目录
- 前言
- 一、网页分析
- 二、主要代码
- 1.请求Json包
- 2. Guesstoken获取
- 2.Json文件解析
- 3.存入xlsx
- 运行效果
- 名人信息解析获取
- 存入excel
- 总结
前言
最近在帮助做BD的哥们寻找社交媒体红人,目前主要是Twitter,Youtube,Instagram,以及微博,B站,知乎这几个平台,根据关键词去自动获取满足相关条件的名人,对名人做一个初步的筛选,方便后续联系,因此设计了一套社交名人爬虫系统,目前已经在稳定使用中,有需要使用的朋友也可以联系。

今天大概讲一下Twitter的抓取,Twitter作为一款世界级的媒体平台,拥有大量的用户以及用户发布的海量信息,价值巨大。Github以及Twitter本身也有API或者抓取工具,但都并不是很符合我的使用需求,因此自己根据Twitter现有的接口设计了一套。
一、网页分析
由于我只需要查找根据关键词查找推文,从而获取相关的用户。因此我选择的是不需要登录的接口,根据查询网上的信息,找到Twitter高级搜索的网址:Twitter高级搜索
进入之后可以看到页面如下
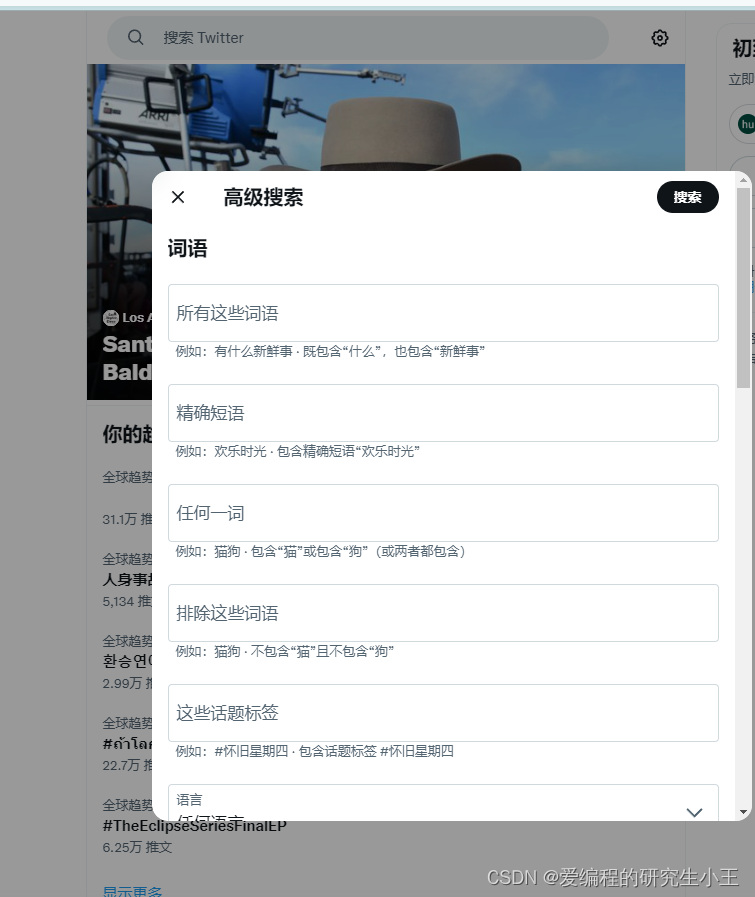
使用F12打开网络分析,随便输入关键词与筛选条件,获取相关请求,如图所示,搜索BItcoin相关的名人,从2021年到2022年的,就可以获取到相关的推文以及用户。
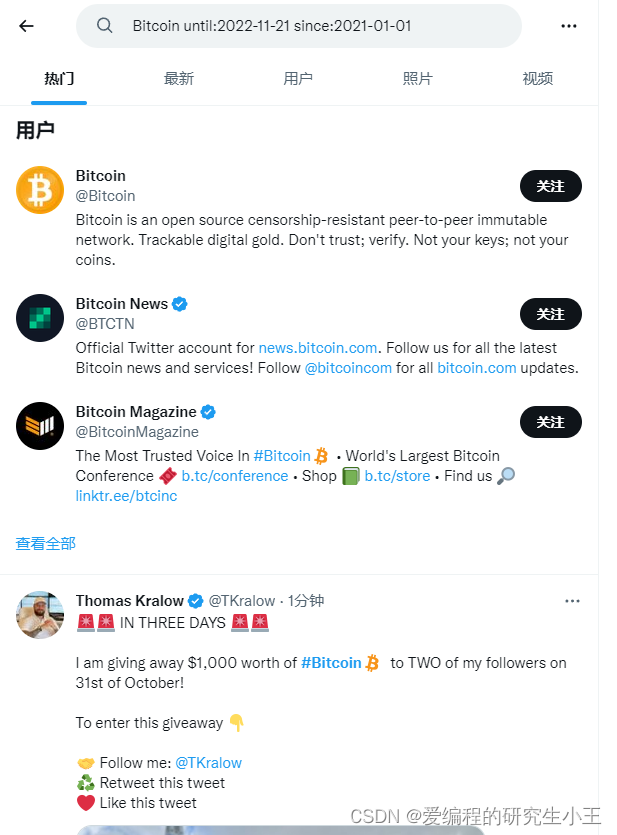
进入网络,就可以看到所有的请求包,此时就需要对这些包进行分析,如果里面包含有我们需要的数据,我们使用request等网络请求包模拟相关请求获取数据即可。
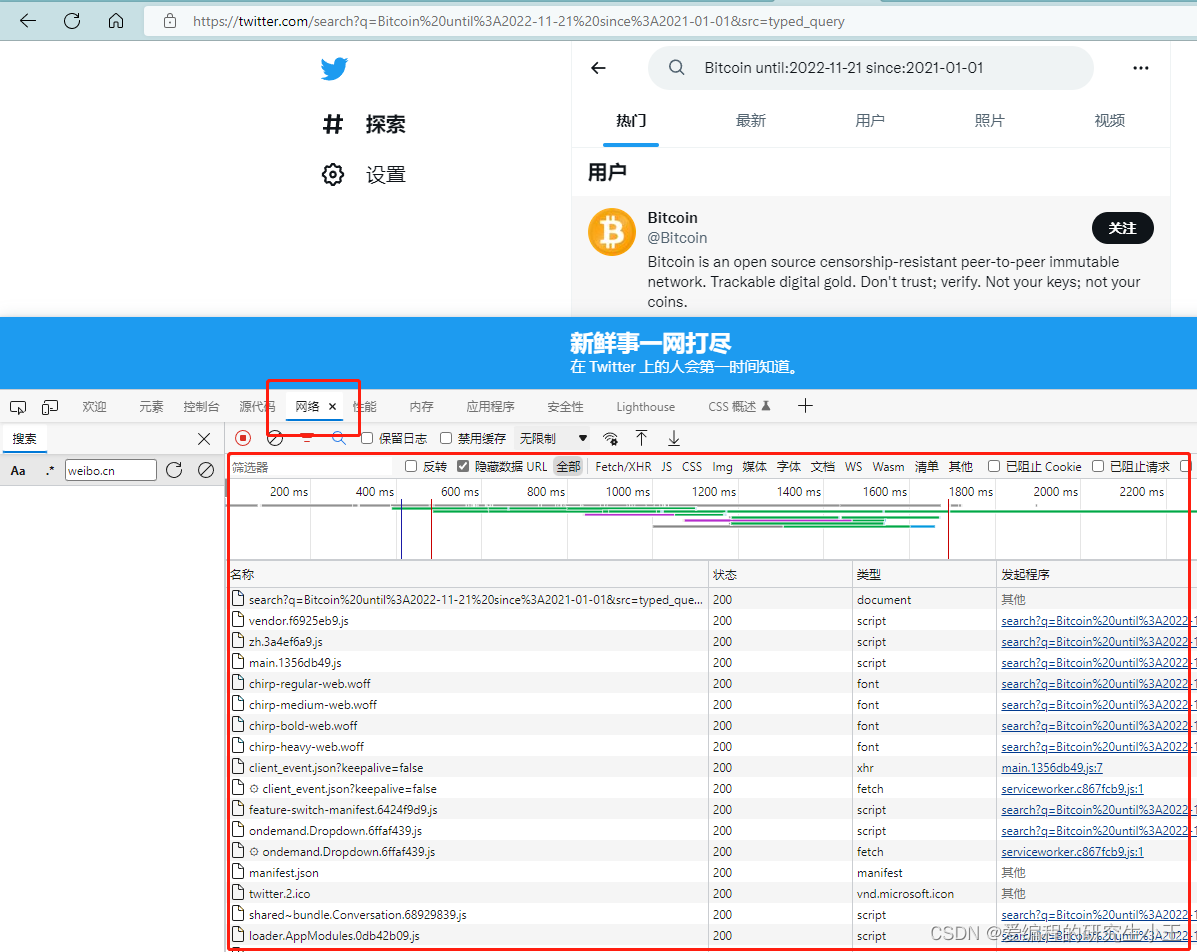
经过一通分析,发现推文相关JSON文件在下图的这个包里。接下来的事情就比较好办了,直接右键点击包,选择复制,复制为cURL(bash),然后打开cURL转Python程序的网站,将请求转为Python代码。
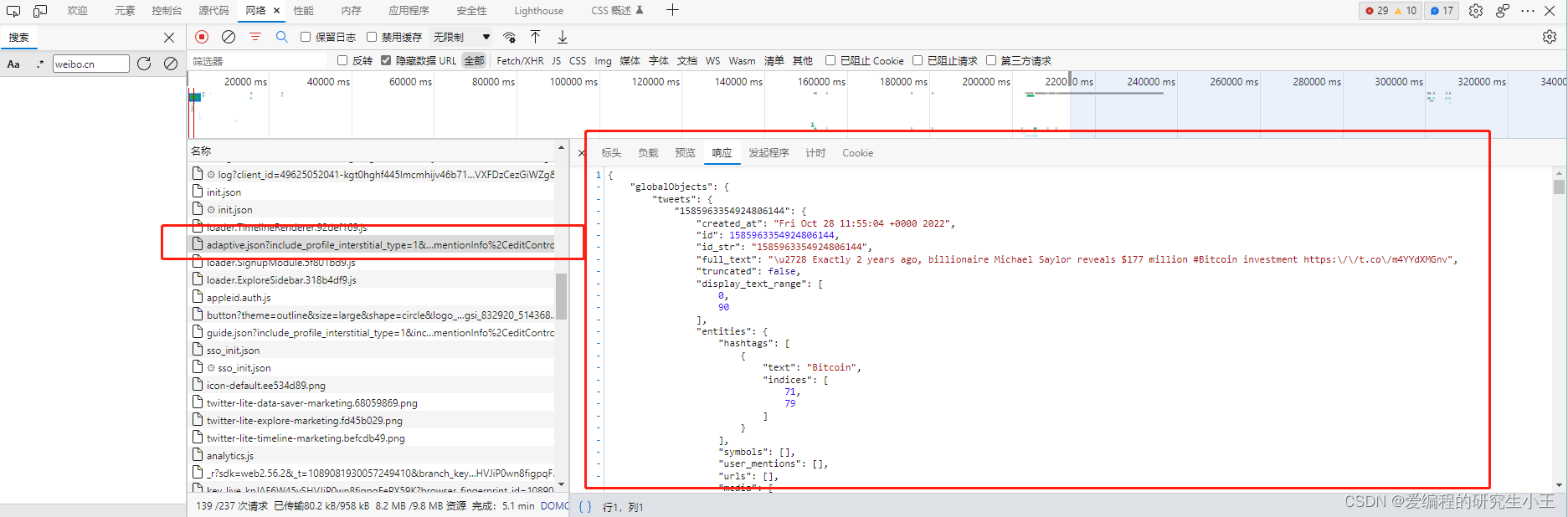
直接复制出Python代码即可
