Python 分布与并行 asyncio实现生产者消费者模型
- 一、题目介绍
- 二、题目分析
- 三、asyncio模块的入门学习
- 四、实现代码
由于疫情原因这个学期格外的短,越到期末,时间就越显得宝贵,学习效率也尤为重要!本次分布并行实验也是最后一个分布并行系列作业,需要实现生产者消费者模型,而对于python爱好者的我来说如何都避不开异步编程、学习asyncio库这个关卡。这篇文章旨在分享我的实现过程和知识交流。
一、题目介绍
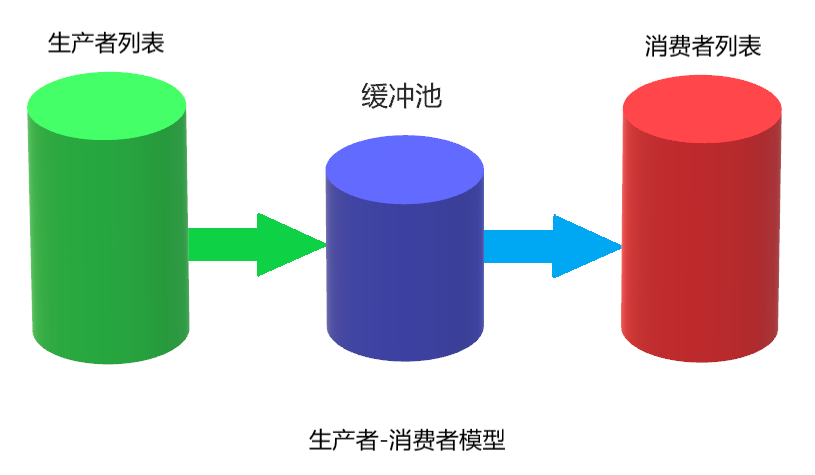
本实验让大家体验一下生产者-消费者的模式,并对此进行并行化改造。
1、生产者
随机生成一个大于20亿的正整数
2、消费者
判断某个数字是否素数(判断素数算法自己百度)
3、缓冲区
使用队列(FIFO)
基本要求:
第一个实验:使用1个生产者按要求生成1000000(100万)个数字,同时由1个消费者判断所生成的数字是否素数。记下所需时间。
第二个实验:使用1个生产者按要求生成1000000(100万)个数字,同时由2个消费者判断所生成的数字是否素数。记下所需时间。
第三个实验:使用2个生产者按要求生成1000000(100万)个数字,同时由4个消费者判断所生成的数字是否素数。记下所需时间。
二、题目分析
针对整体,查询网上资料会知道实现生产者消费者模型大多有两种选择:
1、使用yield语句(优点:实现简单,缺点:用法过于老旧,不适应本题)
2、使用asyncio异步编程(优点:时髦先进,缺点:学习成本相对较高)
显然只有第二条路可走。
针对第一个要求,并没有给定上界故自行设置,python自带大整数存储,故使用random模块产生随机整数
针对第二个要求,推荐使用高效的算法以提高运行效率
针对第三个要求,由于asyncio本身特色,实现协程需要用到队列交换数据,故直接使用asyncio模块中的Queue类
从整体上看,核心就是掌握入门级的asynico异步编程
三、asyncio模块的入门学习
1、 知识的起源——《流畅的python》
并发是指一次处理多件事。
并行是指一次做多件事。
二者不同,但是有联系。
一个关于结构,一个关于执行。
并发用于制定方案,用来解决可能(但未必)并行的问题。
——Rob Pike Go 语言的创造者之一
真正的并行需要多个核心。现代的笔记本电脑有4个 CPU 核心,但是
通常不经意间就有超过 100 个进程同时运行。因此,实际上大多数过程
都是并发处理的,而不是并行处理。计算机始终运行着 100 多个进程,
确保每个进程都有机会取得进展,不过 CPU 本身同时做的事情不能超
过四件。十年前使用的设备也能并发处理 100 个进程,不过都在同一个
核心里。鉴于此,Rob Pike 才把那次演讲取名为“Concurrency Is Not
Parallelism (It’s Better)”[“并发不是并行(并发更好)”]。
这本书中所讲可以先带领你了解asyncio的地位和领略并发并行的本质区别,鉴于这本书容量实在太大,感兴趣的读者可以去阅读,这里就相当于是个楔子。
2、网上资料的检索查询
最近身边的同学都反映,网上高质量、能直接移植的代码实在是太少了,大多数的文章相似度极高而且核心知识简单,再加上某度搜索引擎的检索能力堪忧,加大了我们获取有效知识的难度。
这里提供一篇我认为代码可复用性很高的文章:
python asyncio 生产者消费者模型实现
其中类的构建、消费者循环终止异常处理和asynico.wait_for()方法的使用令我大受启发。
3、小破站的快速教程
众所周知B站是一个学习网站,上面优质课程不胜枚举,既然要速成,那我们就不能选那些时长过长的视频(doge),检索“python asynico”出现了一堆视频。
只是因为在人群中多看了你一眼,就决定是你了——蜡笔小新
