首先通过pip 安装scrapy ,安装方式一百度一大堆~
这里就不再赘述
安装成功之后,开始今天的教程
执行:scrapy startproject First 生成项目文件
如图所示即为创建项目成功

创建成功后会生成如图所示的目录结构
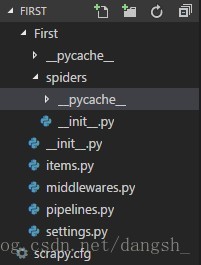
我的理解是:
- 用户自己写的爬虫py文件应放在spiders目录下,
- Item用来保存爬取到的数据,
- middlewares 是Spider中间件
- pipelines 是管道
- scrapy.cfg是项目的配置文件
其实不懂也不重要,用到的时候自己去理解
接下来开始写爬虫
爬虫需要放到spiders文件夹下
给这个爬虫文件起名为second.py
创建成功,进行模块的导入
import scrapy写一个类,继承scrapy的Spider
给这只爬虫起个名字叫做 sean
我们的爬取目标选择了拉勾网,所以将拉勾网的网址放入start_urls中
class Lagou(scrapy.Spider):
name = "sean"
start_urls = [
"https://www.lagou.com/"
]爬取到信息后需要进行解析,使用parse方法进行解析
def parse(self , response):然后我们需要分析拉勾网的结构,才可以取出其中的数据
这里我使用的是chrome浏览器
F12进入开发者工具
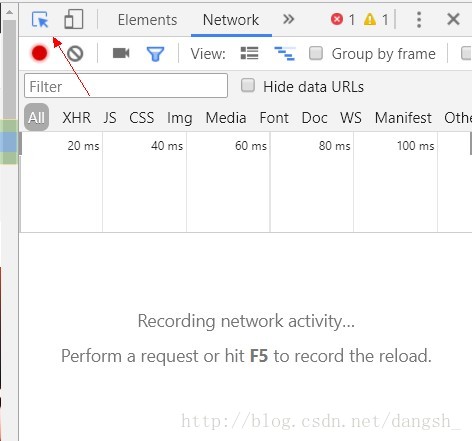
点击左上角箭头所指的工具
再点击左侧
快速的找到这个元素
并且可以看到html的标签结构如下,
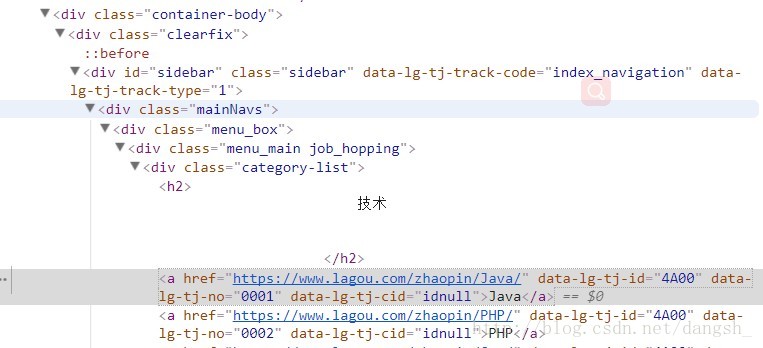
我们接下来需要通过selector(选择器)来进行内容的选择
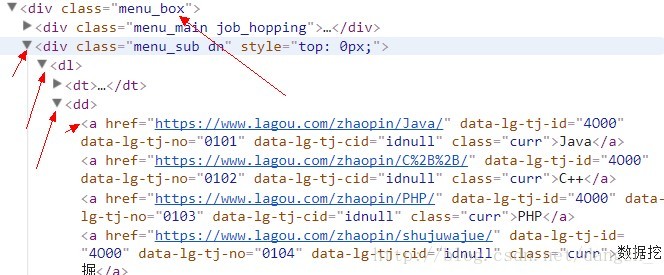
通过xpath选择器,找到class=”menu_box”的div
获得它下一个div标签,的下一个dl标签,的下一个a标签,通过遍历取出所有符合条件的内容
使用以下语句作为选择器来选择到a标签
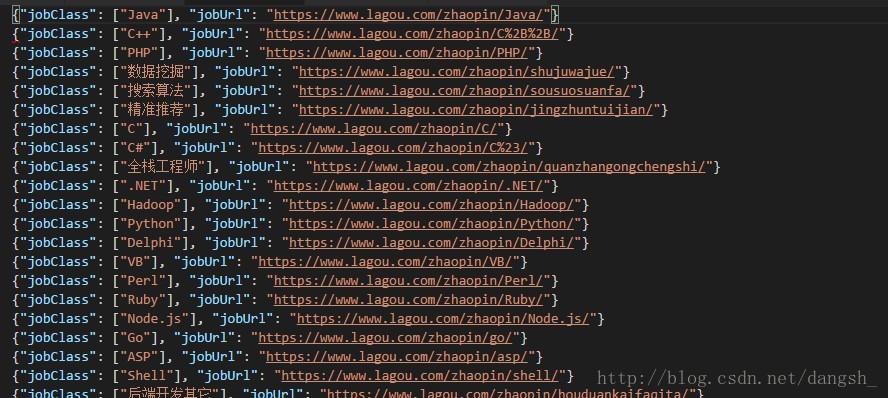
for item in response.xpath(‘//div[@class=”menu_box”]/div/dl/dd/a’):
for item in response.xpath('//div[@class="menu_box"]/div/dl/dd/a'):
jobClass = item.xpath('text()').extract()
jobUrl = item.xpath("@href").extract_first()
oneItem = FirstItem()
oneItem["jobClass"] = jobClass
oneItem["jobUrl"] = jobUrl
只要获取到标签的 内容text(),和 链接@href 就得到了 工作类型和该工作类型的链接
jobClass = item.xpath('text()').extract()
jobUrl = item.xpath("@href").extract_first()在处理得到的数据的时候,需要进入items.py文件
import scrapy
class FirstItem(scrapy.Item):
jobClass = scrapy.Field()
jobUrl = scrapy.Field()定义jobClass 和 jobUrl 来接收获取到的这两条数据
