Python实践笔记 - 2、从网站上爬取公开信息
张板书的Python的实践笔记,包括笔记与DeBug的经历。
为了完成一个比较麻烦的实习任务,尝试着做了这样一个爬虫项目。
任务要求之一是要检索安徽省应急管理厅的政务公开中,记录下所有的发放了危险化学品安全许可证的企业名称,但是检索后可以看到安徽省的信息是按周发布,那么如果要拿到所有的企业名称,就需要打开50+个网页,比较麻烦,故希望设计一个爬虫来解决。
http://yjt.ah.gov.cn/public/column/9377745?type=4&action=list&nav=3&catId=49550951
目录
- Python实践笔记 - 2、从网站上爬取公开信息
- 一、单个网页的信息获取
- 获取 xpath 来定位信息
- 二、获取所有的url
- 1、通过 post 请求获取信息
- 2、翻页 url 不变的爬虫
一、单个网页的信息获取
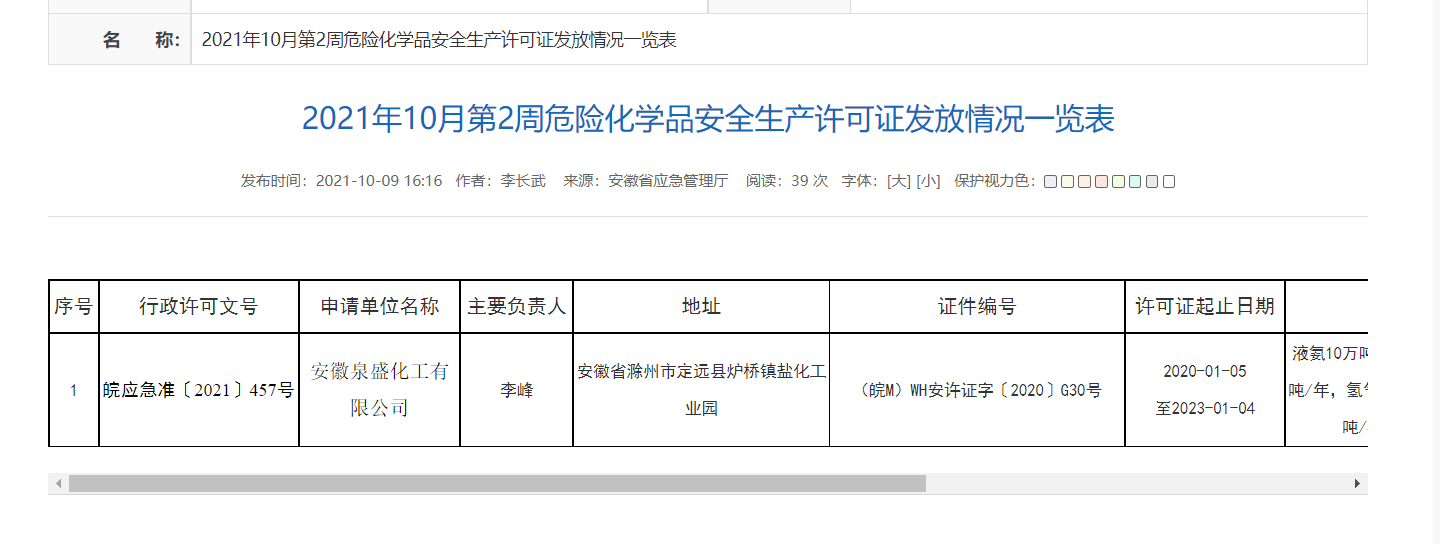
我们打开其中几个网页,可以看到格式都很规整,均是以一个表格的形式来进行信息的展示:
http://yjt.ah.gov.cn/public/9377745/146123891.html
http://yjt.ah.gov.cn/public/9377745/146123631.html
获取 xpath 来定位信息
使用谷歌浏览器或Edge浏览器的开发者工具( F12 或 Fn + F12 )
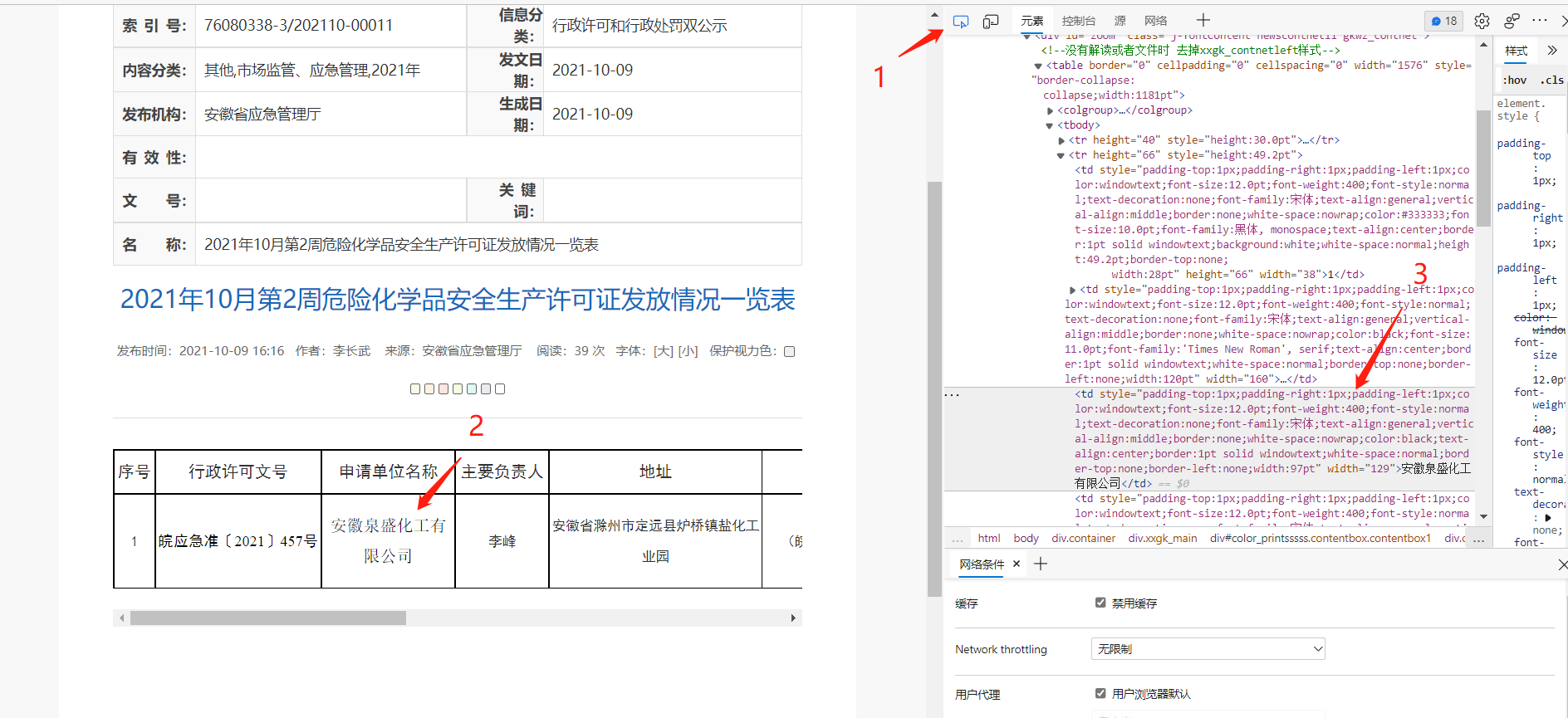
- 1、选择 元素检索 工具;
- 2、 光标放到需要的元素上;
- 3、需要的元素会显示在右侧;
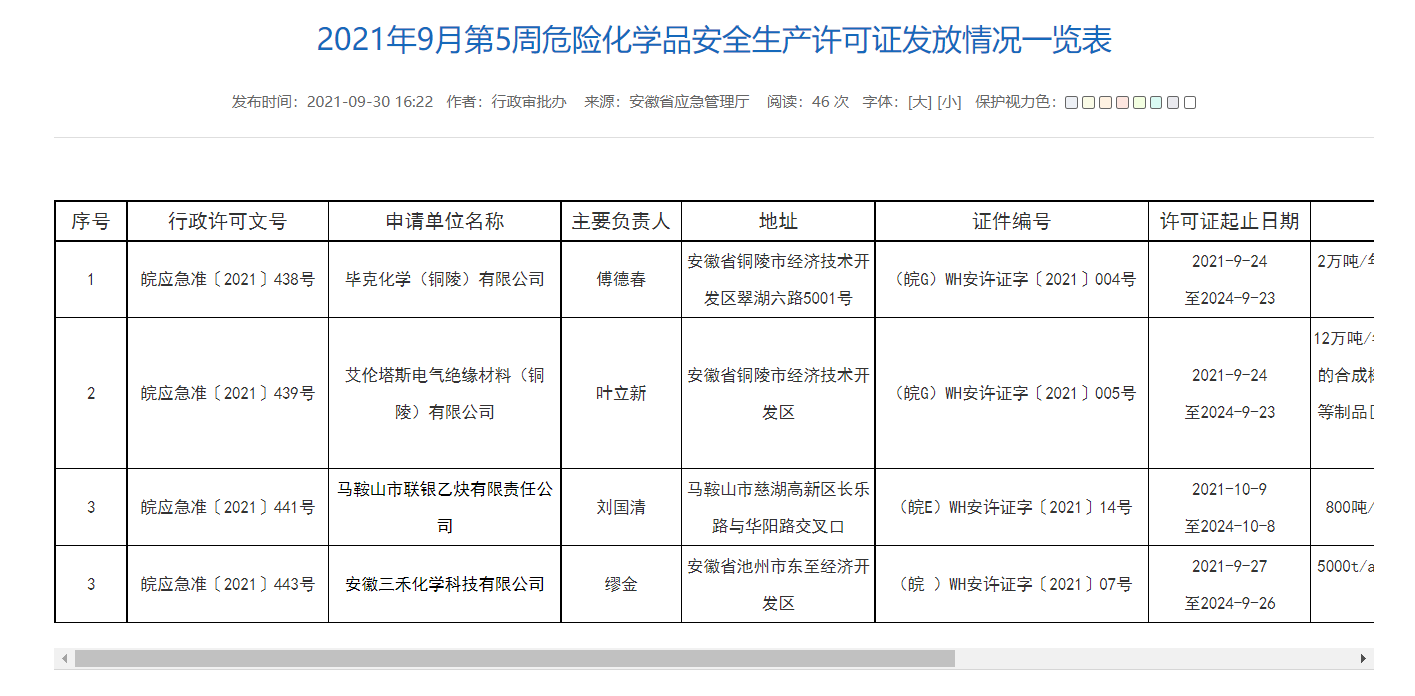
找另一个不止有一行表格的文件,用元素检索工具看表格中每一行的 Xpath :
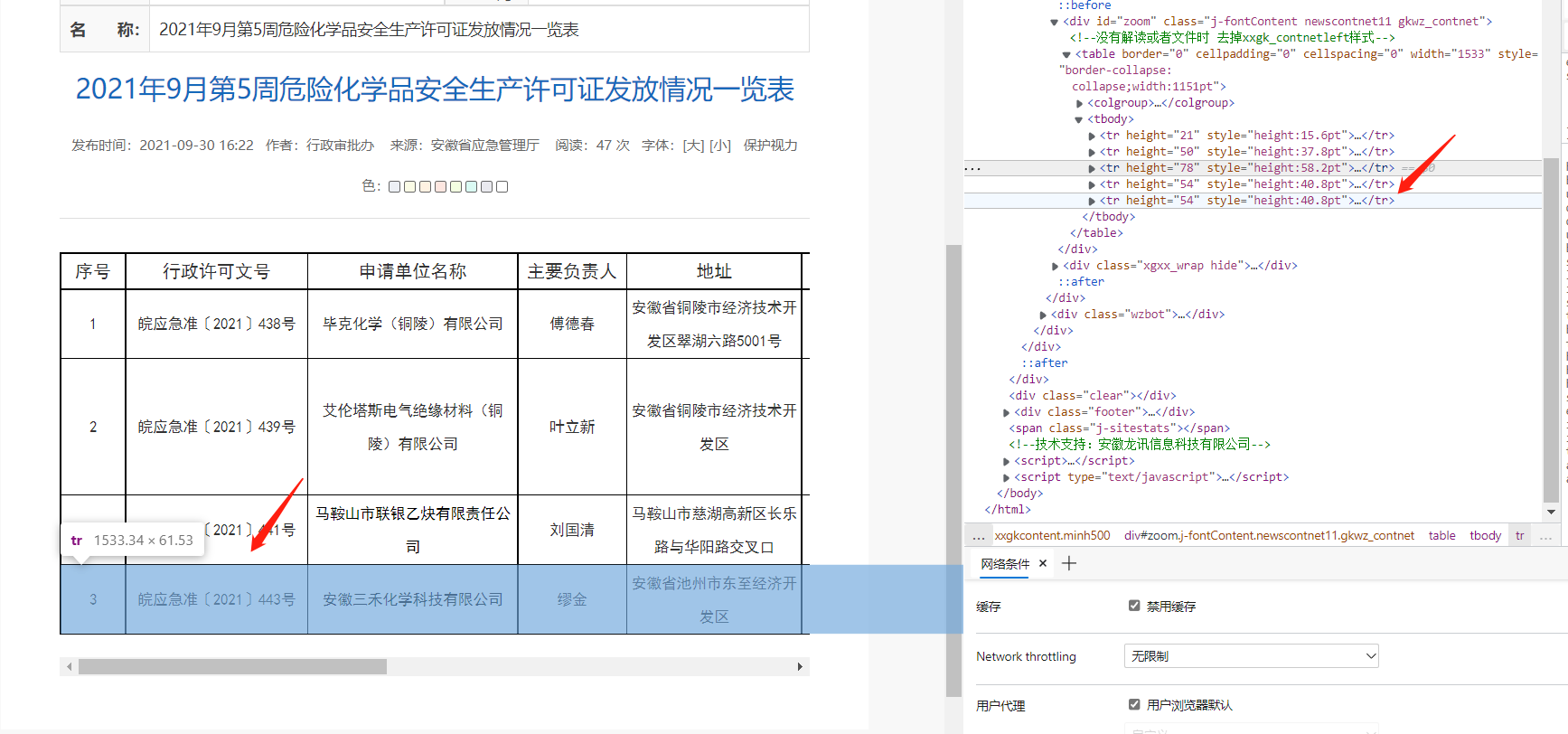
如此在程序中可以用循环来遍历每一行的信息
- 右键 — 复制 — 复制 xpath
