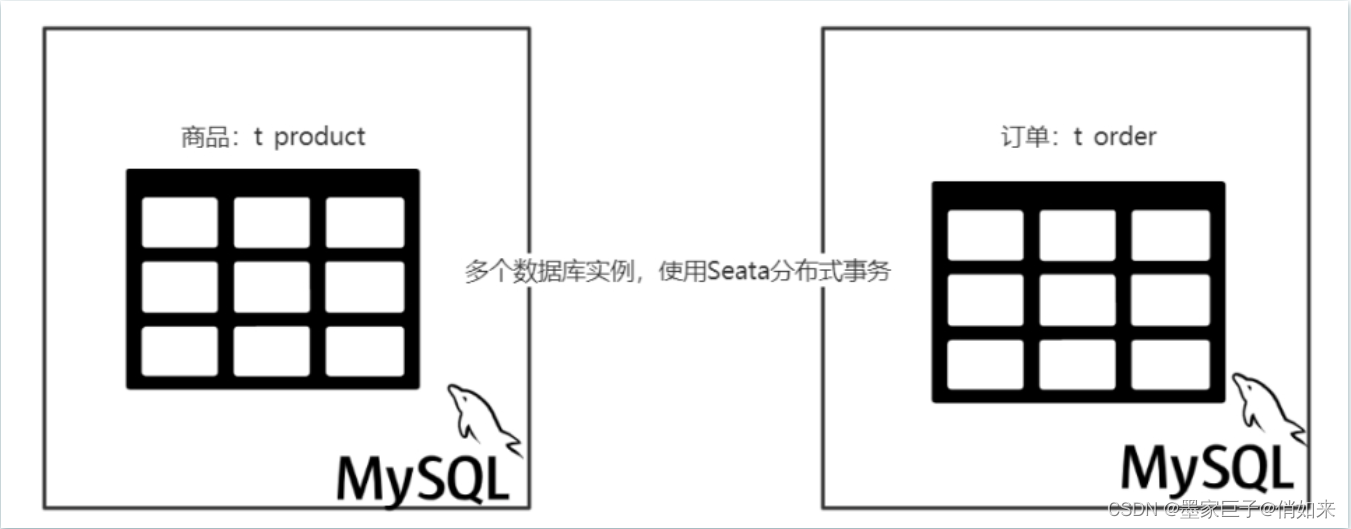
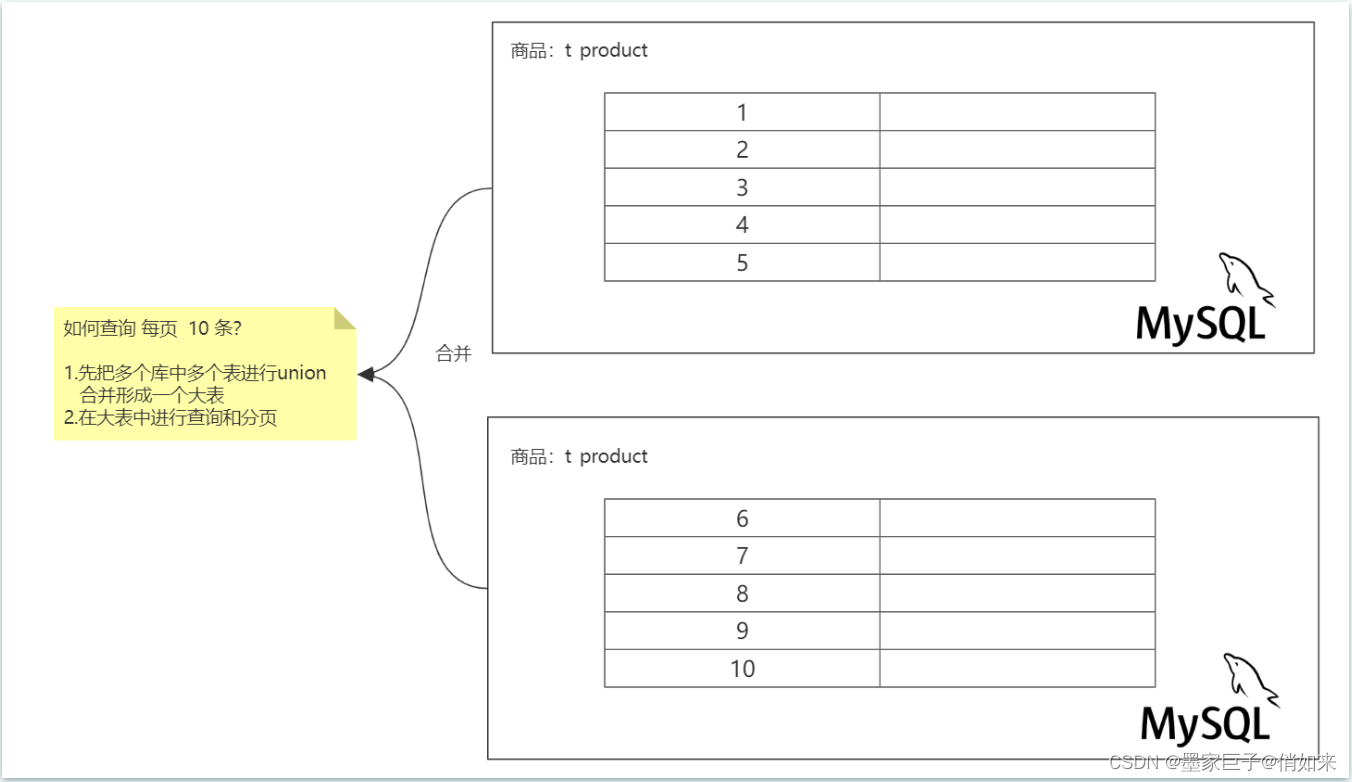
2.第二个是跨库查询问题,如果一个查询需要的数据正好处于拆分后的2个表,甚至2个库怎么办,要join吗?ShardingJDBC会自动帮我们连表查询,但是性能肯定要打折扣了
3.主键重复问题,单体项目中都喜欢用主键自增长,在分表后如果还用自增长是不是就会ID重复呢?所以如何保证ID全局唯一?也是有很多方案,比如使用雪花算法生成唯一ID。甚至你用UUID也行嘛
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割 成多个部分,每个部分代表不同的含义(41位时间戳,10位机器号,12位序列号)。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的
4.分库之后,如果多个库中的多个表都需要关联某一个公共表怎么办,比如数据字典,难道我多个库中都要放一份数据字典?好在ShardingJDBC帮我们想好了办法,我们只需要把公共表设置为 broadcast-tables 即可
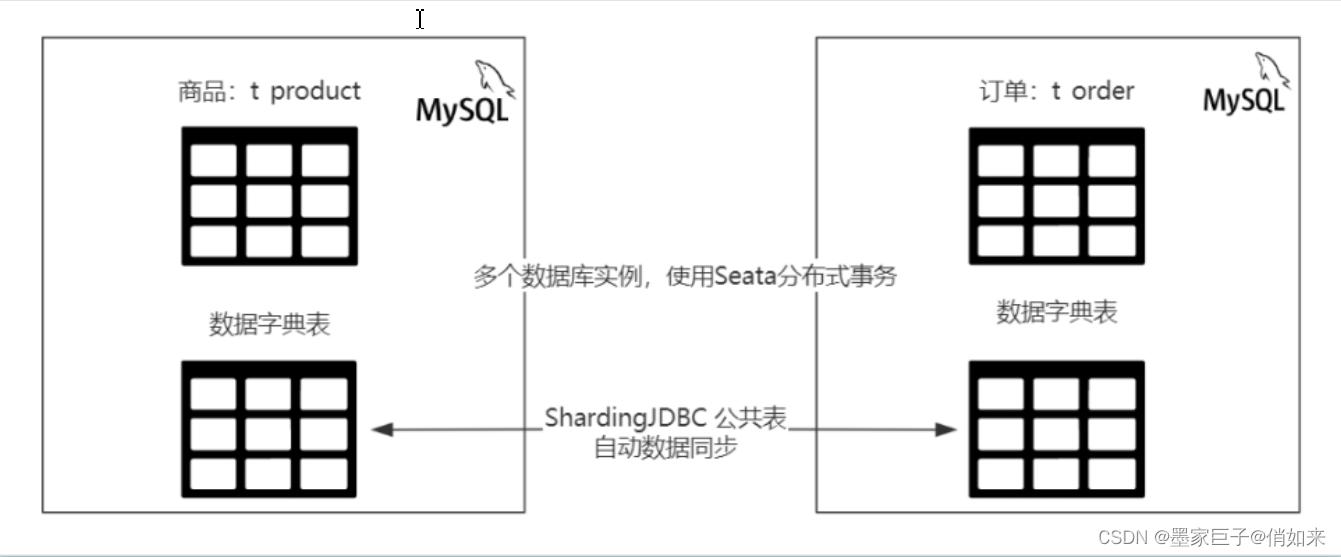
讲到这里你是否觉得ShardingJDBC还是挺强大的呢
分库分表组件
分库分表业界用的比较都的有shardingJDBC 以及 MyCat ,两者各有千秋把~ , 这里主要介绍一下ShardingJDBC如何做分库分表。上一章节已经介绍过ShardingJDBC了所以这里不重复介绍。
配置文档:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/
第一步:导入依赖
<!-- 引入shardingjdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
