文章链接
0、摘要
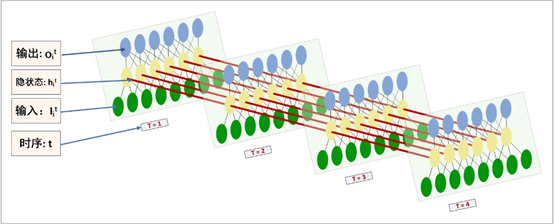
RNN的可解释性具有挑战:用户需要在不同时间步中分析哪些特性是重要的,以便更好地理解模型的行为并信任模型的预测结果。
这就需要有效和扩展性好的可视化方法来揭示隐藏单元与特征之间复杂的多对多关系
论文贡献:
- 提出一个可视分析系统从全局和个体层面来解释用于多维时间序列预测的RNN模型
- 提出一种评估隐藏单元响应的方法,通过度量不同特征选择如何影响隐藏单元的输出分布
- 基于响应嵌入向量聚类隐藏单元和特征
使用空气污染预测案例证明方法的有效性
1、引言
目的:
- 帮助专家根据现有的领域知识了解模型的行为是否证实了某些假设,从而增强对预测的可信度辅助决策
- 通过探索不同的案例识别之前没发现的模式,进而丰富专家的领域知识
- 理解RNN模型可以帮助模型设计者选择合适的模型结构和超参数
挑战:
由于输入序列的高维性使得难以发现特征与隐藏单元之间的关系——不同时间步的不同特征具有关联,传统方法不适用,因为没有揭示特征重要性如何随时间变化
分析这种复杂的时序多维数据需要一种有效的可视化设计,它可以同时揭示跨维(cross-dimension)数据之间的关系和模型的时序行为
论文提出一个可视分析系统MultiRNNExplorer,帮助领域专家从两个方面理解高维时序预测中的RNN模型——模型机制和特征重要性
为了理解模型机制,计算了隐藏单元和特征的整体响应,并为隐藏单元和特征生成响应嵌入向量
然后分别对隐藏单元和特征进行聚类,揭示模型捕获的高层知识
为了度量特征重要性,计算给定情况下所有时间步所有特征的梯度
设计可视化界面允许用户交互式探索模型行为
论文贡献:
- 一种用于评估神经元对多维时序数据响应的方法,即通过度量不同输入特征范围内隐藏单元的响应分布
- 一个可视分析系统帮助专家探索、解释和对比多维时序数据中的RNN模型
- 多个空气污染数据集的案例分析证明系统的有效性和探索过程获得见解
2、相关工作
-
RNN
vanilla RNN
Long Short Term Memory LSTM
Gate Recurrent Unit GRU——update gate、reset gate
bidirectional RNN
每个输入维度都具有一定的信息量,通常代表一个可解释的因素,分析哪些特征对预测结果影响最大很重要
用户需要探索和理解隐含单元如何随时间演化,以此揭示RNN模型的潜在工作机制
论文提出的MultiRNNExplorer系统能够更好的理解模型和解释RNN模型,尤其是当模型的输入是多变量的 -
机器学习可解释性
两大分类:model reduction and feature contribution 模型简化和特征贡献
模型简化——学习一个代理模型来近似原始的复杂模型,例如:线性回归、决策树
三种简化方法:decompositional, pedagogical, and eclectic 分解、指导和混合
a) 分解型:模型依赖,主要简化原模型,如神经网络的层数和权重
b) 指导型:利用输入、输出信息来模拟原始模型
c) 混合型:前两种方法的组合
代理模型简洁容易理解,但是它是否真实反映了原始模型的行为有待进一步考究
敏感性分析方法帮助用户理解输入特征和输出预测之间的关系
为每个特征分配一个重要性分数表示它对最终预测的影响
部分依赖图Partial Dependence Plot PDP——描述特征值的变化如何影响预测
基于博弈论的shapley value的SHAP方法——与参考数据点相比,计算数据实例的特征敏感性(求每一维特征的shapley value值,值越大对目标函数的影响越正向,值越小对目标函数的影响越负向)
局限性:计算量大理解隐藏层的行为:
探索不同序列集中隐藏细胞的激活值
LSTMVis分析、对比单个细胞激活值的变化,分析不同细胞可能捕获不同时变的语言模式
RNNVis描述了隐藏单元和输入单词的共聚类模式
