之所以将这三个放在一起,主要是在学习的时候,感觉他们之间有很大的关联,是一大类非监督学习,且其中的主要算法都可以从这几个学习方法的角度来解释。我的一个不成熟的解释是,这三种算法都是在寻找一种转换,将数据放在一个适合的空间,以求获得合适的度量方式(距离度量,维度度量等等)。这里主要总结了其他大神们的杰作,以及西瓜书上的内容。维度灾难发生时,利用维度学习将数据转换到合适空间;流形学习利用拓扑流形概念来实现降维;维度和流形学习都是寻找低维空间,寻找度量方式,而度量学习直接寻找一种度量方式。维度学习主要有MDS,PCA等;流形学习主要有Isomap,LLE等;度量学习主要有NCA,LDA等。以下详细分析。
转自http://blog.csdn.net/u014470581/article/details/51770356
维度学习
这里,我们讨论特征选择和特征提取,前者选取重要的特征子集,后者由原始输入形成较少的新特征,理想情况下,无论是分类还是回归,我们不应该将特征选择或特征提取作为一个单独的进程,分类或者回归方法应该能够利用任何必要的特征,而丢弃不相关的特征。但是,考虑到算法存储量和时间的复杂度,或者输入不必要的特征等原因,还是需要降维。较简单的模型在小数据上更为鲁棒,有小方差,模型的变化更依赖于样本的特殊性,包括噪声,离群点等。同时,低纬度描述数据,方便我们队数据绘图,可视化分析数据结构和离群点。
降低方法,一般为特征选择,特征提取,按监督和非监督分:
非监督:PCA、FA ,LLE
监督:LDA,MDS
其中,PCA,FA,MDS,LDA,都是线性投影方法,非线性维度规约有等距特征映射,局部线性嵌入LLE。
维度归约使用数据编码或变换,以便得到原数据的归约或“压缩”表示。如果原数据可以由压缩数据重新构造而不丢失任何信息,则该数据归约是无损的。如果我们只能重新构造原数据的近似表示,则该数据归约是有损的。有一些很好的串压缩算法。尽管它们通常是无损的,但是只允许有限的数据操作。
一.先说特征选择,即子集选择。
在子集选择中,我们选择最佳子集,其含的维度最少,但对正确率的贡献最大。在维度较大时,采用启发式方法,在合理的时间内得到一个合理解(但不是最优解)。维度较小时,对所有子集做检验。
有两种方法,向前选择,即从空集开始逐渐增加特征,每次添加一个降低误差最多的变量,直到进一步添加不会降低误差或者降低很少。同时,可以用浮动搜索,每一步可以改变增加和去掉的特征数量,以此来加速。
向后选择中,从所有变量开始,逐个排除他们,每次排除一个降低误差最多的变量,直到进一步的排除会显著提高误差。如果我们预料有许多无用特征时,向前选择更可取。
在两种情况下,误差检测都应在不同于训练集的验证集上做,因为我们想要检验泛化准确率。使用更多的特征,我们一般会有更低的训练误差,但不一定有更低的验证误差。
像人脸识别这样的应用中,特征选择不是很好的降维方法,因为个体像素本身并不携带很多识别信息,携带脸部识别信息的是许多像素值的组合。这可以用特征提取来归约。
二. 主成分分析(PCA)
1. 问题
真实的训练数据总是存在各种各样的问题:
1、 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余。
2、 拿到一个数学系的本科生期末考试成绩单,里面有三列,一列是对数学的兴趣程度,一列是复习时间,还有一列是考试成绩。我们知道要学好数学,需要有浓厚的兴趣,所以第二项与第一项强相关,第三项和第二项也是强相关。那是不是可以合并第一项和第二项呢?
3、 拿到一个样本,特征非常多,而样例特别少,这样用回归去直接拟合非常困难,容易过度拟合。比如北京的房价:假设房子的特征是(大小、位置、朝向、是否学区房、建造年代、是否二手、层数、所在层数),搞了这么多特征,结果只有不到十个房子的样例。要拟合房子特征->房价的这么多特征,就会造成过度拟合。
4、 这个与第二个有点类似,假设在IR中我们建立的文档-词项矩阵中,有两个词项为“learn”和“study”,在传统的向量空间模型中,认为两者独立。然而从语义的角度来讲,两者是相似的,而且两者出现频率也类似,是不是可以合成为一个特征呢?
5、 在信号传输过程中,由于信道不是理想的,信道另一端收到的信号会有噪音扰动,那么怎么滤去这些噪音呢?
回顾我们之前介绍的《模型选择和规则化》,里面谈到的特征选择的问题。但在那篇中要剔除的特征主要是和类标签无关的特征。比如“学生的名字”就和他的“成绩”无关,使用的是互信息的方法。
而这里的特征很多是和类标签有关的,但里面存在噪声或者冗余。在这种情况下,需要一种特征降维的方法来减少特征数,减少噪音和冗余,减少过度拟合的可能性。
下面探讨一种称作主成分分析(PCA)的方法来解决部分上述问题。PCA的思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征。这k维特征称为主元,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。
2. PCA计算过程
首先介绍PCA的计算过程:
假设我们得到的2维数据如下:
![clip_image001[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201244271313.png "clip_image001[4]")
行代表了样例,列代表特征,这里有10个样例,每个样例两个特征。可以这样认为,有10篇文档,x是10篇文档中“learn”出现的TF-IDF,y是10篇文档中“study”出现的TF-IDF。也可以认为有10辆汽车,x是千米/小时的速度,y是英里/小时的速度,等等。
第一步分别求x和y的平均值,然后对于所有的样例,都减去对应的均值。这里x的均值是1.81,y的均值是1.91,那么一个样例减去均值后即为(0.69,0.49),得到
![clip_image002[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201257779972.png "clip_image002[4]")
第二步,求特征协方差矩阵,如果数据是3维,那么协方差矩阵是
![clip_image003[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201253831200.png "clip_image003[4]")
这里只有x和y,求解得
![clip_image004[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201257285737.png "clip_image004[4]")
对角线上分别是x和y的方差,非对角线上是协方差。协方差大于0表示x和y若有一个增,另一个也增;小于0表示一个增,一个减;协方差为0时,两者独立。协方差绝对值越大,两者对彼此的影响越大,反之越小。
第三步,求协方差的特征值和特征向量,得到
![clip_image005[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201257853294.png "clip_image005[4]")
上面是两个特征值,下面是对应的特征向量,特征值0.0490833989对应特征向量为![]() ,这里的特征向量都归一化为单位向量。
,这里的特征向量都归一化为单位向量。
第四步,将特征值按照从大到小的顺序排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
这里特征值只有两个,我们选择其中最大的那个,这里是1.28402771,对应的特征向量是![]() 。
。
第五步,将样本点投影到选取的特征向量上。假设样例数为m,特征数为n,减去均值后的样本矩阵为DataAdjust(m*n),协方差矩阵是n*n,选取的k个特征向量组成的矩阵为EigenVectors(n*k)。那么投影后的数据FinalData为
![]()
这里是
FinalData(10*1) = DataAdjust(10*2矩阵)×特征向量![]()
得到结果是
![clip_image012[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201257649755.png "clip_image012[4]")
这样,就将原始样例的n维特征变成了k维,这k维就是原始特征在k维上的投影。
上面的数据可以认为是learn和study特征融合为一个新的特征叫做LS特征,该特征基本上代表了这两个特征。
上述过程有个图描述:
![clip_image013[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201255916059.png "clip_image013[4]")
正号表示预处理后的样本点,斜着的两条线就分别是正交的特征向量(由于协方差矩阵是对称的,因此其特征向量正交),最后一步的矩阵乘法就是将原始样本点分别往特征向量对应的轴上做投影。
如果取的k=2,那么结果是
![clip_image014[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201257488117.png "clip_image014[4]")
这就是经过PCA处理后的样本数据,水平轴(上面举例为LS特征)基本上可以代表全部样本点。整个过程看起来就像将坐标系做了旋转,当然二维可以图形化表示,高维就不行了。上面的如果k=1,那么只会留下这里的水平轴,轴上是所有点在该轴的投影。
这样PCA的过程基本结束。在第一步减均值之后,其实应该还有一步对特征做方差归一化。比如一个特征是汽车速度(0到100),一个是汽车的座位数(2到6),显然第二个的方差比第一个小。因此,如果样本特征中存在这种情况,那么在第一步之后,求每个特征的标准差![]() ,然后对每个样例在该特征下的数据除以
,然后对每个样例在该特征下的数据除以![]() 。
。
归纳一下,使用我们之前熟悉的表示方法,在求协方差之前的步骤是:
![clip_image017[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201253631666.png "clip_image017[4]")
其中![]() 是样例,共m个,每个样例n个特征,也就是说
是样例,共m个,每个样例n个特征,也就是说![]() 是n维向量。
是n维向量。![]() 是第i个样例的第j个特征。
是第i个样例的第j个特征。![]() 是样例均值。
是样例均值。![]() 是第j个特征的标准差。
是第j个特征的标准差。
整个PCA过程貌似及其简单,就是求协方差的特征值和特征向量,然后做数据转换。但是有没有觉得很神奇,为什么求协方差的特征向量就是最理想的k维向量?其背后隐藏的意义是什么?整个PCA的意义是什么?
3. PCA理论基础
要解释为什么协方差矩阵的特征向量就是k维理想特征,我看到的有三个理论:分别是最大方差理论、最小错误理论和坐标轴相关度理论。这里简单探讨前两种,最后一种在讨论PCA意义时简单概述。
3.1 最大方差理论
在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。如前面的图,样本在横轴上的投影方差较大,在纵轴上的投影方差较小,那么认为纵轴上的投影是由噪声引起的。
因此我们认为,最好的k维特征是将n维样本点转换为k维后,每一维上的样本方差都很大。
比如下图有5个样本点:(已经做过预处理,均值为0,特征方差归一)
![clip_image026[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201265273845.png "clip_image026[4]")
下面将样本投影到某一维上,这里用一条过原点的直线表示(前处理的过程实质是将原点移到样本点的中心点)。
![clip_image028[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201262313695.jpg "clip_image028[4]")
假设我们选择两条不同的直线做投影,那么左右两条中哪个好呢?根据我们之前的方差最大化理论,左边的好,因为投影后的样本点之间方差最大。
这里先解释一下投影的概念:

红色点表示样例![]() ,蓝色点表示
,蓝色点表示![]() 在u上的投影,u是直线的斜率也是直线的方向向量,而且是单位向量。蓝色点是
在u上的投影,u是直线的斜率也是直线的方向向量,而且是单位向量。蓝色点是![]() 在u上的投影点,离原点的距离是
在u上的投影点,离原点的距离是![]() (即
(即![]() 或者
或者![]() )由于这些样本点(样例)的每一维特征均值都为0,因此投影到u上的样本点(只有一个到原点的距离值)的均值仍然是0。
)由于这些样本点(样例)的每一维特征均值都为0,因此投影到u上的样本点(只有一个到原点的距离值)的均值仍然是0。
回到上面左右图中的左图,我们要求的是最佳的u,使得投影后的样本点方差最大。
由于投影后均值为0,因此方差为:
![clip_image042[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201265196809.png "clip_image042[4]")
中间那部分很熟悉啊,不就是样本特征的协方差矩阵么(![]() 的均值为0,一般协方差矩阵都除以m-1,这里用m)。
的均值为0,一般协方差矩阵都除以m-1,这里用m)。
用![]() 来表示
来表示![]() ,
,![]() 表示
表示![]() ,那么上式写作
,那么上式写作
![]()
由于u是单位向量,即![]() ,上式两边都左乘u得,
,上式两边都左乘u得,![]()
即![]()
We got it!![]() 就是
就是![]() 的特征值,u是特征向量。最佳的投影直线是特征值
的特征值,u是特征向量。最佳的投影直线是特征值![]() 最大时对应的特征向量,其次是
最大时对应的特征向量,其次是![]() 第二大对应的特征向量,依次类推。
第二大对应的特征向量,依次类推。
因此,我们只需要对协方差矩阵进行特征值分解,得到的前k大特征值对应的特征向量就是最佳的k维新特征,而且这k维新特征是正交的。得到前k个u以后,样例![]() 通过以下变换可以得到新的样本。
通过以下变换可以得到新的样本。
![clip_image059[4]](https://www.shuijiaxian.com/files_image/2023110822/202311082201276766015.png "clip_image059[4]")
其中的第j维就是![]() 在
在![]() 上的投影。
上的投影。
通过选取最大的k个u,使得方差较小的特征(如噪声)被丢弃。
这是其中一种对PCA的解释
3.2 最小平方误差理论

假设有这样的二维样本点(红色点),回顾我们前面探讨的是求一条直线,使得样本点投影到直线上的点的方差最大。本质是求直线,那么度量直线求的好不好,不仅仅只有方差最大化的方法。再回想我们最开始学习的线性回归等,目的也是求一个线性函数使得直线能够最佳拟合样本点,那么我们能不能认为最佳的直线就是回归后的直线呢?回归时我们的最小二乘法度量的是样本点到直线的坐标轴距离。比如这个问题中,特征是x,类标签是y。回归时最小二乘法度量的是距离d。如果使用回归方法来度量最佳直线,那么就是直接在原始样本上做回归了,跟特征选择就没什么关系了。
因此,我们打算选用另外一种评价直线好坏的方法,使用点到直线的距离d’来度量。
现在有n个样本点![]() ,每个样本点为m维(这节内容中使用的符号与上面的不太一致,需要重新理解符号的意义)。将样本点
,每个样本点为m维(这节内容中使用的符号与上面的不太一致,需要重新理解符号的意义)。将样本点![]() 在直线上的投影记为
在直线上的投影记为![]() ,那么我们就是要最小化
,那么我们就是要最小化
![]()
这个公式称作最小平方误差(Least Squared Error)。
而确定一条直线,一般只需要确定一个点,并且确定方向即可。
第一步确定点:
假设要在空间中找一点![]() 来代表这n个样本点,“代表”这个词不是量化的,因此要量化的话,我们就是要找一个m维的点
来代表这n个样本点,“代表”这个词不是量化的,因此要量化的话,我们就是要找一个m维的点![]() ,使得
,使得