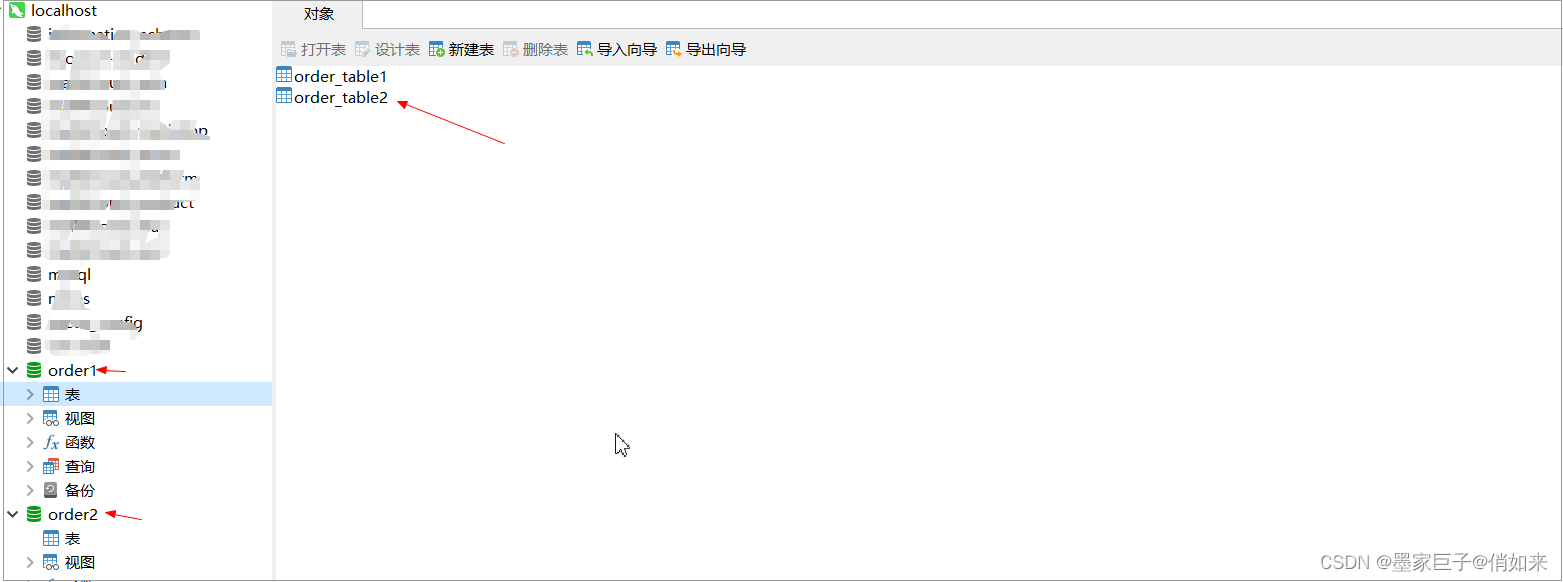
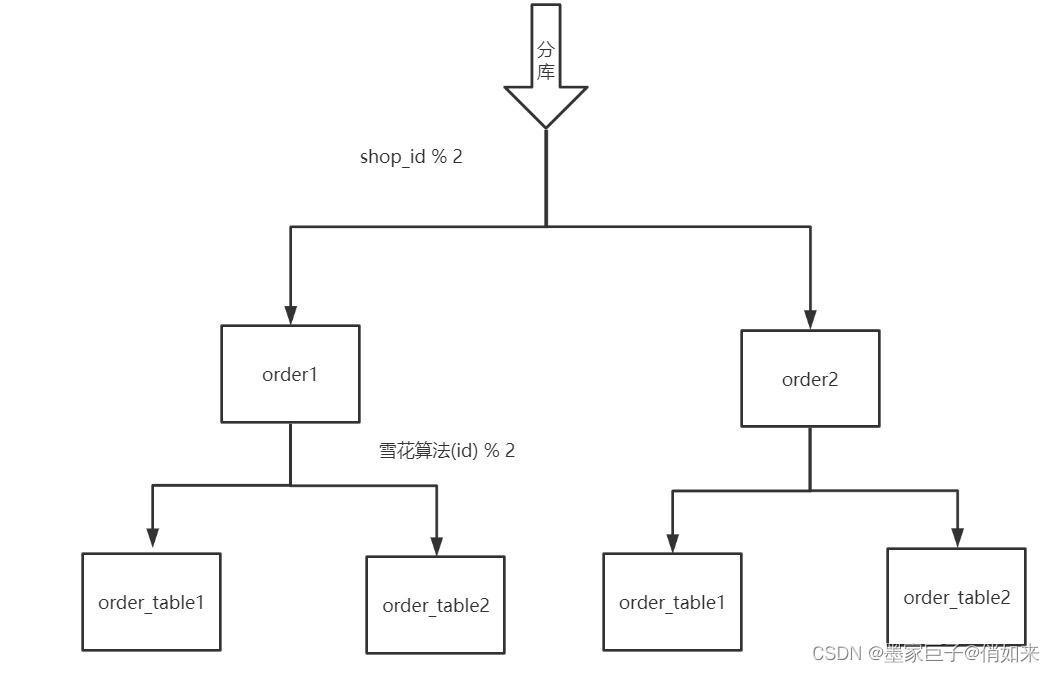
第二步:创建多个数据库,我这里以order1;order2为例,2个库里面都有相同名字的2张表
- order1 和 order2是分库 ;
- order_table1 和 order_table2是分表 , 表中有2个字段 , id 和 shop_id 都是bigint类型
第三步:加入shardingJDBC配置
#datasource的名字,有几个数据源就写几个名字,和url中的数据库名字保持一致
spring.shardingsphere.datasource.names=order1,order2
spring.shardingsphere.datasource.order1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.order1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order1.url=jdbc:mysql://localhost:3307/order1
spring.shardingsphere.datasource.order1.username=root
spring.shardingsphere.datasource.order1.password=123456
spring.shardingsphere.datasource.names=order1,order2
spring.shardingsphere.datasource.order2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.order2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.order2.url=jdbc:mysql://localhost:3307/order2
