AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
数据预处理、预测问题类型、训练预测集划分、模型选择
一、背后的技术
AutoGluon是一个Automl框架(Automl:自动对数据抽取特征并进行模型训练,其目的是尽量在不需要人的帮助下对输入进行特征的提取,选取适合的机器学习模型,对它进行训练)
目前市面上有多款Automl的框架,大部分Automl框架是基于超参数搜索技术,就是在数十或数百个超参数的候选中选取一个比较好的模型,希望通过这样避免人工调参。
Autogluon设计思路:想避免超参数的搜索,从而可以在相同的时间可以训练多个不一样的模型。
依赖于融合多个无需超参数搜索的模型,训练数10个臭皮匠希望合在一起打败诸葛亮
二、技术
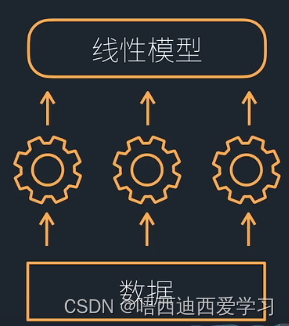
1、stacking
在同一份数据上训练多个模型,模型输出进入线性模型,得到最终的输出。线性权重训练得到。
2、k则交叉bagging
bagging是训练同类型模型,采用不同初始权重或不同数据块,最后做平均。
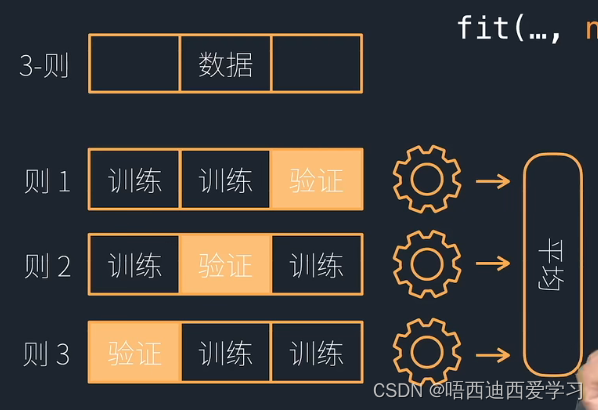
fit(… , num_bag_folds=3),那么就是对stacking中的每个模型,对它做3则交叉bagging。
3、多层stacking
将多个模型的输出和数据合并起来再做一次stacking,也就是在上面再训练多个模型,然后用一个线性模型得到一个输出。
防止过拟合,多层stacking往往是要配合k-则交叉bagging使用的,也就是这里的每个模型是k个模型的bagging,stacking的输出是指每个bagging模型的输出它对应的验证集上的输出的合并。
在autogluon里可以通过num_stake_levels=1和num_bag_folds=3来选择额外使用一次stacking,而且每个模型使用3则交叉bagging,因为这两个选项都会额外增加计算开销,所以需要用户在计算资源充分而且需要高精度模型的时候手动置零。
对结构化数据(csv)的自动ML。
1、集成多个模型堆叠分层训练,比寻找最好的更高效
2、评估多个AutoML平台
提供模型选择、集成、调参、特征工程、数据预处理、数据分离等策略。
自动识别数据类型并数据预处理。
使用
模型中的数据预处理:
预测问题类型: binary, multi-class classification or regression
数据预处理: model-agnostic preprocessing:文本数字等分类、
model-specific preprocessing
可以先自己对数据进行更好的预处理再调用。
API
1 from autogluon import TabularPrediction as task
2 predictor = task.fit("train.csv", label="class")
3 predictions = predictor.predict("test.csv")
最后
以上就是爱撒娇黑米最近收集整理的关于AutoGluon-Tabular: Robust and Accurate AutoML for Structured DataAutoGluon-Tabular: Robust and Accurate AutoML for Structured Data的全部内容,更多相关AutoGluon-Tabular:内容请搜索靠谱客的其他文章。






![客户贷款逾期预测[1]-逻辑回归模型任务代码:遇到的问题 参考](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)

发表评论 取消回复