最小。其中![]() 是平方错误评价函数(squared-error criterion function),假设m为n个样本点的均值:
是平方错误评价函数(squared-error criterion function),假设m为n个样本点的均值:

那么平方错误可以写作:

后项与![]() 无关,看做常量,而
无关,看做常量,而![]() ,因此最小化
,因此最小化![]() 时,
时,
![]()
![]() 是样本点均值。
是样本点均值。
第二步确定方向:
我们从![]() 拉出要求的直线(这条直线要过点m),假设直线的方向是单位向量e。那么直线上任意一点,比如
拉出要求的直线(这条直线要过点m),假设直线的方向是单位向量e。那么直线上任意一点,比如![]() 就可以用点m和e来表示
就可以用点m和e来表示
![]()
其中![]() 是
是![]() 到点m的距离。
到点m的距离。
我们重新定义最小平方误差:

这里的k只是相当于i。![]() 就是最小平方误差函数,其中的未知参数是
就是最小平方误差函数,其中的未知参数是![]() 和e。
和e。
实际上是求![]() 的最小值。首先将上式展开:
的最小值。首先将上式展开:

我们首先固定e,将其看做是常量,![]() ,然后对
,然后对![]() 进行求导,得
进行求导,得
![]()
这个结果意思是说,如果知道了e,那么将![]() 与e做内积,就可以知道了
与e做内积,就可以知道了![]() 在e上的投影离m的长度距离,不过这个结果不用求都知道。
在e上的投影离m的长度距离,不过这个结果不用求都知道。
然后是固定![]() ,对e求偏导数,我们先将公式(8)代入
,对e求偏导数,我们先将公式(8)代入![]() ,得
,得

其中![]() 与协方差矩阵类似,只是缺少个分母n-1,我们称之为散列矩阵(scatter matrix)。
与协方差矩阵类似,只是缺少个分母n-1,我们称之为散列矩阵(scatter matrix)。
然后可以对e求偏导数,但是e需要首先满足![]() ,引入拉格朗日乘子
,引入拉格朗日乘子![]() ,来使
,来使![]() 最大(
最大(![]() 最小),令
最小),令
![]()
求偏导
![]()
这里存在对向量求导数的技巧,方法这里不多做介绍。可以去看一些关于矩阵微积分的资料,这里求导时可以将![]() 看作是
看作是![]() ,将
,将![]() 看做是
看做是![]() 。
。
导数等于0时,得
![]()
两边除以n-1就变成了,对协方差矩阵求特征值向量了。
从不同的思路出发,最后得到同一个结果,对协方差矩阵求特征向量,求得后特征向量上就成为了新的坐标,如下图:

这时候点都聚集在新的坐标轴周围,因为我们使用的最小平方误差的意义就在此。
4. PCA理论意义
PCA将n个特征降维到k个,可以用来进行数据压缩,如果100维的向量最后可以用10维来表示,那么压缩率为90%。同样图像处理领域的KL变换使用PCA做图像压缩。但PCA要保证降维后,还要保证数据的特性损失最小。再看回顾一下PCA的效果。经过PCA处理后,二维数据投影到一维上可以有以下几种情况:

我们认为左图好,一方面是投影后方差最大,一方面是点到直线的距离平方和最小,而且直线过样本点的中心点。为什么右边的投影效果比较差?直觉是因为坐标轴之间相关,以至于去掉一个坐标轴,就会使得坐标点无法被单独一个坐标轴确定。
PCA得到的k个坐标轴实际上是k个特征向量,由于协方差矩阵对称,因此k个特征向量正交。看下面的计算过程。
假设我们还是用![]() 来表示样例,m个样例,n个特征。特征向量为e,
来表示样例,m个样例,n个特征。特征向量为e,![]() 表示第i个特征向量的第1维。那么原始样本特征方程可以用下面式子来表示:
表示第i个特征向量的第1维。那么原始样本特征方程可以用下面式子来表示:
前面两个矩阵乘积就是协方差矩阵![]() (除以m后),原始的样本矩阵A是第二个矩阵m*n。
(除以m后),原始的样本矩阵A是第二个矩阵m*n。

上式可以简写为![]()
我们最后得到的投影结果是![]() ,E是k个特征向量组成的矩阵,展开如下:
,E是k个特征向量组成的矩阵,展开如下:

得到的新的样例矩阵就是m个样例到k个特征向量的投影,也是这k个特征向量的线性组合。e之间是正交的。从矩阵乘法中可以看出,PCA所做的变换是将原始样本点(n维),投影到k个正交的坐标系中去,丢弃其他维度的信息。举个例子,假设宇宙是n维的(霍金说是11维的),我们得到银河系中每个星星的坐标(相对于银河系中心的n维向量),然而我们想用二维坐标去逼近这些样本点,假设算出来的协方差矩阵的特征向量分别是图中的水平和竖直方向,那么我们建议以银河系中心为原点的x和y坐标轴,所有的星星都投影到x和y上,得到下面的图片。然而我们丢弃了每个星星离我们的远近距离等信息。

5. 总结与讨论
这一部分来自http://www.cad.zju.edu.cn/home/chenlu/pca.htm
PCA技术的一大好处是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。

图表 4:黑色点表示采样数据,排列成转盘的形状。
容易想象,该数据的主元是![]() 或是旋转角
或是旋转角![]() 。
。
如图表 4中的例子,PCA找出的主元将是![]() 。但是这显然不是最优和最简化的主元。
。但是这显然不是最优和最简化的主元。![]() 之间存在着非线性的关系。根据先验的知识可知旋转角
之间存在着非线性的关系。根据先验的知识可知旋转角![]() 是最优的主元(类比极坐标)。则在这种情况下,PCA就会失效。但是,如果加入先验的知识,对数据进行某种划归,就可以将数据转化为以
是最优的主元(类比极坐标)。则在这种情况下,PCA就会失效。但是,如果加入先验的知识,对数据进行某种划归,就可以将数据转化为以![]() 为线性的空间中。这类根据先验知识对数据预先进行非线性转换的方法就成为kernel-PCA,它扩展了PCA能够处理的问题的范围,又可以结合一些先验约束,是比较流行的方法。
为线性的空间中。这类根据先验知识对数据预先进行非线性转换的方法就成为kernel-PCA,它扩展了PCA能够处理的问题的范围,又可以结合一些先验约束,是比较流行的方法。
有时数据的分布并不是满足高斯分布。如图表 5所示,在非高斯分布的情况下,PCA方法得出的主元可能并不是最优的。在寻找主元时不能将方差作为衡量重要性的标准。要根据数据的分布情况选择合适的描述完全分布的变量,然后根据概率分布式
![]()
来计算两个向量上数据分布的相关性。等价的,保持主元间的正交假设,寻找的主元同样要使![]() 。这一类方法被称为独立主元分解(ICA)。
。这一类方法被称为独立主元分解(ICA)。

图表 5:数据的分布并不满足高斯分布,呈明显的十字星状。
这种情况下,方差最大的方向并不是最优主元方向。
另外PCA还可以用于预测矩阵中缺失的元素。
6. 其他参考文献
A tutorial on Principal Components Analysis LI Smith – 2002
A Tutorial on Principal Component Analysis J Shlens
http://www.cmlab.csie.ntu.edu.tw/~cyy/learning/tutorials/PCAMissingData.pdf
http://www.cad.zju.edu.cn/home/chenlu/pca.htm
所谓主成分,就是在某方向上样本投影之后,被广泛散布,使得样本之间的差别变得最明显。为了得到唯一解并且使得该方向成为最重要因素,要求该向量长度为1,利用拉格朗日,计算出在方差最大情况下,我们选择具有最大特征值的特征向量为该投影向量。后面次方差最大。。。如此类推。由于协方差矩阵是对称的,因此,对于两个不同的特征值,特征向量是正交的。
通常情况下,我们考虑贡献90%以上方差的前K个分量,或者利用斜坡图,目视化分析拐点k,也可以忽略特征值小于平均输入方差的特征向量。
当然,如果原维之间不相关,则PCA就没有收益。在许多图像和语音处理任务中,邻近的输入时高度相关的。
如果原维的方差变化显著,则他们对主成分方向的影响比相关性大。因此,一般在PCA之前预处理下,使得每个维都具有0均值和单位方差。或者,为了使协方差而不是个体方差起作用,我们用协相关矩阵R而不是协方差矩阵S的本征向量。
离群点对方差有很大影响,从而影响特征向量,鲁棒的估计方法是允许计算离群点存在时的参数,如计算数据的马氏距离,丢弃哪些远离的孤立点数据。
当原维度很大时,我们可以直接从数据计算特征向量,特征值,不必计算协方差矩阵。
在所有正交线性投影中,PCA最小化重构误差。
这里,作为一种维度归约方法,我们直观地介绍主成分分析。
假定待归约的数据由n个属性或维描述的元组或数据向量组成。主成分分析(principal components analysis)或PCA(又称Karhunen-Loeve或K-L方法)搜索k个最能代表数据的n维正交向量,其中k≤n。这样,原来的数据投影到一个小得多的空间,导致维度归约。不像属性子集选择通过保留原属性集的一个子集来减少属性集的大小,PCA通过创建一个替换的、更小的变量集“组合”属性的基本要素。原数据可以投影到该较小的集合中。PCA常常揭示先前未曾察觉的联系,并因此允许解释不寻常的结果。
基本过程如下:
(1)对输入数据规范化,使得每个属性都落入相同的区间。此步有助于确保具有较大定义域的属性不会支配具有较小定义域的属性。
(2)PCA计算k个标准正交向量,作为规范化输入数据的基。这些是单位向量,每一个方向都垂直于另一个。这些向量称为主成分。输入数据是主成分的线性组合。
(3)对主成分按“重要性”或强度降序排列。主成分基本上充当数据的新坐标轴,提供关于方差的重要信息。也就是说,对坐标轴进行排序,使得第一个坐标轴显示数据的最大方差,第二个显示次大方差,如此下去。例如,图2-17显示原来映射到轴X1和X2的给定数据集的前两个主成分Y1和Y2。这一信息帮助识别数据中的分组或模式。
(4)既然主成分根据“重要性”降序排列,就可以通过去掉较弱的成分(即方差较小)来归约数据的规模。使用最强的主成分,应当能够重构原数据的很好的近似。
图2-17 主成分分析。Y1和Y2是给定数据的前两个主成分
PCA计算开销低,可以用于有序和无序的属性,并且可以处理稀疏和倾斜数据。多于2维的多维数据可以通过将问题归约为2维问题来处理。主成分可以用作多元回归和聚类分析的输入。与小波变换相比,PCA能够更好地处理稀疏数据,而小波变换更适合高维数据。
三.FA
FA也是非监督的,但与PCA相反,其旨在找到较少数量的因子,刻画观测变量之间的依赖性。但是,对于维度归约,除了因子可解释性,允许识别公共原因,简单解释,知识提取外,FA与PCA相比,并无优势。
1 问题
之前我们考虑的训练数据中样例![]() 的个数m都远远大于其特征个数n,这样不管是进行回归、聚类等都没有太大的问题。然而当训练样例个数m太小,甚至m<<n的时候,使用梯度下降法进行回归时,如果初值不同,得到的参数结果会有很大偏差(因为方程数小于参数个数)。另外,如果使用多元高斯分布(Multivariate Gaussian distribution)对数据进行拟合时,也会有问题。让我们来演算一下,看看会有什么问题:
的个数m都远远大于其特征个数n,这样不管是进行回归、聚类等都没有太大的问题。然而当训练样例个数m太小,甚至m<<n的时候,使用梯度下降法进行回归时,如果初值不同,得到的参数结果会有很大偏差(因为方程数小于参数个数)。另外,如果使用多元高斯分布(Multivariate Gaussian distribution)对数据进行拟合时,也会有问题。让我们来演算一下,看看会有什么问题:
多元高斯分布的参数估计公式如下:


分别是求mean和协方差的公式,![]() 表示样例,共有m个,每个样例n个特征,因此
表示样例,共有m个,每个样例n个特征,因此![]() 是n维向量,
是n维向量,![]() 是n*n协方差矩阵。
是n*n协方差矩阵。
当m<<n时,我们会发现![]() 是奇异阵(
是奇异阵(![]() ),也就是说
),也就是说![]() 不存在,没办法拟合出多元高斯分布了,确切的说是我们估计不出来
不存在,没办法拟合出多元高斯分布了,确切的说是我们估计不出来![]() 。
。
如果我们仍然想用多元高斯分布来估计样本,那怎么办呢?
2 限制协方差矩阵
当没有足够的数据去估计![]() 时,那么只能对模型参数进行一定假设,之前我们想估计出完全的
时,那么只能对模型参数进行一定假设,之前我们想估计出完全的![]() (矩阵中的全部元素),现在我们假设
(矩阵中的全部元素),现在我们假设![]() 就是对角阵(各特征间相互独立),那么我们只需要计算每个特征的方差即可,最后的
就是对角阵(各特征间相互独立),那么我们只需要计算每个特征的方差即可,最后的![]() 只有对角线上的元素不为0
只有对角线上的元素不为0