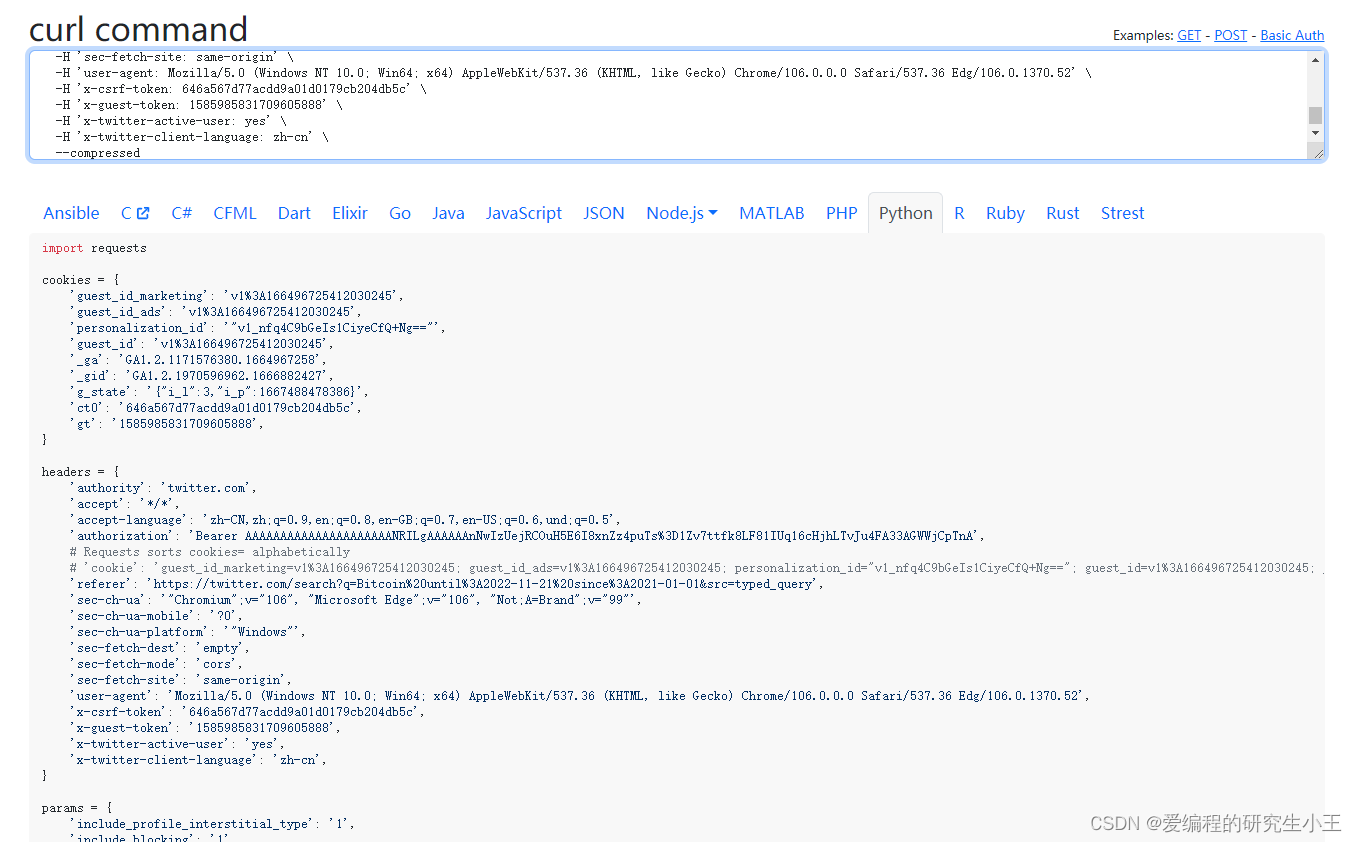
二、主要代码
1.请求Json包
代码如下
import requests
cookies = {
'guest_id_marketing': 'v1%3A166496725412030245',
'guest_id_ads': 'v1%3A166496725412030245',
'personalization_id': '"v1_nfq4C9bGeIs1CiyeCfQ+Ng=="',
'guest_id': 'v1%3A166496725412030245',
'_ga': 'GA1.2.1171576380.1664967258',
'_gid': 'GA1.2.1970596962.1666882427',
'g_state': '{"i_l":3,"i_p":1667488478386}',
'ct0': '646a567d77acdd9a01d0179cb204db5c',
'gt': '1585985831709605888',
}
headers = {
'authority': 'twitter.com',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,und;q=0.5',
'authorization': 'Bearer AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA',
# Requests sorts cookies= alphabetically
# 'cookie': 'guest_id_marketing=v1%3A166496725412030245; guest_id_ads=v1%3A166496725412030245; personalization_id="v1_nfq4C9bGeIs1CiyeCfQ+Ng=="; guest_id=v1%3A166496725412030245; _ga=GA1.2.1171576380.1664967258; _gid=GA1.2.1970596962.1666882427; g_state={"i_l":3,"i_p":1667488478386}; ct0=646a567d77acdd9a01d0179cb204db5c; gt=1585985831709605888',
