生成对抗网络
一.背景
一般而言,深度学习模型可以分为判别式模型与生成式模型。由于反向传播(Back propagation, BP)、Dropout等算法的发明,判别式模型得到了迅速发展。然而,由于生成式模型建模较为困难,因此发展缓慢,直到近年来最成功的生成模型——生成式对抗网络的发明,这一领域才焕发新的生机。
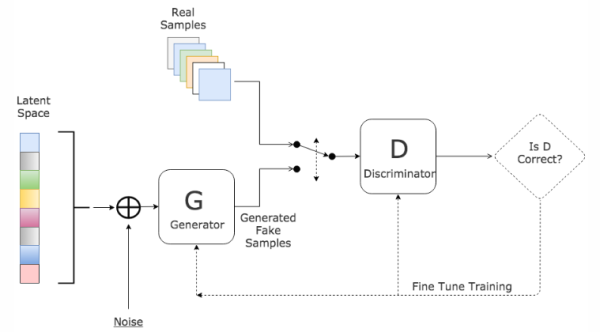
生成式对抗网络(Generative adversarial network, GAN)自Ian Goodfellow[1]等人提出后,就越来越受到学术界和工业界的重视。而随着GAN在理论与模型上的高速发展,它在计算机视觉、自然语言处理、人机交互等领域有着越来越深入的应用,并不断向着其它领域继续延伸。
二.简介
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
三 .GAN算法流程原理
3.1 判别模型和生成模型
机器学习的模型可大体分为两类,生成模型(Generative Model)和判别模型(Discriminative Model)。判别模型需要输入变量 ,通过某种模型来预测 。生成模型是给定某种隐含信息,来随机产生观测数据。举个简单的例子,
- 判别模型:给定一张图,判定图中的动物是什么类别
- 生成模型:给一系列猫的图片,生成一张新的猫咪
3.2 GAN 原理
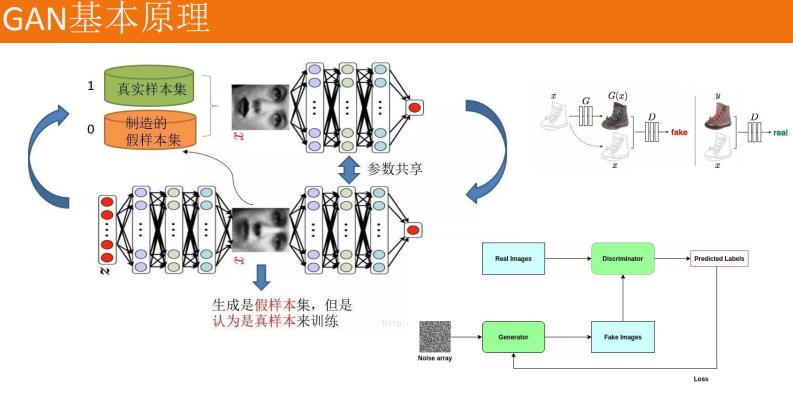
GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:
G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。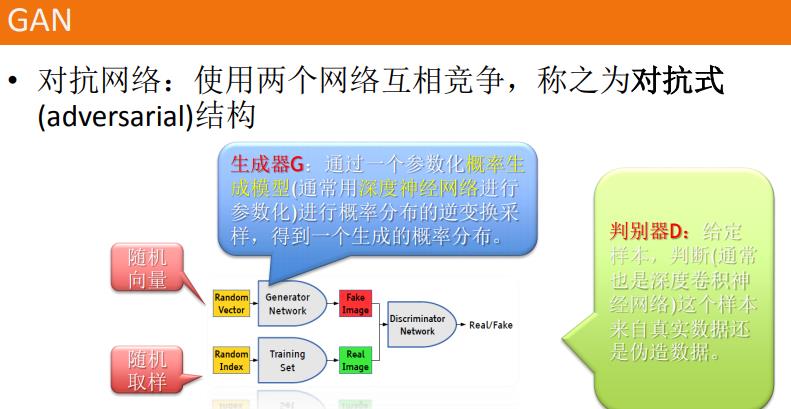
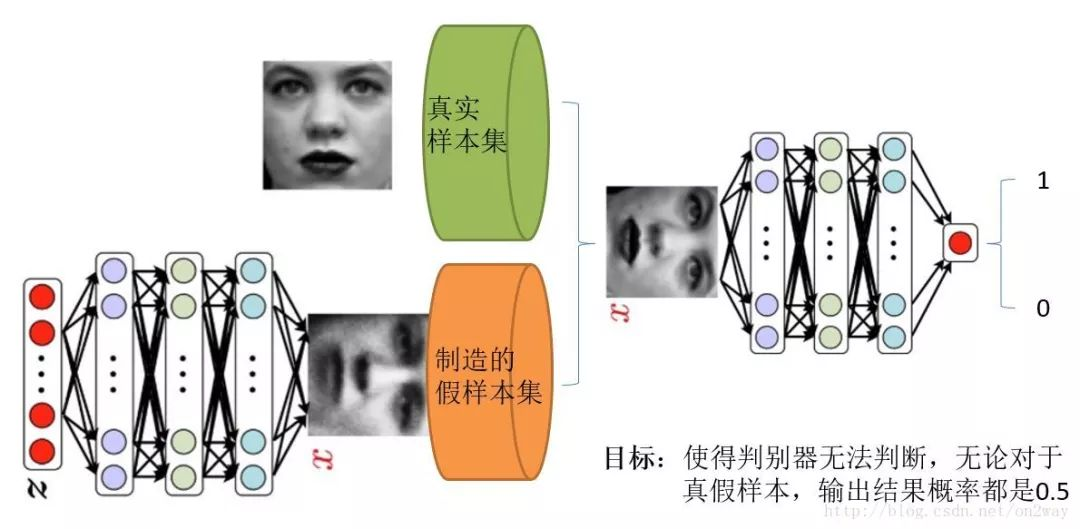
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
二人零和博弈思想(two-player game)
