人生苦短,我用python。
Python之爽,莫过爬虫。
建筑标准真是多如六毛,住建部网站公开发布的就有近千条。还好住建部将各类标准进行了公开发布,可免费下载。要是手工全部下载,也太lowB了,也是对自己的耐性是个极大的考验,光干这个枯燥的事怕是也要个三五天。
我会python我怕谁,写个爬虫半天全撸完,看着自动下载的上千的标准文件,想想都暗爽,说干就干。
一、网站分析
1.进入住建部官网http://www.mohurd.gov.cn/,进入标准定额,再进标准发布公告,记下网址http://www.mohurd.gov.cn/bzde/bzfbgg/index.html,这个就是我们要爬取的第一个页面内容。可以看到,公布的标准共有50页,每页有20条标准。点击下一页,网址变成http://www.mohurd.gov.cn/bzde/bzfbgg/index_2.html,你会发现每一页的链接地址就是在首页的地址后面加上’_n’,找到地址规律就为自动爬取奠定基础了。
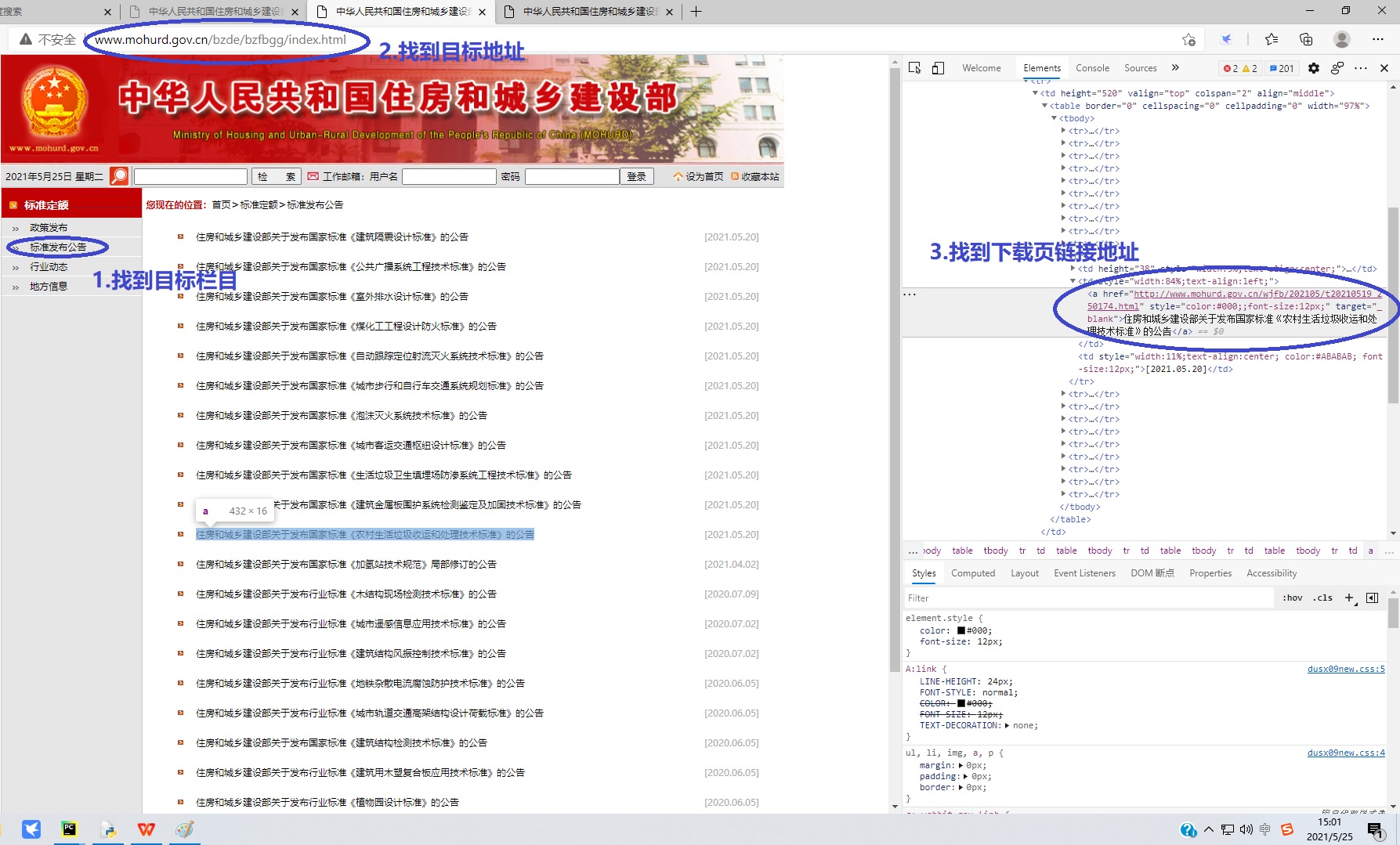
2.然后随便找一页网页进行结构分析,要从中提取出下载链接的页面。在网页上点击鼠标右键,选择“检查”就可以看到网页的结构了,找到我们要提取的目标链接地址,分析一下是否存在规律。在这里不得不吐槽一下,这个网页结构写的,太无语了,所有节点属性连一个class属性都没有,整个网页也没一点CSS样式,这个水平就能交差,看来政府的钱真是好赚啊。因为网页毫无章法,给内容提取确实带来了一点困扰,不过总算找到一点规律,每个a标签里都有个target=_blank的属性,总算是可以进行简单提取了。这里也有坑,将在程序中注明。
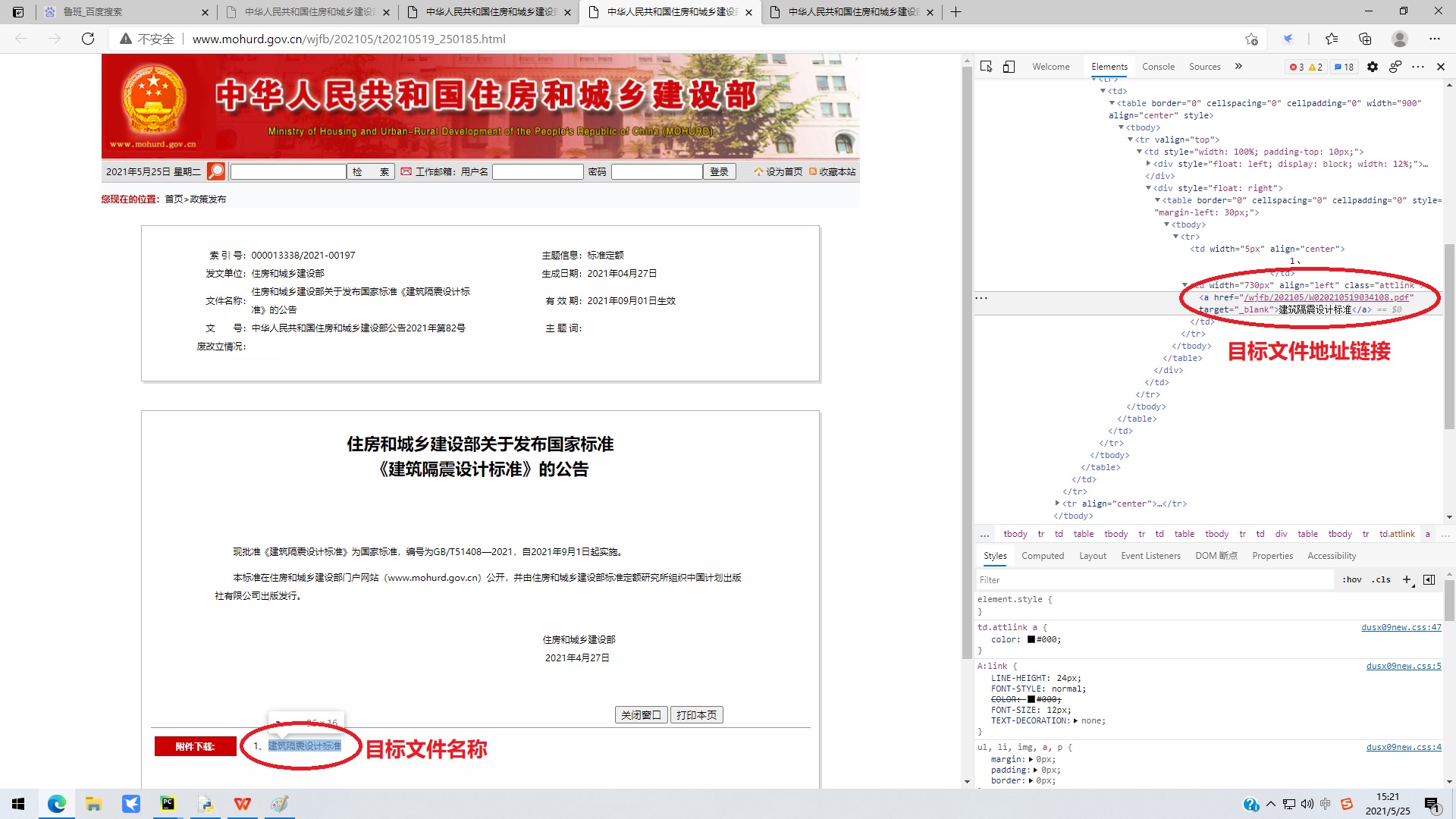
3.点击进入下载页面,进一步分析下载页面的网页结构。通过网页检查查看网页html结构,好歹这个页面的a标签的上一级有一个class=”attlink”的属性,这个提取下载链接就轻松多了,通过程序提取下载链接和文件名,就可以自动下载和保存文件了。这里也有坑,你会发现下载链接的写法根本不一致。
二、python程序实现
1.环境准备
IDE:pycharm
发送请求:requests模块
网页解析:beautifulsoup, re模块
