好事达保险索赔预测 Allstate Claims Severity (xgboost)
在这次Machine Learning中,我用了一个在学校做的一个项目来进行实战,当时老师给的数据还是比较小的,但是也还好哈哈哈,当然这个也在kaggle上有一个competition - > Allstate Claims Severity
在这次中,我希望我能学习到xgboost的算法,这个多次在kaggle斩获第一的算法,希望这次以后,能对xgboost有更加清晰的认识,也希望能在之后的实战中能得到更好的结果
如果想了解更多的知识,可以去我的机器学习之路 The Road To Machine Learning通道
目录
- Overview
- Data
- Read In Data
- IsNULL
- Continuous vs Caterogical features
- Data Processing
- 连续值特征
- 离散型特征
- 特征工程
- 建立模型
- LinearRegression
- LinearSVR
- GBDT
- XGBOOST
Overview
When you’ve been devastated by a serious car accident, your focus is on the things that matter the most: family, friends, and other loved ones. Pushing paper with your insurance agent is the last place you want your time or mental energy spent. This is why Allstate, a personal insurer in the United States, is continually seeking fresh ideas to improve their claims service for the over 16 million households they protect.
Allstate is currently developing automated methods of predicting the cost, and hence severity, of claims. In this recruitment challenge, Kagglers are invited to show off their creativity and flex their