我是靠谱客的博主 优美抽屉,这篇文章主要介绍爬虫网络请求模块-urllib-requests-python爬虫知识点2爬虫网络请求模块一、urllib二、requests,现在分享给大家,希望可以做个参考。
爬虫网络请求模块
步骤
- 发出请求
获取响应
解析响应
一、urllib
python内置的网络请求模块
版本
- python2 :urllib2、urllib
python3 :把urllib和urllib2合并
学习意义
- 1.有些比较老的爬虫项目就是这个技术
- 2.有的时候我们去怕一些数据需要reque+urlib模块进行配合
- 3.内置的
导包注意
- 直接import urllib不行的话,就一个一个像这样导urllib.request
(一)请求并获取urllib.request
request.Request(url,headers)
创建请求对象
- get请求: req=urllib.request.Request(url,headers)
- post请求: req=urllib.request.Request(url,data,headers)
- data必须是字节流bytes, 是由字典通过parse.urlencode()转化为str,再通过bytes()转化为bytes字节流
request.urlopen(req)
想网站发起请求,并获取响应对象
- urllib.request.urlopen(‘网址’),可以直接填网址,但不能添加headers,不好反反爬
- urllib.request.urlopen(req),请求对象自带headers就行
request.urlretrive(url,'文件名')
将请求链接直接下载保存为文件
- 一般用于图片下载
- 不能添加headers
(二)处理编码urlib.parse
parse.urlencode(wd)
编码url的中文字段
- wd 参数是字典 ,key是链接中“=”的左边关键字,value是链接中“=”的右边中文字
作用
- url 汉字要进行编码,网址到编辑器就会变成十六进制+%(三个%之间表示一个汉字),因为机器无法识别汉字,需要进行编码
- 如果你把网址的十六进制改为中文,就会报错

parse.quote(wd)
编码url的中文字段
- wd是字符串,不带关键字,直接将中文字符串转成编码
parse.unquote(wd)
解码十六进制+%
- wd是字符串,不带关键字,直接将中文字符串转成编码
作用
- 有的时候爬下来的链接http后面全都是十六进制+%,这个时候就需要把它转化为正常的链接
(三)对响应对象操作
定义
- response = request.urlopen(req) 获取的响应对象
- 没有text、content方法
区分
- get响应对象:<class ‘http.client.HTTPResponse’>
- post响应对象:<class ‘urllib.request.Request’>
response.read()
读取html信息
- 返回的是bytes
- response.read().decode(‘utf-8’) 将返回的内容转化为字符串,并显现出中文字
- 数据获取的是少量bytes,非图片链接
- 说明被反爬了,并进一步观察是否要添加修改headers信息
response.getcode()
查看状态码
response.geturl()返回请求地址
返回请求地址
- 返回实际数据的URL(防止重定向问题)
(四)urllib实现
找请求文件:headers的url正确,请求状态码Status Code: 200 OK 是请求成功
urllib get请求
获取百度搜索相应内容的网页源代码
- get请求,不会对服务器产生影响,响应结果就是网页源代码

import urllib.request
import urllib.parse
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
search_word = '肖战壁纸'
word = urllib.parse.quote(search_word)
url = 'https://www.baidu.com/s?wd=' + word
## 获取请求对象
req = urllib.request.Request(url, headers=headers)
## 获取响应对象
response = urllib.request.urlopen(req)
print(type(response)) # <class 'http.client.HTTPResponse'>
## 解析响应对象
content = response.read() # <class 'bytes'>
print(type(content)) # <class 'bytes'>
print(content.decode('utf-8'))# str