回到second.py
在文件头部导入FirstItem
from First.items import FirstItem然后在parse方法中实例化一个FirstItem,并且将获取到的值放入其中
oneItem = FirstItem()
oneItem["jobClass"] = jobClass
oneItem["jobUrl"] = jobUrl
yield oneItem然后使用yield输出oneItem
接下来执行这个爬虫
scrapy的爬虫执行方式和平时执行py文件有所不同
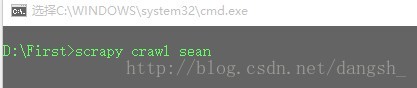
**scrapy crawl sean**sean是我们在上面定义的爬虫的name
回车执行,如图所示效果,输出了工作类型,和对应的url
我们还可以使用
**scrapy crawl sean -o shujv.json**将获取到的数据存储在shujv.json中

回车执行之后,发现当前目录下多了一个shujv.json文件,双击打开,查看内容
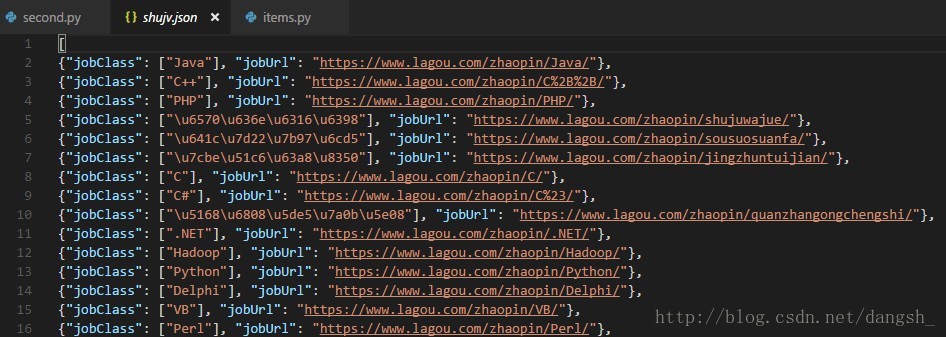
存储是存储进去了,英文显示的还是英文,但是中文居然显示成了乱码,
事实上这并不是乱码,编码过后的数据。
我们需要对数据进行解析
通过阅读源码知道,在scrapy.exporters 的 JsonLinesItemExporter类中,对数据进行了编码。
所以我们可以在spiders文件夹的同级目录下创建一个xxx文件夹,在xxx文件夹中创建一个__init__.py文件,在里面写一个类继承JsonLinesItemExporter,并且设置不编码。
__init__.py文件内容如下
from scrapy.exporters import JsonLinesItemExporter
class chongxie(JsonLinesItemExporter):
def __init__(self , file , **kwargs):
super(chongxie , self).__init__(file , ensure_ascii = None)
重写完了之后需要在settings.py文件中进行设置,添加如下语句
FEED_EXPORTERS_BASE = {
'json' : 'First.xxx.chongxie' ,
'jsonlines' : 'scrapy.contrib.exporter.JsonLinesItemExporter',
} 再次运行爬虫,结果如下
编码问题解决了
整体代码如下
second.py
import scrapy
from First.items import FirstItem
class Lagou(scrapy.Spider):
name = "sean"
start_urls = [
"https://www.lagou.com/"
]
def parse(self , response):
for item in response.xpath('//div[@class="menu_box"]/div/dl/dd/a'):
jobClass = item.xpath('text()').extract()
jobUrl = item.xpath("@href").extract_first()
oneItem = FirstItem()
oneItem["jobClass"] = jobClass
