好久没有写关于单篇文章的解读了。但是今天这一篇《ESCM2: Entire Space Counterfactual Multi-Task Model for Post-Click Conversion Rate Estimation》必须值得单独写一篇解读。原因有二:
文章非常有现实意义。这篇2022年的阿里新文,是关于“因果推断”、“反事实学习”在推荐模型中的应用,用于减轻建模一条转化链条的前后环节之间存在的bias,解决的确是推荐算法的一个痛点。
文章写得,真的不好懂。文章中“怎么做”、“为什么这样做”,还有一堆数学证明杂揉在一起,找人摸不清文章的网络和重点。顺着原文来读,思路极容易被打断。而且表达同样意思的公式,可能写了两遍,用了两种符号。有的重要结论,只用文字轻描淡写提了一句,而没有写成公式引起读者的注意。唉,可能作者也没办法,论文这东西就是八股文。
Causal Inference和Counterfactual Learning,和我们平常用到的Machine Learning理论上还是有所不同的,我也是一知半解,所以在本文中将我的疑问也列举出来,欢迎大家一起来讨论。
要解决的问题
阿里的这篇文章,应对的是CVR建模问题。在电商环境下,用户转化需要“先曝光->再点击->最后购买”,三个环节之间存在先后顺序之分,也蕴含着因果关系。
业务要求建模三个目标:
CTR:从曝光到点击的概率
CVR:从点击到购买的概率
CTCVR:从曝光到购买的概率
中间环节单独建模的意义
这里需要指出的是,单独对中间环节建模(i.e., 这里的CVR)的意义:
理论上,我们只关心购买。如果CTCVR预测的是准确的,那么其实没必要单独建模CVR。以最终CTCVR排序即可。
但是,以上两个假设都不成立
首先,CTCVR预测得肯定有误差
其次,业务要求,使我们需要关心中间环节。比如广告场景下,不同的转化环节,不同的计费模式。
因此,这里必须把cvr, ctr, ctcvr都预测出来,再把三个分数加权成一个综合得分,再排序
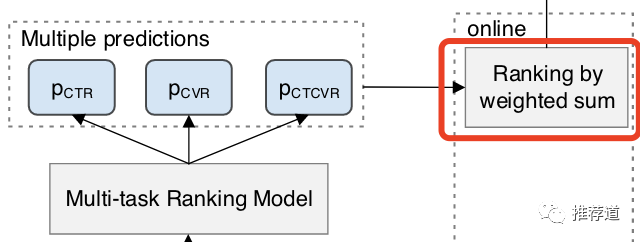
而在其他一些场景下,比如内容推荐场景下,就直接建模ctr和“完播”就行了,没再建模“点击后完播”的条件概率。当然,未来可以借鉴电商广告场景,把中间环节拎出来单独建模。
建模中间环节的Naive方法