Seq2SeqVis主要关注Seq2Seq模型
RetainVis允许专家分析电子医疗数据
论文通过揭示隐含单元对不同特征的激活敏感性,并高亮随着时间的推移哪些特征对最终预测的影响最大
3、应用和模型
- 应用
本文针对多变量时序数据的回归任务,即目标位置目标污染物的空气污染预测
目标位置:香港16个空气质量监测站点位置
目标污染物:5种污染物,即PM2.5、PM10、SO2、NO2、O3
训练目的:预测每个站点目标污染物的值 - 数据描述
时间粒度:小时
区间:2015年1月1日到2018年12月31日
气象和污染物观测值

两类输入特征——空气污染、气象(7+8)
将目标位置周围的区域划分为不同的空间分区,并将每组内所有监测站点的监测值进行聚合生成特征,如图5B所示。
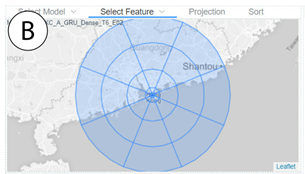
以目标位置为圆心,划分同心圆,半径分别是10km/30km/100km/200km/300km
每个圆划分8个扇区,共有40个区域
对于每个区域,使用对应区域内空气污染和气象的监测数据(包括16个目标站点)作为特征
如果一个区域有多个监测站,则使用平均值作为特征
每个特征用一个三元组进行表示(distance,direction,feature_type) -> (10km,E,NO2)
对于每个时间步,使用一个向量来表示所有的特征,其中每个维度表示一个特征三元组58(7+8)=600维

- 模型描述
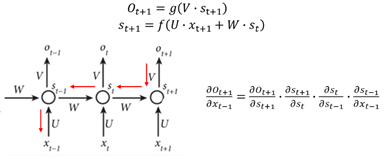
RNN将固定长度T的序列作为输入:
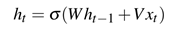
W、V权重矩阵、σ是tanh函数将隐藏单元的输出约束至(-1,1)
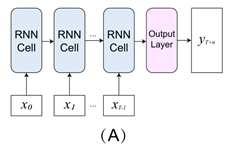
RNN:RNN的输出直接作为模型预测结果
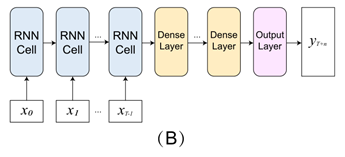
RNN+Dense:RNN输出需要经过全连接层计算后才作为预测结果
4、系统设计
目标:
G1:理解RNN模型在高维预测中的行为/机制
G2:理解特征重要性
G3:支持案例探索
- 分析任务
- T1:编码隐藏单元统计信息——隐含单元是模型中间结果的直接反映,对于揭示模型捕获的信息至关重要
- T2:在多个层级上度量特征重要性——整个数据集中特征重要性的总览(overview level),聚焦单个案例(case)中的重要性(individual level)
- T3:分析特征和隐藏单元之间的响应——度量特征与隐藏单元之间的响应是揭示模型捕获模式的关键因素。针对特征与隐藏单元复杂的多对多关系,应该进行聚类,以减轻用户的负担
- T4:支持时序分析——RNN模型可以捕获时序依赖关系,展示预测过程中保留和丢弃的信息有助于用户更好理解模型如何利用时序信息。此外,用户可以识别导致预测发生重大变化的关键时间步
- T5:识别数据簇和异常点——通过数据簇和异常点来获取数据的概述,提供具体的例子供用户进一步探索感兴趣的数据。结合领域知识,用户可通过检查具有不同预测结果的异常点来检测模型是否训练出错
- T6:基于案例探索模型行为——系统需要允许用户探索在个别情况下的模型行为,如建立特征趋势和特征重要性趋势之间的关联。因为每种案例都会将数百个时序特征作为输入,因此需要进行有效的总结。
- 系统概览
系统包含3个模块:预处理、分析、可视化
预处理模块:产生需要分析的原始数据,包括计算响应关系和特征重要性
分析模块: 聚类、投影、排序
可视化模型:集成不同视图支持从不同角度对模型进行交互式解释和推理
5、模型解释
如何分析特征和隐藏单元之间的关系
论文提出一个有效的方法计算每个隐藏单元对特定一个特征变化的敏感程度,并应用聚类方法对响应关系进行模式分组
为用户提供一个概览,即模型如何对不同的特征进行分类和将特征值调整到什么范围会最大程度上影响模型行为