回想我们之前讨论过的二维多元高斯分布的几何特性,在平面上的投影是个椭圆,中心点由![]() 决定,椭圆的形状由
决定,椭圆的形状由![]() 决定。
决定。![]() 如果变成对角阵,就意味着椭圆的两个轴都和坐标轴平行了。
如果变成对角阵,就意味着椭圆的两个轴都和坐标轴平行了。

如果我们想对![]() 进一步限制的话,可以假设对角线上的元素都是等值的。
进一步限制的话,可以假设对角线上的元素都是等值的。
![]()
其中

也就是上一步对角线上元素的均值,反映到二维高斯分布图上就是椭圆变成圆。
当我们要估计出完整的![]() 时,我们需要m>=n+1才能保证在最大似然估计下得出的
时,我们需要m>=n+1才能保证在最大似然估计下得出的![]() 是非奇异的。然而在上面的任何一种假设限定条件下,只要m>=2都可以估计出限定的
是非奇异的。然而在上面的任何一种假设限定条件下,只要m>=2都可以估计出限定的![]() 。
。
这样做的缺点也是显然易见的,我们认为特征间独立,这个假设太强。接下来,我们给出一种称为因子分析的方法,使用更多的参数来分析特征间的关系,并且不需要计算一个完整的![]() 。
。
3 边缘和条件高斯分布
在讨论因子分析之前,先看看多元高斯分布中,条件和边缘高斯分布的求法。这个在后面因子分析的EM推导中有用。
假设x是有两个随机向量组成(可以看作是将之前的![]() 分成了两部分)
分成了两部分)
![]()
其中![]() ,
,![]() ,那么
,那么![]() 。假设x服从多元高斯分布
。假设x服从多元高斯分布![]() ,其中
,其中

其中![]() ,
,![]() ,那么
,那么![]() ,
,![]() ,由于协方差矩阵是对称阵,因此
,由于协方差矩阵是对称阵,因此![]() 。
。
整体看来![]() 和
和![]() 联合分布符合多元高斯分布。
联合分布符合多元高斯分布。
那么只知道联合分布的情况下,如何求得![]() 的边缘分布呢?从上面的
的边缘分布呢?从上面的![]() 和
和![]() 可以看出,
可以看出,
![]() ,
,![]() ,下面我们验证第二个结果
,下面我们验证第二个结果

由此可见,多元高斯分布的边缘分布仍然是多元高斯分布。也就是说![]() 。
。
上面Cov(x)里面有趣的是![]() ,这个与之前计算协方差的效果不同。之前的协方差矩阵都是针对一个随机变量(多维向量)来说的,而
,这个与之前计算协方差的效果不同。之前的协方差矩阵都是针对一个随机变量(多维向量)来说的,而![]() 评价的是两个随机向量之间的关系。比如
评价的是两个随机向量之间的关系。比如![]() ={身高,体重},
={身高,体重},![]() ={性别,收入},那么
={性别,收入},那么![]() 求的是身高与身高,身高与体重,体重与体重的协方差。而
求的是身高与身高,身高与体重,体重与体重的协方差。而![]() 求的是身高与性别,身高与收入,体重与性别,体重与收入的协方差,看起来与之前的大不一样,比较诡异的求法。
求的是身高与性别,身高与收入,体重与性别,体重与收入的协方差,看起来与之前的大不一样,比较诡异的求法。
上面求的是边缘分布,让我们考虑一下条件分布的问题,也就是![]() 的问题。根据多元高斯分布的定义,
的问题。根据多元高斯分布的定义,![]() 。
。
且

这是我们接下来计算时需要的公式,这两个公式直接给出,没有推导过程。如果想了解具体的推导过程,可以参见Chuong B. Do写的《Gaussian processes》。
4 因子分析例子
下面通过一个简单例子,来引出因子分析背后的思想。
因子分析的实质是认为m个n维特征的训练样例![]() 的产生过程如下:
的产生过程如下:
1、 首先在一个k维的空间中按照多元高斯分布生成m个![]() (k维向量),即
(k维向量),即
![]()
2、 然后存在一个变换矩阵![]() ,将
,将![]() 映射到n维空间中,即
映射到n维空间中,即
![]()
因为![]() 的均值是0,映射后仍然是0。
的均值是0,映射后仍然是0。
3、 然后将![]() 加上一个均值
加上一个均值![]() (n维),即
(n维),即
![]()
对应的意义是将变换后的![]() (n维向量)移动到样本
(n维向量)移动到样本![]() 的中心点
的中心点![]() 。
。
4、 由于真实样例![]() 与上述模型生成的有误差,因此我们继续加上误差
与上述模型生成的有误差,因此我们继续加上误差![]() (n维向量),
(n维向量),
而且![]() 符合多元高斯分布,即
符合多元高斯分布,即
![]()
![]()
5、 最后的结果认为是真实的训练样例![]() 的生成公式
的生成公式
![]()
让我们使用一种直观方法来解释上述过程:
假设我们有m=5个2维的样本点![]() (两个特征),如下:
(两个特征),如下:

那么按照因子分析的理解,样本点的生成过程如下:
1、 我们首先认为在1维空间(这里k=1),存在着按正态分布生成的m个点![]() ,如下
,如下

均值为0,方差为1。
2、 然后使用某个![]() 将一维的z映射到2维,图形表示如下:
将一维的z映射到2维,图形表示如下:

3、 之后加上![]() ,即将所有点的横坐标移动
,即将所有点的横坐标移动![]() ,纵坐标移动
,纵坐标移动![]() ,将直线移到一个位置,使得直线过点
,将直线移到一个位置,使得直线过点![]() ,原始左边轴的原点现在为
,原始左边轴的原点现在为![]() (红色点)。
(红色点)。

然而,样本点不可能这么规则,在模型上会有一定偏差,因此我们需要将上步生成的点做一些扰动(误差),扰动![]() 。
。
4、 加入扰动后,我们得到黑色样本![]() 如下:
如下:

5、 其中由于z和![]() 的均值都为0,因此
的均值都为0,因此![]() 也是原始样本点(黑色点)的均值。
也是原始样本点(黑色点)的均值。
由以上的直观分析,我们知道了因子分析其实就是认为高维样本点实际上是由低维样本点经过高斯分布、线性变换、误差扰动生成的,因此高维数据可以使用低维来表示。
5 因子分析模型
上面的过程是从隐含随机变量z经过变换和误差扰动来得到观测到的样本点。其中z被称为因子,是低维的。
我们将式子再列一遍如下:
![]()
![]()
![]()
其中误差![]() 和z是独立的。
和z是独立的。
下面使用的因子分析表示方法是矩阵表示法,在参考资料中给出了一些其他的表示方法,如果不明白矩阵表示法,可以参考其他资料。
矩阵表示法认为z和x联合符合多元高斯分布,如下
![]()
求![]() 之前需要求E[x]
之前需要求E[x]
![]()
![]()
![]()
我们已知E[z]=0,因此
![]()
下一步是计算![]() ,
,
其中![]()
接着求![]()

这个过程中利用了z和![]() 独立假设(
独立假设(![]() )。并将
)。并将![]() 看作已知变量。
看作已知变量。
接着求![]()

然后得出联合分布的最终形式

从上式中可以看出x的边缘分布![]()
那么对样本![]() 进行最大似然估计
进行最大似然估计

然后对各个参数求偏导数不就得到各个参数的值了么?
可惜我们得不到closed-form。想想也是,如果能得到,还干嘛将z和x放在一起求联合分布呢。根据之前对参数估计的理解,在有隐含变量z时,我们可以考虑使用EM来进行估计。
6 因子分析的EM估计
我们先来明确一下各个参数,z是隐含变量,![]() 是待估参数。
是待估参数。
回想EM两个步骤:
| 循环重复直到收敛 { (E步)对于每一个i,计算
(M步)计算
|

我们套用一下:
(E步):
![]()
根据第3节的条件分布讨论,
![]()
因此

那么根据多元高斯分布公式,得到

(M步):
直接写要最大化的目标是

其中待估参数是![]()
下面我们重点求![]() 的估计公式
的估计公式
首先将上式简化为:

这里![]() 表示
表示![]() 服从
服从![]() 分布。然后去掉与
分布。然后去掉与![]() 不相关的项(后两项),得
不相关的项(后两项),得

去掉不相关的前两项后,对![]() 进行导,
进行导,

第一步到第二步利用了tr a = a(a是实数时)和tr AB = tr BA。最后一步利用了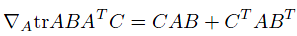
tr就是求一个矩阵对角线上元素和。
最后让其值为0,并且化简得

然后得到

到这里我们发现,这个公式有点眼熟,与之前回归中的最小二乘法矩阵形式类似
![]()
这里解释一下两者的相似性,我们这里的x是z的线性函数(包含了一定的噪声)。在E步得到z的估计后,我们找寻的![]() 实际上是x和z的线性关系。而最小二乘法也是去找特征和结果直接的线性关系。
实际上是x和z的线性关系。而最小二乘法也是去找特征和结果直接的线性关系。
到这还没完,我们需要求得括号里面的值
根据我们之前对z|x的定义,我们知道

第一步根据z的条件分布得到,第二步根据![]() 得到
得到
将上面的结果代入(7)中得到

至此,我们得到了![]() ,注意一点是E[z]和
,注意一点是E[z]和![]() 的不同,后者需要求z的协方差。
的不同,后者需要求z的协方差。
其他参数的迭代公式如下:

均值![]() 在迭代过程中值不变。
在迭代过程中值不变。
![]()
然后将![]() 上的对角线上元素抽取出来放到对应的
上的对角线上元素抽取出来放到对应的![]() 中,就得到了
中,就得到了![]() 。
。
7 总结
根据上面的EM的过程,要对样本X进行因子分析,只需知道要分解的因子数(z的维度)即可。通过EM,我们能够得到转换矩阵![]() 和误差协方差
和误差协方差![]() 。
。
因子分析实际上是降维,在得到各个参数后,可以求得z。但是z的各个参数含义需要自己去琢磨。
下面从一个ppt中摘抄几段话来进一步解释因子分析。
因子分析(factor analysis)是一种数据简化的技术。它通过研究众多变量之间的内部依赖关系,探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。这几个假想变量能够反映原来众多变量的主要信息。原始的变量是可观测的显在变量,而假想变量是不可观测的潜在变量,称为因子。
例如,在企业形象或品牌形象的研究中,消费者可以通过一个有24个指标构成的评价体系,评价百货商场的24个方面的优劣。
但消费者主要关心的是三个方面,即商店的环境、商店的服务和商品的价格。因子分析方法可以通过24个变量,找出反映商店环境、商店服务水平和商品价格的三个潜在的因子,对商店进行综合评价。而这三个公共因子可以表示为:
![]()
这里的![]() 就是样例x的第i个分量,
就是样例x的第i个分量,![]() 就是
就是![]() 的第i个分量,
的第i个分量,![]() 就是
就是![]() 的第i行第j列元素,
的第i行第j列元素,![]() 是z的第i个分量,
是z的第i个分量,![]() 是
是![]() 。
。
称![]() 是不可观测的潜在因子。24个变量共享这三个因子,但是每个变量又有自己的个性,不被包含的部分
是不可观测的潜在因子。24个变量共享这三个因子,但是每个变量又有自己的个性,不被包含的部分![]() ,称为特殊因子。
,称为特殊因子。
注:
因子分析与回归分析不同,因子分析中的因子是一个比较抽象的概念,而回归因子有非常明确的实际意义;
主成分分析分析与因子分析也有不同,主成分分析仅仅是变量变换,而因子分析需要构造因子模型。
主成分分析:原始变量的线性组合表示新的综合变量,即主成分;
因子分析:潜在的假想变量和随机影响变量的线性组合表示原始变量。
PPT地址
http://www.math.zju.edu.cn/webpagenew/uploadfiles/attachfiles/2008123195228555.ppt
其他值得参考的文献
An Introduction to Probabilistic Graphical Models by Jordan Chapter 14
主成分分析和因子分析的区别http://cos.name/old/view.php?tid=10&id=82
四.ICA
1. 问题:
1、PCA是一种数据降维的方法,但是只对符合高斯分布的样本点比较有效,那么对于其他分布的样本,有没有主元分解的方法呢?
2、经典的鸡尾酒宴会问题(cocktail party problem)。假设在party中有n个人,他们可以同时说话,我们也在房间中一些角落里共放置了n个声音接收器(Microphone)用来记录声音。宴会过后,我们从n个麦克风中得到了一组数据![]() ,i表示采样的时间顺序,也就是说共得到了m组采样,每一组采样都是n维的。我们的目标是单单从这m组采样数据中分辨出每个人说话的信号。
,i表示采样的时间顺序,也就是说共得到了m组采样,每一组采样都是n维的。我们的目标是单单从这m组采样数据中分辨出每个人说话的信号。
将第二个问题细化一下,有n个信号源![]() ,
,![]() ,每一维都是一个人的声音信号,每个人发出的声音信号独立。A是一个未知的混合矩阵(mixing matrix),用来组合叠加信号s,那么
,每一维都是一个人的声音信号,每个人发出的声音信号独立。A是一个未知的混合矩阵(mixing matrix),用来组合叠加信号s,那么
![]()
x的意义在上文解释过,这里的x不是一个向量,是一个矩阵。其中每个列向量是![]() ,
,![]()
表示成图就是

这张图来自
http://amouraux.webnode.com/research-interests/research-interests-erp-analysis/blind-source-separation-bss-of-erps-using-independent-component-analysis-ica/

![]() 的每个分量都由
的每个分量都由![]() 的分量线性表示。A和s都是未知的,x是已知的,我们要想办法根据x来推出s。这个过程也称作为盲信号分离。
的分量线性表示。A和s都是未知的,x是已知的,我们要想办法根据x来推出s。这个过程也称作为盲信号分离。
令![]() ,那么
,那么![]()
将W表示成