spring.shardingsphere.datasource.order2.username=root
spring.shardingsphere.datasource.order2.password=123456
#分库策略================================================================================================================
#按照shop_id分库 ,分库规则:
order是数据库前缀,拼接上: shop_id
% 2 取余数 + 1 的值
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=shop_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=order$->{shop_id % 2 + 1}
#分表策略================================================================================================================
#按照id分表,id使用雪花算保证全局唯一,具体算法:order_table是表前缀,拼接上:$->{id % 2}
的值
spring.shardingsphere.sharding.tables.order_table.actual-data-nodes=order$->{1..2}.t_course$->{1..2}
#对id进行分表 , +1是因为表名字是以order_table1开始的
spring.shardingsphere.sharding.tables.order_table.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.order_table.table-strategy.inline.algorithm-expression=order$->{id % 2 + 1}
#主键生成策略,order_id使用雪花算法
spring.shardingsphere.sharding.tables.order_table.key-generator.column=id
spring.shardingsphere.sharding.tables.order_table.key-generator.type=SNOWFLAKE
#=================================================================================================================================
#这个是绑定的表,不加后缀
spring.shardingsphere.sharding.binding-tables=order_table
#公共的表
#spring.shardingsphere.sharding.broadcast-tables=公共表
#是否打印sql
spring.shardingsphere.props.sql.show=true
画个图理解一下:
第四步:启动测试,可以根据插入的数据的 shop_id 和 id 来计算数据应该存储到哪个库中的哪个表,然后进行校验
文章结束,如果对你有所帮助请给个好评把,你的肯定是我最大的动力!!!!
最后
以上就是善良大炮最近收集整理的关于Sharding-JDBC实现分库分表的全部内容,更多相关Sharding-JDBC实现分库分表内容请搜索靠谱客的其他文章。








发表评论 取消回复