引入一种基于梯度的方法来识别影响预测的最重要特征
从另一个视角分析特征重要性如何随时间变化
- 隐藏单元和特征之间的关系
为了测量特征变化对隐藏单元的影响,一种常见的方法是调整特征值并测量与原始数据相比隐藏单元分布的变化
调整特征值的方法——耗时、特征之间相关则不适用
直接采用比较不同特征值范围的隐藏单元分布
隐藏单元分布: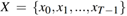
模型输入: 
不同时间步的隐藏单元输出: 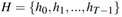
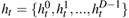
对于所有的训练样本 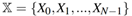
聚合到一个特征向量集 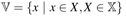
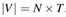
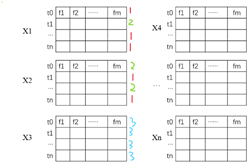
对一个特征按照分位数(四分之一、四分之三)将特征向量集分成3组
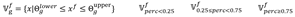
关系强度计算:
通过度量不同特征值范围的隐藏单元分布之间的距离来计算隐藏单元与特征的关系强度 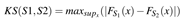
Two-sample Kolmogorov Smirnov 两组样本柯尔莫哥洛夫-斯米尔诺夫适合度检定用来分析两组数据分布型(distribution)之差异
H0假设:两个分布存在显著性差异。
H1假设:两个分布不存在显著性差异。
通过累计分布函数计算KS值。
若KS值大于给定显著性水平下的取值,则接受H0假设,即两个分布存在显著性差异;
若KS值小于给定显著性水平下的取值,则拒绝H0假设,接受H1假设。
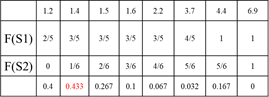
求解两组数据的累计分布函数的最大值,作为两个分布的距离
如:S1 : 1.2, 1.4, 1.2, 3.7, 4.4 S2: 1.6, 1.5, 3.7, 6.9, 2.2, 1.4
随机变量X的累计分布函数: 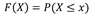
在给定显著性水平α下的拒绝系数 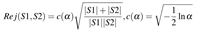
两个分布的距离: 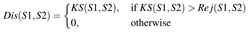
隐藏单元与特征的响应关系: 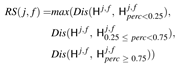
取最大值的原因—如有两组数(0.1, 0.08, 0.05) (0.03, 0.04, 0.05) 选择差异最大的体现敏感性
- 隐藏单元和特征的聚类
由于隐藏单元成百上千,向用户展示每个隐藏单元的激活分布是无效的
一般解决方法是采样或聚类
本文采用聚类,因为它可以较好的保留隐藏单元对特征的响应关系,同时很好的总结模型捕获的信息
根据上述响应关系的计算,构造一个D*M的二维表

特征响应嵌入向量: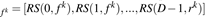
一列
隐藏单元响应嵌入向量: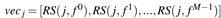
一行
使用谱系共聚类聚类Spectral Co-clustering(SCoC)、凝聚层次聚类Agglomerative Clustering(AC)、 谱聚类Spectral Clustering(SC)
使用轮廓系数衡量聚类质量 取值(-1,1),值越高聚类越有效
使用二部图进行聚类结果展示,能够揭示隐藏单元和特征之间的多对多抽象关系
- 局部特征重要性
受到机器学习反向传播的启发,根据局部梯度进行个体层级分析,在NLP分析任务中被用来表现单词的显著性
