今天
小帅b要跟你说说
增量爬虫
是这样的
当你去爬取某个网站的数据时
你会发现
这些网站随着时间的推移
会更新更多的网页数据
这时候你要爬取的是
那些更新的网页数据
而不是
又一次爬取整站的内容
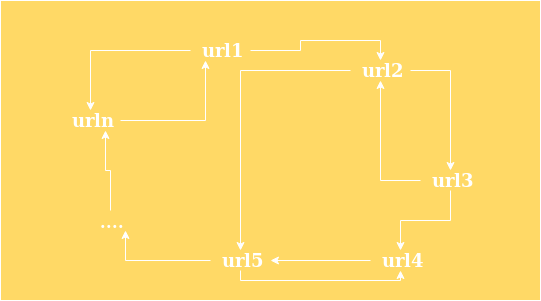
对于一些稍微复杂点的网站
它们的 url 之间会指来指去
如果你根据 url 的定向去爬取
可能会出现这种情况
 那么如何确保
爬取的数据不要重复?
接下来就是
学习 python 的正确姿势
那么如何确保
爬取的数据不要重复?
接下来就是
学习 python 的正确姿势
那么如何确保
爬取的数据不要重复?
接下来就是
学习 python 的正确姿势

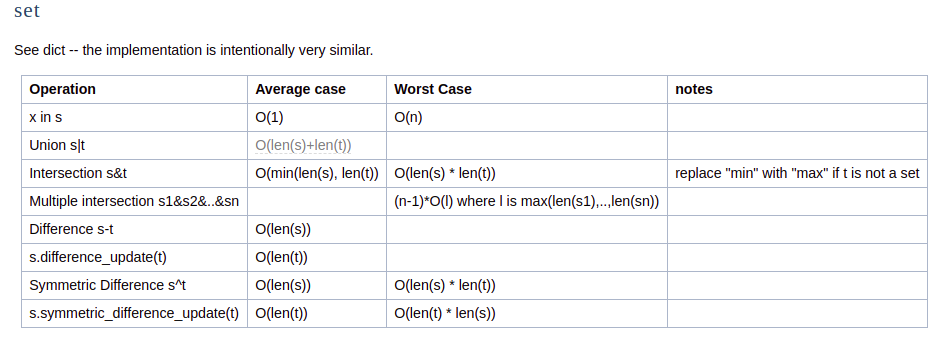
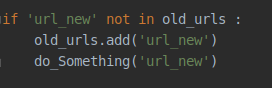

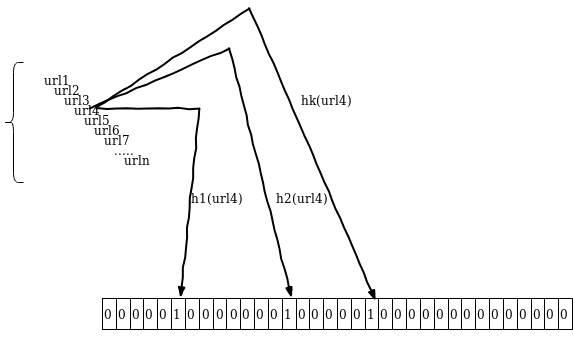
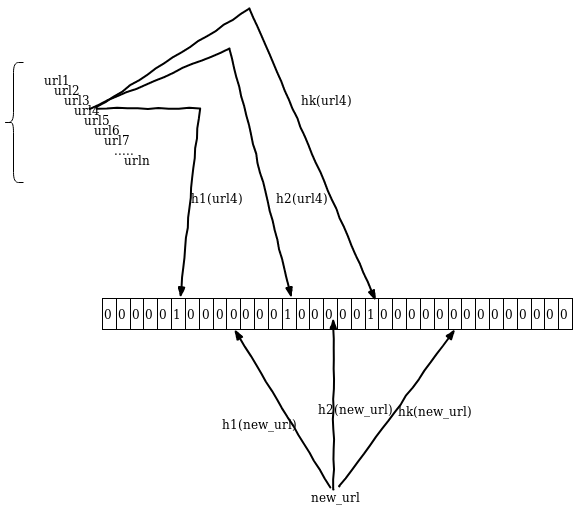

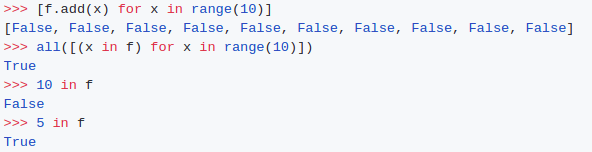
使用 add 方法
如果元素存在就直接返回 True
如果不存在就返回 False
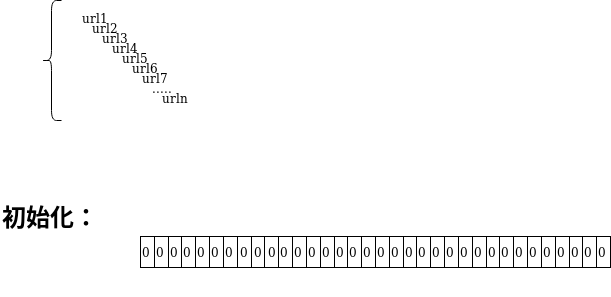
此外
还可以使用动态容量的方式


扫一扫
学习 Python 没烦恼

最后
以上就是欢呼草丛最近收集整理的关于md5会重复吗_听说你的爬虫一直在整站里循环绕圈圈爬取重复的数据?的全部内容,更多相关md5会重复吗_听说你内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复