如何让你的Python爬虫采集得更快
转自:http://www.site-digger.com/html/articles/20131019/69.html
鲲鹏数据的技术人员长期从事Python爬虫的开发工作,如何让Python爬虫采集的更快,如何处理海量数据的下载是我们一直探索和研究的对象。下面是我们从数学角度给出的一些分析以及我们的一些经验分享。
假设线程数为n,线程中下载平均用时为td,线程中数据处理部分(纯计算)用时为tc。由于单个Python进程只能使用单CPU核心,因此总的数据处理耗时应是各线程tc的累加即n*tc。因为下载是阻塞操作,CPU可以几乎同时处理所有下载,因此总的下载耗时就近似为td。那么Python爬虫的下载速度应为:
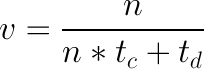
等式稍作变换后为:
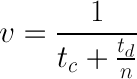
对于特定的网站td为定值(常量),对于特定的数据处理算法tc也近似为定值。所以下载速度的最大值也不会超过1/tc。试想一下,如果线程函数内数据处理部分耗时为0.1秒,那么不管线程数再大,整体的速度也不会超过10个/秒。线程数n的增大的确能够使得v增大,但是如果tc值较大,n的值达到一定程度后对v的影响就很小了。假设tc = 0.1,td = 3,那么 v = 1/(0.1+3/n)的函数图象应为如下图所示:
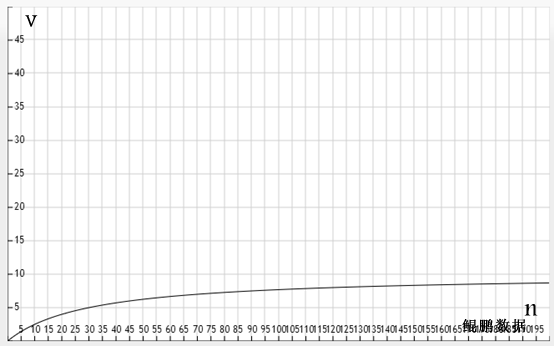
由图可以看出当n在100以后对v的影响就不大了。因此不能盲目的增大线程数n。线程数越大消耗的系统资源就越多,同时过多的CPU切换反而会增加整体花费的时间。
如何让你的爬虫跑的更快呢?通过上面的分析我们知道单个Python爬虫进程最大速度为1/tc。如果我们同时启动m个进程,那么整体的速度就能提高m倍。但是m的值也不是越大越好,因为进程的系统开销比线程还要大。一般进程数取CPU的核心数的为宜(具体可视实际CPU使用率情况调整)。
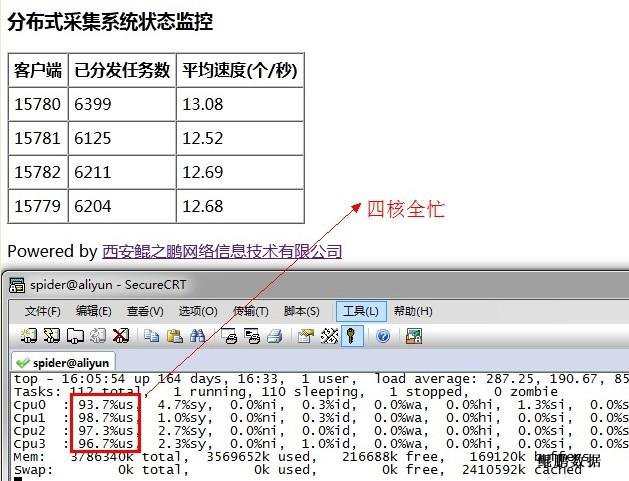
如下图所示,为我们在一4核机器上同时启动4进程的情况。只启动一个进程时速度最大仅为13个/秒,同时启动4个进程,整体的速度就达到约50个/秒。
另外,Python虽然有multiprocessing库,但是我们实际测试其速度远没有真正的多个独立进程快。因此建议用真正的“多进程”。
多进程的设计增加了程序的开发难度。主要要解决两大问题:
一、输入(任务队列)。多进程要共享一个任务队列。如果该任务队列方案支持网络,那么就很容易把采集系统做成真正的分布式集群采集。
二、输出。简单的做法就是直接把数据写入数据库,但是在爬虫程序内频繁操作数据库势必会增加耗时。一个较好的方案是将输出先写入消息队列,然后用一单独进程来处理消息队列。
最后
以上就是缓慢大象最近收集整理的关于如何让你的Python爬虫采集得更快的全部内容,更多相关如何让你内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复