
作者 | Elvis
译者 | 凯隐、夕颜
出品 | AI科技大本营(ID: rgznai100)
【导读】对自然语音处理(NLP)领域而言,2019年是令人印象深刻的一年,本文将回顾2019年NLP和机器学习领域的重要事件。内容 主要集中于 NLP 领域,但也会包括一些与 AI 有关的有趣故事,包括新发布模型、工程成果、年度报告以及学习资源等。
文章较长,将近万字,适合先马后看,静下心来细细研读。
模型与文献????
谷歌AI 提出了 ALBERT 模型,这是 BERT 模型的简化版本,用于语境化语言表示的自监督学习。相较于 BERT,其在模型更加精练的同时更有效地分配了模型的容量。该模型在12个 NLP任务中都达到了最优效果。
ALBERT: https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html
BERT: https://arxiv.org/abs/1810.04805
在今年早些时候,英伟达在一篇流行论文中提出了风格化 GAN(styleGAN),其作为 GAN 的一种可选生成器结构,可以实现图像的风格转换,后续的许多工作在此基础上进一步重新设计了生成器的标准化过程,以适应不同任务。Code2seq 则是其中非常有趣的一篇,其可以通过code的结构化表示来生成自然语言序列,这可以应用到文档或总结的自动摘要。
StyleGAN: https://arxiv.org/pdf/1812.04948.pdf
Code2seq: https://code2seq.org/

在生物医学方面,BioBERT 可以实现生物医学文本挖掘,这是一种基于上下文来从生物医学文本中提取重要信息的方法。
BioBERT: https://arxiv.org/abs/1901.08746
在发布BERT后,Facebook 的研究员们进一步提出了RoBERTa,其引入了新的优化方法来改进BERT,并在各种NLP基准测试上达到了最佳效果。
RoBERTa: https://ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/
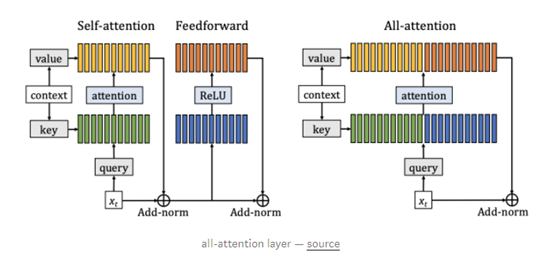
Facebook AI的研究人员最近还发布了一种基于全注意力层(all-attention layer)的方法,用于提高Transformer语言模型的效率,该研究小组的其他工作包括教授人工智能系统如何使用自然语言进行规划。
相关链接:
https://ai.facebook.com/blog/making-transformer-networks-simpler-and-more-efficient/
https://ai.facebook.com/blog/-teaching-ai-to-plan-using-language-in-a-new-open-source-strategy-game/
模型可解释性一直是机器学习和NLP领域的重要课题,这篇文章提供了关于AI可解释性,分类标准,以及未来研究方向的全面综述:
https://arxiv.org/abs/1910.10045
Sebastian Ruder 发表了一篇关于自然语言处理的神经转移学习的论文:https://ruder.io/thesis/
一些研究人员开发了一种在对话上下文中进行情感识别的方法,为生成带情感的对话铺平了道路。另一项相关工作涉及一种名为DialogueGCN的GNN方法来检测对话中的情绪。本论文还提供了代码实现:
https://arxiv.org/abs/1910.04980
https://www.aclweb.org/anthology/D19-1015.pdf
https://github.com/SenticNet/conv-emotion/tree/master/DialogueGCN
谷歌AI量子小组在《自然》杂志上发表了一篇论文,声称他们已经开发出一种比世界上最大的超级计算机还要快的量子计算机。更多的相关实验请戳链接:
https://www.nature.com/articles/s41586-019-1666-5
https://ai.googleblog.com/2019/10/quantum-supremacy-using-programmable.html
如前所述,神经网络的可解释性仍是一个需要改进和提升的领域,本文讨论了注意力作为一种可靠的可解释性方法在语言建模中的局限性:https://arxiv.org/abs/1908.04626
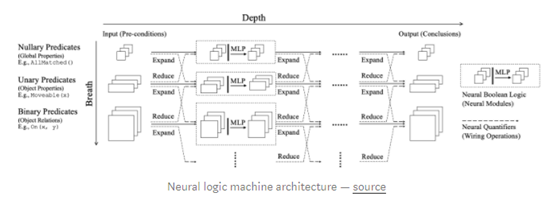
神经逻辑机(Neural logic machine)是一种既能进行归纳学习又能进行逻辑推理的神经符号网络结构。该模型在排序数组和寻找最短路径等任务中表现得非常出色:https://arxiv.org/abs/1904.11694
这是一篇将Transformer语言模型应用于提取和抽象神经文档摘要的论文:https://arxiv.org/abs/1909.03186
研究人员开发了一种侧重于通过对比来建立和训练ML模型的方法。这种技术不需要大量的特征-标签对,而是将图像与以前看到的图像进行比较,以确定图像是否属于某个特定的标签。
https://blog.ml.cmu.edu/2019/03/29/building-machine-learning-models-via-comparisons/