urllib post请求
小型翻译软件
- post请求,会对服务器产生影响,响应结果在response里面,response是json类型的字符串

- post请求的url没有携带向服务器发出的请求内容,所以请求对象创建的时候要加data,从这里获取data
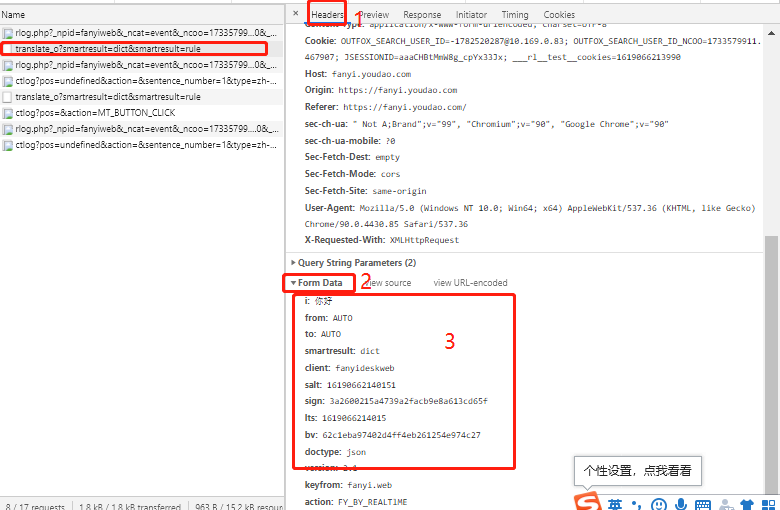
import urllib.request
import urllib.parse
import json
# 请输入您要翻译的内容
content = input('请输入您要翻译的内容:')
# Form data
data = {
'i': content,
'from': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15880623642174',
'sign': 'c6c2e897040e6cbde00cd04589e71d4e',
'ts': '1588062364217',
'bv': '42160534cfa82a6884077598362bbc9d',
'doctype': 'json',
'version': '2.1',
'keyfrom':'fanyi.web',
'action': 'FY_BY_CLICKBUTTION'
}
data = urllib.parse.urlencode(data) ## str
# print(type(data))
data = bytes(data,'utf-8') # bytes,TypeError: string argument without an encoding
# 目标url 去掉_o
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
req = urllib.request.Request(url,data=data,headers=headers)
res = urllib.request.urlopen(req) # # <class 'urllib.request.Request'>
html = res.read().decode('utf-8') ## <class 'str'>
# print(html) # json类型的字符串
# 把json类型的字符串就可以转换成python类型的字典
r_dict = json.loads(html)
# 解析数据
r = r_dict['translateResult'] # [[{"src":"hello","tgt":"你好"}]]
result = r[0][0]['tgt'] # [{"src":"hello","tgt":"你好"}] ->{"src":"hello","tgt":"你好"} -> "你好"
print(result)

