一、概述
学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门。本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴。
这次我选择爬取boss直聘的招聘信息数据,毕竟这个网站的数据还是很有参考价值的,下面我们讲述怎么爬取boss直聘的招聘信息并存盘,下一篇文章我们在对爬取到的数据进行分析。
二、Scrapy框架使用步骤
下面我们做一个简单示例,创建一个名字为BOSS的爬虫工程,然后创建一个名字为zhipin的爬虫来爬取zhipin.com这个网站
创建工程步骤:
1、创建工程 scrapy startproject BOSS
2、创建爬虫程序 cd BOSS 回车 scrapy gensipder zhipin zhipin.com
3、编写数据存储模板items.py 类对象继承自scrapy.item
4、编写爬虫zhipin.py 类对象集成子scrapy.Spider
5、修改settings.py配置文件 ITEM_PIPELINES = {'BOSS.pipelines.WwwZhipinComPipeline':100}
6、编写数据处理脚本进行数据保存,pipelines.py 类对象继承自object
1 def process_item(self, item, spider): 2 with open("my_boss.txt", 'a') as fp: 3 fp.write(item['name'] + 'n')
7、执行爬虫 cd BOSS 回车 scrapy crawl zhipin --nolog
注意:如果导出的中文信息乱码则需要在settings.py文件中配置编码:FEED_EXPORT_ENCODING = 'utf-8'
三、环境安装
爬虫框架我们使用Scrapy,爬取到的数据我们使用mongodb来存储
1、安装Scrapy
1 pip install Scrapy
2、安装mongodb
1 pip install pymongo
如果安装速度太慢,或者安装失败可以尝试使用pip install pymongo -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
mongodb基础操作命令参考:MongoDB基本命令操作
上述操作只是安装了mongodb的python驱动程序,如果要成功存储数据还需要安装Mongodb,具体安装流程参考Windows平台安装MongoDB,安装完成后一定要记得使用命令启动mongodb服务:net start MongoDB
四、mongodb使用
上一小节我们已经安装了mongodb数据库和驱动,因此后续我们爬取到的招聘信息就存储在该数据库中,为了方便数据存储,我们这里封装了一个类,来快速的访问数据库,代码如下所示
1 from pymongo import MongoClient 2 3 class my_connect(object): 4 def __init__(self, settings): 5 try: 6 self.conn = MongoClient(settings["ip"], settings["port"]) 7 except Exception as e: 8 print(e) 9 self.db = self.conn[settings["db_name"]] 10 self.my_set = self.db[settings["set_name"]] 11 12 def insert(self, dic): 13 self.my_set.insert(dic) 14 15 def update(self, dic, newdic): 16 self.my_set.update(dic, newdic) 17 18 def delete(self, dic): 19 self.my_set.remove(dic) 20 21 def dbfind(self, dic): 22 return self.my_set.find(dic) 23 24 def setTableName(self, name): 25 #print(u'修改当前使用集合:{}'.format(name)) 26 self.my_set = self.db[name]
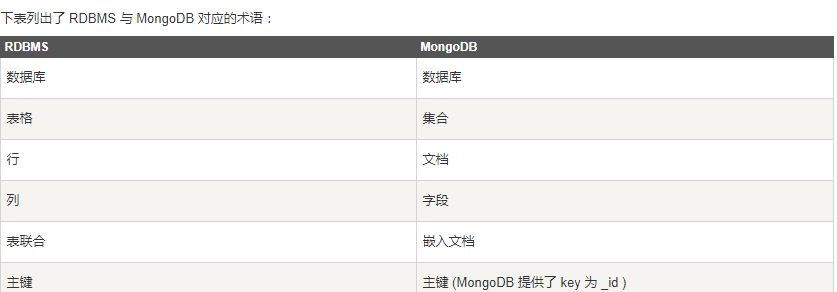
上述代码中我们封装了一个名为my_connect的类,并提供了输入、更新、删除和查找文档的接口,除此之外还提供了一个setTableName的接口,这个接口主要是用于往不同集合中插入文档数据。MongoDB 概念解析可以看这里。mongodb属于非关系型数据库,与关系型数据库对比图如下
my_connect初始化函数中有一个参数,需要我们传入ip地址、端口号、数据库名字和集合名字,使用方式如下所示
1 from pymongo import MongoClient 2 from my_connect import my_connect 3 4 settings = { 5 "ip":'127.0.0.1', #ip 6 "port":27017, #端口 7 "db_name" : "zhipin_datas", #数据库名字 8 "set_name" : "test" #集合名字 9 } 10 11 conn = my_connect(settings) 12 conn.setTableName('21') 13 conn.insert({'12':'3'})