technical chops by creating an algorithm which accurately predicts claims severity. Aspiring competitors will demonstrate insight into better ways to predict claims severity for the chance to be part of Allstate’s efforts to ensure a worry-free customer experience.

其实简单来说,好事达保险公司不断寻求新的模型改进他们为家庭提供的索赔服务,现在需要创造一个能够准确预测索赔程度的回归模型来调整其技术能力。
好事达目前正在开发预测索赔成本和严重程度的自动化方法。在这一招聘挑战中,Kagglers被邀请展示他们的创造力,并展示他们的技术能力,创造出一种能准确预测索赔严重程度的算法。有抱负的竞争对手将展示洞察更好的方法来预测索赔的严重程度,这是好事达努力的一部分,以确保一个无忧的客户体验。
Data
Each row in this dataset represents an insurance claim. You must predict the value for the ‘loss’ column. Variables prefaced with ‘cat’ are categorical, while those prefaced with ‘cont’ are continuous.
数据集中的每一行表示一个保险索赔。必须预测“loss”列的值。以’cat’开头的变量是离散型变量,而以’cont’开头的变量是连续变量。
Read In Data
首先还是需要导入Package
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings('ignore')
然后读入数据
train = pd.read_csv('data files/train.csv')
test = pd.read_csv('data files/test.csv')
# 为了显示所有的行和列
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns',None)
接着我们就观察一下数据的分布和类型
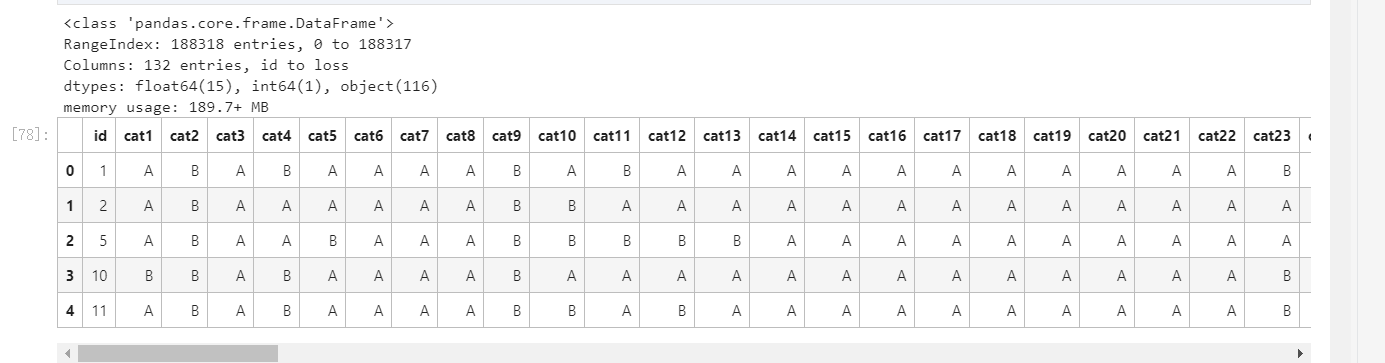
train.info()
train.head()
从下图可以看出来,一共有188318条数据,一共有132个特征,分别从id到loss