'referer': 'https://twitter.com/search?q=Bitcoin%20until%3A2022-11-21%20since%3A2021-01-01&src=typed_query',
'sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.52',
'x-csrf-token': '646a567d77acdd9a01d0179cb204db5c',
'x-guest-token': '1585985831709605888',
'x-twitter-active-user': 'yes',
'x-twitter-client-language': 'zh-cn',
}
params = {
'include_profile_interstitial_type': '1',
'include_blocking': '1',
'include_blocked_by': '1',
'include_followed_by': '1',
'include_want_retweets': '1',
'include_mute_edge': '1',
'include_can_dm': '1',
'include_can_media_tag': '1',
'include_ext_has_nft_avatar': '1',
'skip_status': '1',
'cards_platform': 'Web-12',
'include_cards': '1',
'include_ext_alt_text': 'true',
'include_ext_limited_action_results': 'false',
'include_quote_count': 'true',
'include_reply_count': '1',
'tweet_mode': 'extended',
'include_ext_collab_control': 'true',
'include_entities': 'true',
'include_user_entities': 'true',
'include_ext_media_color': 'true',
'include_ext_media_availability': 'true',
'include_ext_sensitive_media_warning': 'true',
'include_ext_trusted_friends_metadata': 'true',
'send_error_codes': 'true',
'simple_quoted_tweet': 'true',
'q': 'Bitcoin until:2022-11-21 since:2021-01-01',
'count': '20',
'query_source': 'typed_query',
'pc': '1',
'spelling_corrections': '1',
'include_ext_edit_control': 'true',
'ext': 'mediaStats,highlightedLabel,hasNftAvatar,voiceInfo,enrichments,superFollowMetadata,unmentionInfo,editControl,collab_control,vibe',
}
response = requests.get('https://twitter.com/i/api/2/search/adaptive.json', params=params, cookies=cookies, headers=headers)
2. Guesstoken获取
经过测试,如果过多的请求使用同样的guess_token会导致获取不到数据的情况,因此,需要隔一段时间获取一次guess_token,guess_经过分析,guess_token获取只需要每隔一段时间给服务器发送一次请求即可。token获取链接如下:token获取
代码如下:
url_token = "https://api.twitter.com/1.1/guest/activate.json"