五、创建爬虫zhipin
1、输入如下命令,创建zhipin爬虫
1 scrapy startproject www_zhipin_com 2 cd www_zhipin_com 回车 scrapy gensipder zhipin www.zhipin.com
2、修改zhipin.py,爬取数据,类中成员属性含义代码中都有解释,这里不做解释,需要注意的是parse方法,该方法是爬取到数据以后的回调函数,参数response表示爬取到的结果,我们可以对其进行解析拿到网页数据。
1 class ZhipinSpider(scrapy.Spider): 2 # spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。 3 # 不过您可以生成多个相同的spider实例(instance),这没有任何限制。 4 # name是spider最重要的属性,而且是必须的 5 name = 'zhipin' 6 7 # 可选。包含了spider允许爬取的域名(domain)列表(list)。 8 # 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。 9 allowed_domains = ['www.zhipin.com'] 10 11 # URL列表。当没有指定特定的URL时,spider将从该列表中开始进行爬取。 12 # 这里我们进行了指定,所以不是从这个 URL 列表里爬取 13 start_urls = ['http://www.zhipin.com/'] 14 15 #网址URL中特殊字符转义编码:https://blog.csdn.net/u010828718/article/details/50548687 16 #爬取的页面,可以改为自己需要搜的条件,这里搜的是 北京-C++,其他条件都是不限 17 #query:查询岗位 18 #period:时间范围 5表示一个月内 &在url中需要写为%26 19 #a_街道b_区名称 eg:a_上地-b_海淀区 包含在路径内,城市编号(c101010100)下一级 20 positionUrl = 'https://www.zhipin.com/c101010100/?query=C%2B%2B%' 21 curPage = 1
解析数据时,默认一次可以拿到30条数据,我们循环遍历这30条数据,构造WwwZhipinComItem对象item,然后调用yield item即可
1 def parse(self, response): 2 job_list = response.css('div.job-list > ul > li') 3 request_data = [] 4 for job in job_list: 5 item = WwwZhipinComItem() 6 ... 7 yield item
2.1、这里有一个小技巧,我们重写start_requests方法,让他调用了我们自己写的一个方法next_request,并设置了回调函数为parse方法,当parse数据解析完毕后,又构造一个新的url在次调用next_request方法拉取数据,一直循环迭代,拉取数据、解析数据
2.2、boss直聘有一个限制,不管以什么样的方式搜索数据,数据最多显示10页,这也就要求我们需要对爬虫做一个处理,在合适的实际去终止拉取数据,否则爬虫会一直运行下去,直到boss直聘返回异常(请求被限制)
2.3、经过对爬虫数据的分析,我们发现当最后一次请求和上一次请求的数据完全一样时,我们可能已经到达请求的最后一页,那么这个时候我们就可以去终止爬虫了
2.4、为了快速的比对我么爬取到的数据是否和上一次一样,我们对爬取到的数据进行简单的处理,每次去对比关键字段即可
1 class itemData(object): 2 def __init__(self, data): 3 self.companyShortName = data['companyShortName'] 4 self.positionName = data['positionName'] 5 self.time = data['time'] 6 self.city = data['city'] 7 8 def __eq__(self, other): 9 return (self.positionName == other.positionName 10 and self.companyShortName == other.companyShortName 11 and self.time == other.time 12 and self.city == other.city) 13 14 def __str__(self): 15 return "{}:{}:{}:{}".format(self.companyShortName 16 , self.time 17 , self.city 18 , self.positionName)
itemData包含是一条招聘信息,存储了招聘公司名称,职位名称,发布时间和发布城市,我们重写了__eq__方法,就是为了比对两个对象是否相等。
2.5、一次请求的数据是一个itemData集合,当两个集合相等时我们即可终止爬虫