二、requests
安装
- pip install requests
pip install requests -i https://pypi.douban.com/simple 90%以上
特点
- 强大
- 便捷
(一)请求并获取
与urllib的区别
- url 可以含中文,不用转码
- params=kw 可以直接拼接url,不需要另外合并在url上,kw可以直接字典格式,而urllib 没有params,需要把url拼接好,也不允许有中文字符串
- 可以直接在获取响应对象加headers,而urllib是要在设置请求对象里面加
- data 直接是字典类型,而urllib是bytes
requests.get
get获取响应对象
- requests.get(url,params=kw,headers)
- kw 类型是字典
requests.post
post获取响应对象
- requests.get(url,params=kw,data,headers)
- kw 类型是字典
- data 类型是字典
(二)对响应对象response操作
与urllib 区别
- read() 要加()
- content、text不加()
response.content
拿出response的源代码
- 类型是bytes
- 源代码,不作任何处理
- response.content.decode(‘utf-8’) 得到字符串格式的网页源代码
response.text
将content解码为字符串
- 类型字符串
- 是在 response.content 后,默认自行猜解码格式,并解码,所以可能会出现乱码
出现乱码怎么解决
大部分网页编码是utf-8,可以通过网页源代码查看charset=“utf-8”,看源代码编码的格式
response.content 出现乱码
- 解码decode
- response.content.decode(‘utf-8’)
response.text 出现乱码
- 给定解码格式
- 出现乱码是解释器猜解码格式猜错了
- response.encoding = ‘utf-8’
(三)requests实现
requests get请求
获取百度搜索相应内容的网页源代码
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
url = 'https://www.baidu.com/s?wd= 肖战壁纸'
## 获取响应对象
response = requests.get(url, headers=headers) #<class 'requests.models.Response'>
# ## 解析响应对象
# 1.content
# html = response.content # <class 'bytes'>
# print(html.decode('utf-8'))
# 2.text
response.encoding = 'utf-8'
detail = response.text # <class 'str'>
print(detail)
requests post请求
小型翻译软件
import requests
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
content = input('请输入你要翻译的内容:')
data = {
'i': content,
'from': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15880623642174',
'sign': 'c6c2e897040e6cbde00cd04589e71d4e',
'ts': '1588062364217',
'bv': '42160534cfa82a6884077598362bbc9d',
'doctype': 'json',
'version': '2.1',
'keyfrom':'fanyi.web',
'action': 'FY_BY_CLICKBUTTION'
}
url = 'https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
## 获取响应对象
response = requests.post(url, data = data, headers=headers) #<class 'requests.models.Response'>
# ## 解析响应对象
# 1.content
html = response.content.decode('utf-8') # <class 'bytes'>
r_dict = json.loads(html)
print(r_dict['translateResult'][0][0]['tgt'])
# 2.text
# response.encoding = 'utf-8'
# detail = response.text # <class 'str'>
# r_dict = json.loads(detail)
# print(r_dict['translateResult'][0][0]['tgt'])
百度贴吧的练习
需求:
- 1.输入你要的主题
2.爬好几页,要进行翻页,爬前10页
3.爬取每页的源代码,并保存为文件
方法:
- 1.查找链接地址规律:
- 第一页:https://tieba.baidu.com/f?ie=utf-8&kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search
第二页:https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=50
第三页:https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=100 - kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B 海贼王的搜索
- pn= 50*(i-1) 代表页数
- 其他信息删掉看能否打开页面,如果可以的话直接删掉,缩短网址
- 不同信息之间用&链接
- 第一页:https://tieba.baidu.com/f?ie=utf-8&kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search
- 2.进行翻页for range
- 3.保存为文件
后面的代码都注意要改写成面对对象的方法
urllib
import urllib.request
import urllib.parse
class BaiduSpider:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
self.base_url = 'https://tieba.baidu.com/f?'
def readPage(self,url):
req = urllib.request.Request(url, headers=self.headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
return html
def writePage(self,filename,html):
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
print('写入成功')
def main(self):
name = input('请输入您要爬取的贴吧主题:')
begin = int(input('请输入起始页:'))
end = int(input('请输入终止页:'))
kw = {'kw': name}
result = urllib.parse.urlencode(kw)
for i in range(begin, end + 1):
pn = (i - 1) * 50
url = self.base_url + result + '&pn=' + str(pn)
# 调用函数
html = self.readPage(url)
filename = '第' + str(i) + '页.html'
self.writePage(filename, html)
if __name__ == '__main__':
spider = BaiduSpider()
spider.main()
requests
import requests
class BaiduSpider:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
self.base_url = 'https://tieba.baidu.com/f?'
def readPage(self,kw):
res = requests.get(self.base_url,params=kw,headers=self.headers)
html = res.content.decode('utf-8')
return html
def writePage(self, filename, html, i):
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
print('第%d页下载完成' % i)
def main(self):
name = input('请输入您要爬取的贴吧主题:')
begin = int(input('请输入起始页:'))
end = int(input('请输入终止页:'))
kw = {'kw': name}
for i in range(begin, end + 1):
kw['pn'] = str(50 ^ i)
# 调用函数
html = self.readPage(kw)
filename = '第' + str(i) + '页.html'
self.writePage(filename, html, i)
if __name__ == '__main__':
spider = BaiduSpider()
spider.main()
最后
以上就是优美抽屉最近收集整理的关于爬虫网络请求模块-urllib-requests-python爬虫知识点2爬虫网络请求模块一、urllib二、requests的全部内容,更多相关爬虫网络请求模块-urllib-requests-python爬虫知识点2爬虫网络请求模块一、urllib二、requests内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。


![[网络]网络爬虫网络爬虫详细讲解:](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)





发表评论 取消回复