def get_token():
token = json.loads(requests.post(url_token, headers=headers).text)['guest_token']
headers['x-guest-token'] = token
2.Json文件解析
代码如下:
def parse_Twitter_users(country,keyword,content_json):
jsondata = JsonSearch(object=content_json, mode='j')
# channelAboutFullMetadataRenderer
# print(1)
rows = []
user_ids = jsondata.search_all_value(key='users')
screen_names = jsondata.search_all_value(key='screen_name')
locations = jsondata.search_all_value(key='location')
descriptions = jsondata.search_all_value(key='description')
followers_counts = jsondata.search_all_value(key='followers_count')
friends_counts = jsondata.search_all_value(key='friends_count')
cursor_data = jsondata.search_all_value("cursor")
cursor_data = JsonSearch(object=cursor_data, mode='j')
cursor_value = jsondata.search_all_value(key='value')
print(cursor_value)
for idx,name in enumerate(screen_names):
print('第{}个数据'.format(idx))
screen_name = screen_names[idx]
url = "https://www.twitter.com/"+str(screen_names[idx])
flag = filter_already_browsId(country, keyword, url)
if flag:
with open('already_word/{}_already_browsId.txt'.format(country), 'a+', encoding='utf-8') as fp:
fp.write(url + 'n')
location = locations[idx]
description = descriptions[idx]
followers_count = followers_counts[idx]
friends_count = friends_counts[idx]
row = [screen_name,url,location,description,followers_count,friends_count]
rows.append(row)
print(rows)
print(len(rows))
return rows,cursor_value
3.存入xlsx
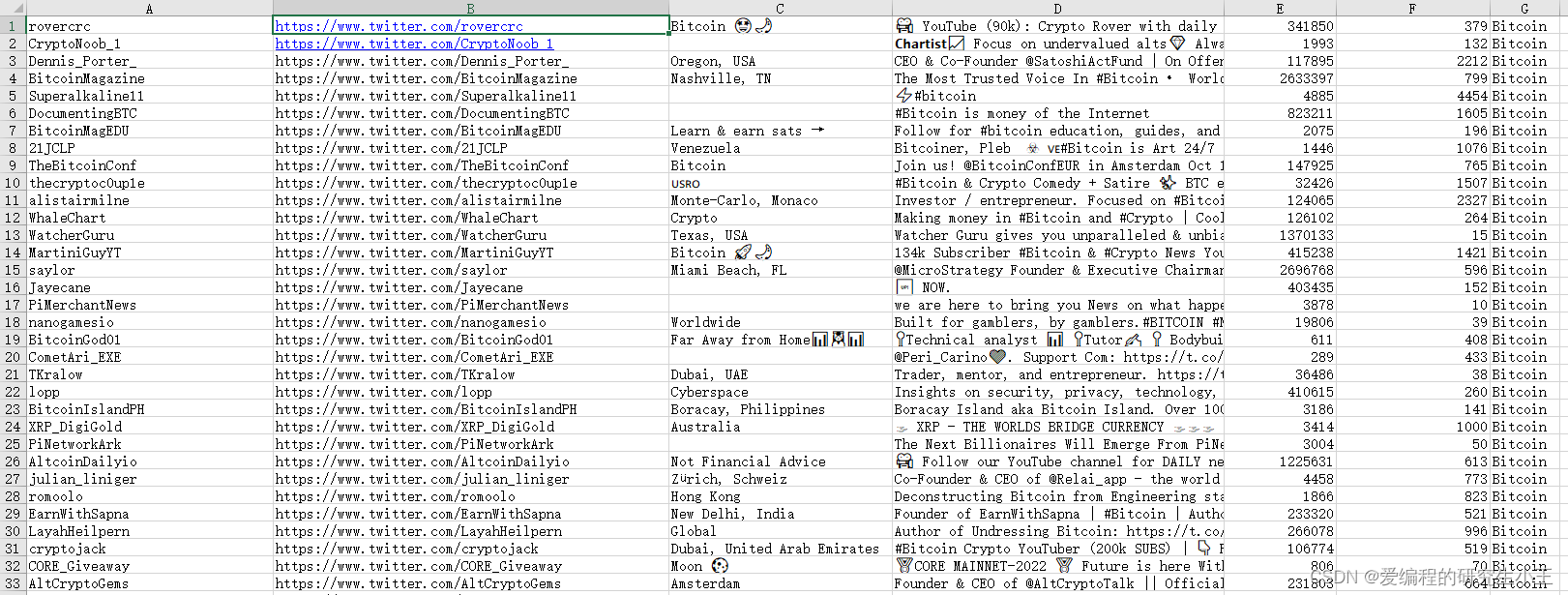
保存我是要的是openxyl库进行保存,将相关信息追加存入excel进行保存
import os
import time
import openpyxl
from openpyxl import Workbook
def save(location,keyword,rows):
print('正在保存:{}'.format(rows))
save_rows = []
for row in rows:
row.append(keyword)
save_rows.append(row)
print("{}录入成功".format(str(rows)))