写出loss来很容易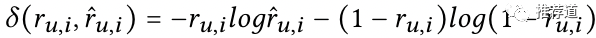
是user 'u'对item 'i'是否转化的ground truth label
是CVR model的预测结果 问题就在于只在click=1的样本上(click space, 下图中的O)才能拿得到
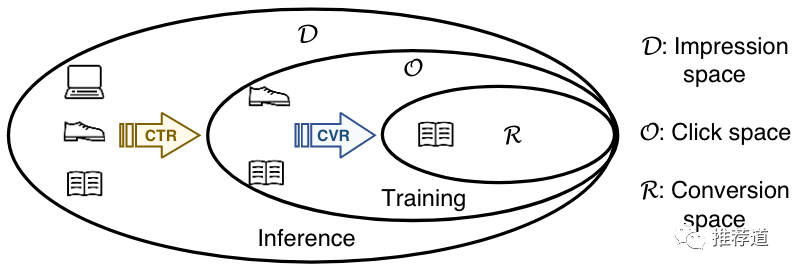
因此,一种naive的方法,训练的时候,只拿click=1样本(click space, O)来训练CVR模型。存在两个问题:
问题1:训练空间与预测空间不匹配
训练的时候,是拿所有click=1的样本来训练,<user, item>的匹配性已经非常高了。
而预测的时候,只是经过召回、粗排的粗筛,<user, item>的匹配度还非常低。
两个空间不匹配,训练时缺失的那部分样本,是由系统性的sample selection bias造成的,Missing Not At Random(MNAR)
问题2:只用click=1的样本,训练数据比较少
ESMM方法的缺点
为了解决Naive方式以上两个问题,阿里提出了ESMM
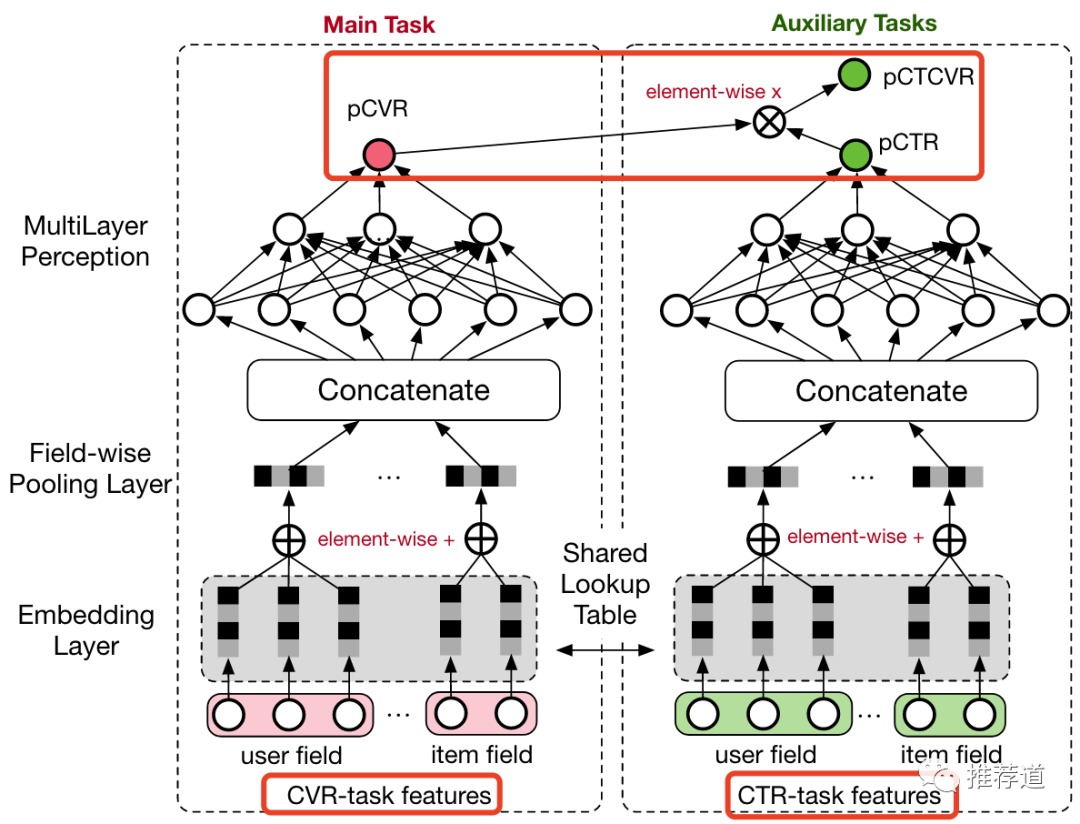
ESMM实际上是回避了单独建模CVR的问题
两个loss,一个ctr loss,另一个ctcvr loss,都是在整个“曝光样本空间”D上建模
CVR= CTCVR / CTR
优点:CTR和CTCVR都是在全体曝光样本上建模的,因此两者相除的结果CVR也算是在全体曝光样本上建模的。因此,CVR模型训练与预测同分布(实际上训练是在曝光样本空间,预测是在召回样本空间,不过这点差异,大家都约定俗成,不予追究了),算是解决了sample selection bias的问题。
缺点:
一是Inherent Estimation Bias (IEB),认为ESMM的CVR得分存在系统性的bias,普遍偏高
二是Potential Independence Priority (PIP)
我理解成,算是另外一种反向sample selection bias
因为CTR, CTCVR都是在全体曝光空间D上建模的,两者的商CVR也是建模在全体曝光空间上的,对于消除training/inference之间的gap当然是好事。
但是CVR的含义毕竟是“点击后再转化”的概率,click->convert之间的因果关系就建模不出来了。