oneItem["jobUrl"] = jobUrl
yield oneItemxxx/__init__.py
from scrapy.exporters import JsonLinesItemExporter
class chongxie(JsonLinesItemExporter):
def __init__(self , file , **kwargs):
super(chongxie , self).__init__(file , ensure_ascii = None)
items.py
import scrapy
class FirstItem(scrapy.Item):
jobClass = scrapy.Field()
jobUrl = scrapy.Field()夜深了,先写这么多,明天接着写 : )
啦啦啦,再度深夜码字 QAQ
在昨天,我们初步获取到了jobClass 和 jobUrl 为我们下一步深入的爬取获取到了重要的信息,jobUrl
在平时我们用浏览器打开拉勾网的时候,通过点击箭头所指的地方,可以进入下级目录
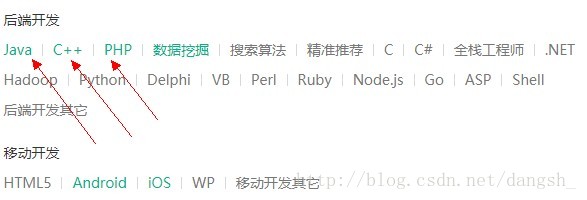
实质上是点击了一个a标签,访问到了它的href属性的url
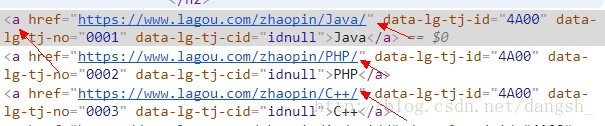
我们取出的jobUrl就是这个地址,通过这个地址访问下一个界面
我们访问https://www.lagou.com/zhaopin/Java/
是java的界面,准备获取以下箭头所指的信息
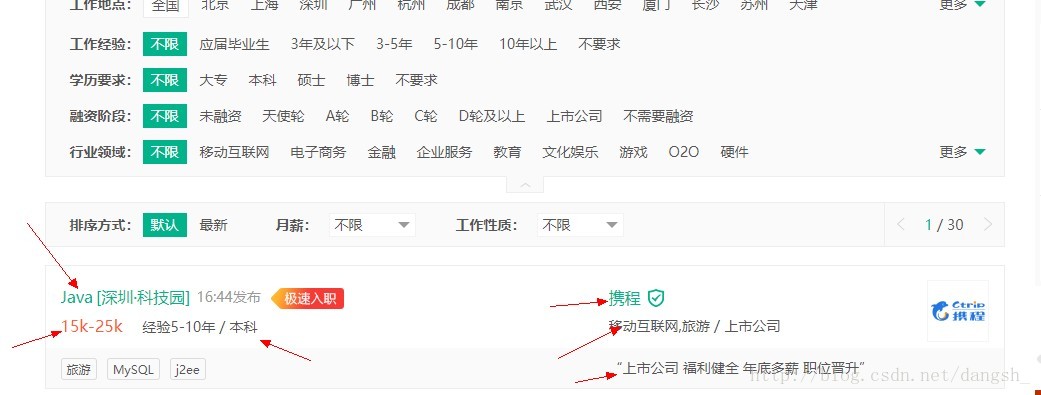
首先我们需要通过以下代码访问到jobUrl,
yield scrapy.Request(url = jobUrl , callback=self.parse_url)callback是回调函数,我们需要在下面实现这个方法,但是有一点我们需要提前完成,那就是攻克拉勾的反爬虫机制,我们通过设置cookie来完成这个功能,接下来先教大家获取到cookie。
在java这个界面F12 , 进入调试模式 , 选择Network,F5 ,找到左侧的java/,点击,在右侧选择Headers,找到其中的Request Headers 中的 Cookie,复制下来,粘贴到编译器中
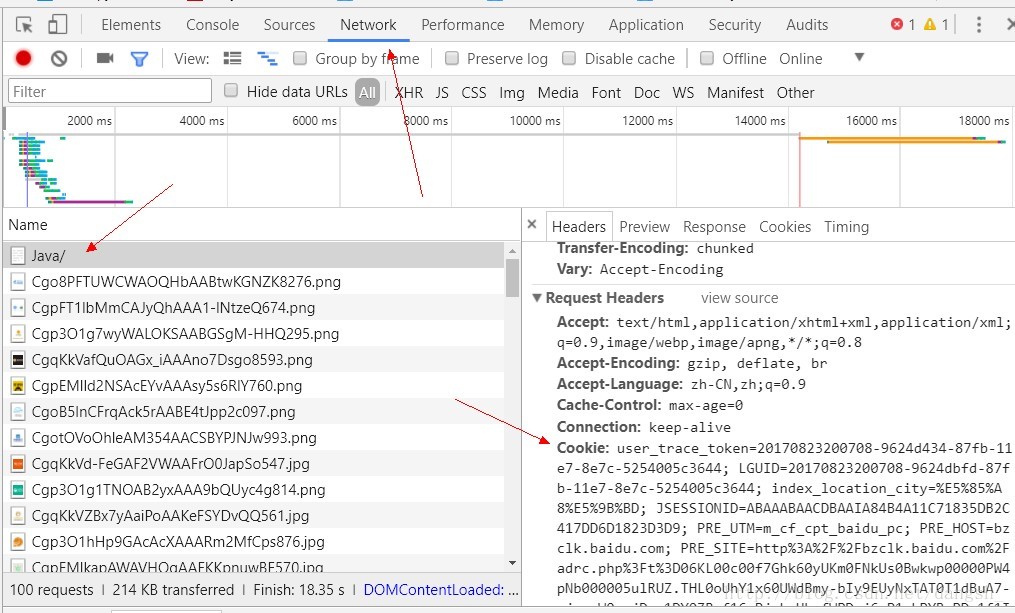
但是在scrapy中,粘贴过来的cookie是不可以直接使用的,需要将它做成一个dict才可以使用,
cookie = {
'user_trace_token':'20170823200708-9624d434-87fb-11e7-8e7c-5254005c3644',
'LGUID':'20170823200708-9624dbfd-87fb-11e7-8e7c-5254005c3644 ',
'index_location_city':'%E5%85%A8%E5%9B%BD',
'JSESSIONID':'ABAAABAAAIAACBIB27A20589F52DDD944E69CC53E778FA9',
'TG-TRACK-CODE':'index_code',
'X_HTTP_TOKEN':'5c26ebb801b5138a9e3541efa53d578f',
'SEARCH_ID':'739dffd93b144c799698d2940c53b6c1',
'_gat':'1',
'Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6':'1511162236,1511162245,1511162248,1511166955',
'Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6':'1511166955',
'_gid':'GA1.2.697960479.1511162230',
'_ga':'GA1.2.845768630.1503490030',
'LGSID':'20171120163554-d2b13687-cdcd-11e7-996a-5254005c3644',
'PRE_UTM':'' ,
'PRE_HOST':'www.baidu.com',
'PRE_SITE':'https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3D7awz0WxWjKxQwJ9xplXysE6LwOiAde1dreMKkGLhWzS%26wd%3D%26eqid%3D806a75ed0001a451000000035a128181',
'PRE_LAND':'https%3A%2F%2Fwww.lagou.com%2F',
'LGRID':'20171120163554-d2b13811-cdcd-11e7-996a-5254005c3644'
}这是我格式化之后的cookie ,你们可以和原始的cookie进行一下对比
有了cookie之后我们的request需要修改一下,来使用我们获取到的cookie
yield scrapy.Request(url = jobUrl2 ,cookies=self.cookie , callback=self.parse_url)我们在下面定义一个函数叫做parse_url完成回调
整体代码如下:
import scrapy
from First.items import FirstItem
class Lagou(scrapy.Spider):
name = "sean"
start_urls = [
"https://www.lagou.com/"
]
cookie = {
'user_trace_token':'20170823200708-9624d434-87fb-11e7-8e7c-5254005c3644',
'LGUID':'20170823200708-9624dbfd-87fb-11e7-8e7c-5254005c3644 ',
'index_location_city':'%E5%85%A8%E5%9B%BD',
'JSESSIONID':'ABAAABAAAIAACBIB27A20589F52DDD944E69CC53E778FA9',
'TG-TRACK-CODE':'index_code',
'X_HTTP_TOKEN':'5c26ebb801b5138a9e3541efa53d578f',
'SEARCH_ID':'739dffd93b144c799698d2940c53b6c1',
'_gat':'1',
'Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6':'1511162236,1511162245,1511162248,1511166955',
'Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6':'1511166955',
'_gid':'GA1.2.697960479.1511162230',
'_ga':'GA1.2.845768630.1503490030',