在这里我们复制表格上一级的 xpath,即 tbody 那一项,xpath为:
//*[@id=“zoom”]/table/tbody
在 python 中创建一个函数来爬取此界面中的所有公司名称:
import requests
import json
from lxml import etree
def paqu_AH(url): # 根据 url 爬取表格中的公司名称
headers = {'referer':'http://yjt.hubei.gov.cn/fbjd/xxgkml/xkfw/xzxkgs/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
html = requests.get(url, headers=headers).content
xml = etree.HTML(html)
factorys = []
xpath = '//*[@id="zoom"]/table/tbody'
content = xml.xpath(xpath) # 用 xpath 解析 get 到的网页信息
for tbody in content[0][1:]: # 具体信息可以打印出来看,或者用 vscode debug时的元素检测查看;
# 同时 [1:] 表示除了第一行(因为第一行是表格的表头
factorys.append(tbody[2].text) # [2]表示第二列,主要看网页结构
return factorys
AH_0 = "http://yjt.ah.gov.cn/public/9377745/146080571.html"
print(paqu_AH(AH_0))
>>>['安徽兴欣新材料有限公司', '铜陵华兴精细化工有限公司', '淮北绿洲新材料有限责任公司', '马鞍山神剑新材料有限公司', '安徽禹泰化工有限公司']
二、获取所有的url
1、通过 post 请求获取信息
如上文所说,单纯爬取一个表格的网页很简单,但是我们要爬取的是所有的信息,那么也就需要爬取所有的此类网页的 url
我们观察这个网页,发现公示危化品许可证网页关键词的有相同的格式:
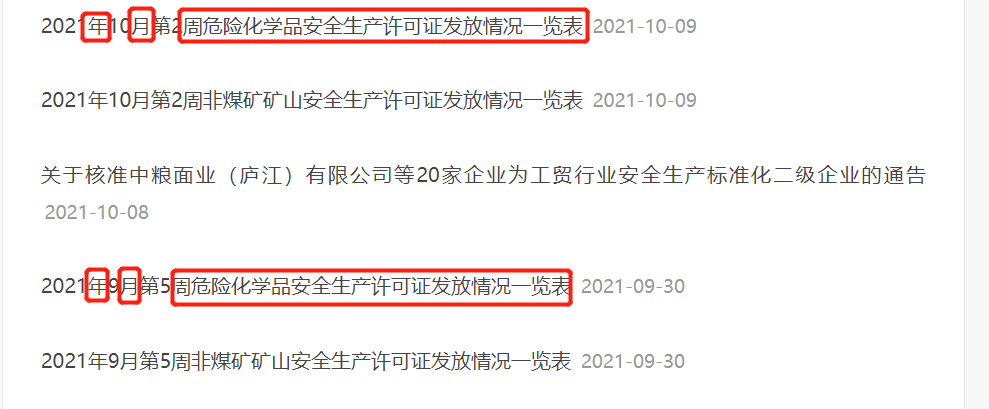
故我们在这个网页上面的搜索中检索这些关键词:
年 月 周危险化学品安全生产许可证发放情况一览表
可以看到符合我们的猜测:
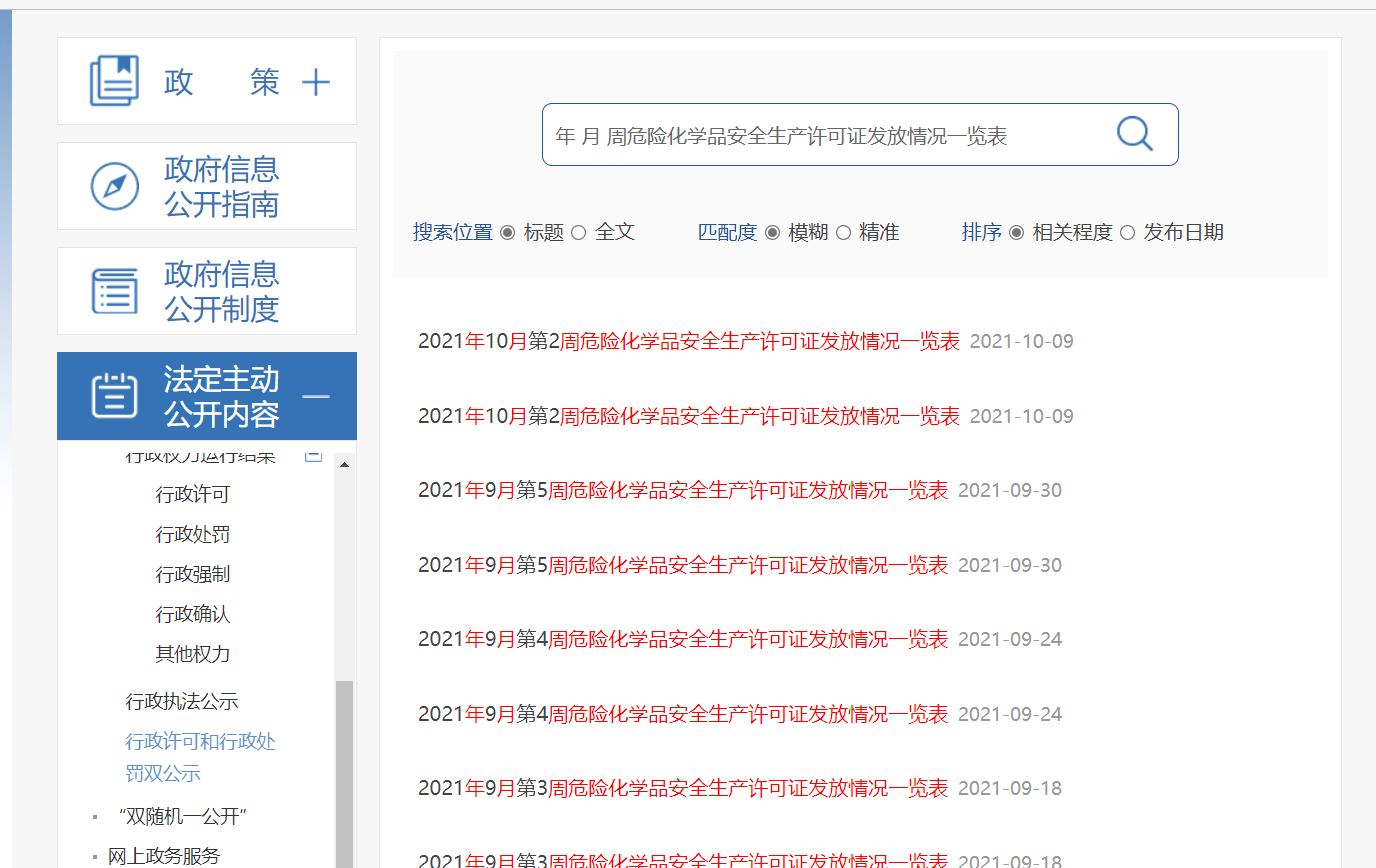
同样使用开发者工具获取 xpath,这样就可以使用程序爬取当页的内容了
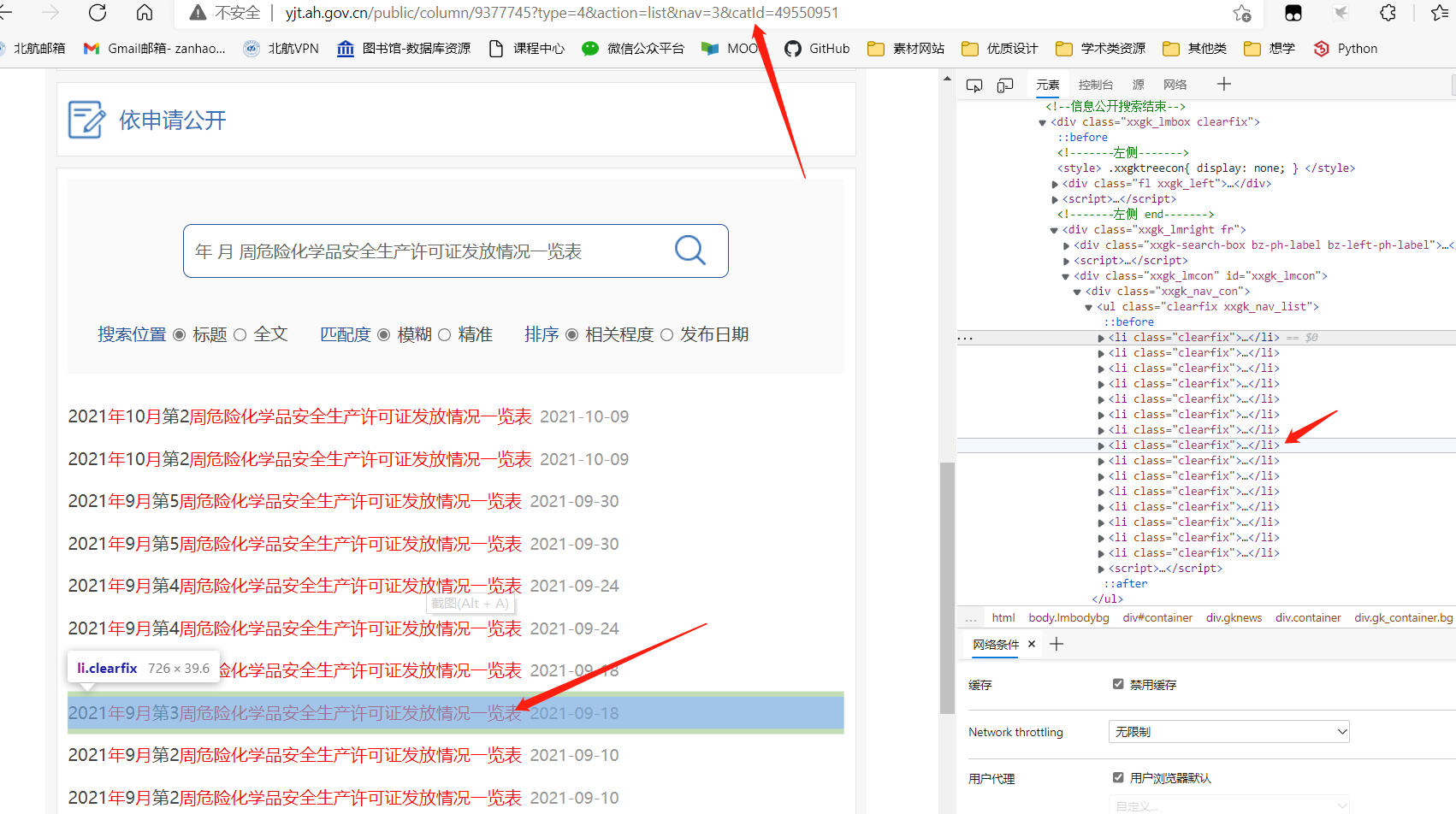
而这次由于不是直接在本界面进行的爬取,使用的请求不是 get,而是使用了 post 请求:
import requests
import json
from lxml import etree
def paqu_URL(url,data): # 子函数,爬取 url 的应用层
URLS = []
num = 0
headers = {'referer':'http://yjt.hubei.gov.cn/fbjd/xxgkml/xkfw/xzxkgs/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
html = requests.post(url, headers=headers, data=data).content
xml = etree.HTML(html)
xpath = '//*[@id="xxgk_lmcon"]/div[1]/ul'
txt = xml.xpath(xpath)
for ul in txt:
for li in ul[:-1]:
content = li[0]
dic = content.attrib
URLS.append(dic['href'])
num += 1
print("-- {} -- ".format(num),dic['href'])
AH = "http://yjt.ah.gov.cn/public/column/9377745?type=4&action=list&nav=3&catId=49550951"