但是CVR=CTCVR/CTR这个公式是肯定不会有错的,那么以上两点偏差是从何而来的?我觉得是:要让这个公式成立,需要理想化的条件,是现实无法满足的。比如,训练CTCVR也是认为,如果最终click & convert=0,就代表着用户不喜欢。但是有可能是因为CTR模型预估得不准,把item排在不好的位置,让用户失去了click的机会,而实际上p(convert|click)应该是很高的。这也就是论文中所谓“反事实”的含义。
Entire Space Counterfactual Multi-task Modelling (ESCM2)
ESCM采用了一种与ESMM完全不同的思路:
CVR遵循其名称的本意,还是只拿click=1的数据来训练
但是采用一些因果推断、反事实学习的方法,在训练过程中就减轻Sample Selection Bais(SSB)、Missing Not At Random(MNAR)带来的负面影响。
最终得到的模型,尽管是只用click=1样本训练出来的,但是在全样本空间预测时,也能得到"unbiased"的结果。(unbiased是论文里宣称的效果,还用数学证明了。我觉得那是理论结论,现实中做不到,至多是降低bias)
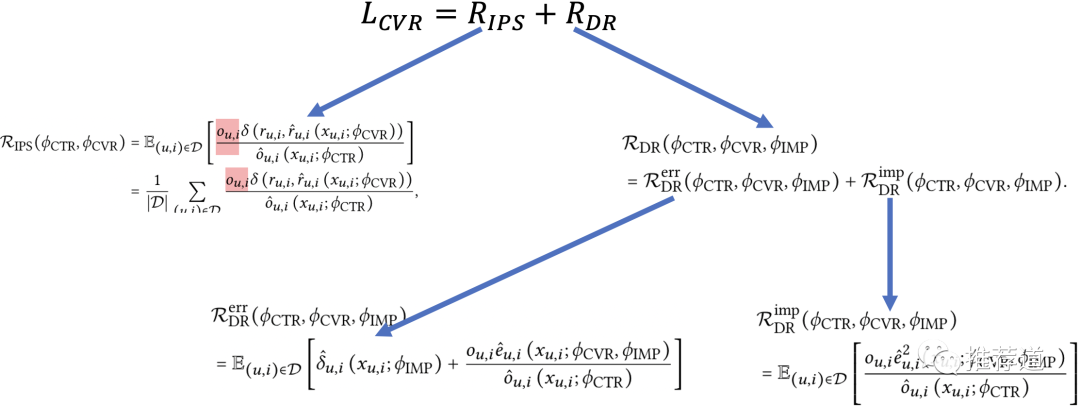
整个ESCM都是围绕着如下公式开展的
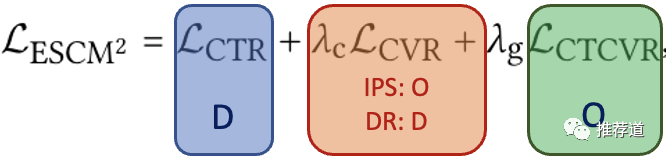
在全量曝光样本D上建模ctr loss
是在click=1的点击空间O上建模“最终转化loss”
用ESMM一样,用ctcvr=ctr*cvr为预测值,用最终是否转化为label,计算binary cross-entropy loss。
论文中说“the global risk minimizer optimizes the risk of CTCVR estimation over D”,我觉得是论文在这里写错了
首先论文中图4“Global Risk Minimizer”下边就有“O”(代表click space)的字样
论文里还说“The amount of training data for CTR task is significantly greater than that of CVR and CTCVR tasks by 1-2 order of magnitudes.”,所以ctcvr也应该是在click space中建模的