IsNULL
pd.isnull(train).values.any()
# False
很好,没有缺失值,我们就不用对数据进行一个缺失值处理了
Continuous vs Caterogical features
刚刚在train.info中大概看到了数据的类型,接着我们现在统计离散型和连续型变量的数目,然后进行分析可以得到,有一些的类型是离散型object,有一些的类型是float64,就是连续型,我们可以根据进行选择去统计一下离散型和连续型变量的数目,并存在两个列表当中
# 统计离散型变量的数目
cat_features = list(train.select_dtypes(include=['object']).columns)
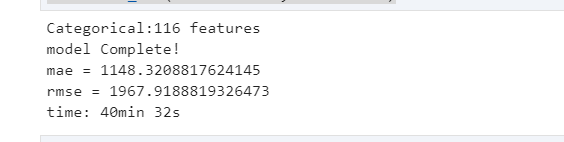
print('Categorical:{} features'.format(len(cat_features)))
# Categorical:116 features
# 统计连续型变量的数目
cont_features = [cont for cont in list(train.select_dtypes(include=['float64']).columns) if cont not in ['loss']]
print('Continuous: {} features'.format(len(cont_features)))
# Continuous: 14 features
我们看到,大概有116个种类属性(如它们的名字所示)和14个连续(数字)属性。
此外,还有ID和赔偿。总计为132列。
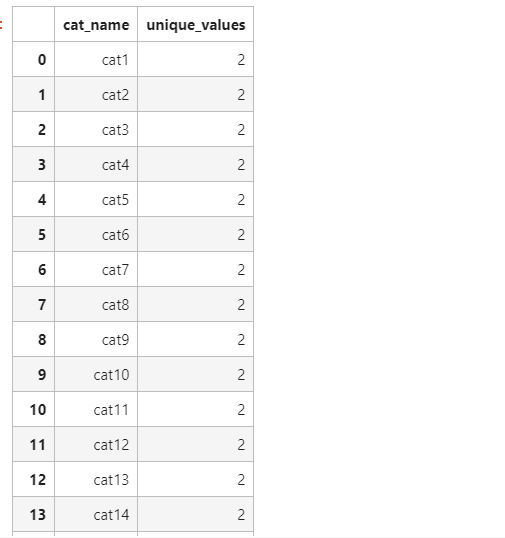
接着,为了对离散型数据更加清楚,我们需要知道他的数目
cat_uniques = []
for cat in cat_features:
cat_uniques.append(len(train[cat].unique()))
uniq_values_in_categories = pd.DataFrame.from_items([('cat_name',cat_features),('unique_values', cat_uniques)])
uniq_values_in_categories
fig, (ax1, ax2) = plt.subplots(1,2)
fig.set_size_inches(16,5)