其中![]() ,其实就是将
,其实就是将![]() 写成行向量形式。那么得到:
写成行向量形式。那么得到:
![]()
2. ICA的不确定性(ICA ambiguities)
由于w和s都不确定,那么在没有先验知识的情况下,无法同时确定这两个相关参数。比如上面的公式s=wx。当w扩大两倍时,s只需要同时扩大两倍即可,等式仍然满足,因此无法得到唯一的s。同时如果将人的编号打乱,变成另外一个顺序,如上图的蓝色节点的编号变为3,2,1,那么只需要调换A的列向量顺序即可,因此也无法单独确定s。这两种情况称为原信号不确定。
还有一种ICA不适用的情况,那就是信号不能是高斯分布的。假设只有两个人发出的声音信号符合多值正态分布,![]() ,I是2*2的单位矩阵,s的概率密度函数就不用说了吧,以均值0为中心,投影面是椭圆的山峰状(参见多值高斯分布)。因为
,I是2*2的单位矩阵,s的概率密度函数就不用说了吧,以均值0为中心,投影面是椭圆的山峰状(参见多值高斯分布)。因为![]() ,因此,x也是高斯分布的,均值为0,协方差为
,因此,x也是高斯分布的,均值为0,协方差为![]() 。
。
令R是正交阵![]() ,
,![]() 。如果将A替换成A’。那么
。如果将A替换成A’。那么![]() 。s分布没变,因此x’仍然是均值为0,协方差
。s分布没变,因此x’仍然是均值为0,协方差![]() 。
。
因此,不管混合矩阵是A还是A’,x的分布情况是一样的,那么就无法确定混合矩阵,也就无法确定原信号。
3. 密度函数和线性变换
在讨论ICA具体算法之前,我们先来回顾一下概率和线性代数里的知识。
假设我们的随机变量s有概率密度函数![]() (连续值是概率密度函数,离散值是概率)。为了简单,我们再假设s是实数,还有一个随机变量x=As,A和x都是实数。令
(连续值是概率密度函数,离散值是概率)。为了简单,我们再假设s是实数,还有一个随机变量x=As,A和x都是实数。令![]() 是x的概率密度,那么怎么求
是x的概率密度,那么怎么求![]() ?
?
令![]() ,首先将式子变换成
,首先将式子变换成![]() ,然后得到
,然后得到![]() ,求解完毕。可惜这种方法是错误的。比如s符合均匀分布的话(
,求解完毕。可惜这种方法是错误的。比如s符合均匀分布的话(![]() ),那么s的概率密度是
),那么s的概率密度是![]() ,现在令A=2,即x=2s,也就是说x在[0,2]上均匀分布,可知
,现在令A=2,即x=2s,也就是说x在[0,2]上均匀分布,可知![]() 。然而,前面的推导会得到
。然而,前面的推导会得到![]() 。正确的公式应该是
。正确的公式应该是
![]()
推导方法
![]()
![]()
更一般地,如果s是向量,A可逆的方阵,那么上式子仍然成立。
4. ICA算法
ICA算法归功于Bell和Sejnowski,这里使用最大似然估计来解释算法,原始的论文中使用的是一个复杂的方法Infomax principal。
我们假定每个![]() 有概率密度
有概率密度![]() ,那么给定时刻原信号的联合分布就是
,那么给定时刻原信号的联合分布就是
![]()
这个公式代表一个假设前提:每个人发出的声音信号各自独立。有了p(s),我们可以求得p(x)
![]()
左边是每个采样信号x(n维向量)的概率,右边是每个原信号概率的乘积的|W|倍。
前面提到过,如果没有先验知识,我们无法求得W和s。因此我们需要知道![]() ,我们打算选取一个概率密度函数赋给s,但是我们不能选取高斯分布的密度函数。在概率论里我们知道密度函数p(x)由累计分布函数(cdf)F(x)求导得到。F(x)要满足两个性质是:单调递增和在[0,1]。我们发现sigmoid函数很适合,定义域负无穷到正无穷,值域0到1,缓慢递增。我们假定s的累积分布函数符合sigmoid函数
,我们打算选取一个概率密度函数赋给s,但是我们不能选取高斯分布的密度函数。在概率论里我们知道密度函数p(x)由累计分布函数(cdf)F(x)求导得到。F(x)要满足两个性质是:单调递增和在[0,1]。我们发现sigmoid函数很适合,定义域负无穷到正无穷,值域0到1,缓慢递增。我们假定s的累积分布函数符合sigmoid函数
![]()
求导后
![]()
这就是s的密度函数。这里s是实数。
如果我们预先知道s的分布函数,那就不用假设了,但是在缺失的情况下,sigmoid函数能够在大多数问题上取得不错的效果。由于上式中![]() 是个对称函数,因此E[s]=0(s的均值为0),那么E[x]=E[As]=0,x的均值也是0。
是个对称函数,因此E[s]=0(s的均值为0),那么E[x]=E[As]=0,x的均值也是0。
知道了![]() ,就剩下W了。给定采样后的训练样本
,就剩下W了。给定采样后的训练样本![]() ,样本对数似然估计如下:
,样本对数似然估计如下:
使用前面得到的x的概率密度函数,得

大括号里面是![]() 。
。
接下来就是对W求导了,这里牵涉一个问题是对行列式|W|进行求导的方法,属于矩阵微积分。这里先给出结果,在文章最后再给出推导公式。
![]()
最终得到的求导后公式如下,![]() 的导数为
的导数为![]() (可以自己验证):
(可以自己验证):

其中![]() 是梯度上升速率,人为指定。
是梯度上升速率,人为指定。
当迭代求出W后,便可得到![]() 来还原出原始信号。
来还原出原始信号。
注意:我们计算最大似然估计时,假设了![]() 与
与![]() 之间是独立的,然而对于语音信号或者其他具有时间连续依赖特性(比如温度)上,这个假设不能成立。但是在数据足够多时,假设独立对效果影响不大,同时如果事先打乱样例,并运行随机梯度上升算法,那么能够加快收敛速度。
之间是独立的,然而对于语音信号或者其他具有时间连续依赖特性(比如温度)上,这个假设不能成立。但是在数据足够多时,假设独立对效果影响不大,同时如果事先打乱样例,并运行随机梯度上升算法,那么能够加快收敛速度。
回顾一下鸡尾酒宴会问题,s是人发出的信号,是连续值,不同时间点的s不同,每个人发出的信号之间独立(![]() 和
和![]() 之间独立)。s的累计概率分布函数是sigmoid函数,但是所有人发出声音信号都符合这个分布。A(W的逆阵)代表了s相对于x的位置变化,x是s和A变化后的结果。
之间独立)。s的累计概率分布函数是sigmoid函数,但是所有人发出声音信号都符合这个分布。A(W的逆阵)代表了s相对于x的位置变化,x是s和A变化后的结果。
5. 实例

s=2时的原始信号

观察到的x信号

使用ICA还原后的s信号
6. 行列式的梯度
对行列式求导,设矩阵A是n×n的,我们知道行列式与代数余子式有关,

![]() 是去掉第i行第j列后的余子式,那么对
是去掉第i行第j列后的余子式,那么对![]() 求导得
求导得

adj(A)跟我们线性代数中学的![]() 是一个意思,因此
是一个意思,因此
![]()
7. ICA算法扩展描述
上面介绍的内容基本上是讲义上的,与我看的另一篇《Independent Component Analysis:
Algorithms and Applications》(Aapo Hyvärinen and Erkki Oja)有点出入。下面总结一下这篇文章里提到的一些内容(有些我也没看明白)。
首先里面提到了一个与“独立”相似的概念“不相关(uncorrelated)”。Uncorrelated属于部分独立,而不是完全独立,怎么刻画呢?
如果随机变量![]() 和
和![]() 是独立的,当且仅当
是独立的,当且仅当![]() 。
。
如果随机变量![]() 和
和![]() 是不相关的,当且仅当
是不相关的,当且仅当![]()
第二个不相关的条件要比第一个独立的条件“松”一些。因为独立能推出不相关,不相关推不出独立。
证明如下:

![]()

反过来不能推出。
比如,![]() 和
和![]() 的联合分布如下(0,1),(0,-1),(1,0),(-1,0)。
的联合分布如下(0,1),(0,-1),(1,0),(-1,0)。
![]()
因此![]() 和
和![]() 不相关,但是
不相关,但是
![]()
因此![]() 和
和![]() 不满足上面的积分公式,
不满足上面的积分公式,![]() 和
和![]() 不是独立的。
不是独立的。
上面提到过,如果![]() 是高斯分布的,A是正交的,那么
是高斯分布的,A是正交的,那么![]() 也是高斯分布的,且
也是高斯分布的,且![]() 与
与![]() 之间是独立的。那么无法确定A,因为任何正交变换都可以让
之间是独立的。那么无法确定A,因为任何正交变换都可以让![]() 达到同分布的效果。但是如果
达到同分布的效果。但是如果![]() 中只有一个分量是高斯分布的,仍然可以使用ICA。
中只有一个分量是高斯分布的,仍然可以使用ICA。
那么ICA要解决的问题变为:如何从x中推出s,使得s最不可能满足高斯分布?
中心极限定理告诉我们:大量独立同分布随机变量之和满足高斯分布。

我们一直假设的是是由独立同分布的主元
![]() 经过混合矩阵A生成。那么为了求
经过混合矩阵A生成。那么为了求![]() ,我们需要计算
,我们需要计算![]() 的每个分量
的每个分量![]() 。定义
。定义![]() ,那么
,那么![]() ,之所以这么麻烦再定义z是想说明一个关系,我们想通过整出一个
,之所以这么麻烦再定义z是想说明一个关系,我们想通过整出一个![]() 来对
来对![]() 进行线性组合,得出y。而我们不知道得出的y是否是真正的s的分量,但我们知道y是s的真正分量的线性组合。由于我们不能使s的分量成为高斯分布,因此我们的目标求是让y(也就是
进行线性组合,得出y。而我们不知道得出的y是否是真正的s的分量,但我们知道y是s的真正分量的线性组合。由于我们不能使s的分量成为高斯分布,因此我们的目标求是让y(也就是![]() )最不可能是高斯分布时的w。
)最不可能是高斯分布时的w。
那么问题递归到如何度量y是否是高斯分布的了。
一种度量方法是kurtosis方法,公式如下:
![]()
如果y是高斯分布,那么该函数值为0,否则绝大多数情况下值不为0。
但这种度量方法不怎么好,有很多问题。看下一种方法:
负熵(Negentropy)度量方法。
我们在信息论里面知道对于离散的随机变量Y,其熵是
![]()
连续值时是
![]()
在信息论里有一个强有力的结论是:高斯分布的随机变量是同方差分布中熵最大的。也就是说对于一个随机变量来说,满足高斯分布时,最随机。
定义负熵的计算公式如下:
![]()
也就是随机变量y相对于高斯分布时的熵差,这个公式的问题就是直接计算时较为复杂,一般采用逼近策略。

这种逼近策略不够好,作者提出了基于最大熵的更优的公式:

之后的FastICA就基于这个公式。
另外一种度量方法是最小互信息方法:

这个公式可以这样解释,前一个H是![]() 的编码长度(以信息编码的方式理解),第二个H是y成为随机变量时的平均编码长度。之后的内容包括FastICA就不再介绍了,我也没看懂。
的编码长度(以信息编码的方式理解),第二个H是y成为随机变量时的平均编码长度。之后的内容包括FastICA就不再介绍了,我也没看懂。
8. ICA的投影追踪解释(Projection Pursuit)
投影追踪在统计学中的意思是去寻找多维数据的“interesting”投影。这些投影可用在数据可视化、密度估计和回归中。比如在一维的投影追踪中,我们寻找一条直线,使得所有的数据点投影到直线上后,能够反映出数据的分布。然而我们最不想要的是高斯分布,最不像高斯分布的数据点最interesting。这个与我们的ICA思想是一直的,寻找独立的最不可能是高斯分布的s。
在下图中,主元是纵轴,拥有最大的方差,但最interesting的是横轴,因为它可以将两个类分开(信号分离)。

9. ICA算法的前处理步骤
1、中心化:也就是求x均值,然后让所有x减去均值,这一步与PCA一致。
2、漂白:目的是将x乘以一个矩阵变成![]() ,使得
,使得![]() 的协方差矩阵是
的协方差矩阵是![]() 。解释一下吧,原始的向量是x。转换后的是
。解释一下吧,原始的向量是x。转换后的是![]() 。
。
![]() 的协方差矩阵是
的协方差矩阵是![]() ,即
,即
![]()
我们只需用下面的变换,就可以从x得到想要的![]() 。
。
![]()
其中使用特征值分解来得到E(特征向量矩阵)和D(特征值对角矩阵),计算公式为
![]()
下面用个图来直观描述一下:
假设信号源s1和s2是独立的,比如下图横轴是s1,纵轴是s2,根据s1得不到s2。

我们只知道他们合成后的信号x,如下

此时x1和x2不是独立的(比如看最上面的尖角,知道了x1就知道了x2)。那么直接代入我们之前的极大似然概率估计会有问题,因为我们假定x是独立的。
因此,漂白这一步为了让x独立。漂白结果如下:

可以看到数据变成了方阵,在![]() 的维度上已经达到了独立。
的维度上已经达到了独立。
然而这时x分布很好的情况下能够这样转换,当有噪音时怎么办呢?可以先使用前面提到的PCA方法来对数据进行降维,滤去噪声信号,得到k维的正交向量,然后再使用ICA。
10. 小结
ICA的盲信号分析领域的一个强有力方法,也是求非高斯分布数据隐含因子的方法。从之前我们熟悉的样本-特征角度看,我们使用ICA的前提条件是,认为样本数据由独立非高斯分布的隐含因子产生,隐含因子个数等于特征数,我们要求的是隐含因子。
而PCA认为特征是由k个正交的特征(也可看作是隐含因子)生成的,我们要求的是数据在新特征上的投影。同是因子分析,一个用来更适合用来还原信号(因为信号比较有规律,经常不是高斯分布的),一个更适合用来降维(用那么多特征干嘛,k个正交的即可)。有时候也需要组合两者一起使用。这段是我的个人理解,仅供参考。
五.MDS
假设给定N个点,切每对点之间的距离dij.但我们不知道这些点的确切坐标,也不知道他们的维度,以及该距离是如何计算的。多维定标(MDS)是把这些点映射到低维空间(如2维)的方法,使他们在低维空间的欧式距离尽可能的接近原空间给定的距离dij.实际上,在相关矩阵上而不是协方差矩阵上做PCA等价于标准化的欧式距离做MDS,其中每个变量有单位方差。这里也不做详细解释。
六.线性判别分析(LDA)
1. 问题
之前我们讨论的PCA、ICA也好,对样本数据来言,可以是没有类别标签y的。回想我们做回归时,如果特征太多,那么会产生不相关特征引入、过度拟合等问题。我们可以使用PCA来降维,但PCA没有将类别标签考虑进去,属于无监督的。
比如回到上次提出的文档中含有“learn”和“study”的问题,使用PCA后,也许可以将这两个特征合并为一个,降了维度。但假设我们的类别标签y是判断这篇文章的topic是不是有关学习方面的。那么这两个特征对y几乎没什么影响,完全可以去除。
再举一个例子,假设我们对一张100*100像素的图片做人脸识别,每个像素是一个特征,那么会有10000个特征,而对应的类别标签y仅仅是0/1值,1代表是人脸。这么多特征不仅训练复杂,而且不必要特征对结果会带来不可预知的影响,但我们想得到降维后的一些最佳特征(与y关系最密切的),怎么办呢?
2. 线性判别分析(二类情况)
回顾我们之前的logistic回归方法,给定m个n维特征的训练样例![]() (i从1到m),每个
(i从1到m),每个![]() 对应一个类标签
对应一个类标签![]() 。我们就是要学习出参数
。我们就是要学习出参数![]() ,使得
,使得![]() (g是sigmoid函数)。
(g是sigmoid函数)。
现在只考虑二值分类情况,也就是y=1或者y=0。
为了方便表示,我们先换符号重新定义问题,给定特征为d维的N个样例,![]() ,其中有
,其中有![]() 个样例属于类别
个样例属于类别![]() ,另外
,另外![]() 个样例属于类别
个样例属于类别![]() 。
。
现在我们觉得原始特征数太多,想将d维特征降到只有一维,而又要保证类别能够“清晰”地反映在低维数据上,也就是这一维就能决定每个样例的类别。
我们将这个最佳的向量称为w(d维),那么样例x(d维)到w上的投影可以用下式来计算
![]()
这里得到的y值不是0/1值,而是x投影到直线上的点到原点的距离。
当x是二维的,我们就是要找一条直线(方向为w)来做投影,然后寻找最能使样本点分离的直线。如下图:

从直观上来看,右图比较好,可以很好地将不同类别的样本点分离。
接下来我们从定量的角度来找到这个最佳的w。
首先我们寻找每类样例的均值(中心点),这里i只有两个

由于x到w投影后的样本点均值为

由此可知,投影后的的均值也就是样本中心点的投影。
什么是最佳的直线(w)呢?我们首先发现,能够使投影后的两类样本中心点尽量分离的直线是好的直线,定量表示就是:
![]()
J(w)越大越好。
但是只考虑J(w)行不行呢?不行,看下图

样本点均匀分布在椭圆里,投影到横轴x1上时能够获得更大的中心点间距J(w),但是由于有重叠,x1不能分离样本点。投影到纵轴x2上,虽然J(w)较小,但是能够分离样本点。因此我们还需要考虑样本点之间的方差,方差越大,样本点越难以分离。
我们使用另外一个度量值,称作散列值(scatter),对投影后的类求散列值,如下

从公式中可以看出,只是少除以样本数量的方差值,散列值的几何意义是样本点的密集程度,值越大,越分散,反之,越集中。
而我们想要的投影后的样本点的样子是:不同类别的样本点越分开越好,同类的越聚集越好,也就是均值差越大越好,散列值越小越好。正好,我们可以使用J(w)和S来度量,最终的度量公式是

接下来的事就比较明显了,我们只需寻找使J(w)最大的w即可。
先把散列值公式展开

我们定义上式中中间那部分

这个公式的样子不就是少除以样例数的协方差矩阵么,称为散列矩阵(scatter matrices)
我们继续定义
![]()
![]() 称为Within-class scatter matrix。
称为Within-class scatter matrix。
那么回到上面![]() 的公式,使用
的公式,使用![]() 替换中间部分,得
替换中间部分,得
![]()
![]()
然后,我们展开分子

![]() 称为Between-class scatter,是两个向量的外积,虽然是个矩阵,但秩为1。
称为Between-class scatter,是两个向量的外积,虽然是个矩阵,但秩为1。
那么J(w)最终可以表示为

在我们求导之前,需要对分母进行归一化,因为不做归一的话,w扩大任何倍,都成立,我们就无法确定w。因此我们打算令![]() ,那么加入拉格朗日乘子后,求导
,那么加入拉格朗日乘子后,求导

其中用到了矩阵微积分,求导时可以简单地把![]() 当做
当做![]() 看待。
看待。
如果![]() 可逆,那么将求导后的结果两边都乘以
可逆,那么将求导后的结果两边都乘以![]() ,得
,得

这个可喜的结果就是w就是矩阵![]() 的特征向量了。
的特征向量了。
这个公式称为Fisher linear discrimination。
等等,让我们再观察一下,发现前面![]() 的公式
的公式
![]()
那么
![]()
代入最后的特征值公式得
![]()
由于对w扩大缩小任何倍不影响结果,因此可以约去两边的未知常数![]() 和
和![]() ,得到
,得到
![]()
至此,我们只需要求出原始样本的均值和方差就可以求出最佳的方向w,这就是Fisher于1936年提出的线性判别分析。
看上面二维样本的投影结果图:

3. 线性判别分析(多类情况)
前面是针对只有两个类的情况,假设类别变成多个了,那么要怎么改变,才能保证投影后类别能够分离呢?
我们之前讨论的是如何将d维降到一维,现在类别多了,一维可能已经不能满足要求。假设我们有C个类别,需要K维向量(或者叫做基向量)来做投影。
将这K维向量表示为![]() 。
。
我们将样本点在这K维向量投影后结果表示为![]() ,有以下公式成立
,有以下公式成立
![]()
![]()
为了像上节一样度量J(w),我们打算仍然从类间散列度和类内散列度来考虑。
当样本是二维时,我们从几何意义上考虑:

其中![]() 和
和![]() 与上节的意义一样,
与上节的意义一样,![]() 是类别1里的样本点相对于该类中心点
是类别1里的样本点相对于该类中心点![]() 的散列程度。
的散列程度。![]() 变成类别1中心点相对于样本中心点
变成类别1中心点相对于样本中心点![]() 的协方差矩阵,即类1相对于
的协方差矩阵,即类1相对于![]() 的散列程度。
的散列程度。
![]() 为
为

![]() 的计算公式不变,仍然类似于类内部样本点的协方差矩阵
的计算公式不变,仍然类似于类内部样本点的协方差矩阵

![]() 需要变,原来度量的是两个均值点的散列情况,现在度量的是每类均值点相对于样本中心的散列情况。类似于将
需要变,原来度量的是两个均值点的散列情况,现在度量的是每类均值点相对于样本中心的散列情况。类似于将![]() 看作样本点,
看作样本点,![]() 是均值的协方差矩阵,如果某类里面的样本点较多,那么其权重稍大,权重用Ni/N表示,但由于J(w)对倍数不敏感,因此使用Ni。
是均值的协方差矩阵,如果某类里面的样本点较多,那么其权重稍大,权重用Ni/N表示,但由于J(w)对倍数不敏感,因此使用Ni。

其中

![]() 是所有样本的均值。
是所有样本的均值。
上面讨论的都是在投影前的公式变化,但真正的J(w)的分子分母都是在投影后计算的。下面我们看样本点投影后的公式改变:
这两个是第i类样本点在某基向量上投影后的均值计算公式。


下面两个是在某基向量上投影后的![]() 和
和![]()


其实就是将![]() 换成了
换成了![]() 。
。
综合各个投影向量(w)上的![]() 和
和![]() ,更新这两个参数,得到
,更新这两个参数,得到
![]()
![]()
W是基向量矩阵,![]() 是投影后的各个类内部的散列矩阵之和,
是投影后的各个类内部的散列矩阵之和,![]() 是投影后各个类中心相对于全样本中心投影的散列矩阵之和。
是投影后各个类中心相对于全样本中心投影的散列矩阵之和。
回想我们上节的公式J(w),分子是两类中心距,分母是每个类自己的散列度。现在投影方向是多维了(好几条直线),分子需要做一些改变,我们不是求两两样本中心距之和(这个对描述类别间的分散程度没有用),而是求每类中心相对于全样本中心的散列度之和。
然而,最后的J(w)的形式是

由于我们得到的分子分母都是散列矩阵,要将矩阵变成实数,需要取行列式。又因为行列式的值实际上是矩阵特征值的积,一个特征值可以表示在该特征向量上的发散程度。因此我们使用行列式来计算(此处我感觉有点牵强,道理不是那么有说服力)。
整个问题又回归为求J(w)的最大值了,我们固定分母为1,然后求导,得出最后结果(我翻查了很多讲义和文章,没有找到求导的过程)
![]()
与上节得出的结论一样
![]()
最后还归结到了求矩阵的特征值上来了。首先求出![]() 的特征值,然后取前K个特征向量组成W矩阵即可。
的特征值,然后取前K个特征向量组成W矩阵即可。
注意:由于![]() 中的
中的![]() 秩为1,因此
秩为1,因此![]() 的秩至多为C(矩阵的秩小于等于各个相加矩阵的秩的和)。由于知道了前C-1个
的秩至多为C(矩阵的秩小于等于各个相加矩阵的秩的和)。由于知道了前C-1个![]() 后,最后一个
后,最后一个![]() 可以有前面的
可以有前面的![]() 来线性表示,因此
来线性表示,因此![]() 的秩至多为C-1。那么K最大为C-1,即特征向量最多有C-1个。特征值大的对应的特征向量分割性能最好。
的秩至多为C-1。那么K最大为C-1,即特征向量最多有C-1个。特征值大的对应的特征向量分割性能最好。
由于![]() 不一定是对称阵,因此得到的K个特征向量不一定正交,这也是与PCA不同的地方。
不一定是对称阵,因此得到的K个特征向量不一定正交,这也是与PCA不同的地方。
4. 实例
将3维空间上的球体样本点投影到二维上,W1相比W2能够获得更好的分离效果。

PCA与LDA的降维对比:

PCA选择样本点投影具有最大方差的方向,LDA选择分类性能最好的方向。
LDA既然叫做线性判别分析,应该具有一定的预测功能,比如新来一个样例x,如何确定其类别?
拿二值分来来说,我们可以将其投影到直线上,得到y,然后看看y是否在超过某个阈值y0,超过是某一类,否则是另一类。而怎么寻找这个y0呢?
看
![]()
根据中心极限定理,独立同分布的随机变量和符合高斯分布,然后利用极大似然估计求
![]()
然后用决策理论里的公式来寻找最佳的y0,详情请参阅PRML。
这是一种可行但比较繁琐的选取方法,可以看第7节(一些问题)来得到简单的答案。
5. 使用LDA的一些限制
1、 LDA至多可生成C-1维子空间
LDA降维后的维度区间在[1,C-1],与原始特征数n无关,对于二值分类,最多投影到1维。
2、 LDA不适合对非高斯分布样本进行降维。

上图中红色区域表示一类样本,蓝色区域表示另一类,由于是2类,所以最多投影到1维上。不管在直线上怎么投影,都难使红色点和蓝色点内部凝聚,类间分离。
3、 LDA在样本分类信息依赖方差而不是均值时,效果不好。

上图中,样本点依靠方差信息进行分类,而不是均值信息。LDA不能够进行有效分类,因为LDA过度依靠均值信息。
4、 LDA可能过度拟合数据。
6. LDA的一些变种
1、 非参数LDA
非参数LDA使用本地信息和K临近样本点来计算![]() ,使得
,使得![]() 是全秩的,这样我们可以抽取多余C-1个特征向量。而且投影后分离效果更好。
是全秩的,这样我们可以抽取多余C-1个特征向量。而且投影后分离效果更好。
2、 正交LDA
先找到最佳的特征向量,然后找与这个特征向量正交且最大化fisher条件的向量。这种方法也能摆脱C-1的限制。
3、 一般化LDA
引入了贝叶斯风险等理论
4、 核函数LDA
将特征![]() ,使用核函数来计算。
,使用核函数来计算。
7. 一些问题
上面在多值分类中使用的

是带权重的各类样本中心到全样本中心的散列矩阵。如果C=2(也就是二值分类时)套用这个公式,不能够得出在二值分类中使用的![]() 。
。

因此二值分类和多值分类时求得的![]() 会不同,而
会不同,而![]() 意义是一致的。
意义是一致的。
对于二值分类问题,令人惊奇的是最小二乘法和Fisher线性判别分析是一致的。
下面我们证明这个结论,并且给出第4节提出的y0值得选取问题。
回顾之前的线性回归,给定N个d维特征的训练样例![]() (i从1到N),每个
(i从1到N),每个![]() 对应一个类标签
对应一个类标签![]() 。我们之前令y=0表示一类,y=1表示另一类,现在我们为了证明最小二乘法和LDA的关系,我们需要做一些改变
。我们之前令y=0表示一类,y=1表示另一类,现在我们为了证明最小二乘法和LDA的关系,我们需要做一些改变