'LGSID':'20171120163554-d2b13687-cdcd-11e7-996a-5254005c3644',
'PRE_UTM':'' ,
'PRE_HOST':'www.baidu.com',
'PRE_SITE':'https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3D7awz0WxWjKxQwJ9xplXysE6LwOiAde1dreMKkGLhWzS%26wd%3D%26eqid%3D806a75ed0001a451000000035a128181',
'PRE_LAND':'https%3A%2F%2Fwww.lagou.com%2F',
'LGRID':'20171120163554-d2b13811-cdcd-11e7-996a-5254005c3644'
}
# user_trace_token=20170823200708-9624d434-87fb-11e7-8e7c-5254005c3644; LGUID=20170823200708-9624dbfd-87fb-11e7-8e7c-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; JSESSIONID=ABAAABAACDBAAIA84B4A11C71835DB2C417DD6D1823D3D9; PRE_UTM=m_cf_cpt_baidu_pc; PRE_HOST=bzclk.baidu.com; PRE_SITE=http%3A%2F%2Fbzclk.baidu.com%2Fadrc.php%3Ft%3D06KL00c00f7Ghk60yUKm0FNkUs0Bwkwp00000PW4pNb000005ulRUZ.THL0oUhY1x60UWdBmy-bIy9EUyNxTAT0T1dBuA7-njcvnW0snjDzn1DY0ZRqf16zPjnkrHbvfWPDrj6zP1ckPYRvPDc1f1IAwj-Anjc0mHdL5iuVmv-b5Hnsn1nznjR1njfhTZFEuA-b5HDv0ARqpZwYTZnlQzqLILT8UA7MULR8mvqVQ1qdIAdxTvqdThP-5ydxmvuxmLKYgvF9pywdgLKW0APzm1Y1PjbkPs%26tpl%3Dtpl_10085_15730_11224%26l%3D1500117464%26attach%3Dlocation%253D%2526linkName%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253D%2525E3%252580%252590%2525E6%25258B%252589%2525E5%25258B%2525BE%2525E7%2525BD%252591%2525E3%252580%252591%2525E5%2525AE%252598%2525E7%2525BD%252591-%2525E4%2525B8%252593%2525E6%2525B3%2525A8%2525E4%2525BA%252592%2525E8%252581%252594%2525E7%2525BD%252591%2525E8%252581%25258C%2525E4%2525B8%25259A%2525E6%25259C%2525BA%2526xp%253Did%28%252522m6c247d9c%252522%29%