ax1.hist(uniq_values_in_categories.unique_values, bins=50)
ax1.set_title('Amount of categorical features with X distinct values')
ax1.set_xlabel('Distinct values in a feature')
ax1.set_ylabel('Features')
ax1.annotate('A feature with 326 vals', xy=(322, 2), xytext=(200, 38), arrowprops=dict(facecolor='black'))
ax2.set_xlim(2,30)
ax2.set_title('Zooming in the [0,30] part of left histogram')
ax2.set_xlabel('Distinct values in a feature')
ax2.set_ylabel('Features')
ax2.grid(True)
ax2.hist(uniq_values_in_categories[uniq_values_in_categories.unique_values <= 30].unique_values, bins=30)
ax2.annotate('Binary features', xy=(3, 71), xytext=(7, 71), arrowprops=dict(facecolor='black'))
正如我们所看到的,大部分的分类特征(72/116)是二值的,绝大多数特征(88/116)有四个值,其中有一个具有326个值的特征
Data Processing
用python绘制出了id和loss的图
plt.figure(figsize=(16,8))
plt.plot(train['id'],train['loss'])
plt.title('Loss values per id')
plt.xlabel('id')
plt.ylabel('loss')
plt.legend()
plt.show()
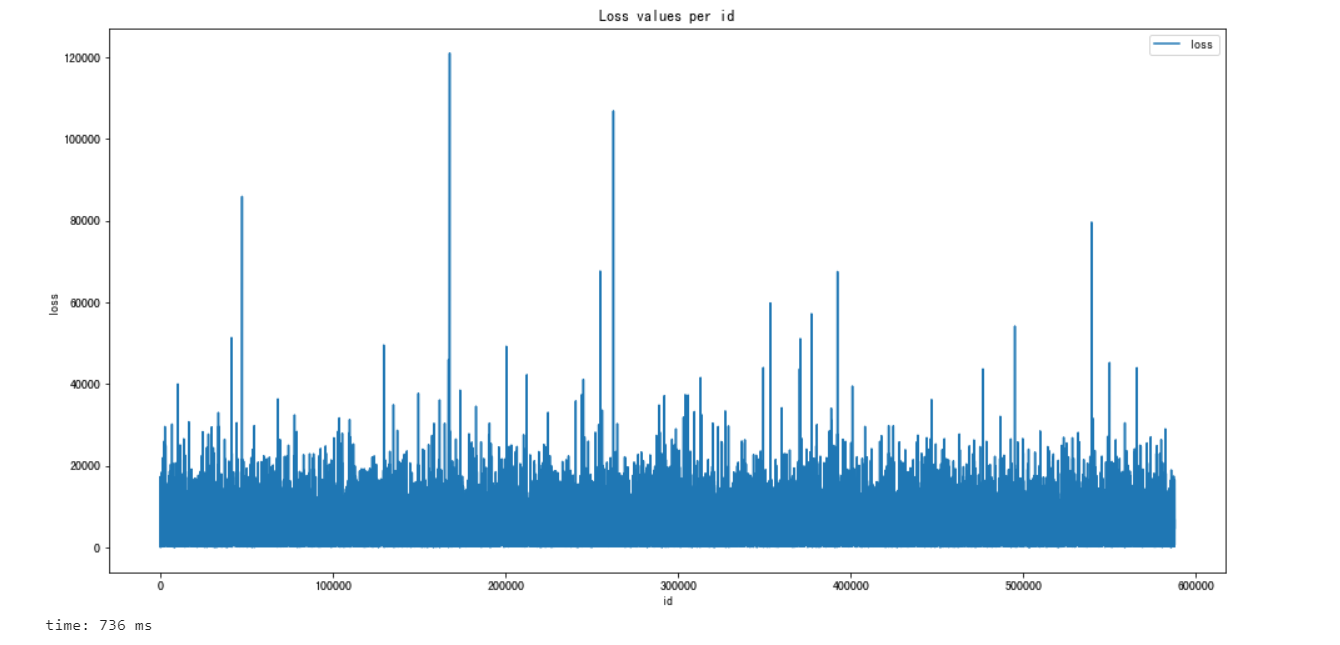
损失值中有几个显著的峰值表示严重事故。这样的数据分布,使得这个功能非常扭曲导致的回归表现不佳
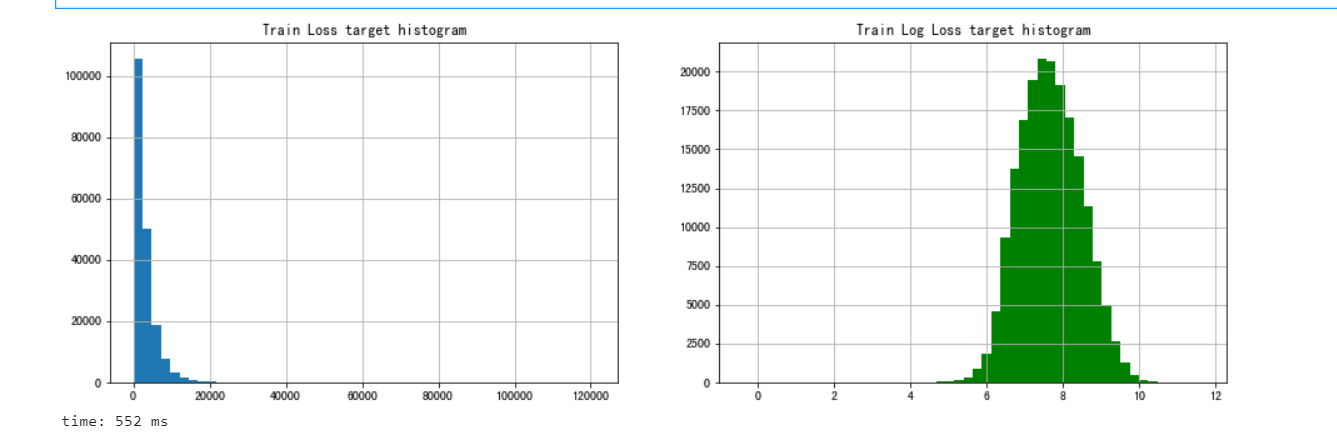
我们还对loss值进行分析,我们发现,loss的图像的分布是不太好拟合的,因为分布的太散了,如果我们对他取对数,会出现类似于正态分布,对数据进行对数变换通常可以改善倾斜,并且会更符合我们的假设