Nelson Liu等人发表了一篇论文,讨论了在预设语境下训练的模型 (如BERT和ELMo)获取的语言知识类型。
https://arxiv.org/abs/1903.08855
XLNet是基于预训练的NLP模型,它在20个任务上相较于BERT都有提升。相关总结请戳链接。
https://arxiv.org/abs/1906.08237
https://medium.com/dair-ai/xlnet-outperforms-bert-on-several-nlp-tasks-9ec867bb563b
来自DeepMind的工作报告了一项广泛的实证调查的结果,该调查旨在评估应用于各种任务中的语言理解模型。这种广泛的分析有助于更好地理解语言模型学习到的内容,从而提高它们的效率。
https://arxiv.org/abs/1901.11373
VisualBERT是一个简单而鲁棒的框架,用于诸如包括VQA和Flickr30K等视觉-语言任务。这种方法通过堆叠Transformer层并结合self-attention来将文本中的元素和图像中的区域进行对齐。
https://arxiv.org/abs/1908.03557
这项工作提供了一个NLP转移学习方法的详细分析比较,以及对NLP领域从业者的指导。
https://arxiv.org/abs/1903.05987
Alex Wang和Kyunghyun提出了一种BERT的实现方法,能够产生高质量、流畅的语言生成器。
https://arxiv.org/abs/1902.04094
https://colab.research.google.com/drive/1MxKZGtQ9SSBjTK5ArsZ5LKhkztzg52RV
Facebook的研究人员发布了XLM的代码,这是一个用于跨语言模型训练的预训练模型。(PyTorch实现)
https://github.com/facebookresearch/XLM
这篇文章全面分析了强化学习算法在神经机器翻译中的应用:
https://www.cl.uni-heidelberg.de/statnlpgroup/blog/rl4nmt/
这篇发表在JAIR上的综述对跨语言单词嵌入模型的训练,验证和部署进行了全面的概述。
https://jair.org/index.php/jair/article/view/11640
The Gradient发表了一篇不错的文章,其详细阐述了强化学习目前的局限性,并提供了一条潜在的分级强化学习的前进道路。很快,其他人又发布了一套优秀的教程来帮助入门强化学习。
https://thegradient.pub/the-promise-of-hierarchical-reinforcement-learning/
https://github.com/araffin/rl-tutorial-jnrr19/blob/master/1_getting_started.ipynb
这篇文章简要介绍了基于上下文的词表示方法。
https://arxiv.org/abs/1902.06006
ML/NLP的创造力和社会性????
机器学习已被应用于解决现实世界的问题,但它也在被以有趣和具有创造性的方式应用着。ML的创造力和任何其他人工智能研究领域一样重要,因为我们的最终目的是建立有助于塑造我们的文化和社会的人工智能系统。
今年年底,Gary Marcus 和Yoshua Bengio 就深度学习、象征性人工智能和混合人工智能系统的想法展开了辩论。
https://www.zdnet.com/article/devils-in-the-details-in-bengio-marcus-ai-debate/
2019年人工智能指数报告最终发布,全面分析了人工智能的现状,可以帮助人们更好地了解人工智能领域的总体进展。
https://hai.stanford.edu/ai-index/2019
常识推理(Commonsense reasoning)仍然是一个重要的研究领域,因为我们的目标是建立不仅能够对提供的数据进行预测,而且能够理解和推理这些决策的人工智能系统。这种技术可以用于会话人工智能,其目标是使智能代理能够与人进行更自然的对话。除了Nasrin Mostafazadeh对常识推理和诸如讲故事和语言理解等应用的讨论, 还可以查看最近这篇关于如何利用语言模型进行常识推理的文章。
https://arxiv.org/abs/1906.02361
激活地图集(Activation Atlases)是谷歌和Open AI的研究人员开发的一种技术,用于更好地理解和可视化神经网络神经元之间发生的交互作用。
https://openai.com/blog/introducing-activation-atlases/

可以看看Geoffrey Hinton和Yann LeCun的图灵奖演讲,他们和Yoshua Bengio一起获得了今年的图灵奖。
https://fcrc.acm.org/turing-lecture-at-fcrc-2019
本文讨论了利用机器学习来应对气候变化问题。
https://arxiv.org/abs/1906.05433
OpenAI发布了一份内容广泛的报告,全面讨论了语言模型的社会影响,包括对现有技术的有益使用和潜在误用。
https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf
情绪分析继续在各种各样的应用发挥作用。Mojifier是一个很酷的项目,它可以观看图片,检测情绪,然后用与检测到的情绪相匹配的表情符号替换脸部表情。
https://themojifier.com/
人工智能在放射学方面的应用也很流行。以下是对这一研究领域的趋势和前景的一个很好的总结。纽约大学的研究人员还发布了一个Pytorch实现的深层神经网络,可以提高放射科医生在乳腺癌筛查中的表现。此外还有重要的数据集发布,叫做MIMIC-CXR,它包括一个胸部x光和文本放射学报告的数据库。
https://arxiv.org/abs/1903.11726
https://medium.com/@jasonphang/deep-neural-networks-improve-radiologists-performance-in-breast-cancer-screening-565eb2bd3c9f
https://physionet.org/content/mimic-cxr/2.0.0/
《纽约时报》写了一篇关于 Karen Spark Jones 的文章,回顾了她对NLP和信息检索的重大贡献。
https://www.nytimes.com/2019/01/02/obituaries/karen-sparck-jones-overlooked.html
OpenAI Five 成为第一个在电子竞技游戏(dota2)中击败世界冠军的AI系统。
https://openai.com/blog/openai-five-defeats-dota-2-world-champions/
全球人工智能人才报告提供了全球人工智能人才库和全球对人工智能人才需求的详细报告。
https://jfgagne.ai/talent-2019/
如果你还没有订阅,DeepMind 团队的播客是很不错的选择,参与者可以在里面讨论与人工智能有关的最紧迫的话题。谈到人工智能的潜力,Demis Hassabis 在接受《经济学人》采访时谈到了一些未来主义的想法,比如将人工智能作为人类思维的延伸,以找到重要科学问题的潜在解决方案。
https://deepmind.com/blog?filters=%7B%22category%22:%5B%22Podcasts%22%5D%7D
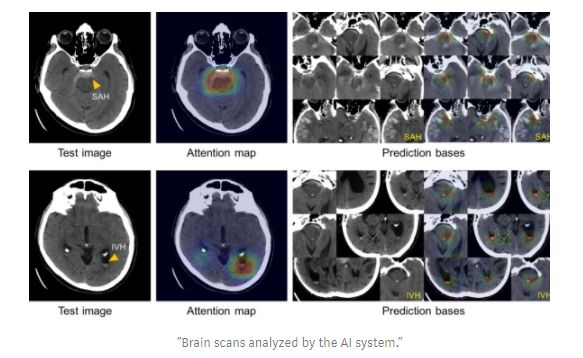
今年还见证了ML在健康应用方面令人难以置信的进步。例如,马萨诸塞州的研究人员开发了一种人工智能系统,能够像人类一样准确地发现脑出血。
https://venturebeat.com/2019/01/04/massachusetts-generals-ai-can-spot-brain-hemorrhages-as-accurately-as-humans/
Janelle Shane 总结了一组“奇怪”的实验,展示了机器学习如何以创造性的方式进行有趣的实验。有时候这是一种需要真正理解人工智能系统实际“做了什么”和“没做什么”的实验。其中一些实验包括利用神经网络生成假蛇和讲笑话。
https://aiweirdness.com/post/181621835642/10-things-artificial-intelligence-did-in-2018

基于 tensorflow 框架的机器学习行星探测模型。
https://www.blog.google/topics/machine-learning/hunting-planets-machine-learning/
OpenAI 讨论了发布(包括潜在的恶意用例)大型非监督语言模型的含义。
https://openai.com/blog/better-language-models/#sample1
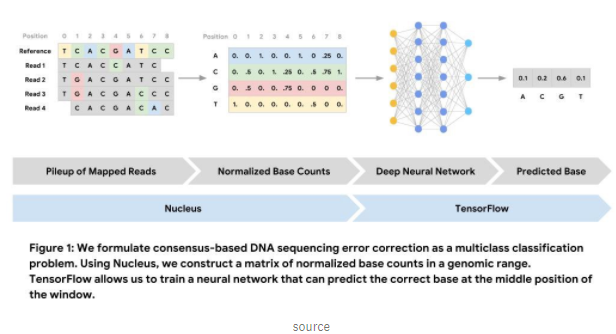
Colab Notebook 提供了一个关于如何使用细胞核和张力流进行“DNA测序错误纠正”的不错介绍。这里有一篇关于深度学习架构在探索DNA中的应用的详细文章。
https://colab.research.google.com/github/google/nucleus/blob/master/nucleus/examples/dna_sequencing_error_correction.ipynb
Alexander Rush 是哈佛大学的一位 NLP 研究员,他写了一篇关于张量存在的问题,以及这些问题如何体现在当前一些代码库中的重要文章。他还提出了一个关于张量附带命名指标的建议。
http://nlp.seas.harvard.edu/NamedTensor
ML/NLP 工具和数据集⚙️
这部分主要介绍与软件和数据集相关的内容,它们促进了 NLP 和机器学习的研究和工程。
抱抱脸(Hugging Face)发布了一个基于Pytorch的流行Transformer库:Pytorch - Transformer。它允许NLP从业者和研究人员轻松地使用最先进的通用架构,如BERT、GPT-2和XLM等。如果你对如何使用pytorch-transformer感兴趣,可以从以下几个地方开始,但是我非常喜欢Roberto Silveira的这个详细教程,它展示了如何使用库进行机器理解。
https://github.com/huggingface/transformers