data = "年 月 周危险化学品安全生产许可证发放情况一览表".encode("utf-8") # 这里要加上编码方式,否则会报错
paqu_URL(AH,data)
>>>-- 1 -- http://yjt.ah.gov.cn/public/9377745/146126481.html
>>>-- 2 -- http://yjt.ah.gov.cn/public/9377745/146123891.html
>>>-- 3 -- http://yjt.ah.gov.cn/public/9377745/146123631.html
>>>-- 4 -- http://yjt.ah.gov.cn/public/9377745/146120821.html
>>>-- 5 -- http://yjt.ah.gov.cn/public/9377745/146115731.html
>>>-- 6 -- http://yjt.ah.gov.cn/public/9377745/146115701.html
>>>-- 7 -- http://yjt.ah.gov.cn/public/9377745/146115601.html
>>>-- 8 -- http://yjt.ah.gov.cn/public/9377745/146115461.html
>>>-- 9 -- http://yjt.ah.gov.cn/public/9377745/146101311.html
>>>-- 10 -- http://yjt.ah.gov.cn/public/9377745/146101251.html
>>>-- 11 -- http://yjt.ah.gov.cn/public/9377745/146101261.html
>>>-- 12 -- http://yjt.ah.gov.cn/public/9377745/146094421.html
>>>-- 13 -- http://yjt.ah.gov.cn/public/9377745/146094401.html
>>>-- 14 -- http://yjt.ah.gov.cn/public/9377745/146080931.html