fig, (ax1,ax2) = plt.subplots(1,2)
fig.set_size_inches(16,5)
ax1.hist(train['loss'], bins=50)
ax1.set_title('Train Loss target histogram')
ax1.grid(True)
ax2.hist(np.log(train['loss']), bins=50, color='g')
ax2.set_title('Train Log Loss target histogram')
ax2.grid(True)
plt.show()
连续值特征
# One thing we can do is to plot histogram of the numerical features and analyze their distributions:
train[cont_features].hist(bins=50,figsize=(16,12))
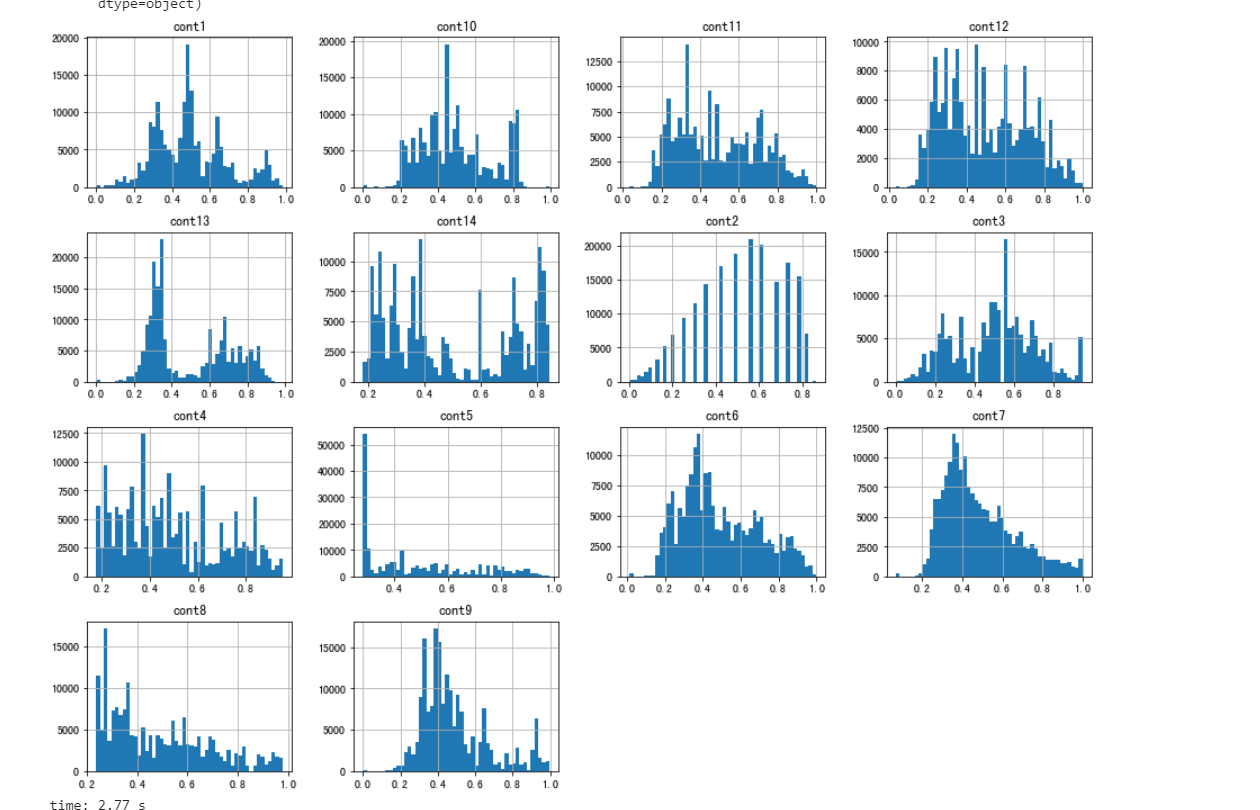
除此之外,还可以得到他们的这些特征的相关性
# 得到各个变量的相关性
plt.subplots(figsize=(16,9))
correlation_mat = train[cont_features].corr()
sns.heatmap(correlation_mat , annot = True)
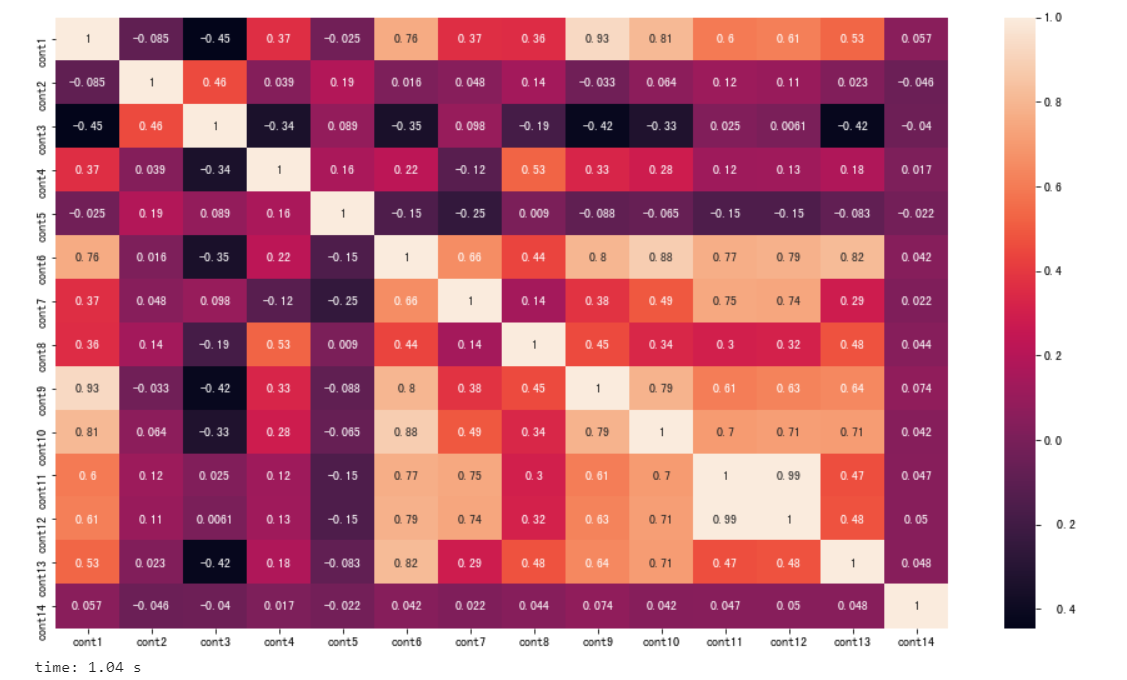
这个时候就可以得到,与loss变量相关的各个连续值的变量的相关性程度
train.corr()['loss'].sort_values()
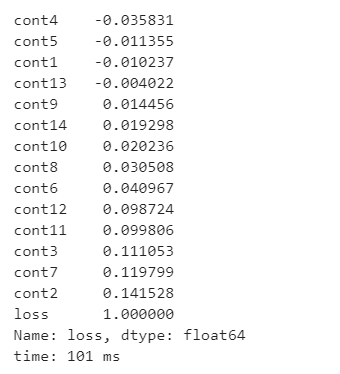
离散型特征
for feature in cat_features:
sns.countplot(x = train[feature], data = train)
plt.show()
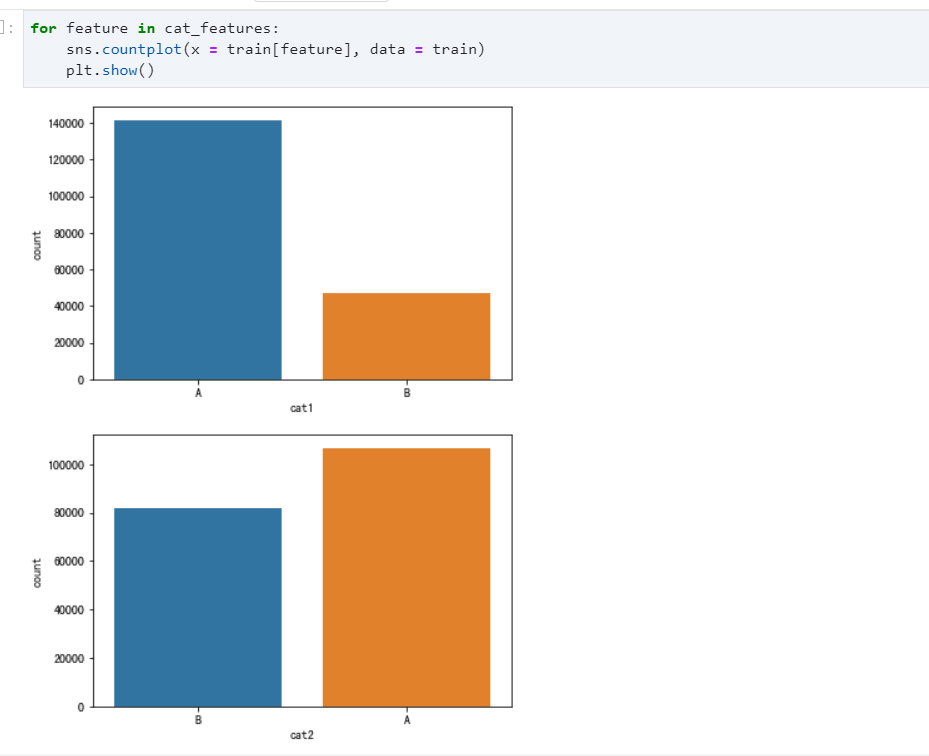
特征工程
我们要对离散型变量进行操作,如果需要建立回归模型,那么需要将所以的离散型变量变为实数型的,因为如果特征值是字符的话有些算法不能直接使用,Linear Regression模型只能处理特征值为实数值的数据,所以对于离散型特征可以将其进行数值化
for c in range(len(cat_features)):