单个样本的特征重要性
一个特征在一个给定时间步上对最终预测的贡献: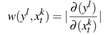
6、可视化设计
可视分析系统包含6个视图:配置面板B、隐藏单元对特征的响应A、特征重要性C、投影视图E、个体视图D
- 聚类视图——概览展示了隐藏单元和特征之间的响应关系
隐藏单元表示成分布、特征表示成图标
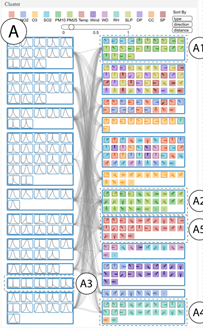
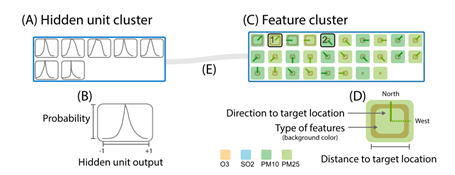
左侧A:隐藏单元分布——每行表示一个簇,横轴输出的取值范围(-1,1),纵轴为取值的概率值 用户可以观察和对比不同隐藏单元的激活分布模式
右侧C:特征图标——每行表示一个特征聚类,颜色编码特征类型(feature_type),图标中的线段编码相对于目标站点的方向(direction),内部正方形半径编码与目标站点的距离(distance)
两个视图之间连线的粗细编码响应强度大小
2) 特征重要性视图
特征重要性视图允许用户探索对模型输出的特征贡献
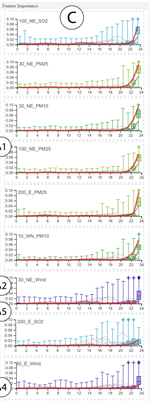
箱线图:整体统计概览
横轴是时间
纵轴是重要性得分,灰色的线是所有样本的数值,将所有数据的重要性得分根据时间步进行统计,画成箱线图
当最大值比上四分位数大很多时,会导致箱线图过于扁平,为了解决此问题,设置一个阈值,如最大值超过阈值,则采用一个类似钻石的图元编码,钻石的透明度编码与阈值的差异
将全部时间步的平均得分求和作为特征的整体重要性
所有特征的图标根据整体重要性从上到下排序——目前只展示前10个特征
- 投影视图
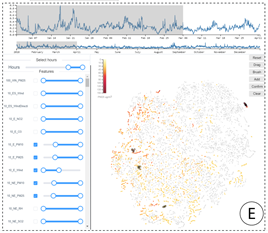
为了帮助用户对聚类和异常值有一个整体的概览,设计了一个投影视图,支持不同的交互,如放大、刷选,允许用户选择一个特定的数据子集进行分析
一个点表示一个案例,使用t-SNE投影
对每个样本,计算将所有时间步的特征簇的重要性作为t-SNE的输入向量,如特征簇共10个,则每个样本的输入由一个10*t维的向量组成
使用连续的颜色编码每个案例的模型输出值
4) 个体视图
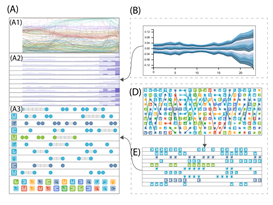
A1:特征趋势视图 Feature Trend Chart
A2:簇重要性视图 Cluster Importance Chart
A3:主要特征列表 Top Feature List
从左到右的横轴编码时间
A1:特征值如何随着时间变化,纵轴编码归一化的值(0,1),每条线代表一个特征,线的颜色与聚类视图中的分类一致
A2:展示特征簇梯度的时变,一行编码一个特征簇,排列顺序与聚类视图一致,每个时间步的柱状图的高度和颜色均表示对应特征簇的平均梯度值
当梯度值较大超过每行的高度时,则在该处叠加一个更深的柱,表示该处的梯度值较大
可选方案——主题河流(B),但是簇与簇之间难以进行对比分析,当簇较多时需要更多的展示空间
A3:D图x轴表示时间,y轴表示特征重要性排序,使用连线将相邻时间步中相同特征进行连接
E图每一行表示一种特征类型,在对应时间步中将出现在前N个重要性排序的特征绘制一个图标
E图进一步简化成A3,即将同一个特征中连续出现的图标用一个灰色的条形表示,同时使用竖线区分时间步,除了展示前N个外,用户还可以点击下方的图标展开查看相应的特征分布
- 交互和连接
跨视图高亮:特征、特征聚类、案例
个体视图和特征重要性视图之间的连接
最后
以上就是高大银耳汤最近收集整理的关于Visual Interpretation of Recurrent Neural Network on Multi-dimensional Time-series Forecast的全部内容,更多相关Visual内容请搜索靠谱客的其他文章。








发表评论 取消回复