GAN 的思想是一种二人零和博弈思想(two-player game)博弈双方的利益之和是一个常数,比如两个人掰手腕,假设总的空间是一定的,你的力气大一点,那你就得到的空间多一点,相应的我的空间就少一点,相反我力气大我就得到的多一点,但有一点是确定的就是,我两的总空间是一定的,这就是二人博弈,但是呢总利益是一定的。
在GAN中就是可以看成,GAN中有两个这样的博弈者,一个人名字是生成模型(G),另一个人名字是判别模型(D)。他们各自有各自的功能。
两者的相同点:
- 这两个模型都可以看成是一个黑匣子,接受输入然后有一个输出,类似一个函数,一个输入输出映射
不同点:
- 生成模型功能:比作是一个样本生成器,输入一个噪声/样本,然后把它包装成一个逼真的样本,也就是输出。
- 判别模型:比作一个二分类器(如同0-1分类器),来判断输入的样本是真是假。(就是输出值大于0.5还是小于0.5)
如下图所示:
3.3 GAN 算法中的生成器
对于生成器,输入需要一个n维度向量,输出为图片像素大小的图片。因而首先我们需要得到输入的向量。
这里的生成器可以是任意可以输出图片的模型,比如最简单的全连接神经网络,又或者是反卷积网络等。
这里输入的向量我们将其视为携带输出的某些信息,比如说手写数字为数字几,手写的潦草程度等等。由于这里我们对于输出数字的具体信息不做要求,只要求其能够最大程度与真实手写数字相似(能骗过判别器)即可。所以我们使用随机生成的向量来作为输入即可,这里面的随机输入最好是满足常见分布比如均值分布,高斯分布等。
假如我们后面需要获得具体的输出数字等信息的时候,我们可以对输入向量产生的输出进行分析,获取到哪些维度是用于控制数字编号等信息的即可以得到具体的输出。而在训练之前往往不会去规定它。
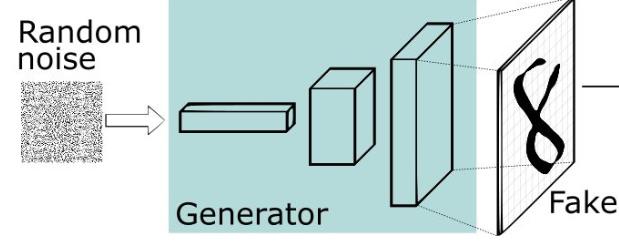
3.4 GAN算法中的判别器
对于判别器不用多说,往往是常见的判别器,输入为图片,输出为图片的真伪标签。
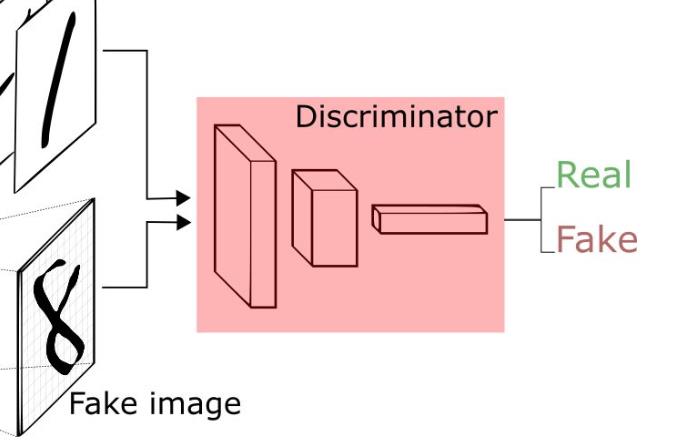
同理,判别器与生成器一样,可以是任意的判别器模型,比如全连接网络,或者是包含卷积的网络等等。
四.GAN 的训练
