症状:系统非常慢,与期望的相差很大,并且当你修改CONCURRENT_REQUESTS的值的时候,速度并没有发生变化。下载器看起来几乎是空的(比CONCURRENT_REQUESTS的值要小),scraper中只有少量一些Response对象。
示例:你可以使用这两个设置项(爬虫代码见这里):SPEED_SPIDER_BLOCKING_DELAY和SPEED_PIPELINE_BLOCKING_DELAY来使得对于每个响应都会有一个100ms的阻塞延迟。我们希望对于100个URL花费2-3s来完成,然而不管如何设置CONCURRENT_REQUESTS的值,结果都是花费了13s左右。
for concurrent in 16 32 64; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=100
-s CONCURRENT_REQUESTS=$concurrent -s SPEED_SPIDER_BLOCKING_DELAY=0.1
done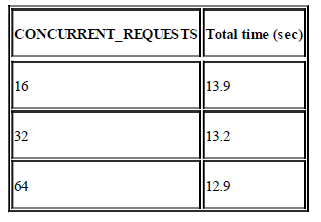
讨论:只要有阻塞的代码,那么Scrapy的并发性就毫无作用了,相当于设置了CONCURRENT_REQUESTS = 1。100个URL * 100ms(阻塞的延迟)= 10s + 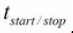 ,大概就是13s了,这样就能解释为什么会出现上面的情况了。
,大概就是13s了,这样就能解释为什么会出现上面的情况了。
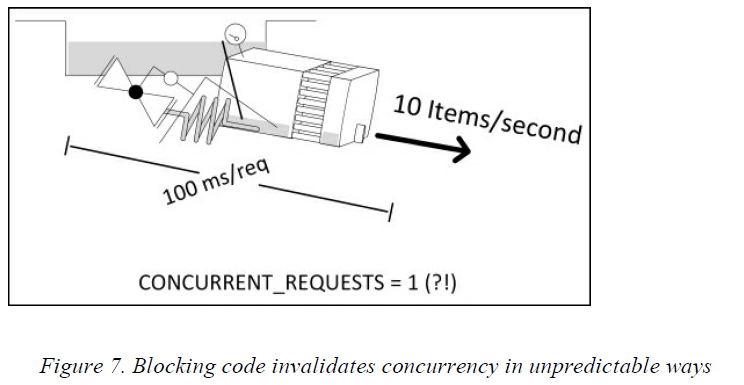
不管阻塞的代码是在pipeline中还是在爬虫中,你都会看到scraper被占满了,并且在它之前或者之后的组件都是空的。这似乎和之前讲过的pipeline的特点有些不符,但是现在已经并不是一个并发的系统了,所以之前的规则已经不适用了。我们很容易就会犯这样的错误,例如使用了阻塞的API,这样在运行的过程中一定会出现这种情况。同时也要注意不要写计算过于复杂的代码,对于这些代码应该使用多线程来处理,或者在Scrapy外进行批处理。
解决方法:如果整个系统不用添加任何pipeline就能运行,那么就先禁用所有的pipeline然后再检查这种情况是不是还在。如果还是这样,那么阻塞的代码就在爬虫中,如果这种情况不见了,那么阻塞的代码就在pipeline中。然后再一个一个地禁用pipeline并且观察什么时候问题以重新出现了。但是如果整个系统不能在没有任何一个组件的时候运行起来,那么可以在每个pipeline中加上日志信息并打上时间戳,通过检查日志就能发现你的系统在哪花费的时间最多。如果需要一种可重用性比较强的方法,那么可以在系统中加上一些没有实际功能的pipeline来跟踪Request对象的处理过程,这些pipeline唯一的功能就是添加时间戳,最后再关联一下item_scraped信号,把时间戳记录到日志中。在发现了阻塞代码的位置之后,把它替换成Twisted/异步的代码,或者使用Twisted的线程池。要试一下这种转换的效果,可以把SPEED_PIPELINE_BLOCKING_DELAY替换成SPEED_PIPELINE_ASYNC_DELAY再运行一下示例,就能发现性能的改变是惊人的。
最后
以上就是紧张大米最近收集整理的关于解决Scrapy性能问题——案例二(含有阻塞的代码)的全部内容,更多相关解决Scrapy性能问题——案例二(含有阻塞内容请搜索靠谱客的其他文章。








发表评论 取消回复