没错就是看中它精简并且综合排序靠前这点,结果点进去真没让我失望。开头讲课老师直接口吐芬芳说出了我的心声,举的例子能让你进一步了解如何使用asynico模块进行编程
下面给出课上的部分代码便于读者学习:
import asyncio # 导入模块
# 协程(协程不是函数)
async def print_hello():
while True:
print("hello world")
await asyncio.sleep(1) # 协程暂停1秒
async def print_goodbye():
while True:
print("goodbye world")
await asyncio.sleep(2) # 协程暂停2秒
# 创建协程对象
co1 = print_hello()
co2 = print_goodbye()
# 获取事件循环
loop = asyncio.get_event_loop() # epoll
loop.run_until_complete(asyncio.gather(co1, co2)) # 监听事件循环
asynico编程最主要的两个关键字就是async和await,分别代表声明协程和协程阻塞,当你想执行一个工作同时又想执行另一个工作时又不影响已有的工作,就可以考虑使用异步编程中的协程。示例中两个协程根据时间间隔交替地打印日志,互不干扰。
接下来这个例子以模拟异步爬虫为例,介绍另外一种管理协程的方法:
import asyncio
import random
"""
—————模拟异步网络爬虫——————
需求:有一个crontab调度器,每隔一秒,拉起一个job,
要求这些job可以并发爬取网页
"""
async def cro_scheduler():
page = 1
while True:
url = '{}/{}'.format('https://www.xxx.com', page)
job = cron_job(url) # 必须有新协程分离出去,让它和当前协程并发
asyncio.create_task(job) # 注册到事件循环
await asyncio.sleep(0) # 这里不是阻塞,而是主动让度线程,可以让job打印日志
page += 1
async def cron_job(url):
tick = random.randint(1, 3) # 模拟下载延迟
await asyncio.sleep(tick) # 阻塞协程,模拟下载
print("下载结束:", url)
if __name__ == '__main__':
asyncio.run(cro_scheduler()) # 开启调度器,硬性要求,这步是必须的
运行这个例子后你就发现异步编程是多么的迷人,让人欲罢不能!
4、底牌——Python官方文档
早些时候,虽然老师一再提到查询官方文档进行编程学习,但是年轻的我心浮气躁,静不下心来啃这块硬骨头。不得不说官方文档是最后的底牌,而且这张底牌恰好是张Ace,跟着 Python官方文档
永远不迷路,有时间还是需要阅读的,这个文档中还有不同python版本的语法说明,可以选择自己常用的版本来学习,这里我选择的是python3.7系列。
在编写这个案例的时候我也查询其中asynico相关的方法参数列表,只需要在对应界面Ctrl+F输入你想查询的方法名就可以快速找到并学习,何乐而不为,这不比在网上漫无目的地寻找来的高效吗。
5、如何高效地判断一个数是否为素数
一提素数就想到了埃拉托斯尼筛法,不过这个过于简易,迭代次数过多就暂不考虑。这个部分真的是有手就行,网上一搜一大把,我这里参考了
判断一个数是否为质数/素数——从普通判断算法到高效判断算法思路
这个算法的时间复杂度是O(sqrt(n)),可谓是高效了。
四、实现代码
终于到了最激动人心的时候了,来看看我是怎么实现的吧!