就是将0/1做了值替换。
我们列出最小二乘法公式

w和![]() 是拟合权重参数。
是拟合权重参数。
分别对![]() 和w求导得
和w求导得


从第一个式子展开可以得到

消元后,得
![]()

可以证明第二个式子展开后和下面的公式等价
![]()
其中![]() 和
和![]() 与二值分类中的公式一样。
与二值分类中的公式一样。
由于![]()
因此,最后结果仍然是
![]()
这个过程从几何意义上去理解也就是变形后的线性回归(将类标签重新定义),线性回归后的直线方向就是二值分类中LDA求得的直线方向w。
好了,我们从改变后的y的定义可以看出y>0属于类![]() ,y<0属于类
,y<0属于类![]() 。因此我们可以选取y0=0,即如果
。因此我们可以选取y0=0,即如果![]() ,就是类
,就是类![]() ,否则是类
,否则是类![]() 。
。
这里主要介绍线性判别式分析(LDA),主要基于Fisher Discriminant Analysis with Kernals[1]和Fisher Linear Discriminant Analysis[2]两篇文献。
LDA与PCA的一大不同点在于,LDA是有监督的算法,而PCA是无监督的,因为PCA算法没有考虑数据的标签(类别),只是把原数据映射到一些方差比较大的方向(基)上去而已。而LDA算法则考虑了数据的标签。文献[2]中举了一个非常形象的例子,说明了在有些情况下,PCA算法的性能很差,如下图:
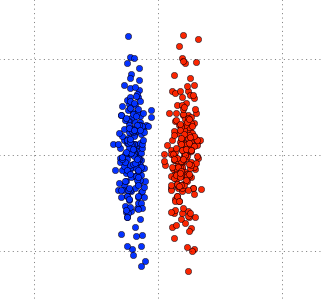 我们用不同的颜色标注C1,C2两个不同类别的数据。根据PCA算法,数据应该映射到方差最大的那个方向,亦即Y轴方向,但是如果映射到Y轴方向,C1,C2两个不同类别的数据将完全混合在一起,很难区分开,所以使用PCA算法进行降维后再进行分类的效果会非常差。但是使用LDA算法,数据会映射到X轴方向。
我们用不同的颜色标注C1,C2两个不同类别的数据。根据PCA算法,数据应该映射到方差最大的那个方向,亦即Y轴方向,但是如果映射到Y轴方向,C1,C2两个不同类别的数据将完全混合在一起,很难区分开,所以使用PCA算法进行降维后再进行分类的效果会非常差。但是使用LDA算法,数据会映射到X轴方向。
LDA算法会考虑到数据的类别属性,给定两个类别C1、C2,我们希望找到一个向量ω,当数据映射到ω的方向上时,来自两个类的数据尽可能的分开,同一个类内的数据尽可能的紧凑。数据的映射公式为:z=ωTx, 其中z是数据x到ω上的投影,因而也是一个d维到1维的维度归约。
令 m 1和m 1分别表示C1类数据投影之前个投影之后的均值,易知m 1=ωTm1,同理m2=ωTm2
令s 1 2和s22分别表示C1和C2类数据在投影之后的散布(scatter),亦即s12=∑(ωTxt-m1)2rt,s22=∑(ωTxt-m2)2(1-rt)其中如果xt∈C1,则rt=1,否则rt=0。
我们希望|m 1-m 2|尽可能的大,而s12+s22尽可能的小,Fisher线性判别式就是最大化下面式子的ω:
J(ω)=(m 1-m 2)2/(s12+s22) 式子-1
改写式子-1中的分子: (m 1-m 2)2= (ωTm1-ωTm2)2=ωT(m1-m2)(m1-m2)Tω=ωTSBω
其中 S B=( m 1- m 2)(m1-m2)T 式子-2
是 类间散布矩阵(between class scatter matrix)。
改写式子-1中的分母:
∑(ω Tx t-m1)2rt=∑ωT(xt-m1)(xt-m1)Tωrt=ωTS1ω, 其中S 1=∑rt(xt-m1)(xt-m1)T是C1的类内散布矩阵(within class scatter matrix)。
令 S W= S 1+ S 2,是 类内散布的总和,则s 12+s22=ωTSWω。
所以式子-1可以改写为:
J(ω)=(ω T S Bω)/(ω TSWω) 式子-3
我们只需要使式子-3对于ω求导,然后使导数等于0,便可以求出ω的值:ω=c S W-1(m1-m2),其中c是一个参数,我们只对ω的方向感兴趣,所以c可以取值为1.
另外,最后求得的 J(ω)的值等于λ k,λ k是SW-1SB的最大的特征值,而ω则是SW-1SB的最大特征值所对应的特征向量。
最后有一些关于LDA算法的讨论,出自文献[1]:
1. Fisher LDA对数据的分布做了一些很强的假设,比如每个类的数据都是高斯分布,各个类的协方差相等。虽然这些强假设很可能在实际数据中并不满足,但是Fisher LDA已经被证明是非常有效地降维算法,其中的原因是线性模型对于噪音的鲁棒性比较好,不容易过拟合。
2. 准确的估计数据的散布矩阵是非常重要的,很可能会有较大的偏置。用式子-2进行估计在样本数据比较少(相对于维数来说)时会产生较大的变异性。
参考文献:
[1] Fisher Discriminant Analysis with Kernals. Sebastian Mika, Gunnar Ratsch, Jason Weston, Bernhadr Scholkopf, Klaus-Robert Muller.
[2] Fisher Linear Discriminant Analysis. Max Welling.
[3] 机器学习导论。 Ethem Alpaydin
七.局部线性嵌入LLE
LLE(Locally Linear Embedding)算法,即局部线性嵌入算法。该算法是针对非线性信号特征矢量维数的优化方法,这种维数优化并不是仅仅在数量上简单的约简,而是在保持原始数据性质不变的情况下,将高维空间的信号映射到低维空间上,即特征值的二次提取[1] 。
理论的提出
LLE 是 S.T.Roweis 等人提出了一种针对非线性数据的无监督降维方法,它是流行学习算法中的一种用局部线性反映全局的非线性的算法,并能够使降维的数据保持原有数据的拓扑结构。LLE 是一种用局部线性的非线性维数约简方法,该算法在一定程度上扩大了对维数约简的认识。[2]
-
- 1. 龚明.基于局部线性嵌入算法的柴油机故障诊断研究[硕士学位论文].太原:中北大学,2013.
- 2. Mclvor R T ,Humphreys P K.A case-based reasoning approach to the make or buy decision[J].Integrated Manufacturing Systems,2000(5):295~310.
- 3. 王珏,周志华,周傲英.机器学习及其应用:清华大学出版社,2000:135-139
- 4. 罗方琼.LLE 流行学习的若干问题分析[J].研究与开发,2012(3):13~16
八.等距特征映射
实际上,6和7属于流形算法了。这里简单解释下等距特征映射,也叫ISOMAP。
例如,一张人脸100*100的二维图像,在这种情况下,每张人脸是10000维空间里的一个点。假设随着一个人由右向左慢慢转动头部,我们取一系列照片,我们得到这个面部图像序列沿着10000维空间中的一条轨迹,而这条曲线不是线性的。现在考虑许多人的人脸,随着他们转动头部,所有人的人脸轨迹定义了10000维空间中的一个流形,并且这就是我们想要建模的。实际上,两张人脸的相似性,不能简单用像素差的和表示,而是应该计算沿着流形的距离,这称作测地距离。等距特征映射就是估计这种距离,使用多维定标进行纬度归约。
九.小波变换
离散小波变换(DWT)是一种线性信号处理技术,当用于数据向量X时,将它变换成数值上不同的小波系数向量X’。两个向量具有相同的长度。当这种技术用于数据归约时,每个元组看作一个n维数据向量,即X = (x1, x2, ., xn),描述n个数据库属性在元组上的n个测量值。
“如果小波变换的数据与原数据的长度相等,这种技术如何能够用于数据归约?”关键在在我们的记号中,代表向量的变量用粗斜体,描述向量的度量用斜体。
于小波变换后的数据可以截短。仅存放一小部分最强的小波系数,就能保留近似的压缩数据。
例如,保留大于用户设定的某个阈值的所有小波系数,其他系数置为0。这样,结果数据表示非常稀疏,使得如果在小波空间进行计算,利用数据稀疏特点的操作计算得非常快。该技术也能用于消除噪声,而不会光滑掉数据的主要特征,使得它们也能有效地用于数据清理。给定一组系数,使用所用的DWT的逆,可以构造原数据的近似。
DWT与离散傅里叶变换(DFT)有密切关系,DFT是一种涉及正弦和余弦的信号处理技术。然而一般地说,DWT是一种更好的有损压缩。也就是说,对于给定的数据向量,如果DWT和DFT保留相同数目的系数,DWT将提供原数据的更准确的近似。因此,对于等价的近似,DWT比DFT需要的空间小。不像DFT,小波空间局部性相当好,有助于保留局部细节。
只有一种DFT,但有若干族DWT。图2-16显示了一些小波族。流行的小波变换包括Haar-2, Daubechies-4和Daubechies-6变换。应用离散小波变换的一般过程使用一种分层金字塔算法(pyramid algorithm),它在每次迭代将数据减半,导致很快的计算速度。该方法如下:
图2-16 小波族的例子。小波名后的数是小波的消失瞬间。这是系数必须满足的数学联系集,并且与小波系数的个数有关
(1)输入数据向量的长度L必须是2的整数幂。必要时(L≥n),通过在数据向量后添加0, 这一条件可以满足。
(2)每个变换涉及应用两个函数。第一个使用某种数据光滑,如求和或加权平均。第二个进行加权差分,产生数据的细节特征。
(3)两个函数作用于X中的数据点对,即用于所有的测量对(x2i, x2i+1)。这导致两个长度为L/2的数据集。一般,它们分别代表输入数据的光滑后的版本或低频版本和它的高频内容。
(4)两个函数递归地作用于前面循环得到的数据集,直到得到的数据集长度为2。
(5)由以上迭代得到的数据集中选择值,指定其为数据变换的小波系数。等价地,可以将矩阵乘法用于输入数据,以得到小波系数。所用的矩阵依赖于给定的DWT。矩阵必须是标准正交的,即列是单位向量并相互正交,使得矩阵的逆是它的转置。尽管受篇幅限制,这里我们不再讨论,但这种性质允许由光滑和光滑-差数据集重构数据。通过将矩阵因子分解成几个稀疏矩阵,对于长度为n的输入向量,“快速DWT”算法的复杂度为O (n)。
小波变换可以用于多维数据,如数据立方体。可以按以下方法做:首先将变换用于第一个维,然后第二个,如此下去。计算复杂性关于立方体中单元的个数是线性的。对于稀疏或倾斜数据和具有有序属性的数据,小波变换给出很好的结果。据报道,小波变换的有损压缩比当前的商业标准JPEG压缩好。小波变换有许多实际应用,包括指纹图像压缩、计算机视觉、时间序列数据分析和数据清理。
流形学习
转自http://blog.sciencenet.cn/blog-722391-583413.html
流形(manifold)的概念最早是在1854年由 Riemann 提出的(德文Mannigfaltigkeit),现代使用的流形定义则是由 Hermann Weyl 在1913年给出的。江泽涵先生对这个名词的翻译出自文天祥《正气歌》“天地有正气,杂然赋流形”,日本人则将之译为“多样体”,二者孰雅孰鄙,高下立判。
流形(Manifold),一般可以认为是局部具有欧氏空间性质的空间。而实际上欧氏空间就是流形最简单的实例。像地球表面这样的球面是一个稍为复杂的例子。一般的流形可以通过把许多平直的片折弯并粘连而成。
流形在数学中用于描述几何形体,它们提供了研究可微性的最自然的舞台。物理上,经典力学的相空间和构造广义相对论的时空模型的四维伪黎曼流形都是流形的实例。他们也用于组态空间(configuration space)。环(torus)就是双摆的组态空间。
如果把几何形体的拓扑结构看作是完全柔软的,因为所有变形(同胚)会保持拓扑结构不变,而把解析簇看作是硬的,因为整体的结构都是固定的(譬如一个1维多项式,如果你知道(0,1)区间的取值,则整个实属范围的值都是固定的,局部的扰动会导致全局的变化),那么我们可以把光滑流形看作是介于两者之间的形体,其无穷小的结构是硬的,而整体结构是软的。这也许是中文译名流形的原因(整体的形态可以流动),该译名由著名数学家和数学教育学家江泽涵引入。这样,流形的硬度使它能够容纳微分结构,而它的软度使得它可以作为很多需要独立的局部扰动的数学和物理上的模型。
最容易定义的流形是拓扑流形,它局部看起来象一些"普通"的欧氏空间Rn。形式化的讲,一个拓扑流形是一个局部同胚于一个欧氏空间的拓扑空间。这表示每个点有一个领域,它有一个同胚(连续双射其逆也连续)将它映射到Rn。这些同胚是流形的坐标图。
通常附加的技术性假设被加在该拓扑空间上,以排除病态的情形。可以根据需要要求空间是豪斯朵夫的并且第二可数。这表示下面所述的有两个原点的直线不是拓扑流形,因为它不是豪斯朵夫的。
流形在某一点的维度就是该点映射到的欧氏空间图的维度(定义中的数字n)。连通流形中的所有点有相同的维度。有些作者要求拓扑流形的所有的图映射到同一欧氏空间。这种情况下,拓扑空间有一个拓扑不变量,也就是它的维度。其他作者允许拓扑流形的不交并有不同的维度。
自从2000年以后,流形学习被认为属于非线性降维的一个分支。众所周知,引导这一领域迅速发展的是2000年Science杂志上的两篇文章: Isomap and LLE (Locally Linear Embedding)。
1. 流形学习的基本概念