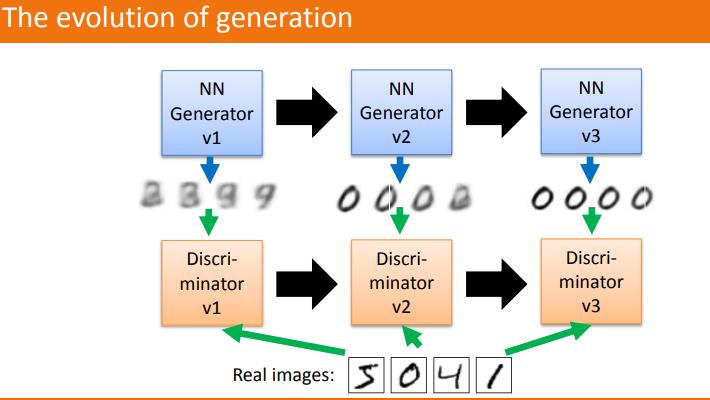
1.在噪声数据分布中随机采样,输入生成模型,得到一组假数据,记为D(z)
2.在真实数据分布中随机采样,作为真实数据,记做x;
将前两步中某一步产生的数据作为判别网络的输入(因此判别模型的输入为两类数据,真/假),判别网络的输出值为该输入属于真实数据的概率,real为1,fake为0.
3.然后根据得到的概率值计算损失函数;
4.根据判别模型和生成模型的损失函数,可以利用反向传播算法,更新模型的参数。(先更新判别模型的参数,然后通过再采样得到的噪声数据更新生成器的参数)

这里需要注意的是:生成模型与对抗模型是完全独立的两个模型,他们之间没有什么联系。那么训练采用的大原则是单独交替迭代训练。
GAN强大之处在于能自动学习原始真实样本集的数据分布,不管这个分布多么的复杂,只要训练的足够好就可以学出来。
传统的机器学习方法,一般会先定义一个模型,再让数据去学习。
比如知道原始数据属于高斯分布,但不知道高斯分布的参数,这时定义高斯分布,然后利用数据去学习高斯分布的参数,得到最终的模型。
再比如定义一个分类器(如SVM),然后强行让数据进行各种高维映射,最后变成一个简单的分布,SVM可以很轻易的进行二分类(虽然SVM放松了这种映射关系,但也给了一个模型,即核映射),其实也是事先知道让数据该如何映射,只是映射的参数可以学习。
以上这些方法都在直接或间接的告诉数据该如何映射,只是不同的映射方法能力不一样。
而GAN的生成模型最后可以通过噪声生成一个完整的真实数据(比如人脸),说明生成模型掌握了从随机噪声到人脸数据的分布规律。GAN一开始并不知道这个规律是什么样,也就是说GAN是通过一次次训练后学习到的真实样本集的数据分布。
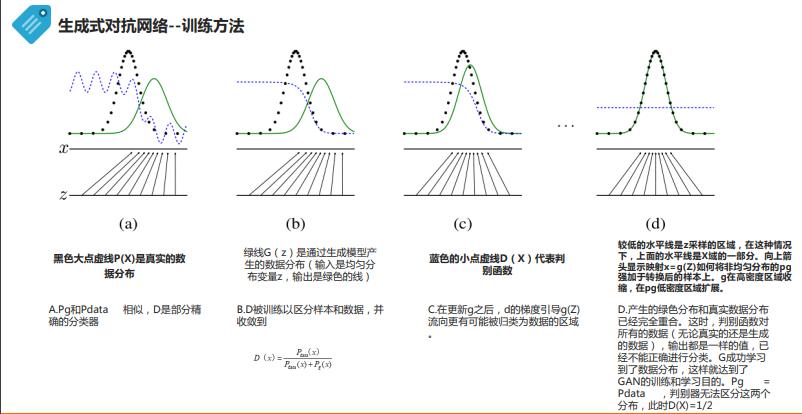
五.GAN 的损失函数
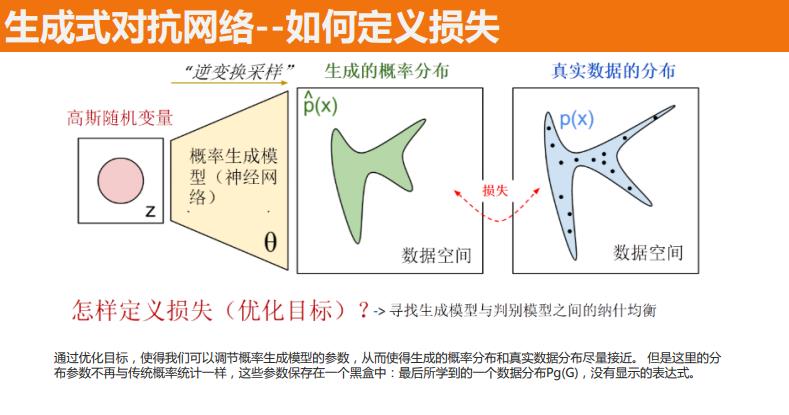

判别器在这里是一种分类器,用于区分样本的真伪,因此我们常常使用交叉熵(cross entropy)来进行判别分布的相似性,交叉熵公式如下图所示: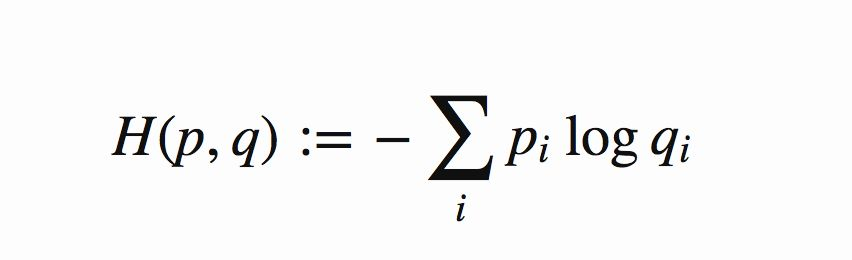