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FH2%25255B1%25255D%25252FA%25255B1%25255D%2526linkType%253D%2526checksum%253D220%26wd%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26issp%3D1%26f%3D8%26ie%3Dutf-8%26rqlang%3Dcn%26tn%3Dbaiduhome_pg%26inputT%3D2975%26sug%3D%2525E6%25258B%252589%2525E5%25258B%2525BE%2525E7%2525BD%252591; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F%3Futm_source%3Dm_cf_cpt_baidu_pc; TG-TRACK-CODE=index_navigation; SEARCH_ID=baf14683532a443db458152ff17699e0; _gid=GA1.2.697960479.1511162230; _ga=GA1.2.845768630.1503490030; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1511251272,1511258443,1511258449,1511278379; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1511278923; LGSID=20171121233256-3f41ebb3-ced1-11e7-9983-5254005c3644; LGRID=20171121234201-8432ac74-ced2-11e7-9983-5254005c3644
def parse(self , response):
for item in response.xpath('//div[@class="menu_box"]/div/dl/dd/a'):
jobClass = item.xpath('text()').extract()
jobUrl = item.xpath("@href").extract_first()
oneItem = FirstItem()
oneItem["jobClass"] = jobClass
oneItem["jobUrl"] = jobUrl
yield scrapy.Request(url = jobUrl ,cookies=self.cookie , callback=self.parse_url)
def parse_url(self , response):
print("parse_url 方法")再次运行爬虫,发现服务器返回的状态码为302(重定向)
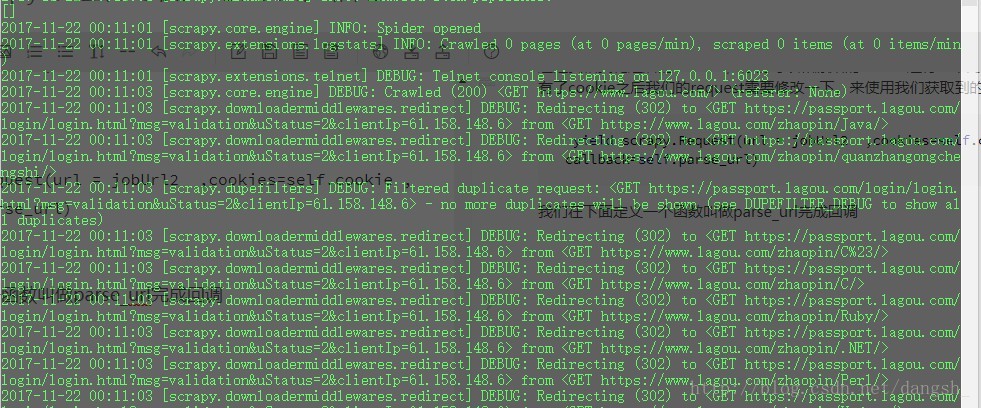
将我们重定向到了拉钩的登录界面,在这个界面我们是无法爬取到数据的,所以我们应该想办法解决这个问题,这也是拉勾的另一个反爬虫机制。
因为我们没有使用浏览器代理来进行请求,拉勾网可以通过这个方式来对我们的爬虫进行重定向,使我们无法获取到数据
我们需要获取到User-Agent
还在刚才获取cookie的页面,在一个角落里我们发现了这个User-Agent
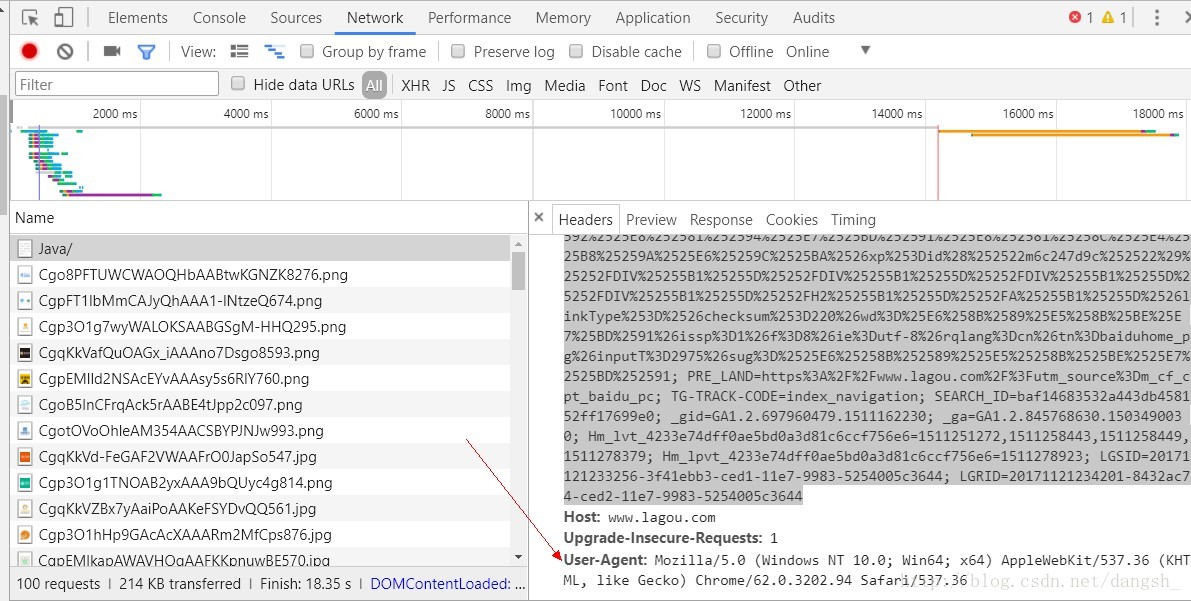
那么我们怎么去使用它呢?