1 if one_request == request_data:#已经拉取到最后一页数据了 退出 2 print('{}:本次拉取数据和上次拉取数据相同,{}'.format(time.strftime("%Y-%m-%d %H:%M:%S" 3 , time.localtime()), self.curPage)) 4 return 5 6 one_request = request_data #更新最后一次请求数据 7 8 print('{}:拉取数据量:{}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), len(job_list))) 9 self.curPage += 1 10 time.sleep(5) # 停停停!听听听!都给我停下来听着!睡一会(~﹃~)~zZ 11 yield self.next_request()
2.6、parse解析数据时,对每一条数据会构造一个WwwZhipinComItem对象item,并通过yield item方式触发
3、对于爬取的字段定义需要我们修改item.py文件,定义爬取字段如下
1 class WwwZhipinComItem(scrapy.Item): 2 # define the fields for your item here like: 3 # name = scrapy.Field() 4 pid = scrapy.Field() 5 positionName = scrapy.Field() 6 positionLables = scrapy.Field() 7 workYear = scrapy.Field() 8 salary = scrapy.Field() 9 city = scrapy.Field() 10 education = scrapy.Field() 11 companyShortName = scrapy.Field() 12 industryField = scrapy.Field() 13 financeStage = scrapy.Field() 14 companySize = scrapy.Field() 15 time = scrapy.Field() 16 updated_at = scrapy.Field()
4、最后一步写入数据库
4.1、第四节我们封装了一个名字为my_connect的数据库操作对象,在这里我们就可以用上了。
4.2、首先构造一个conn对象
1 db_name = 'zhipin_datas_C++' 2 nowMonth = datetime.datetime.now().month 3 settings = { 4 "ip":'127.0.0.1', #ip 5 "port":27017, #端口 6 "db_name" : db_name, #数据库名字 7 "set_name" : "test" #集合名字 8 } 9 10 conn = my_connect(settings)
4.3、指定要插入的集合,然后构造数据、插入数据
1 conn.setTableName(month) 2 3 data = {"pid": item['pid']#"27102804" 4 , "positionName": item['positionName'] 5 , "positionLables": item['positionLables']#[] 6 , "workYear": item['workYear']#"5-10年" 7 , "salary": item['salary']#"30k-50k" 8 , "city": item['city']#"北京 海淀区 知春路" 9 , "education": item['education']#"硕士" 10 , "companyShortName": item['companyShortName']#"vmware" 11 , "industryField": item['industryField']#"计算机软件" 12 , "financeStage": item['financeStage']#"已上市" 13 , "companySize": item['companySize']#"10000人以上" 14 , "time": item['time']#"2018-11-13 17:35:02" 15 , "updated_at": item['updated_at']#"2018-11-13 17:35:02" 16 } 17 18 conn.insert(data)
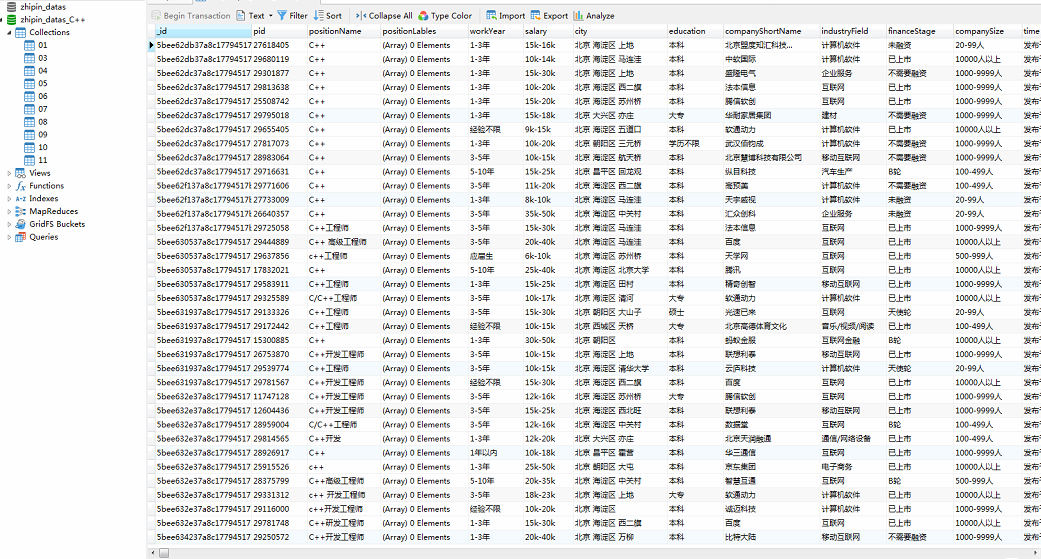
4.4、数据爬取结束后,使用gui工具Navicat 12 for MongoDB可以查看爬取到的数据,效果如下图所示
六、源码下载
需要全部代码的到csdn直接下载:python爬虫Scrapy(一)-我爬了boss数据
转载声明:本站文章无特别说明,皆为原创,版权所有,转载请注明:朝十晚八
转载于:https://www.cnblogs.com/swarmbees/p/10011898.html
最后
以上就是虚幻吐司最近收集整理的关于python爬虫Scrapy(一)-我爬了boss数据的全部内容,更多相关python爬虫Scrapy(一)-我爬了boss数据内容请搜索靠谱客的其他文章。








发表评论 取消回复