前面已经说过,Scrapy的瓶颈被设置在下载器这个地方。要获得最高的性能,可以从一个低的CONCURRENT_REQUESTS开始,一直增加这个值,直到达到了以下某个限制:
- CPU使用率达到80-90%
- 目标网站的延迟显著上升
- scraper(即爬虫和pipeline)中的所有
Response对象占用的总内存大小不超过5MB
同时还要保证以下条件:
- 在任何时候都要保证调度器的队列(mqs/dqs)中有一些
Request,以保证下载器中的请求数量 - 永远不要使用阻塞的代码或者CPU密集型的代码(这种情况下应该使用另一个线程处理)
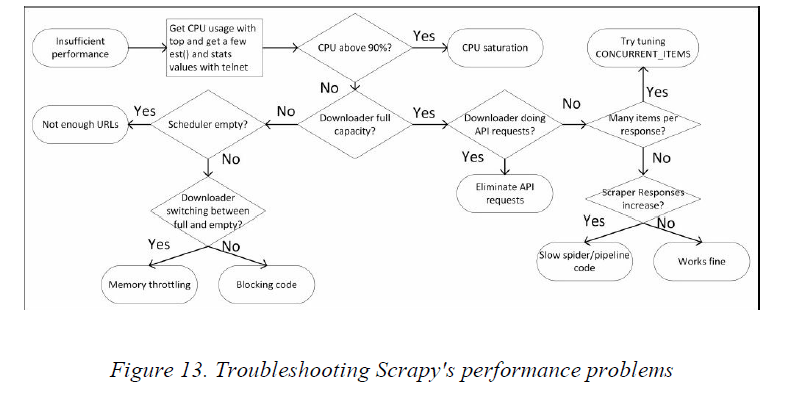
上图总结了诊断并修复Scrapy性能问题的步骤。
最后
以上就是背后野狼最近收集整理的关于Scrapy性能调优及检测性能问题的步骤的全部内容,更多相关Scrapy性能调优及检测性能问题内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复