train[cat_features[c]] = train[cat_features[c]].astype('category').cat.codes
接下来我们可以看看,处理后的数据是怎么样的

建立模型
首先还是要划分数据
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
X, y = train[train.columns.delete(-1)],train['loss']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
LinearRegression
我们老师给我的第一个就是线性回归模型,我们来试一下
linear_model = LinearRegression()
linear_model.fit(X_train, y_train)
coef = linear_model.coef_#回归系数
line_pre = linear_model.predict(X_test)
print('SCORE:{:.4f}'.format(linear_mocdel.score(X_test, y_test)))
print('RMSE:{:.4f}'.format(np.sqrt(mean_squared_error(y_test, line_pre))))
print('MAE:{:.4f}'.format(np.sqrt(mean_absolute_error(y_test,line_pre))))

利用线性回归模型,这样对train集进行测试大约得到的分数为48左右,RMSE误差为2076,MAE大约是36左右
在这里顺便也可视化了一下预测的情况
hos_pre = pd.DataFrame()
hos_pre['Predict'] = line_pre
hos_pre['Truth'] = y_test.reset_index(drop=True)
hos_pre.plot(figsize=(18,10))
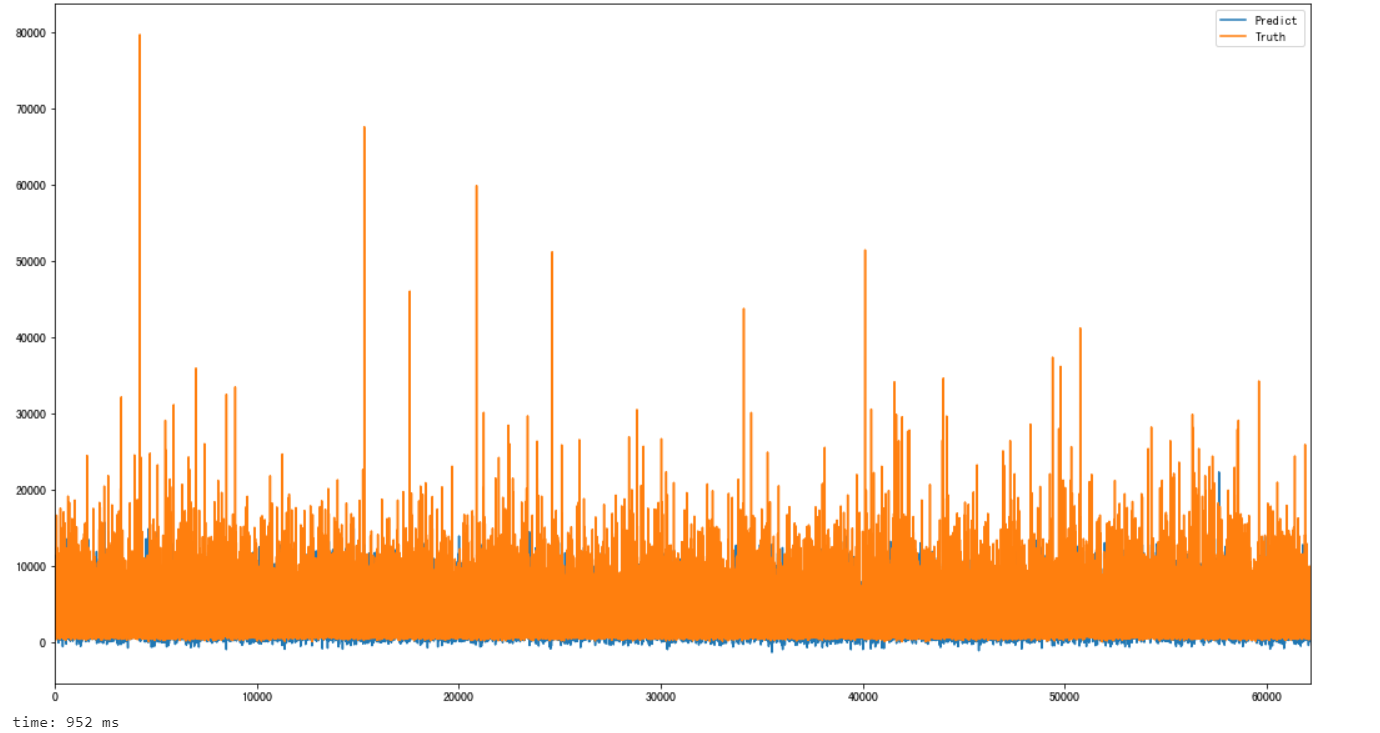
从可视化的结果看出,确实拟合的结果不是那么理想,下面继续寻找模型优化
前面提到过,可以对loss值取对数,然后进行回归模型的测量,这里试一下
X = train[train.columns.delete(-1)]
X = X[X.columns.delete(-1)]
y = train['log_loss']
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=18)