# -*- coding:utf8 -*-
import time
import random
import asyncio
import math
def isPrime(num: int):
if num == 2 or num == 3:
return True
if num % 6 != 1 and num % 6 != 5:
return False
for i in range(5, int(math.sqrt(num)) + 1, 6):
if num % i == 0 or num % (i + 2) == 0:
return False
return True
def big_number():
# 生成大于20亿的随机数,上限自定义
return random.randint(2 * 10 ** 10, 2 * 10 ** 15)
class Producer_Consumer_Model:
def __init__(self, c_num=1, p_num=1, size=1000000, is_print=False):
"""
生产者消费者模型
:param c_num: 消费者个数
:param p_num: 生产者个数
:param size: 需要处理的数据大小
:param is_print: 是否打印日志
"""
self.consumer_num = c_num
self.producer_num = p_num
self.size = size
self.print_log = is_print
async def consumer(self, buffer, name):
for _ in iter(int, 1): # 死循环,秀一波python黑魔法
try:
# 从缓冲区取数,如果超过设定时间取不到数则证明协程任务结束
value = await asyncio.wait_for(buffer.get(), timeout=0.5)
if isPrime(value):
if self.print_log:
print('[{}]{} is Prime'.format(name, value))
else:
if self.print_log:
print('[{}]{} is not Prime'.format(name, value))
except asyncio.TimeoutError:
break
await asyncio.sleep(0)
async def producer(self, buffer, name):
for i in range(self.size // self.producer_num): # 将处理数据总数按生产者个数进行切分
big_num = big_number() # 生成大随机数
await buffer.put(big_num) # 放入缓冲区
if self.print_log:
print('[{}] {} is Produced'.format(name, big_num))
await asyncio.sleep(0)
async def main(self):
buffer = asyncio.Queue() # 定义缓冲区
jobers = [] # 工作列表
# 将生成者和消费者都加入工作列表
for i in range(self.consumer_num):
# 给消费者传入公共缓冲区和该消费者名字
jobers.append(asyncio.create_task(self.consumer(buffer, 'Consumer' + str(i + 1))))
for i in range(self.producer_num):
# 给消费者传入公共缓冲区和该消费者名字
jobers.append(asyncio.create_task(self.producer(buffer, 'Producer' + str(i + 1))))
for j in jobers:
# 打工人开始上班了
await asyncio.gather(j)
if __name__ == '__main__':
start_time = time.perf_counter() # 时间计数
pc_model = Producer_Consumer_Model(c_num=2, p_num=2, size=100, is_print=False)
asyncio.run(pc_model.main()) # 开启协程服务
end_time = time.perf_counter()
print("此次程序耗时:【{:.3f}】秒 ".format(end_time - start_time))
其中有几个细节要注意,主函数入口中的asynico.run是必写的;是可以通过迭代的方式将协程任务依次传给asyncio.gather()的,await asyncio.wait_for(buffer.get(), timeout=0.5)中的timeout大小自行决定,尽量不要设置的太小,否则不敢保证因为缓冲区暂时空闲造成消费者饥饿而退出程序,其实还是要看程序规模和计算算法而定,这里只是提供整体框架和思路,触类旁通嘛。
很高兴在午夜刚好到来的时候完成。
PS:由衷感谢本文中提及的文章和视频创作者的支持和启发!
欢迎读者在评论区和我交流!在此虚心接受各路大佬批评指正。
最后
以上就是飘逸心锁最近收集整理的关于Python 分布与并行 asyncio实现生产者消费者模型的全部内容,更多相关Python内容请搜索靠谱客的其他文章。








发表评论 取消回复