那流形学习是什莫呢?为了好懂,我尽可能应用少的数学概念来解释这个东西。所谓流形(manifold)就是一般的几何对象的总称。比如人,有中国人、美国人等等;流形就包括各种维数的曲线曲面等。和一般的降维分析一样,流形学习把一组在高维空间中的数据在低维空间中重新表示。和以往方法不同的是,在流形学习中有一个假设,就是所处理的数据采样于一个潜在的流形上,或是说对于这组数据存在一个潜在的流形。对于不同的方法,对于流形性质的要求各不相同,这也就产生了在流形假设下的各种不同性质的假设,比如在Laplacian Eigenmaps中要假设这个流形是紧致黎曼流形等。对于描述流形上的点,我们要用坐标,而流形上本身是没有坐标的,所以为了表示流形上的点,必须把流形放入外围空间(ambient space)中,那末流形上的点就可以用外围空间的坐标来表示。比如R^3中的球面是个2维的曲面,因为球面上只有两个自由度,但是球面上的点一般是用外围R^3空间中的坐标表示的,所以我们看到的R^3中球面上的点有3个数来表示的。当然球面还有柱坐标球坐标等表示。对于R^3中的球面来说,那末流形学习可以粗略的概括为给出R^3中的表示,在保持球面上点某些几何性质的条件下,找出找到一组对应的内蕴坐标(intrinsic coordinate)表示,显然这个表示应该是两维的,因为球面的维数是两维的。这个过程也叫参数化(parameterization)。直观上来说,就是把这个球面尽量好的展开在通过原点的平面上。在PAMI中,这样的低维表示也叫内蕴特征(intrinsic feature)。一般外围空间的维数也叫观察维数,其表示也叫自然坐标(外围空间是欧式空间)表示,在统计中一般叫observation。
了解了流形学习的这个基础,那末流形学习中的一些是非也就很自然了,这个下面穿插来说。由此,如果你想学好流形学习里的方法,你至少要了解一些微分流形和黎曼几何的基本知识。
2. 代表方法
a) Isomap。
Josh Tenenbaum的Isomap开创了一个数据处理的新战场。在没有具体说Isomap之前,有必要先说说MDS(Multidimensional Scaling)这个方法。我们国内的很多人知道PCA,却很多人不知道MDS。PCA和MDS是相互对偶的两个方法。MDS就是理论上保持欧式距离的一个经典方法,MDS最早主要用于做数据的可视化。由于MDS得到的低维表示中心在原点,所以又可以说保持内积。也就是说,用低维空间中的内积近似高维空间中的距离。经典的MDS方法,高维空间中的距离一般用欧式距离。
Isomap就是借窝生蛋。他的理论框架就是MDS,但是放在流形的理论框架内,原始的距离换成了流形上的测地线(geodesic)距离。其它一模一样。所谓的测地线,就是流形上加速度为零的曲线,等同于欧式空间中的直线。我们经常听到说测地线是流形上两点之间距离最短的线。其实这末说是不严谨的。流形上两点之间距离最短的线是测地线,但是反过来不一定对。另外,如果任意两个点之间都存在一个测地线,那末这个流形必须是连通的邻域都是凸的。Isomap就是把任意两点的测地线距离(准确地说是最短距离)作为流形的几何描述,用MDS理论框架理论上保持这个点与点之间的最短距离。在Isomap中,测地线距离就是用两点之间图上的最短距离来近似的,这方面的算法是一般计算机系中用的图论中的经典算法。
如果你曾细致地看过Isomap主页上的matlab代码,你就会发现那个代码的实现复杂度远超与实际论文中叙述的算法。在那个代码中,除了论文中写出的算法外,还包括了 outlier detection和embedding scaling。这两样东西,保证了运行他们的程序得到了结果一般来说相对比较理想。但是,这在他们的算法中并没有叙述。如果你直接按照他论文中的方法来实现,你可以体会一下这个结果和他们结果的差距。从此我们也可以看出,那几个作者做学问的严谨态度,这是值得我们好好学习的。
另外比较有趣的是,Tenenbaum根本不是做与数据处理有关算法的人,他是做计算认知科学(computational cognition science)的。在做这个方法的时候,他还在stanford,02年就去了MIT开创一派,成了CoCoSci 的掌门人,他的组成长十分迅速。但是有趣的是,在Isomap之后,他包括他在MIT带的学生就从来再也没有做过类似的工作。其原因我今年夏天有所耳闻。他在今年参加 UCLA Alan Yuille 组织的一个summer school上说,(不是原文,是大意)我们经常忘了做研究的原始出发点是什莫。他做Isomap就是为了找一个好的visual perception的方法,他还坚持了他的方向和信仰,computational cognition,他没有随波逐流。而由他引导起来的 manifold learning 却快速的发展成了一个新的方向。
这是一个值得我们好好思考的问题。我们做一个东西,选择一个研究方向究竟是为了什莫。你考虑过吗?
(当然,此问题也在问我自己)
b) LLE (Locally linear Embedding)
LLE在作者写出的表达式看,是个具有十分对称美的方法. 这种看上去的对称对于启发人很重要。LLE的思想就是,一个流形在很小的局部邻域上可以近似看成欧式的,就是局部线性的。那末,在小的局部邻域上,一个点就可以用它周围的点在最小二乘意义下最优的线性表示。LLE把这个线性拟合的系数当成这个流形局部几何性质的刻画。那末一个好的低维表示,就应该也具有同样的局部几何,所以利用同样的线性表示的表达式,最终写成一个二次型的形式,十分自然优美。
注意在LLE出现的两个加和优化的线性表达,第一个是求每一点的线性表示系数的。虽然原始公式中是写在一起的,但是求解时,是对每一个点分别来求得。第二个表示式,是已知所有点的线性表示系数,来求低维表示(或嵌入embedding)的,他是一个整体求解的过程。这两个表达式的转化正好中间转了个弯,使一些人困惑了,特别后面一个公式写成一个二次型的过程并不是那末直观,很多人往往在此卡住,而阻碍了全面的理解。我推荐大家去精读 Saul 在JMLR上的那篇LLE的长文。那篇文章无论在方法表达还是英文书写,我认为都是精品,值得好好玩味学习。
另外值得强调的是,对于每一点处拟合得到的系数归一化的操作特别重要,如果没有这一步,这个算法就没有效果。但是在原始论文中,他们是为了保持数据在平行移动下embedding不变。
LLE的matlab代码写得简洁明了,是一个样板。
在此有必要提提Lawrence Saul这个人。在Isomap和LLE的作者们中,Saul算是唯一一个以流形学习(并不限于)为研究对象开创学派的人。Saul早年主要做参数模型有关的算法。自从LLE以后,坐阵UPen创造了一个个佳绩。主要成就在于他的两个出色学生,Kilian Weinberger和 Fei Sha,做的方法。拿了很多奖,在此不多说,可以到他主页上去看。Weinberger把学习核矩阵引入到流形学习中来。他的这个方法在流形学习中影响到不是很显著,却是在 convex optimization 中人人得知。Fei Sha不用多说了,machine learning中一个闪亮的新星,中国留学生之骄傲。现在他们一个在Yahoo,一个在Jordan手下做PostDoc。
c) Laplacian Eigenmaps
要说哪一个方法被做的全面,那莫非LE莫属。如果只说LE这个方法本身,是不新的,许多年前在做mesh相关的领域就开始这莫用。但是放在黎曼几何的框架内,给出完整的几何分析的,应该是Belkin和Niyogi(LE作者)的功劳。
LE的基本思想就是用一个无向有权图来描述一个流形,然后通过用图的嵌入(graph embedding)来找低维表示。说白了,就是保持图的局部邻接关系的情况把这个图从高维空间中重新画在一个低维空间中(graph drawing)。
在至今为止的流行学习的典型方法中,LE是速度最快、效果相对来说不怎莫样的。但是LE有一个其他方法没有的特点,就是如果出现outlier情况下,它的鲁棒性(robustness)特别好。
后来Belkin和Niyogi又分析了LE的收敛性。大家不要忽视这个问题,很重要。鼓励有兴趣数学功底不错的人好好看看这篇文章。
d) Hessian Eigenmaps
如果你对黎曼几何不懂,基本上看不懂这个方法。又加作者表达的抽象,所以绝大多数人对这个方法了解不透彻。在此我就根据我自己的理解说说这个方法。
这个方法有两个重点:(1)如果一个流形是局部等距(isometric)欧式空间中一个开子集的,那末它的Hessian矩阵具有d+1维的零空间。(2)在每一点处,Hessian系数的估计。
首先作者是通过考察局部Hessian的二次型来得出结论的,如果一个流形局部等距于欧式空间中的一个开子集,那末由这个流形patch到开子集到的映射函数是一个线性函数,线性函数的二次混合导数为零,所以局部上由Hessian系数构成的二次型也为零,这样把每一点都考虑到,过渡到全局的Hessian矩阵就有d+1维的零空间,其中一维是常函数构成的,也就是1向量。其它的d维子空间构成等距坐标。这就是理论基础的大意,当然作者在介绍的时候,为了保持理论严谨,作了一个由切坐标到等距坐标的过渡。
另外一个就是局部上Hessian系数的估计问题。我在此引用一段话:
If you approximate a function f(x) by a quadratic expansion
f(x) = f(0) + (grad f)^T x + x^T Hf x + rem
then the hessian is what you get for the quadratic component. So simply over a given neighborhood, develop the operator that approximates a function by its projection on 1, x_1,...,x_k, x_1^2,...,x_k^2, x_1*x_2,... ,x_{k-1}*x_{k}. Extract the component of the operator that delivers the projection on x_1^2,...,x_k^2, x_1*x_2,... ,x_{k-1}*x_{k}.
dave
这段话是我在初学HE时候,写信问Dave Donoho,他给我的回信。希望大家领会。如果你了解了上述基本含义,再去细看两遍原始论文,也许会有更深的理解。由于HE牵扯到二阶导数的估计,所以对噪声很敏感。另外,HE的原始代码中在计算局部切坐标的时候,用的是奇异值分解(SVD),所以如果想用他们的原始代码跑一下例如图像之类的真实数据,就特别的慢。其实把他们的代码改一下就可以了,利用一般PCA的快速计算方法,计算小尺寸矩阵的特征向量即可。还有,在原始代码中,他把Hessian系数归一化了,这也就是为什莫他们叫这个方法为 Hessian LLE 的原因之一。
Dave Dohono是学术界公认的大牛,在流形学习这一块,是他带着他的一个学生做的,Carrie Grimes。现在这个女性研究员在Google做 project leader,学术界女生同学的楷模 : )
e) LTSA (Local tangent space alignment)
很荣幸,这个是国内学者(浙江大学数学系的老师ZHANG Zhenyue)为第一作者做的一个在流行学习中最出色的方法。由于这个方法是由纯数学做数值分析出身的老师所做,所以原始论文看起来公式一大堆,好像很难似的。其实这个方法非常直观简单。
象 Hessian Eigenmaps 一样,流形的局部几何表达先用切坐标,也就是PCA的主子空间中的坐标。那末对于流形一点处的切空间,它是线性子空间,所以可以和欧式空间中的一个开子集建立同构关系,最简单的就是线性变换。在微分流形中,就叫做切映射 (tangential map),是个很自然很基础的概念。把切坐标求出来,建立出切映射,剩下的就是数值计算了。最终这个算法划归为一个很简单的跌代加和形式。如果你已经明白了MDS,那末你就很容易明白,这个算法本质上就是MDS的从局部到整体的组合。
这里主要想重点强调一下,那个论文中使用的一个从局部几何到整体性质过渡的alignment技术。在spectral method(特征分解的)中,这个alignment方法特别有用。只要在数据的局部邻域上你的方法可以写成一个二次项的形式,就可以用。
其实LTSA最早的版本是在02年的DOCIS上。这个alignment方法在02年底Brand的 charting a manifold 中也出现,隐含在Hessian Eigenmaps中。在HE中,作者在从局部的Hessian矩阵过渡到全局的Hessian矩阵时,用了两层加号,其中就隐含了这个alignment方法。后来国内一个叫 ZHAO Deli 的学生用这个方法重新写了LLE,发在Pattern Recognition上,一个短文。可以预见的是,这个方法还会被发扬光大。
ZHA Hongyuan 后来专门作了一篇文章来分析 alignment matrix 的谱性质,有兴趣地可以找来看看。
f) MVU (Maximum variance unfolding)
这个方法刚发出来以后,名字叫做Semi-definite Embedding (SDE)。构建一个局部的稀疏欧式距离矩阵以后,作者通过一定约束条件(主要是保持距离)来学习到一个核矩阵,对这个核矩阵做PCA就得到保持距离的embedding,就这莫简单。但是就是这个方法得了多少奖,自己可以去找找看。个人观点认为,这个方法之所以被如此受人赏识,无论在vision还是在learning,除了给流形学习这一领域带来了一个新的解决问题的工具之外,还有两个重点,一是核方法(kernel),二是半正定规划(semi-definite programming),这两股风无论在哪个方向(learning and Vision)上都吹得正猛。
g) S-Logmaps
aa
这个方法不太被人所知,但是我认为这个是流形学习发展中的一个典型的方法(其实其他还有很多人也这莫认为)。就效果来说,这个方法不算好,说它是一个典型的方法,是因为这个方法应用了黎曼几何中一个很直观的性质。这个性质和法坐标(normal coordinate)、指数映射(exponential map)和距离函数(distance function)有关。