还有建模ctcvr时,用到的ctcvr prediction是由predict ctr * predict cvr相乘得到的。predict cvr肯定是只由click=1的样本上训练得到的(这是本文区别ESMM的最大区别),所以ctcvr也应该是只在click=1的样本上建模。
到底在哪个空间建模,要区分具体是用IPS实现,还是DR实现。
用IPS实现CVR建模
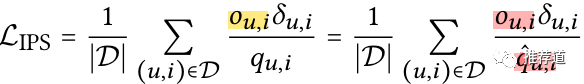
或者写得更具体一点
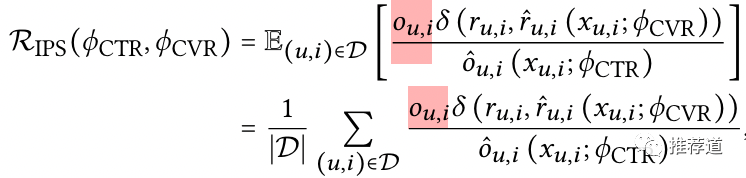
是用户是否点击的label。因此,尽管公式的计算范围是D(全体曝光样本),但是实际上是只拿点击样本(=1)建立loss
是user 'u'对item 'i'是否转化的ground truth label。毕竟只有click=1的样本上的才是可信的
是CVR tower的预测结果
都是ctr tower的预测值
然后,我们要建模的。(这也是这篇文章难懂的原因之一,同一个意思在不同地方用不同的符号来表达,也没有一个地方写清楚这个两个符号表达同样含义。)
不要看原论文中的图4,在IPS实现中是压根没有中间那个计算Imputation Error的塔的。更准确的图是《LARGE-SCALE CAUSAL APPROACHES TO DEBIASING POST-CLICK CONVERSION RATE ESTIMATION WITH MULTI-TASK LEARNING》中的图4。注意右下角的“O”,说明CVR只在click=1的空间上建模。
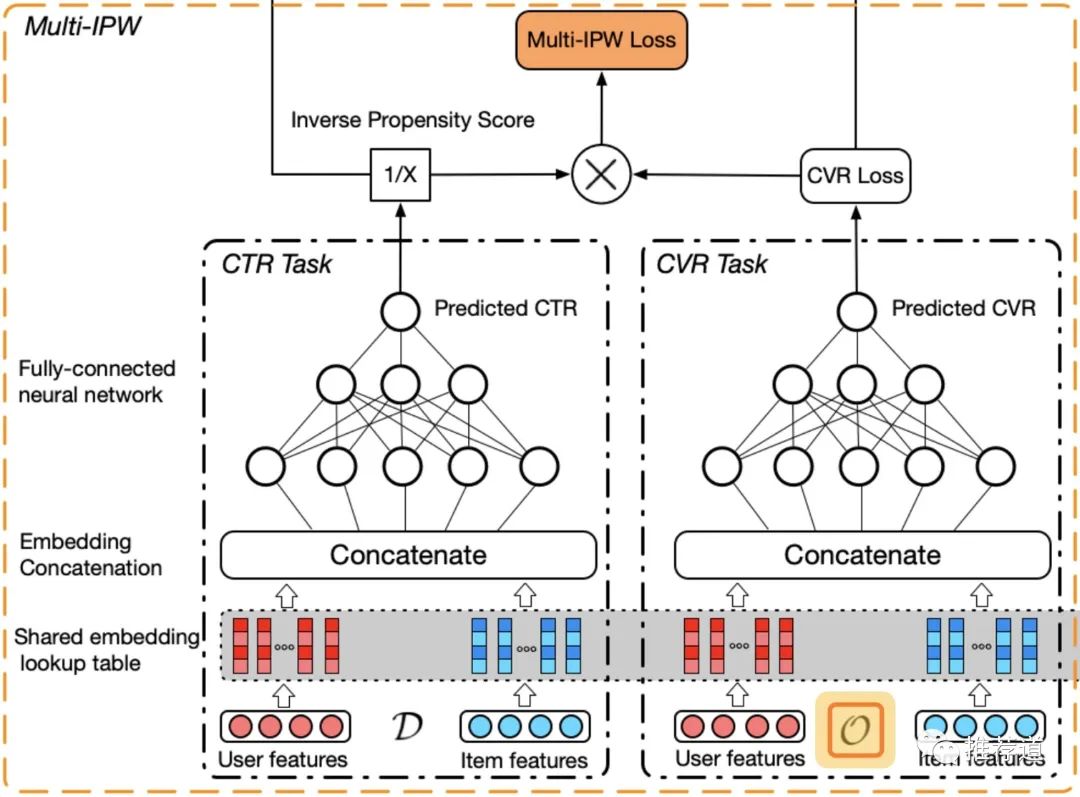
对于以上公式的解读,我看到的解释都是:
如果ctr高,还转化了,是理所应当的,权重应该低一些
如果ctr低,最终反而转化了,是Counterfactual的,正好是对Sample Selection Bias的有力反击,所以权重应该大一些。
但是我始终有一个疑问,ctr高低来决定样本权重,难道不应该视样本的正负而定吗?
ctr高,还转化了,没啥新鲜的,权重理应低一些
ctr高,但是未转化,这个非常非常counterfactual呀,权重理应更高呀!!!