linear_model_loss = LinearRegression()
linear_model_loss.fit(X_train, y_train)
coef = linear_model_loss.coef_#回归系数
predicted = linear_model_loss.predict(X_test)
y_test = np.exp(y_test)
predicted = np.exp(predicted)

最后的结果依然没有那么理想,接下来就试一下其他模型吧
LinearSVR
from sklearn.svm import LinearSVR
X = train[train.columns.delete(-1)]
X = X[X.columns.delete(-1)]
y = train['loss']
X_train, X_test, y_train, y_test = train_test_split(X , y, test_size=0.3, random_state=42)
model = LinearSVR(epsilon=0.0, tol=0.0001, C=1.0, loss='epsilon_insensitive',
fit_intercept=True, intercept_scaling=1.0, dual=True, verbose=0,
random_state=None, max_iter=1000)
model.fit(X_train, y_train)
predicted = model.predict(X_test)
print("Model complete")
print(predicted)
mae = mean_absolute_error(predicted, y_test)
print("RMSE:{:.4f}".format(np.sqrt(mean_squared_error(predicted,y_test))))
print("Training data mean absolute error: ",mae)
可以看出来,比普通的线性回归还是稍微优那么一点点的

GBDT
from sklearn.ensemble import GradientBoostingRegressor as gBR
n_estimators= 100
reg2 = gBR(n_estimators=n_estimators,learning_rate=0.05)
reg2 = reg2.fit(X_train, y_train)
print('model Complete!')