公式中 ![[公式]](https://www.shuijiaxian.com/files_image/2023062822/20200329125404975.png) 和
和 ![[公式]](https://www.shuijiaxian.com/files_image/2023062822/2020032912542587.png) 为真实的样本分布和生成器的生成分布。
为真实的样本分布和生成器的生成分布。
在当前模型的情况下,判别器为一个二分类问题,因此可以对基本交叉熵进行更具体地展开如下图所示:
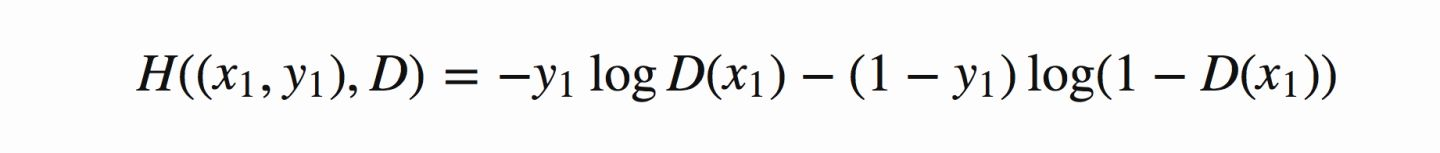
上式推广到N个样本后,将N个样本相加得到对应的公式如下:
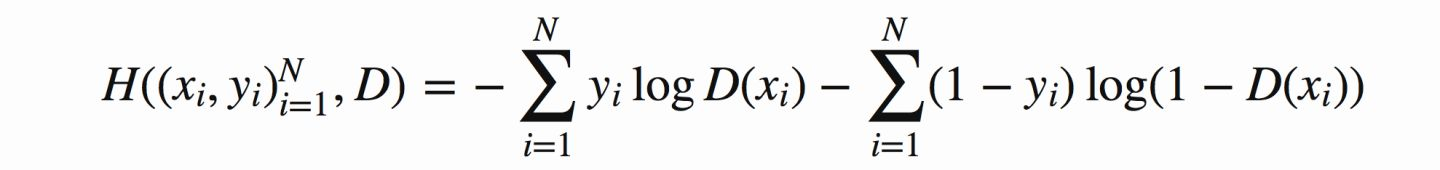
GAN损失函数期望形式


六.GAN 算法的不足

- 可解释性差,生成模型的分布 Pg(G)没有显式的表达
- 比较难训练,D与G之间需要很好的同步(例如D更新k次而G更新一次),GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。
- 网络难以收敛,目前所有的理论都认为GAN应该在纳什均衡上有很好的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。
- 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但在实践中它还是比训练玻尔兹曼机稳定的多
- 它很难去学习生成离散的数据,就像文本
- 相比玻尔兹曼机,GANs很难根据一个像素值去猜测另外一个像素值,GANs天生就是做一件事的,那就是一次产生所有像素, 你可以用BiGAN来修正这个特性,它能让你像使用玻尔兹曼机一样去使用Gibbs采样来猜测缺失值
参考:
复旦大学 《深度学习》
最后
以上就是安详外套最近收集整理的关于图解 生成对抗网络GAN 原理 超详解生成对抗网络的全部内容,更多相关图解内容请搜索靠谱客的其他文章。








发表评论 取消回复