@Lecture 11: Linear Models for Classifification
从之前学过的模型出发,看一下这些模型怎么来做复杂的分类问题
Linear Models for Binary Classifification
回顾一下线性模型都使用到了线性得分函数s =wx
三种模型的总结分析:如果他们之间和相似的话,那能不能用回归模型来帮助线性分类(因为linear classification不好解)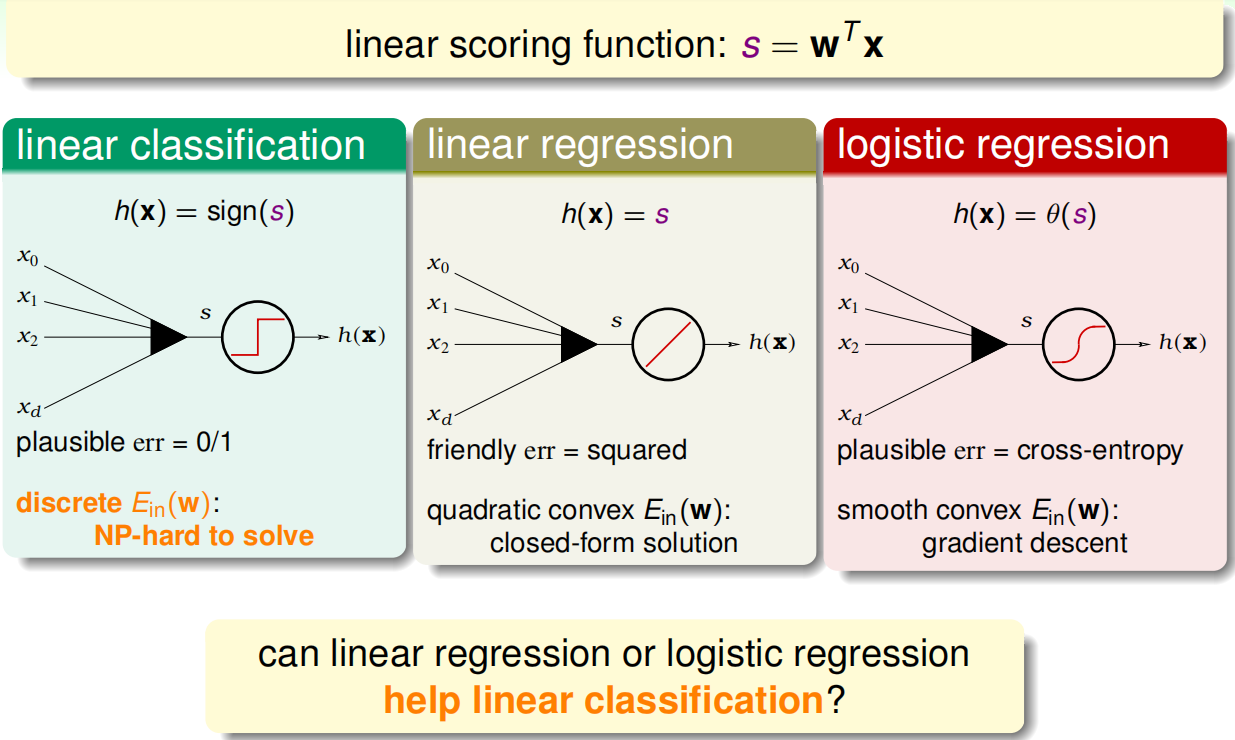
分析其Error function 统一用ys表达,得到每个err function都与ys有关,ys的物理意义为估计值和实际值之间的相似度,应该越大越好:
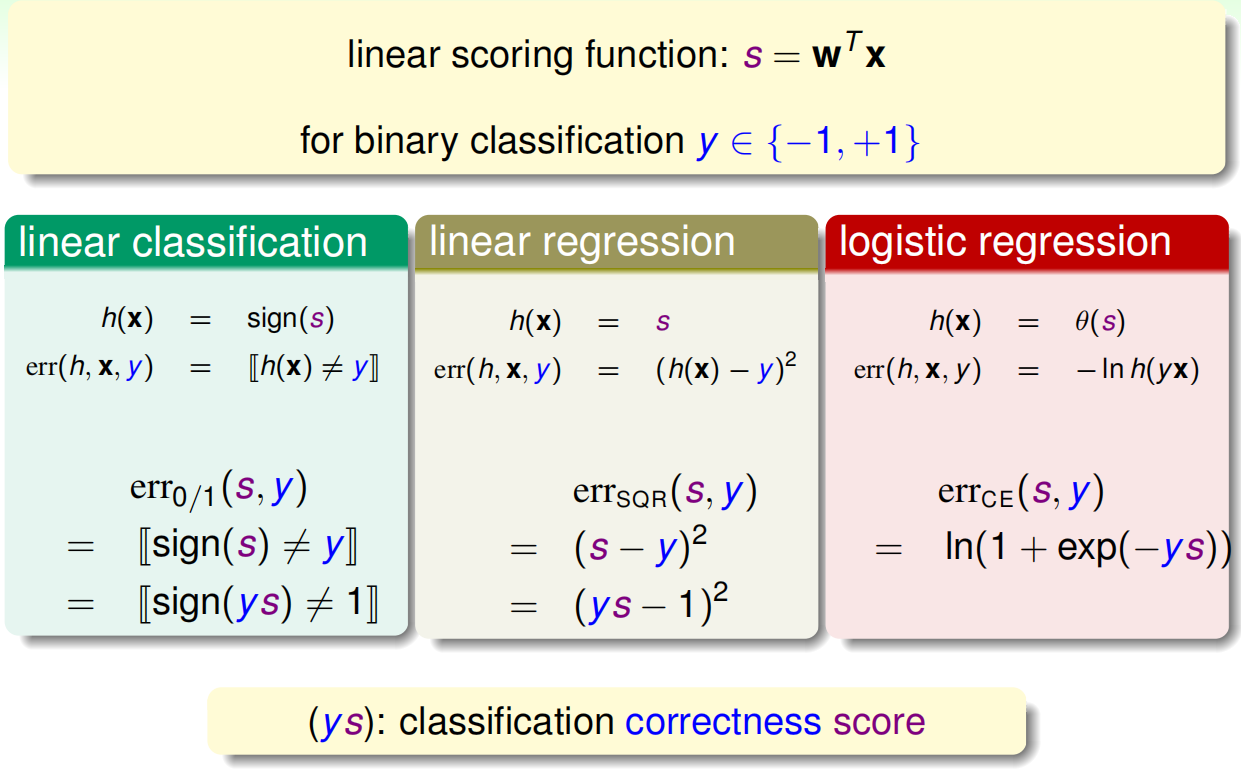
分析linear regression、logistic regression和linear classfication的err function:
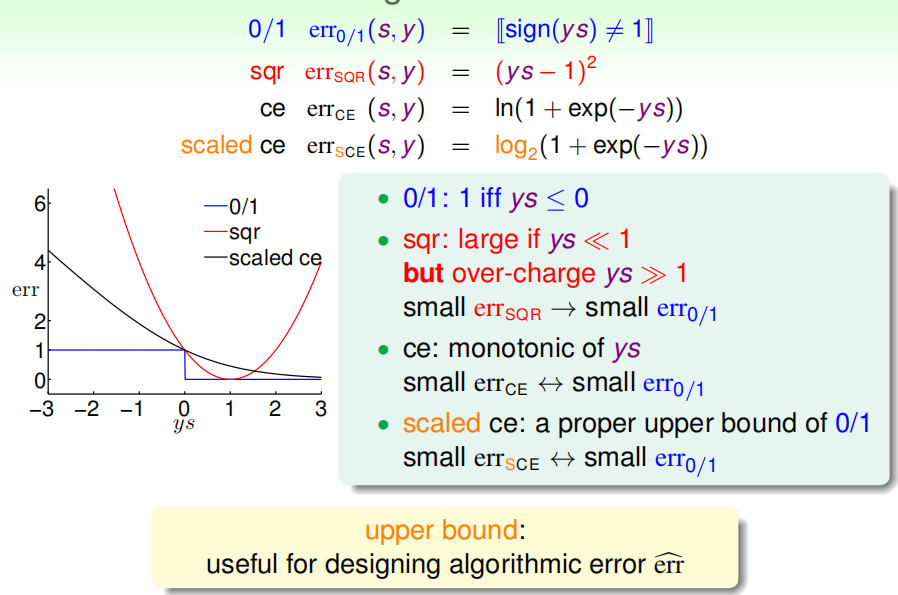 得到0/1的Err是小于逻辑斯蒂回归的Err的,且通过VC bound可以证明如果Ein比较小,Eout也会比较小
得到0/1的Err是小于逻辑斯蒂回归的Err的,且通过VC bound可以证明如果Ein比较小,Eout也会比较小