全用inverse ctr当权重,“一视同仁”,不太合适吧
另外,论文里说用这种IPS建模,尽管是在click=1的样本训练,但是在全体样本空间预测时得到的cvr也是unbiasd。我不太相信,我们是在debias,不是在unbias。cvr都是在点击样本上训练得到的,尽管以inverse ctr反向加权,但是点击样本中的ctr基本上都不低吧。
用DR实现CVR建模
认为IPS中用predict ctr 当propensity score,毕竟是预测值,偏差会高,因此采用如下Doubly Robust来计算。
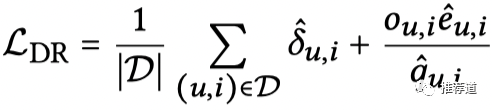
写得更具体一些
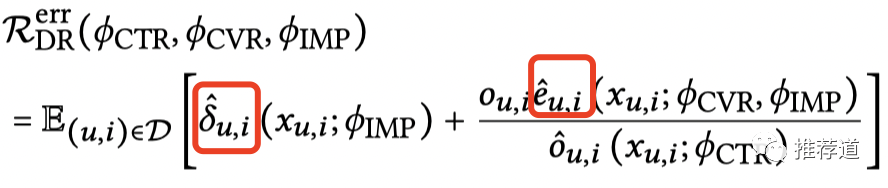
不同于IPS,DR是在整个曝光样本空间上建模
是imputed error,全体曝光空间上的“推测cvr loss”。
因为只有click=1的样本才有是否转化的真实label,所以只有在click=1的样本上计算出来的cvr loss 才是真实可信的
在除了click之外的剩余的曝光空间上,我们无法计算出真实的。所以,我们单独建立一个模型来模拟在click=0上的cvr loss,就是这里的imputed error 。再次发挥了DNN中的“无中生有、空手套白狼”的本事。
-
就是imputation tower"凭空"造出来的输出,是建模在全体曝光样本空间上的
在click space上,根据predicted cvr和convert ground truth计算得到的真实cvr loss
Doubly Robust的意义,我看到的解释都是:起到一个双保险的作用,只要propensity score ,和imputed error ,有一个预测得准,就能起到debias的作用。
的准确性,是由ctr tower决定的,是被“是否点击”的ground truth label限制住的。
但是谁来保证 的准确性?
点击样本
如果是click样本,即,再忽略分母的影响,则,就是点击样本上的真实cvr loss。那么 的准确性就由converted ground truth label给约束住了。而且还加上如下mse loss,减少真实cvr loss与imputed cvr loss之间的距离。
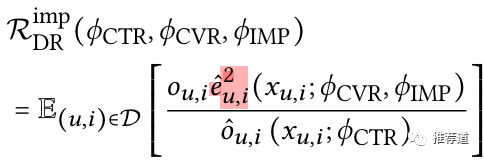
总之,对于click样本,采用如下公式计算cvr loss ,准确性是有保障的。
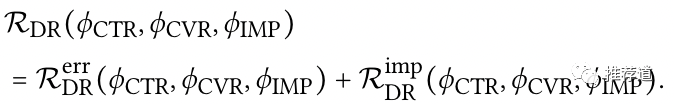
曝光未点击样本
但是对于click=0的曝光样本呢?整个cvr loss 就只剩下了imputed cvr loss 。由于我们拿不到click=0的曝光样本上的“是否转化”的ground truth,本来就是由模型“无中生有”硬造出来的,岂不是就没有了约束?比如这个模型可以让其中所有W、b都变成0,那么不也变成0了吗?
