一、生产者消费者模型介绍
1.1 为什么需要使用生产者消费者模型
生产者是指生产数据的任务,消费者是指消费数据的任务。当生产者的生产能力远大于消费者的消费能力,生产者就需要等消费者消费完才能继续生产新的数据,同理,如果消费者的消费能力远大于生产者的生产能力,消费者就需要等生产者生产完数据才能继续消费,这种等待会造成效率的低下,为了解决这种问题就引入了生产者消费者模型。
1.2 如何实现生产者消费者模型
进程间引入队列可以实现生产者消费者模型,通过使用队列无需考虑锁的概念,因为进程间的通信是通过队列来实现的;
生产者生产的数据往队列里面写,消费者消费数据直接从队列里面取,这样就对实现了生产者和消费者之间的解耦。
生产者 -- > 队列 <--消费者
二、Queue实现生产者消费者模型
2.1 消费者生产者模型代码
from multiprocessing import Process, Queue
import time
# 消费者方法
def consumer(q, name):
while True:
res = q.get()
# if res is None: break
print("%s 吃了 %s" % (name, res))
# 生产者方法
def producer(q, name, food):
for i in range(3):
time.sleep(1) # 模拟生产西瓜的时间延迟
res = "%s %s" % (food, i)
print("%s 生产了 %s" % (name, res))
# 把生产的vegetable放入到队列中
q.put(res)
if __name__ == "__main__":
#创建队列
q = Queue()
# 创建生产者
p1 = Process(target=producer, args=(q, "kelly", "西瓜"))
c1 = Process(target=consumer, args=(q, "peter",))
p1.start()
c1.start()
# p1.join()
# q.put(None)
print("主进程")2.2 执行结果
2.2.1 直接执行上面的代码的结果
直接执行会出现一个问题就是生产者生产完了,没有向消费者发送一个停止的信号,所以消费者一直会一直阻塞在q.get(),导致程序无法退出。
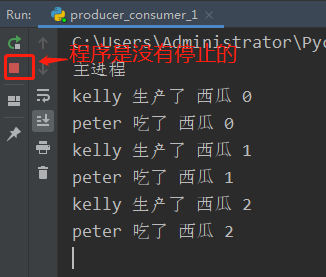
为了解决上面的问题,让消费者消费完了生产者的数据之后自动退出,就需要在生产者进程介绍的时候往队列里面put一个结束信号,消费者拿到这个信号,就退出消费进程。
主要是两个地方修改 ,把下方代码的注释打开就可以实现消费者消费完接收到生产者的结束信号就退出消费者进程了。
def consumer():
if res is None: break
if __name__ == "__main__":
p1.join()
q.put(None)2.2.2 把注释打开后的运行结果
把注释打开后,消费者拿到了生产者发送的结束信号,可以正常退出程序了。
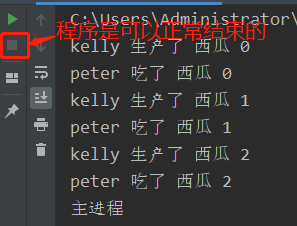
但如果有n个消费者,就需要发送n个结束信号,这种方式就不是那么简洁,像下面的代码这样:
from multiprocessing import Process, Queue
import time
# 消费者方法
def consumer(q, name):
while True:
res = q.get()
if res is None: break
print("%s 吃了 %s" % (name, res))
# 生产者方法
def producer(q, name, food):
for i in range(3):
time.sleep(1) # 模拟生产西瓜的时间延迟
res = "%s %s" % (food, i)
print("%s 生产了 %s" % (name, res))
# 把生产的vegetable放入到队列中
q.put(res)
if __name__ == "__main__":
# 创建队列
q = Queue()
# 创建生产者
p1 = Process(target=producer, args=(q, "kelly", "西瓜"))
p2 = Process(target=producer, args=(q, "kelly2", "香蕉"))
c1 = Process(target=consumer, args=(q, "peter",))
c2 = Process(target=consumer, args=(q, "peter2",))
c3 = Process(target=consumer, args=(q, "peter3",))
p1.start()
p2.start()
c1.start()
c2.start()
c3.start()
p1.join()
p2.join()
q.put(None)
q.put(None)
q.put(None)
print("主进程")
其实我们现在就是生产者生产完数据之后想往队列里面发送一个结束信号,python语言提供了另外一种队列JoinableQueue([maxsize])来解决这种问题
三、JoinableQueue实现生产者消费者模型
3.1 JoinableQueue方法介绍
JoinableQueue([maxsize]) : A queue type which also supports join() and task_done() methods
q.task_done():消费者使用此方法发出信号,表示q.get()的返回项目已经被处理。
q.join():生产者调用此方法进行阻塞,直到队列中所有的项目均被处理;阻塞将持续到队列中的每个项目均调用q.task_done()方法为止。
3.2 JoinableQueue实现生产者消费者模型源码
from multiprocessing import Process,JoinableQueue
import time
# 消费者方法
def consumer(q, name):
while True:
res = q.get()
if res is None: break
print("%s 吃了 %s" % (name, res))
q.task_done() # 发送信号给q.join(),表示已经从队列中取走一个值并处理完毕了
# 生产者方法
def producer(q, name, food):
for i in range(3):
time.sleep(1) # 模拟生产西瓜的时间延迟
res = "%s %s" % (food, i)
print("%s 生产了 %s" % (name, res))
# 把生产的vegetable放入到队列中
q.put(res)
q.join() # 等消费者把自己放入队列的所有元素取完之后才结束
if __name__ == "__main__":
# q = Queue()
q = JoinableQueue()
# 创建生产者
p1 = Process(target=producer, args=(q, "kelly", "西瓜"))
p2 = Process(target=producer, args=(q, "kelly2", "蓝莓"))
# 创建消费者
c1 = Process(target=consumer, args=(q, "peter",))
c2 = Process(target=consumer, args=(q, "peter2",))
c3 = Process(target=consumer, args=(q, "peter3",))
c1.daemon = True
c2.daemon = True
c3.daemon = True
p_l = [p1, p2, c1, c2, c3]
for p in p_l:
p.start()
p1.join()
p2.join()
# 1.主进程等待p1,p2进程结束才继续执行
# 2.由于q.join()的存在,生产者只有等队列中的元素被消费完才会结束
# 3.生产者结束了,就代表消费者已经消费完了,也可以结束了,所以可以把消费者设置为守护进程(随着主进程的退出而退出)
print("主进程")
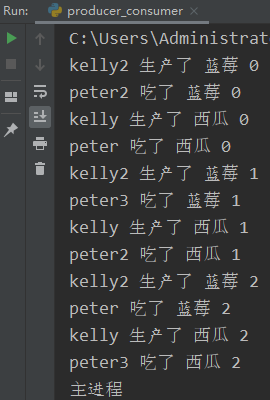
3.3 运行结果
通过运行结果可以看出,生产者没有手动发送结束信号给消费者,而是通过JoinableQueue队列的方式也实现了生产者消费者模型。
最后
以上就是自信冰淇淋最近收集整理的关于python多进程下的生产者和消费者模型一、生产者消费者模型介绍三、JoinableQueue实现生产者消费者模型的全部内容,更多相关python多进程下内容请搜索靠谱客的其他文章。








发表评论 取消回复