2.获取网页html
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
}
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
html = response.text
return html
3.获取总页数
def get_total_page(url):
html = get_html(url)
total_page = re.findall('共(d*?)页', html)[0]
return int(total_page)
4.获取单页下载页链接
def get_links(url):
links = []
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
select_result = soup.find_all('a', attrs={"target":"_blank"})
result = select_result[:-2]
for item in result:
links.append(item['href'])
return links
5.获取所有下载页链接
def get_all_links(total_page):
all_links = []
for i in range(total_page):
if i == 0:
url = url_base + '.html'
else:
url = url_base + '_' + str(i + 1) + '.html'
links = get_links(url)
all_links = all_links + links
print('正在获取第{}页链接...'.format(i+1))
return all_links
6.获取下载文件地址和文件名
def get_file_link(links):
file_links = []
i = 0
for link in links:
i+=1
print('正在获取第%d个标准下载链接...'%(i))
print(link)
html = get_html(link)
soup = BeautifulSoup(html, 'html.parser')
select_result = soup.select('.attlink > a')
if len(select_result)>0:
result = select_result[0]
link_temp = result['href']
if re.search('download', link_temp):
file_link = link_temp
else:
file_link = 'http://www.mohurd.gov.cn' + link_temp
file_name = result.text + '.pdf'
file_links.append([file_link, file_name])
time.sleep(0.5)
return file_links
7.下载和保存文件
def save_file(file_links):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
}
i = 0
for link in file_links:
i += 1
print('正在下载第%d个标准...'%(i))
response = requests.get(link[0], headers=headers)
file_content = response.content
f = open(link[1], 'wb')
f.write(file_content)
time.sleep(0.5)
三、避坑与小结
1.用target=_blank属性提取下载页面地址时,会有网站底部信息链接一同被提取出来,要进行二次筛选。
2.提取到的文件下载地址,有的是相对地址,这时需要进行补全,有的是绝对地址,这时直接保存即可。
3.有些公告下面没有附下载文件,是提取不到下载链接的,要注意跳过。
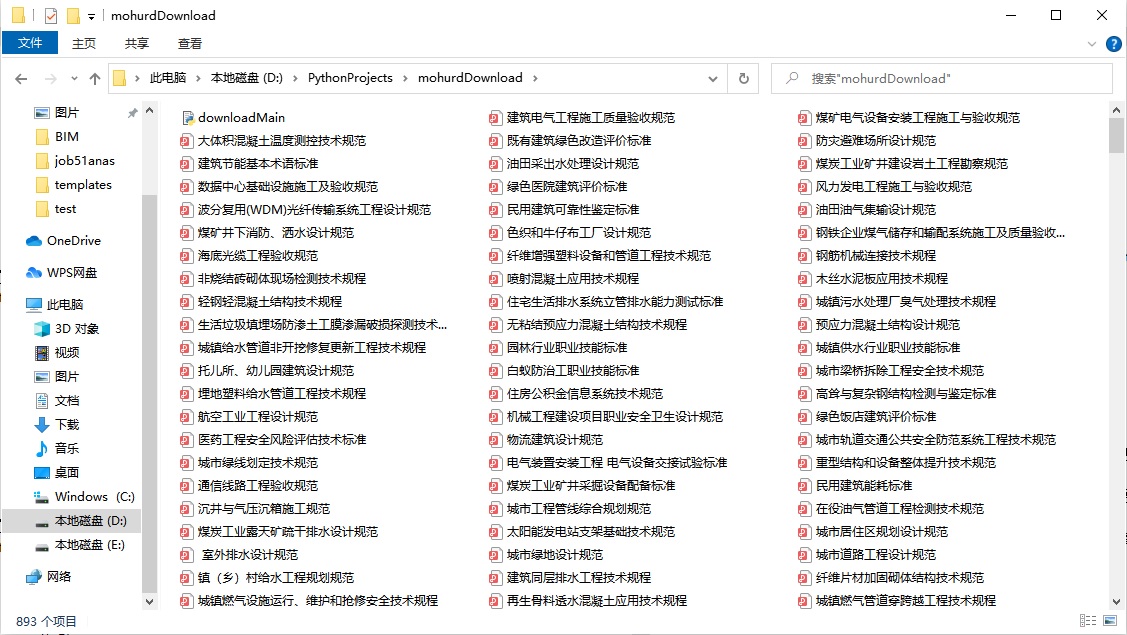
文件下载还是要费一定周期的,一定要处理好各种意外,以免程序中断又全部重来。处理规避好各种坑之后,就可以蹭蹭下载了,看到满屏的白嫖文件,确实有点神清气爽、洋洋得意啊。
最后
以上就是无奈水池最近收集整理的关于建筑标准何其之多,python爬虫半天全梭的全部内容,更多相关建筑标准何其之多内容请搜索靠谱客的其他文章。








发表评论 取消回复