>>>-- 15 -- http://yjt.ah.gov.cn/public/9377745/146080571.html
但是由于不是以一页全部显示检索内容的,而且观察本页的 url,发现 url 中没有检索的关键词“年 月 周危险化学品安全生产许可证发放情况一览表”,而且翻页之后在 url 上没有体现,这样就无法直接在 url 上变化来实现翻页。
2、翻页 url 不变的爬虫
使用开发者工具监测网页动作:
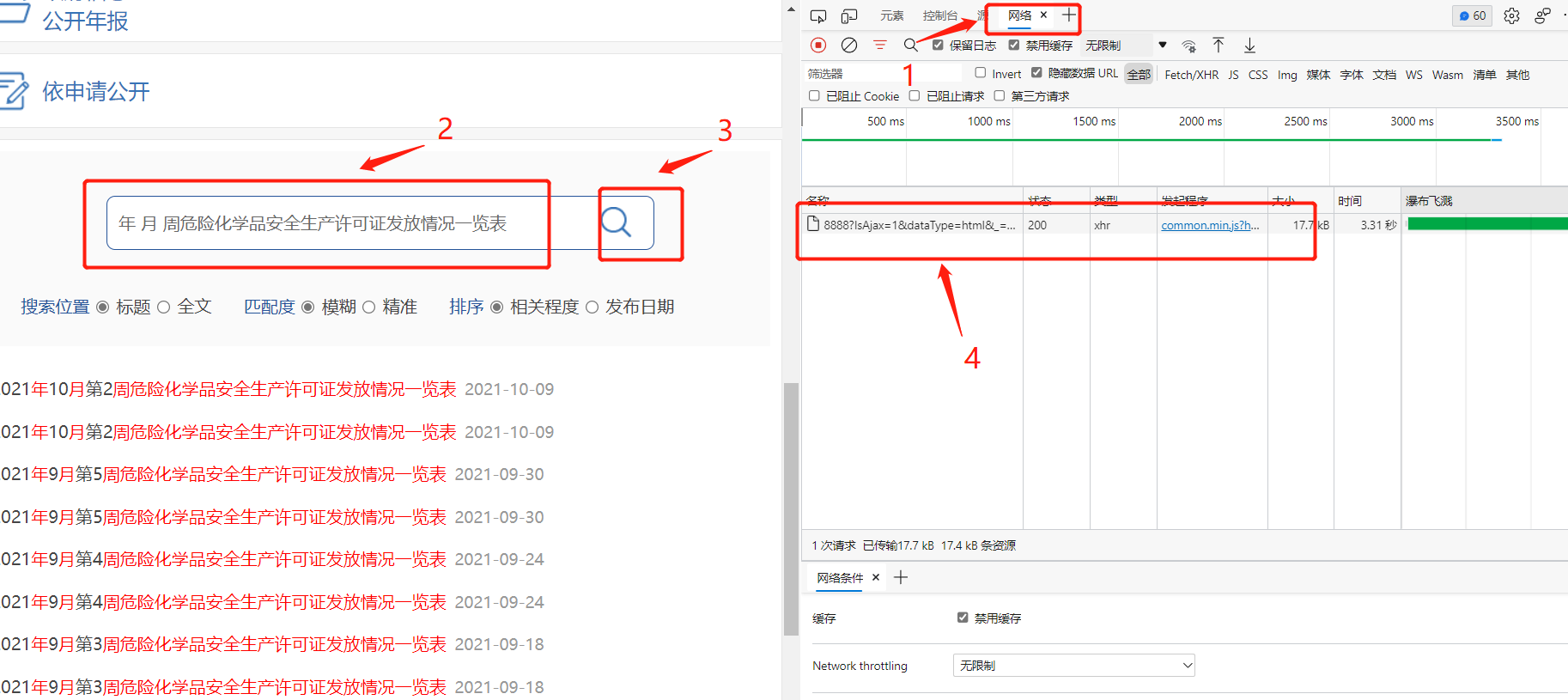
- 1、打开开发者工具中的 网络;
- 2、在检索框中输入检索内容;
- 3、点击检索;
- 4、发现网页有发送的信息与相关的响应;
点进去这个响应,可以看到他的响应内容预览确实是检索结果:
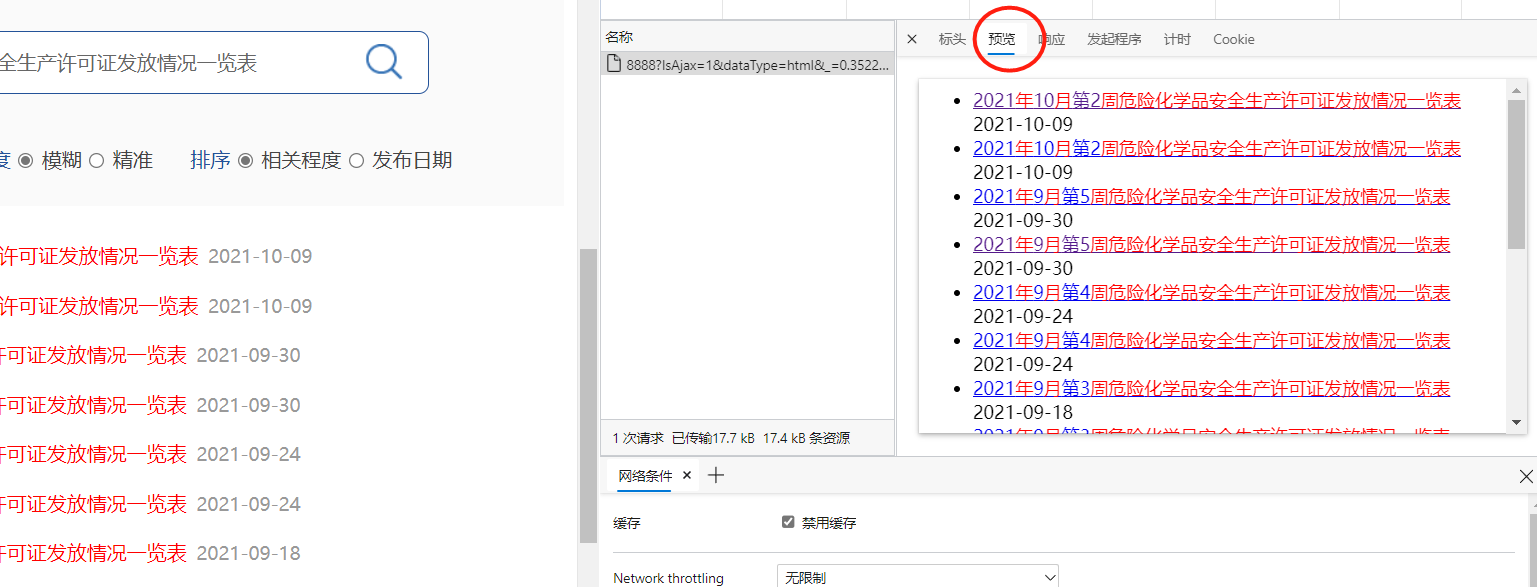
点进表头中去,观察发送的信息,并根据表头名称猜测参数意义:
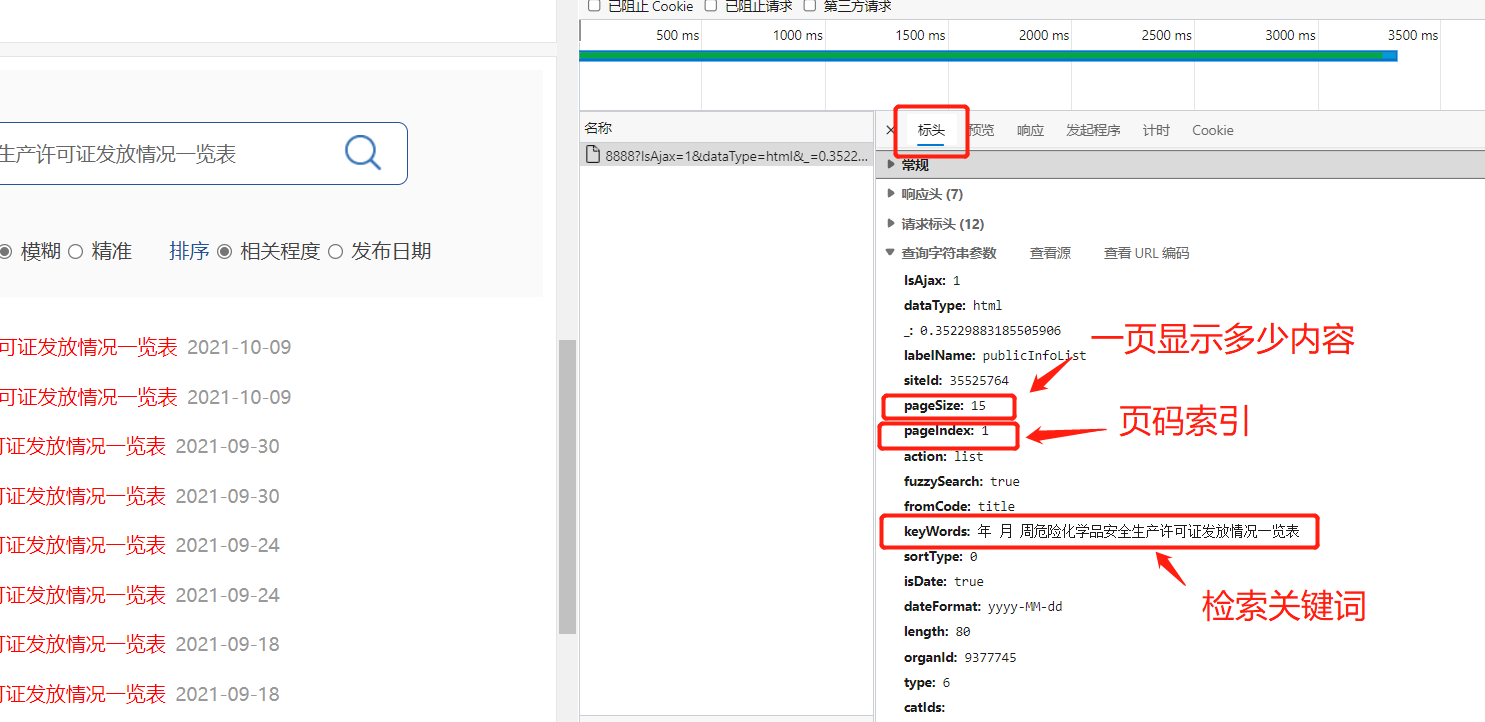
分析可得,可是试用 post 请求,而请求的信息发送这里的表头文件,并更改相应参数就可以实现翻页或其他功能:
import requests
import json
from lxml import etree
def get_all_url(num): # 爬取所有公式url
i = 1
url_list = []
for i in range(num):
print("#####第 {} 组###########################".format(i))
request_dic = {
'IsAjax': 1,
'dataType': 'html',
'_': '0.9035590852646269',
'labelName': 'publicInfoList',
'siteId': 35525764,
'pageSize': 15,
'pageIndex': i, # 每次更改页码索引
'action': 'list',
'fuzzySearch': 'true',