先在settings.py文件中进行如下设置
MY_USER_AGENT = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
]
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
'First.middlewares.MyUserAgentMiddleware': 400,
}这里User-Agent可以设置多个,我这里进行举例,使用两个,随后我们会随机取出一个进行使用
下面是对DOWNLOADER_MIDDLEWARES(下载中间件)进行设置,
然后进入middlewares.py文件,进行User-Agent的选择
首先导入我们需要的模块
import scrapy
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
在下面定义类,继承UserAgentMiddleware,对User-Agent进行设置
class MyUserAgentMiddleware(UserAgentMiddleware):
# 设置User-Agent
def __init__(self, user_agent):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
return cls(
user_agent=crawler.settings.get('MY_USER_AGENT')
)
def process_request(self, request, spider):
agent = random.choice(self.user_agent)
request.headers['User-Agent'] = agent再次启动爬虫,服务器返回状态码200,请求成功,成功回调
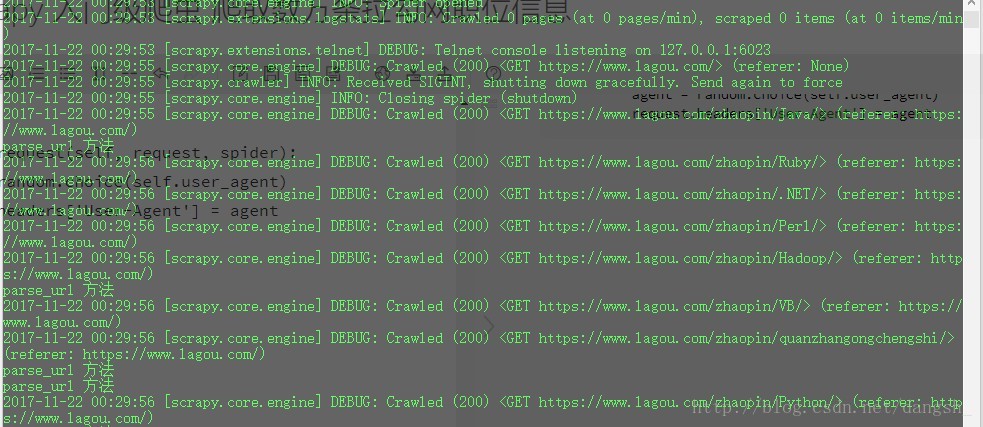
接下来我们又需要分析网站的结构,来获取到自己需要的数据
还是使用之前的方法,
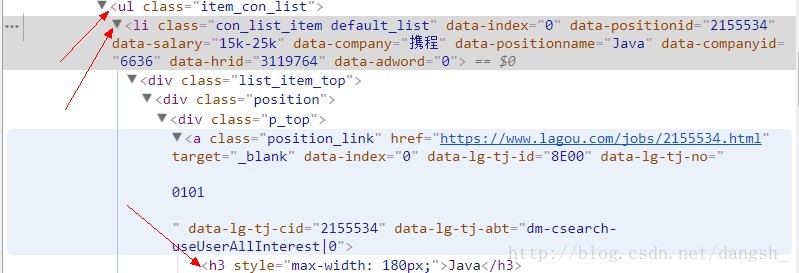
还是使用xpath选择器选择出所需要的数据,
for sel2 in response.xpath('//ul[@class="item_con_list"]/li'):
jobName = sel2.xpath('div/div/div/a/h3/text()').extract()
jobMoney = sel2.xpath('div/div/div/div/span/text()').extract()
jobNeed = sel2.xpath('div/div/div/div/text()').extract()
jobCompany = sel2.xpath('div/div/div/a/text()').extract()
jobType = sel2.xpath('div/div/div/text()').extract()
jobSpesk = sel2.xpath('div[@class="list_item_bot"]/div/text()').extract()
这个大家可以自己进行尝试,不只这一种选择方法,我之后也会对我的选择方法进行优化,现在只求得到数据
在items.py文件中进行声明
jobName = scrapy.Field()
jobMoney = scrapy.Field()
jobNeed = scrapy.Field()
jobCompany = scrapy.Field()
jobType = scrapy.Field()
jobSpesk = scrapy.Field()再在second.py中进行存储,并且yield Item
Item = FirstItem()
Item["jobName"] = jobName