pred = np.exp(reg2.predict(X_test))
print('mae = {}'.format(mae(pred,np.exp(y_test))))
print('rmse = {}'.format(np.sqrt(mse(pred,np.exp(y_test)))))
reg2_full = gBR(n_estimators=n_estimators,learning_rate=0.05)
reg2_full.fit(X,y)
result = pd.DataFrame({
'id':test_id,
'loss':np.exp(reg2_full.predict(test))
})
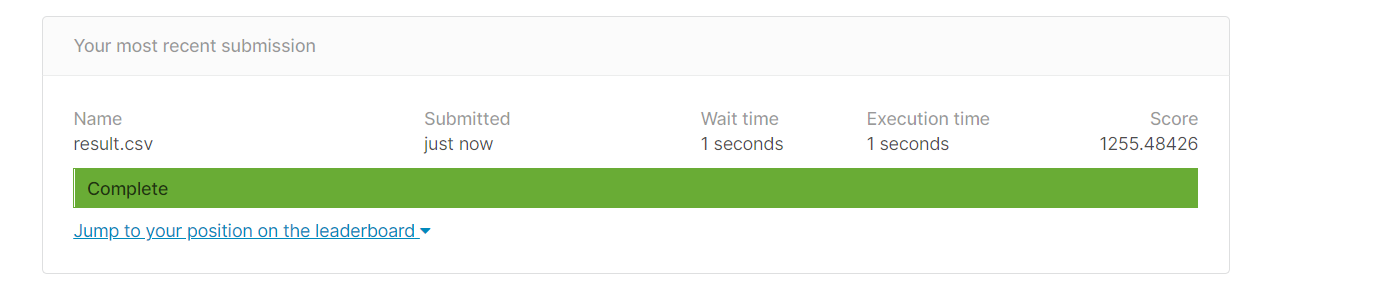
result.to_csv('result.csv',index=False)
这个也还好
XGBOOST
这里就是本次blog的重点了,xgboost,这里就不详细解释xgboost了,感兴趣可以看看终于有人说清楚了–XGBoost算法,下次我会专门写出一篇博客来让我详细理解xgboost,不过实在太麻烦了哈哈哈,现在先给出代码实现吧
reg = xgb.XGBRegressor(n_estimators=1000,learning_rate=0.01)
reg.fit(X_train,y_train)
reg_predict = reg.predict(X_test)
print('mse = {}'.format(mae(reg_predict,y_test)))
wow,我只能说,无论结果多优,运行的时间是真的久,如果你去调参,真要自闭了。。。
这个也就17min,无所谓吧

reg.fit(X,y)
submission = pd.DataFrame({
"id": test_id,
"loss": reg.predict(test)
})
submission.to_csv('Submission3_xgboost.csv', index = False)
如果你用训练的模型去预测,你会发现,得出来的误差居然降低了1000,所以这个是真的好用,但是时间也是真的久哈哈哈哈,而且万一你有哪一部分出现问题,就直接炸裂了哦嘻嘻

如果还没更新,就说明我还在运行中。。。
我改成500次迭代,好像更加优,这时候就是疯狂调参了哈哈

有一说一,最后我拟合出来当今最小的误差的

但是这个足足拟合了我40min。。。真难呀
每日一句
The best preparation for tomorrow is doing your best today.
对明天做好的准备就是今天做到最好!
如果需要数据和代码,可以自提
- 路径1:我的gitee
- 路径2:百度网盘
链接:https://pan.baidu.com/s/1uA5YU06FEW7pW8g9KaHaaw
提取码:5605
最后
以上就是沉默荷花最近收集整理的关于机器学习实战四:好事达保险索赔预测 Allstate Claims Severity (xgboost)OverviewDataRead In DataIsNULLContinuous vs Caterogical featuresData Processing连续值特征离散型特征特征工程建立模型GBDTXGBOOST的全部内容,更多相关机器学习实战四:好事达保险索赔预测内容请搜索靠谱客的其他文章。








发表评论 取消回复