Light GBM
a基本原理:
基本原理同XGBoost、GBDT决策树相同,属于在XGBoost的基础上的再一次的提升。在精度上和GBDT、XGBoost一致或更优的情况下,效率上大幅领先于XGBoost和GBDT。用多个回归树将来拟合训练集,拟合好的模型需要做到多个回归树的结果之和训练集的结果一致,将该模型保存起来,之后只需要将要预测的数据再过一遍模型,即可得到预测数据结果。
b算法原理:
对比GBDT和XGBoost来说,不需要通过所有样本计算信息增益了,而且内置特征降维技术,所以更快。
Light GBM会选取梯度较大的样本来计算信息增益,对于梯度小的样本则会选取其中的一部分,对其带来的信息增益进行放大,相当于减少了一部分梯度小的样本损失的影响。
假设选出梯度较大的样本占比a%,梯度小的样本占比b%,那么将选出来的b%个梯度小的样本的信息增益扩大到1-a/b倍。
Light GBM拥有的特征降维技术可以合并那些冲突小的稀疏特征。如可以将特征矩阵[1,nan,1,nan,1]和特征矩阵[nan,1,nan,1,nan]合并为特征矩阵[1,2,1,2,1]
c方法优缺点:
Light GBM存在的优点也可以理解成XGBoost和GBDT存在的缺点,主要有以下两点:
-
占用的内存更低,只保存特征离散化后的值,而这个值一般用8位整型存储就足够了, 内存消耗可以降低为原来的1/8。
-
LightGBM牺牲了一部分切分的精确性来提高切分的效率,但是对损失的精确度有又有用 放大信息增益的方法来弥补,所以最终的准确率几乎没有变化,但是运行效率大大提升。
d算法入口:
Sklearn里面没有Light BGM集成模型,但是网上有一个Light BGM模块,需要安装才能使用
pip install lightbgm


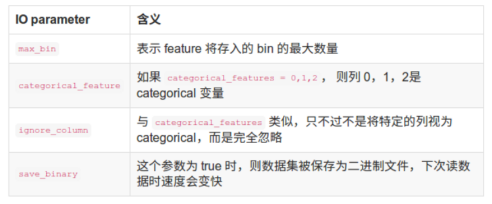
e实例参考:
# -*- coding: utf-8 -*-
'''
建立Light GBM决策树,并预测
'''
from sklearn.datasets import make_hastie_10_2
import lightgbm
def change_y1(y): # 转化label的值,由原来的[-1,1]为[0,1]
for i in range(len(y)):
if y[i] == -1.0:
y[i] = 0.0
return y
def change_y2(y): # 转化label的值,由原来的[-1,1]为[0,1]
for i in range(len(y)):
if y[i] >= 0.5:
y[i] = 1.0
else:
y[i] = 0.0
return y
# 使用make_hastie_10_2随机生成一组十维的数据X,和对应的输出值y,共12000条
X, y = make_hastie_10_2(random_state=0)
y = change_y1(y)
X_train, X_test = X[:4000], X[4000:8000]
y_train, y_test = y[:4000], y[4000:8000]
lgb_train = lightgbm.Dataset(X_train, y_train)
lgb_test = lightgbm.Dataset(X_test, y_test, reference=lgb_train)
yy = y[8000:]
# 配置基本参数
params = {
'task': 'train',
'booster': 'gbdt',
'objective': 'binary',
'learning_rate': 0.5, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': -1, # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
'max_depth': 4, # 最大深度
}
# 迭代拟合再预测
lgb = lightgbm.train(params=params, train_set=lgb_train, num_boost_round=100,
valid_sets=lgb_test)
ypred = lgb.predict(data=X[8000:])
ypred = change_y2(ypred)
error = 0
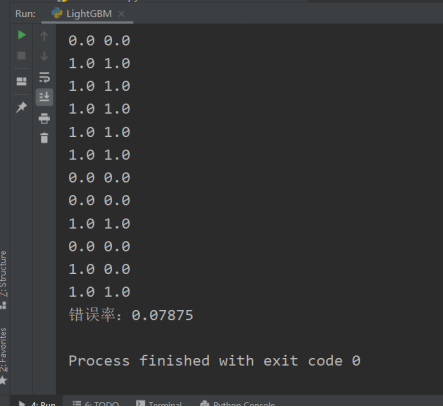
for i in range(ypred.shape[0]): # 输出测试数据所有的预测和真实值
print(ypred[i], yy[i])
if ypred[i] != yy[i]:
error += 1
print('错误率:{}'.format(error / ypred.shape[0]))输出结果如下
f参考文献:
无痛看懂LightGBM原文 https://zhuanlan.zhihu.com/p/89360721
机器学习 集成学习各算法-gbdt,xgboost,lightgbm比较及优缺点特征总结 https://blog.csdn.net/a1272899331/article/details/104714892/?utm_term=lightGbm%E7%9A%84%E4%BC%98%E7%BC%BA%E7%82%B9
LightGBM——提升机器算法(图解+理论+安装方法+python代码)https://blog.csdn.net/huacha__/article/details/81057150
LightGBM介绍及参数调优 https://www.cnblogs.com/jiangxinyang/p/9337094.html
LightGBM官方文档 https://lightgbm.readthedocs.io/en/latest/index.html
最后
以上就是陶醉芒果最近收集整理的关于趋势预测方法(八)Light GBM_决策树Light GBM的全部内容,更多相关趋势预测方法(八)Light内容请搜索靠谱客的其他文章。



![客户贷款逾期预测[1]-逻辑回归模型任务代码:遇到的问题 参考](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)




发表评论 取消回复