Item["jobMoney"] = jobMoney
Item["jobNeed"] = jobNeed
Item["jobCompany"] = jobCompany
Item["jobType"] = jobType
Item["jobSpesk"] = jobSpesk
yield Item在终端命令下输入scrapy crawl sean -o shujv2.json 执行爬虫,并将爬取到的数据放入shujv2.json文件中
结束之后打开shujv2.json文件
如图所示
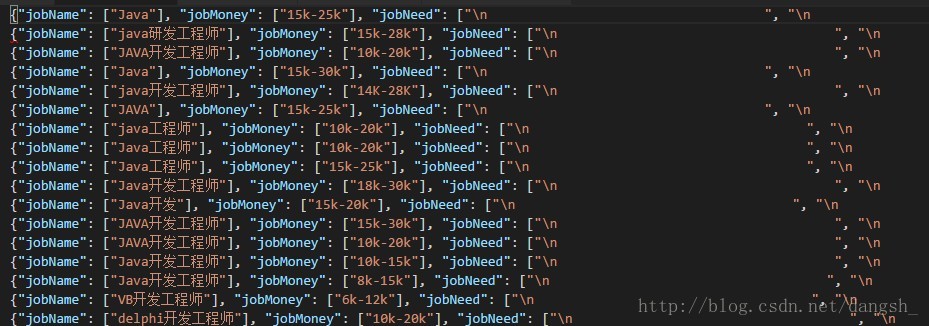
前半部分看起来正常,但是后半部分却多了很多换行符,我们需要对换行符进行处理,我们暂且选择strip的方法进行选取,之后再进行优化。
修改代码如下:
jobName = sel2.xpath('div/div/div/a/h3/text()').extract()
jobMoney = sel2.xpath('div/div/div/div/span/text()').extract()
jobNeed = sel2.xpath('div/div/div/div/text()').extract()
jobNeed = jobNeed[2].strip()
jobCompany = sel2.xpath('div/div/div/a/text()').extract()
jobCompany =jobCompany[3].strip()
jobType = sel2.xpath('div/div/div/text()').extract()
jobType = jobType[7].strip()
jobSpesk = sel2.xpath('div[@class="list_item_bot"]/div/text()').extract()
jobSpesk =jobSpesk[-1].strip()清空shujv2.json ,再次运行爬虫
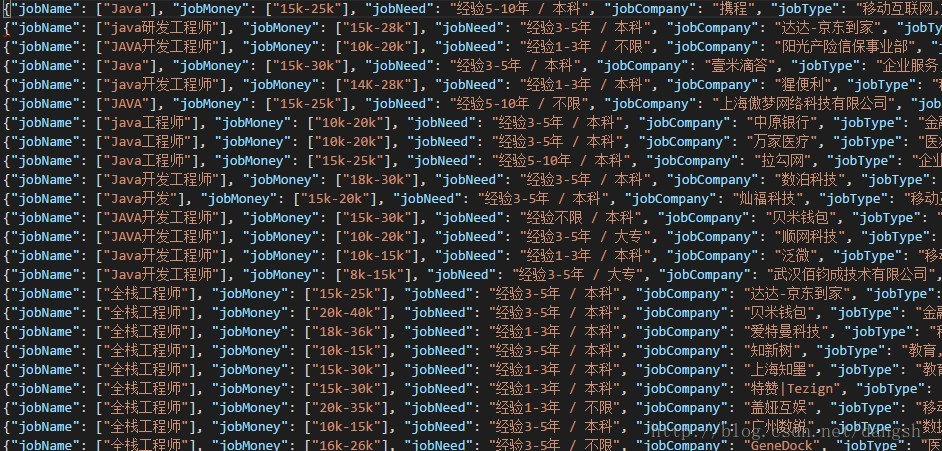
问题得以解决。
项目基本完成,但是还有一个问题,我们这只是爬取到了没一种工作的第一页的数据,我们还需要换页。如图所示有30页,我们只爬取到了第一页

通过测试换页,我们可以发现页数的规律
第一页https://www.lagou.com/zhaopin/Java/
第二页https://www.lagou.com/zhaopin/Java/2
第三页https://www.lagou.com/zhaopin/Java/3
那就很简单了,我们只需要在jobUrl后面拼接1-30数字就可以了
修改代码如下:
for i in range(30):
jobUrl2 = jobUrl + str(i+1)
# print(jobUrl2)
try:
yield scrapy.Request(url = jobUrl2 ,cookies=self.cookie , meta = {"jobClass":jobClass} , callback=self.parse_url)
except:
pass用jobUrl2接收拼接后的url,请求这个url,一共循环30次。
为了防止有的工作不是30页,我们将请求语句用try。。。except。。。包括,防止出现BUG,
再次运行爬虫,疯狂的爬取数据。我运行了20min,大概爬取到了8W条数据。
我是python爬虫新手,我的爬虫有很多不足的地方~希望大家不吝指教
我也是CSDN博客的新手,写文章也有很多不足,欢迎大家指正~共同学习
最后附项目github地址
最后
以上就是靓丽夕阳最近收集整理的关于python3 scrapy 入门级爬虫 爬取数万条拉勾网职位信息的全部内容,更多相关python3内容请搜索靠谱客的其他文章。








发表评论 取消回复