如果你了解黎曼几何,你会知道,对于流形上的一条测地线,如果给定初始点和初始点处测地线的切方向,那莫这个测地线就可以被唯一确定。这是因为在这些初始条件下,描述测地线的偏微分方程的解是唯一的。那末流形上的一条测地线就可以和其起点处的切平面上的点建立一个对应关系。我们可以在这个切平面上找到一点,这个点的方向就是这个测地线在起点处的切方向,其长度等于这个测地线上的长。这样的一个对应关系在局部上是一一对应的。那末这个在切平面上的对应点在切平面中就有一个坐标表示,这个表示就叫做测地线上对应点的法坐标表示(有的也叫指数坐标)。那末反过来,我们可以把切平面上的点映射到流形上,这个映射过程就叫做指数映射(Logmap就倒过来)。如果流形上每一个点都可以这样在同一个切平面上表示出来,那末我们就可以得到保持测地线长度的低维表示。如果这样做得到,流形必须可以被单坐标系统所覆盖。
如果给定流形上的采样点,如果要找到法坐标,我们需要知道两个东西,一是测地线距离,二是每个测地线在起点处的切方向。第一个东西好弄,利用Isomap中的方法直接就可以解决,关键是第二个。第二个作者利用了距离函数的梯度,这个梯度和那个切方向是一个等价的关系,一般的黎曼几何书中都有叙述。作者利用一个局部切坐标的二次泰勒展开来近似距离函数,而距离是知道的,就是测地线距离,局部切坐标也知道,那末通过求一个简单的最小二乘问题就可以估计出梯度方向。
如果明白这个方法的几何原理,你再去看那个方法的结果,你就会明白为什莫在距离中心点比较远的点的embedding都可以清楚地看到在一条条线上,效果不太好。
bb
最近这个思想被北大的一个年轻的老师 LIN Tong 发扬光大,就是ECCV‘06上的那篇,还有即将刊登出的TPAMI上的 Riemannian Manifold Learning,实为国内研究学者之荣幸。Lin的方法效果非常好,但是虽然取名叫Riemannian,没有应用到黎曼几何本身的性质,这样使他的方法更容易理解。
Lin也是以一个切空间为基准找法坐标,这个出发点和思想和Brun(S-Logmaps)的是一样的。但是Lin全是在局部上操作的,在得出切空间原点处局部邻域的法坐标以后,Lin采用逐步向外扩展的方法找到其他点的法坐标,在某一点处,保持此点到它邻域点的欧式距离和夹角,然后转化成一个最小二乘问题求出此点的法坐标,这样未知的利用已知的逐步向外扩展。说白了就像缝网一样,从几个临近的已知点开始,逐渐向外扩散的缝。效果好是必然的。
有人做了个好事情,做了个系统,把几个方法的matlab代码放在了一起http://www.math.umn.edu/~wittman/mani/
以上提到方法论文,都可以用文中给出的关键词借助google.com找到。
3. 基本问题和个人观点
流形学习现在还基本处于理论探讨阶段,在实际中难以施展拳脚,不过在图形学中除外。我就说说几个基本的问题。
a. 谱方法对噪声十分敏感。希望大家自己做做实验体会一下,流形学习中谱方法的脆弱。
b. 采样问题对结果的影响。
c. 收敛性
d. 一个最尴尬的事情莫过于,如果用来做识别,流形学习线性化的方法比原来非线性的方法效果要好得多,如果用原始方法做识别,那个效果叫一个差。也正因为此,使很多人对流形学习产生了怀疑。原因方方面面 : )
e. 把偏微分几何方法引入到流形学习中来是一个很有希望的方向。这样的工作在最近一年已经有出现的迹象。
f. 坦白说,我已不能见庐山真面目了,还是留给大家来说吧
结尾写得有点草率,实在是精疲力尽了,不过还好主体部分写完。
『以下是dodo在回帖中补充的内容:
看一些问到人脸识别有关的问题。由于此文结尾写得有点草,我这里再补充一下。
dodo
1)人脸识别的识别效果首先取决于 visual feature,图片中表示的模式和一般的向量模式还是有很大差别的。visual feature的好坏,决定了你所用的向量到底能不能代表这个图像中的模式和这个模式与其他模式的正确关系,如果能,那再谈降维识别的事情。
结构能保持,效果就好;不能保持,就很难说。
2)现在流形学习中的极大多数方法不收敛。正因为这样,在原始样本集中,如果增添少部分点,或是减少少部分点,或是扰动少部分点,都会对最后的nonlinear embedding产生影响。也就是说,极不稳定。
到现在为止,就 Laplacian Eigenmaps 有收敛性的证明。但是,这个被证明的结果的前提条件是啥,这个很重要。如果是均匀采样,那么基本对实际用处不大,理论上有引导作用。
3)采样的问题,包括采样密度和采样方式,都对最后结果有显著影响。而实际数据都是非常复杂的。
4)最后降到多少维的问题。这个对于流行学习来说,也是一个正在争论探讨的问题。
5)多流形的问题。现在的流形学习算法能处理的流形情况非常的弱,前提建设的条件非常的强,比如单坐标系统覆盖,与欧式空间的开子集等距等等。对于具有不同维数的多流形混合的问题,还没有人能解。而
这恰恰是模式识别中一个合理的情况!(具有不同维数的多流形混合的问题)
而4)5)后两者是紧紧联系在一起。
这几点也是流形学习能发挥其威力必须克服的问题。实际的情况并不是像一些人说的“流形学习已经做烂了”,问题在于
1)没有找到真正的问题在哪,
2)知道问题在哪儿,解决不了。
这就是流形学习目前的状况,如果你能用恰当的理论,而不是技巧和实验,解决了2)、5)其中一个问题,你就会是流形学习进入下一个黄金时期的功臣。
而现在的情况是,引导和开创流形学习进入第一个黄金时期和为这个黄金时期推波助澜的那第一拨人,大都不再为此而努力了。现在就M. Belkin还在第一线为2)问题而奋斗。
另外一个可喜的局面是,那些专职搞数值和几何的数学人开始涉足此领域,这必将带动流形学习这个方向深入发展,这也是这个方向发展的一个必然。
现在流形学习就处在这个懵懂的时期,就等着打开下一个局面的人出现,这需要机遇或者天才。但是从历史的角度来看,可以肯定的是,这样的人必定出现。流形学习很有可能会经历神经网络类似的发展历程,但是比神经网络更新的要快的多。
细数历史,可以看到机会。如果你对此有兴趣,什么时候加入都不晚。
- 局部线性嵌入(LLE)
- 等距映射(Isomap)
- 拉普拉斯特征映射(Laplacian Eigenmap)
局部线性嵌入(LLE)
前提假设:采样数据所在的低维流形在局部是线性的,即每个采样点可以用它的近邻点线性表示。
求解方法:特征值分解。
LLE算法:
- 计算每一个点Xi的近邻点,一般采用K近邻或者ξ领域。
- 计算权值Wij,使得把Xi用它的K个近邻点线性表示的误差最小,即通过最小化||Xi-WijXj||来求出Wij.
- 保持权值Wij不变,求Xi在低维空间的象Yi,使得低维重构误差最小。
多维尺度变换(MDS)
- MDS是一种非监督的维数约简方法。
- MDS的基本思想:约简后低维空间中任意两点间的距离应该与它们在原高维空间中的距离相同。
- MDS的求解:通过适当定义准则函数来体现在低维空间中对高维距离的重建误差,对准则函数用梯度下降法求解,对于某些特殊的距离可以推导出解析法。
等距映射(Isomap)
基本思想:建立在多维尺度变换(MDS)的基础上,力求保持数据点的内在几何性质,即保持两点间的测地距离。
前提假设:
- 高维数据所在的低维流形与欧氏空间的一个子集是整体等距的。
- 与数据所在的流形等距的欧氏空间的子集是一个凸集。
核心:
估计两点间的测地距离:
- 离得很近的点间的测地距离用欧氏距离代替。
- 离得较远的点间的测地距离用最短路径来逼近。
拉普拉斯特征映射(Laplacian Eigenmap)
基本思想:在高维空间中离得很近的点投影到低维空间中的象也应该离得很近。
求解方法:求解图拉普拉斯算子的广义特征值问题。
度量学习
转自http://blog.csdn.net/nehemiah_li/article/details/44230053
在数学中,一个度量(或距离函数)是一个定义集合中元素之间距离的函数。一个具有度量的集合被称为度量空间。
1 为什么要用度量学习?
很多的算法越来越依赖于在输入空间给定的好的度量。例如K-means、K近邻方法、SVM等算法需要给定好的度量来反映数据间存在的一些重要关系。这一问题在无监督的方法(如聚类)中尤为明显。举一个实际的例子,考虑图1的问题,假设我们需要计算这些图像之间的相似度(或距离,下同)(例如用于聚类或近邻分类)。面临的一个基本的问题是如何获取图像之间的相似度,例如如果我们的目标是识别人脸,那么就需要构建一个距离函数去强化合适的特征(如发色,脸型等);而如果我们的目标是识别姿势,那么就需要构建一个捕获姿势相似度的距离函数。为了处理各种各样的特征相似度,我们可以在特定的任务通过选择合适的特征并手动构建距离函数。然而这种方法会需要很大的人工投入,也可能对数据的改变非常不鲁棒。度量学习作为一个理想的替代,可以根据不同的任务来自主学习出针对某个特定任务的度量距离函数。
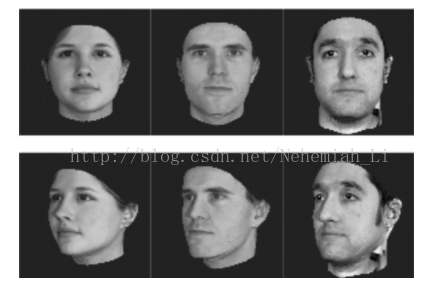
图 1
2 度量学习的方法
根据相关论文[2,3,4],度量学习方法可以分为通过线性变换的度量学习和度量学习的非线性模型。
2.1 通过线性变换的度量学习
由于线性度量学习具有简洁性和可扩展性(通过核方法可扩展为非线性度量方法),现今的研究重点放在了线性度量学习问题上。线性的度量学习问题也称为马氏度量学习问题,可以分为监督的和非监督的学习算法。
监督的马氏度量学习可以分为以下两种基本类型:
I 监督的全局度量学习:该类型的算法充分利用数据的标签信息。如
- Information-theoretic metric learning(ITML)
- Mahalanobis Metric Learning for Clustering([1]中的度量学习方法,有时也称为MMC)
- Maximally Collapsing Metric Learning (MCML)
II 监督的局部度量学习:该类型的算法同时考虑数据的标签信息和数据点之间的几何关系。如
- Neighbourhood Components Analysis (NCA)
- Large-Margin Nearest Neighbors (LMNN)
- Relevant Component Analysis(RCA)
- Local Linear Discriminative Analysis(Local LDA)
此外,一些很经典的非监督线性降维算法可以看作属于非监督的马氏度量学习。如
- 主成分分析(Pricipal Components Analysis, PCA)
- 多维尺度变换(Multi-dimensional Scaling, MDS)
- 非负矩阵分解(Non-negative Matrix Factorization,NMF)
- 独立成分分析(Independent components analysis, ICA)
- 邻域保持嵌入(Neighborhood Preserving Embedding,NPE)
- 局部保留投影(Locality Preserving Projections. LPP)
2.2 度量学习的非线性模型
非线性的度量学习更加的一般化,非线性降维算法可以看作属于非线性度量学习。经典的算法有等距映射(Isometric Mapping,ISOMAP) 、局部线性嵌入(Locally Linear Embedding, LLE) ,以及拉普拉斯特征映射(Laplacian Eigenmap,LE ) 等。另一个学习非线性映射的有效手段是通过核方法来对线性映射进行扩展。此外还有如下几个方面
- Non-Mahalanobis Local Distance Functions
- Mahalanobis Local Distance Functions
- Metric Learning with Neural Networks
3 应用
度量学习已应用于计算机视觉中的图像检索和分类、人脸识别、人类活动识别和姿势估计,文本分析和一些其他领域如音乐分析,自动化的项目调试,微阵列数据分析等[4]。
推荐阅读的论文
以下列举的论文大都对后来度量学习产生了很大影响(最高的google引用量上了5000次)。1-6篇论文是关于一些方法的论文,最后一篇为综述。
- Distance metric learning with application to clustering with side-information
- Information-theoretic metric learning(关于ITML)
- Distance metric learning for large margin nearest neighbor classification(关于LMNN)
- Learning the parts of objects by non-negative matrix factorization(Nature关于RCA的文章)
- Neighbourhood components analysis(关于NCA)
- Metric Learning by Collapsing Classes(关于MCML)
- Distance metric learning a comprehensive survey(一篇经典的综述)
相关博客:
http://blog.pluskid.org/?p=533
http://www.docin.com/p-272409018.html
https://en.wikipedia.org/wiki/Metric_(mathematics)
http://www.cs.cmu.edu/~liuy/distlearn.htm
最后
以上就是纯情咖啡豆最近收集整理的关于维度学习、度量学习 一.先说特征选择,即子集选择。 二. 主成分分析(PCA) 三.FA 四.ICA 六.线性判别分析(LDA) 七.局部线性嵌入LLE 八.等距特征映射 九.小波变换 推荐阅读的论文的全部内容,更多相关维度学习、度量学习内容请搜索靠谱客的其他文章。








发表评论 取消回复