因此一般有两个方法来在分类问题中使用回归算法:
一、使用线性回归得到的w作为PLA或者pocket/logistic regressiond的初始值
二、使用logistic regression来代替pocket算法

Stochastic Gradient Descent
本节讲随机梯度下降
上章讲可以用逻辑斯蒂回归进行二分类问题,并用梯度下降的算法求解。
但是PLA算法每次更新w只用找一个点,看他是否是正确还是错误的,每次更新的算法复杂度为O(1)
但逻辑斯蒂回归每更新一次w需要便利样本中所有点,计算Err,每次更新算法的复杂度为O(N)
所以逻辑斯蒂回归的权重更新的会比较慢
引入随机梯度算法:
从样本中随机选一个点出来,计算这个点的Err的梯度来当作总体的Err的梯度

SGD logistic regression可以看作soft PLA:
 一个有用的小技巧:η=0.1或者0.1126(经验)
一个有用的小技巧:η=0.1或者0.1126(经验)
Multiclass via Logistic Regression
本节讲使用逻辑斯蒂回归进行多分类问题。
多分类问题:思路:one class at a time:每次都只把一个类别从里面分出去
但是会遇到一个问题:有的区域(重叠部分)分类器都想要,有的区域(中间没被分到的地方)都不想要
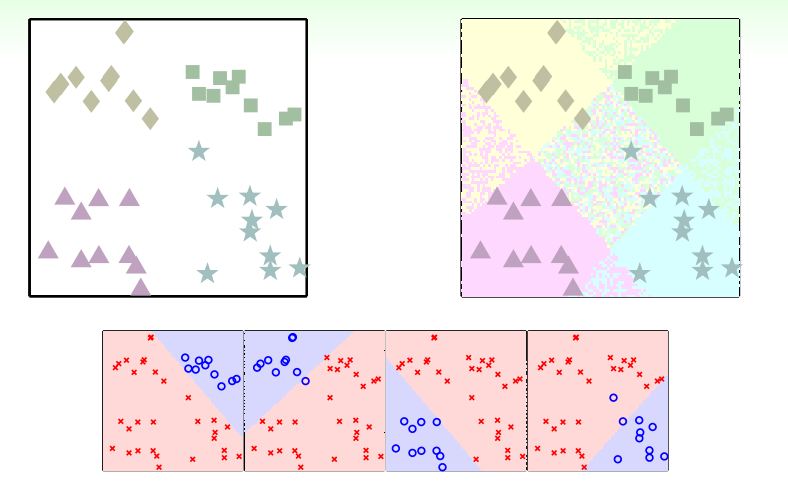 因此,转换为soft分类,将是否落在该区域换成某个分类落在该区域的概率:
因此,转换为soft分类,将是否落在该区域换成某个分类落在该区域的概率:
OVA算法流程图:

留下一个问题:这样的训练方式会导致当分类数较多时,会导致样本不均匀,负样本会比较多
Multiclass via Binary Classifification
解决OVA算法训练时的样本不均匀问题:
每次在两个类别的数据上面运行二分类算法(one vs one):需要运行CK2次,例如有4个分类
需要运行6次二分类算法:让得到的六个分类器投票,投票得到最后的分类
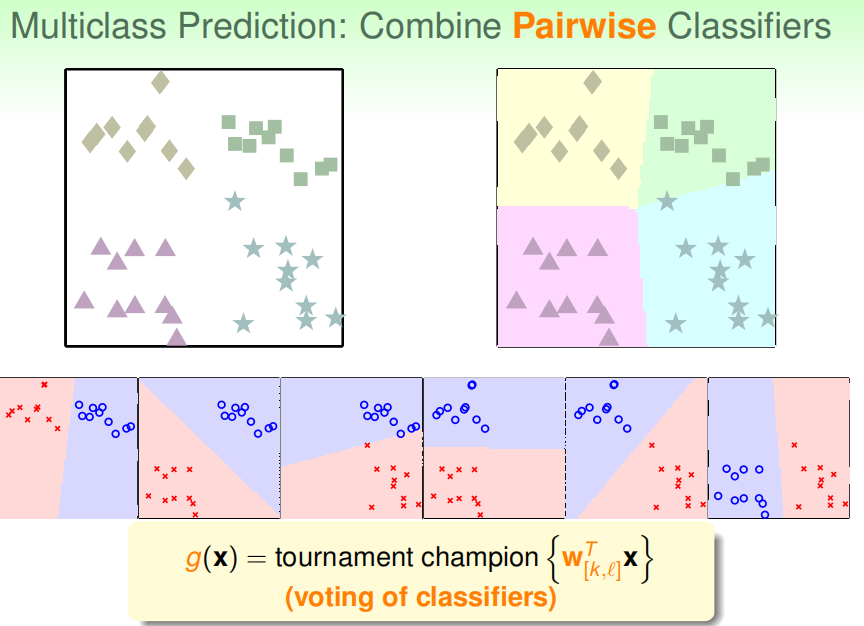
OVO算法:优点:效率高稳定,缺点:算法复杂度高

最后
以上就是苗条唇膏最近收集整理的关于林轩田机器学习基石Lecture 11: Linear Models for Classification的全部内容,更多相关林轩田机器学习基石Lecture内容请搜索靠谱客的其他文章。








发表评论 取消回复