在我看来,还就真的没有对的直接约束,对它的约束都是间接的。因为对于click=0和click=1的样本,共享一套模型参数。而当click=1时的“是否转化”的ground truth label,把模型参数约束住了,那就不会出现W、b都变成0的情况,在click=0的样本上也不会无下限的小下去。或许这就是在论文里,称这一项为regularizer的原因,毕竟对于regularizer来说,约束就是它自己。
整体结构
论文中说,“ESCM2-DR: It augments ESCM2-IPS with an imputation tower”。所以,我觉得这里的应该如下:(唉,这么重要的地方,论文作者为什么不给出一个直接明白的公式,非要让我们自己去猜,真是的)
整体架构如下:
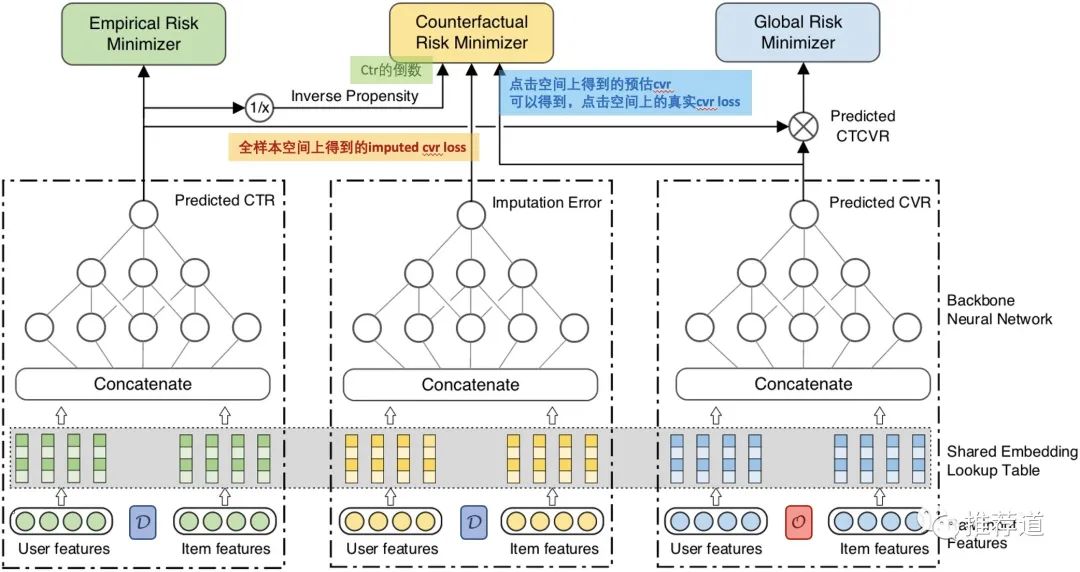
左边的塔,在全体曝光样本上训练,得到ctr
预测出来的ctr,喂入Empirical Risk Minimizer,计算
ctr的倒数喂入Counterfactual Risk Minimizer,计算
右边的塔,在点击样本上训练,得到cvr。
由cvr,计算出点击样本上的真实cvr loss " ",喂入Counterfactual Risk Minimizer,参与计算
ctr tower输出的predict ctr,和这里输出的predict cvr相乘,得到点击空间上的predict ctcvr,喂入Global Risk Minimizer计算点击空间上的
中间的塔,在全量曝光样本上,预测输出imputed cvr loss
中间的Counterfactual Risk Minimizer,输入全体曝光上样本上的ctr和 ,还有点击样本上的真实cvr loss ,计算得到曝光空间上的
结尾
本文和ESMM面向的问题是一样的,解决“转化链路多环节之间的bias”,但是与ESMM采用了完全不同的思路
ESMM不直接优化CVR,而是在全体曝光样本上优化cvr loss和ctcvr loss,再用cvr=ctcvr/ctr来得到cvr,从而使训练和预测CVR的所使用的数据同分布,解决sample selection bias
ESCM回归cvr的本质,只拿click数据上训练、优化cvr loss。但是通过Counterfactual方法debias,使只用click数据得到的模型,能够在面对全量数据预测时,产生所谓“unbias”的结果。
另外,论文中还有几点:
底层是一个MMOE
“we implemented ESMM and ESCM2 with our internal C++ based deep learning framework, where ESCM2 was built with the IPS regularizer for its competitive offline performance and training efficiency.”。所以最终上线的是哪一种?只使用了IPS,而没有使用DR?
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)


最后
以上就是大胆花生最近收集整理的关于推荐算法遇到后悔药:评蚂蚁的ESCM2模型要解决的问题Entire Space Counterfactual Multi-task Modelling (ESCM2)结尾的全部内容,更多相关推荐算法遇到后悔药:评蚂蚁的ESCM2模型要解决的问题Entire内容请搜索靠谱客的其他文章。








发表评论 取消回复