'fromCode': 'title',
'keyWords': '年月第周危险化学品安全生产许可证发放情况一览表',
'sortType': 0,
'isDate': 'true',
'dateFormat': 'yyyy-MM-dd',
'length': 80,
'organId': 9377745,
'type': 6,
'catIds': '',
'cId': '',
'result': '暂无相关信息',
'file': '/xxgk/publicInfoList_newest2020',}
i += 1
urls,num = paqu_URL(AH,request_dic)
url_list += urls
# try:
# urls,num = paqu_URL(AH,request_dic)
# url_list += urls
# except:
# print("-#-#-#- 爬取第 {} 页出现错误 -#-#-#-".format(i))
print("爬取完成,共 {} 个 URL".format(len(url_list)))
return url_list
def paqu_URL(url,data): # 这里更改了data的发送与读取模式
URLS = []
num = 0
headers = {'referer':'http://yjt.hubei.gov.cn/fbjd/xxgkml/xkfw/xzxkgs/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
# html = requests.get(url, headers=headers).content
html = requests.post(url, headers=headers, data = json.dumps(data)).content
xml = etree.HTML(html)
xpath = '//*[@id="xxgk_lmcon"]/div[1]/ul'
txt = xml.xpath(xpath)
for ul in txt:
for li in ul[:-1]:
content = li[0]
dic = content.attrib
URLS.append(dic['href'])
num += 1
# print("-- {} -- ".format(num),dic['href'])
return URLS, num
get_all_url(5) # 爬取50页
>>>#####第 0 组###########################
>>>#####第 1 组###########################
>>>#####第 2 组###########################
>>>#####第 3 组###########################
>>>#####第 4 组###########################
爬取完成,共 75 个 URL
最后将这几个函数结合在一起就可以完整地爬取这些公司的名称啦
def get_factorys(num):
factorys = []
urls = get_all_url(num)
for url in urls:
try:
for factory in paqu_AH(url):
if factory not in factorys:
factorys.append(factory)
except:
factorys = factorys
print(factorys)
print("-#-#- 爬取结束,共爬取得个 {} 公司 -#-#-".format(len(factorys)))
return factorys
>>>爬取完成,共 75 个 URL
>>>['安徽泉盛化工有限公司', '金寨华润生态农业发展有限公司', '安徽天诚石业有限公司', '安徽马钢矿业资源集团有限公司姑山矿业有限公司和睦山铁矿', '毕克化学(铜陵)有限公司', '艾伦塔斯电气绝缘材料(铜陵)有限公司', '马鞍山市联银乙炔有限责任公司', '安徽三禾化学科技有限公司', '安徽省霍邱县张家夏楼铁矿', '安徽省枞阳县恒源矿业有限责任公司佘家凹铜金矿', '安徽