# craw_t = time.strftime('%Y_%m_%d', time.localtime(time.time()))
# csvfilename = '../../../Datas/{}_youtube_keyword_{}_5000.xlsx'.format(craw_t,keyword)
csvfilename = '../../../Datas/Twitter/Twitter_{}.xlsx'.format(location)
'''
只需要进行追加插入即可
'''
if os.path.exists(csvfilename):
workbook = openpyxl.load_workbook(csvfilename)
else:
workbook = Workbook()
save_file = csvfilename
worksheet = workbook.active
# 每个workbook创建后,默认会存在一个worksheet,对默认的worksheet进行重命名
worksheet.title = "Sheet1"
max_row = worksheet.max_row
for r in range(len(save_rows)):
for c in range(len(save_rows[0])):
try:
worksheet.cell(r + max_row, c + 1).value = save_rows[r][c]
except:
worksheet.cell(r + max_row, c + 1).value = ''
workbook.save(filename=save_file)
print('保存成功')
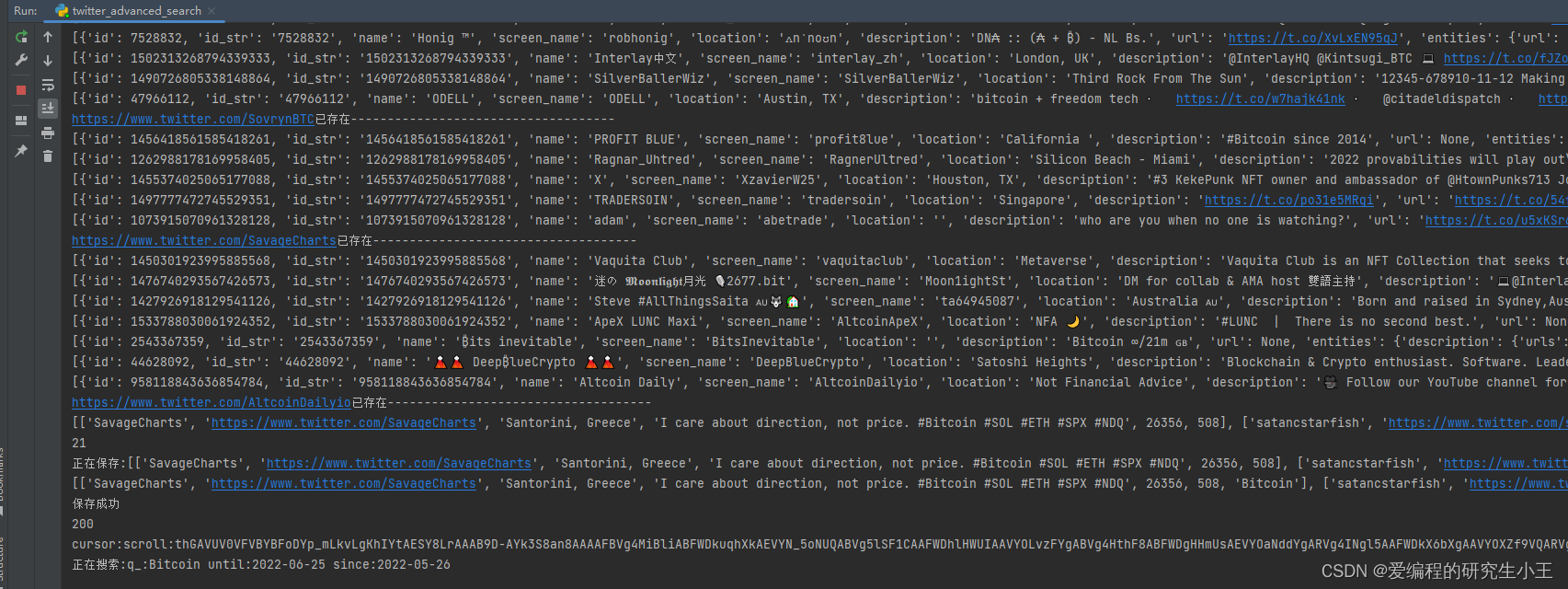
运行效果
名人信息解析获取
存入excel
总结
以上就是对twitter搜索的整个抓取过程,目前已经稳定运行。上述只是简易版本,高级版本目前可以获取用户,推文以及用户粉丝的信息,主要服务运营以及科研相关获取数据。其他相关社媒获取分析也会在后续更新,欢迎催更。
最后
以上就是直率纸飞机最近收集整理的关于【2022 Twitter爬虫高级搜索接口分析及代码编写 Python爬虫 附主要代码及解析】前言一、网页分析二、主要代码运行效果总结的全部内容,更多相关【2022内容请搜索靠谱客的其他文章。








发表评论 取消回复