马钢矿业资源集团南山矿业有限公司和尚桥铁矿', '安徽马钢矿业资源集团南山矿业有限公司高村铁矿', '安徽马钢矿业资源集团南山矿业有限公司城门峒尾矿库', '安徽马钢矿业资源集团南山矿业有限公司凹山总尾矿库', '安徽省舒城县新街萤石矿业有限公司', '金丰矿业(安徽)有限公司', '广德晶宇矿业有限公司大梅岭矿区 方解石矿', '安徽金日晟矿业有限责任公司', '泾县银山岭矿业有限公司', '铜陵市虎山磁铁矿有限责任公司', '繁昌县前山矿业有限责任公司', '池州市泰鼎矿业开发有限责任公司 贵池区棠溪乡鸡头山大理岩矿', '池州市桃坡鑫隆矿业开发有限公司尾矿库', '安徽九华金峰矿业股份有限公司池州市来龙山白云石矿', '凤阳县灵山-木屐山矿区玻璃用石英岩矿15号段', '安徽三力矿业有限责任公司灵山石英岩矿', '潜山天柱红石业有限公司官庄镇坛畈村菜坪花岗石矿', '安徽中淮矿业新型建材有限公司', '铜陵茅迪矿业有限公司石灰石矿一矿', '安徽舜泰天成爆破工程有限公司', '马鞍山马钢林德气体有限责任公司', '广德美涂士化工有限公司', '广德来威漆业有限公司', '铜陵化工集团有机化工有限责任公司', '安徽佳田森农药化工有限公司', '安徽久易农业股份有限公司', '池州市六合华丰石子有限公司', '安徽兴欣新材料有限公司', '铜陵华兴精细化工有限公司', '淮北绿洲新材料有限责任公司', '马鞍山神剑新材料有限公司', '安徽禹泰化工有限公司']
>>>-#-#- 爬取结束,共爬取得个 42 公司 -#-#-
最后自白一下,在我爬取的时候可能由于单位时间访问量过大,导致安徽省应急管理厅政务公开的检索部分 “小崩” 了一段时间,大家如果要尝试,尽可能用其他的网站,特别是大厂的、新的网站,他们的带宽比较大,否则惹祸呀呀呀呀呀呀
ah ~ _ ~
最后
以上就是干净铅笔最近收集整理的关于Python实践 - 网络爬虫笔记 - 2、从网站上爬取公开信息Python实践笔记 - 2、从网站上爬取公开信息的全部内容,更多相关Python实践内容请搜索靠谱客的其他文章。








发表评论 取消回复