https://rsilveira79.github.io/fermenting_gradients/machine_learning/nlp/pytorch/pytorch-transformer-squad/

TensorFlow 2.0带着一系列新特点发布了。在这里阅读更多关于最佳实践的信息。Francois Chollet也在这个Colab notebook 中对新特点进行了全面的概述。
https://medium.com/tensorflow/whats-coming-in-tensorflow-2-0-d3663832e9b8
https://colab.research.google.com/drive/1UCJt8EYjlzCs1H1d1X0iDGYJsHKwu-NO
PyTorch 1.3发布了大量新特性,包括命名张量和其他前端改进。
https://ai.facebook.com/blog/pytorch-13-adds-mobile-privacy-quantization-and-named-tensors/
艾伦人工智能研究所(Allen Institute for AI)发布了一款名为 Iconary 的人工智能系统,它可以和人类一起玩图画类游戏。这项工作结合了视觉/语言学习系统和常识推理。他们还发布了一个新的常识推理基准,称为Abductive-NLI。
https://iconary.allenai.org/
spaCy发布了一个新的库,将 Transformer 语言模型合并到它们自己的库中,以便能够在spaCy NLP中提取特征并使用它们。这一工作依赖于由 Hugging Face 开发的流行 Transformer 库。
Maximilien Roberti也写了一篇关于如何快速合并 fast.ai 代码与 pytorch-transformer 的文章。
https://explosion.ai/blog/spacy-transformers
https://towardsdatascience.com/fastai-with-transformers-bert-roberta-xlnet-xlm-distilbert-4f41ee18ecb2
Facebook人工智能团队发布了物理推理基准:PHYRE,旨在通过解决各种物理难题来测试人工智能系统的物理推理能力。
https://phyre.ai/
StanfordNLP 发布了StanfordNLP 0.2.0,这是一个用于自然语言分析的Python库,你可以对70多种不同的语言进行不同类型的语言分析,如词化和部分语音识别。
https://stanfordnlp.github.io/stanfordnlp/
GQA是一个可视化的问题回答数据集,用于支持与可视化推理相关的研究。
https://cs.stanford.edu/people/dorarad/gqa/
exBERT是一个可视化交互工具,用于探索 Transformer 语言模型的嵌入机制和注意力机制,你可以在这里找到论文和演示。
https://arxiv.org/abs/1910.05276
http://exbert.net/
Distill发表了一篇关于如何在递归神经网络(RNN)中可视化神经元记忆状态的文章。
https://distill.pub/2019/memorization-in-rnns/
Mathpix 是一个从图像中识别公式的工具,它可以根据公式的照片来提取并生成该公式的latex 版本。
https://mathpix.com/
Parl.ai 是一个聚合众多会话和会话人工智能相关工作数据集的托管平台。
https://parl.ai/
Uber 的研究人员发布了一个开源工具盒 Ludwig,用户只需几行代码就可以轻松地训练和测试深度学习模型。该框架的初衷是在训练和测试模型时避免任何形式的编码。
https://uber.github.io/ludwig/
谷歌人工智能研究人员发布了“Natural Questions”,这是一个大规模的语料库,用于训练和测试开放领域问题回答系统。
https://ai.googleblog.com/2019/01/natural-questions-new-corpus-and.html
文章和博客✍️
2019 年见证了数据科学作家和爱好者的爆炸式增长。这对我们的领域非常有用,鼓励了健康的讨论和学习。在这里,我列出了一些有趣且必看的文章和博客文章:
Christian Perone 很好地介绍了最大似然估计(MLE)和最大后验(MAP),这是了解如何估计模型参数的重要原理:http://blog.christianperone.com/2019/01/mle/
Reiichiro Nakano 发表了一篇博文,讨论了具有对抗性强的分类器的神经样式转换,并附带了 Colab 笔记:
https://reiinakano.com/2019/06/21/robust-neural-style-transfer.html
https://colab.research.google.com/github/reiinakano/adversarially-robust-neural-style-transfer/blob/master/Robust_Neural_Style_Transfer.ipynb
Saif M. Mohammad 撰写了一系列精彩的文章,讨论了 ACL 选集的历时分析:https://medium.com/@nlpscholar/state-of-nlp-cbf768492f90
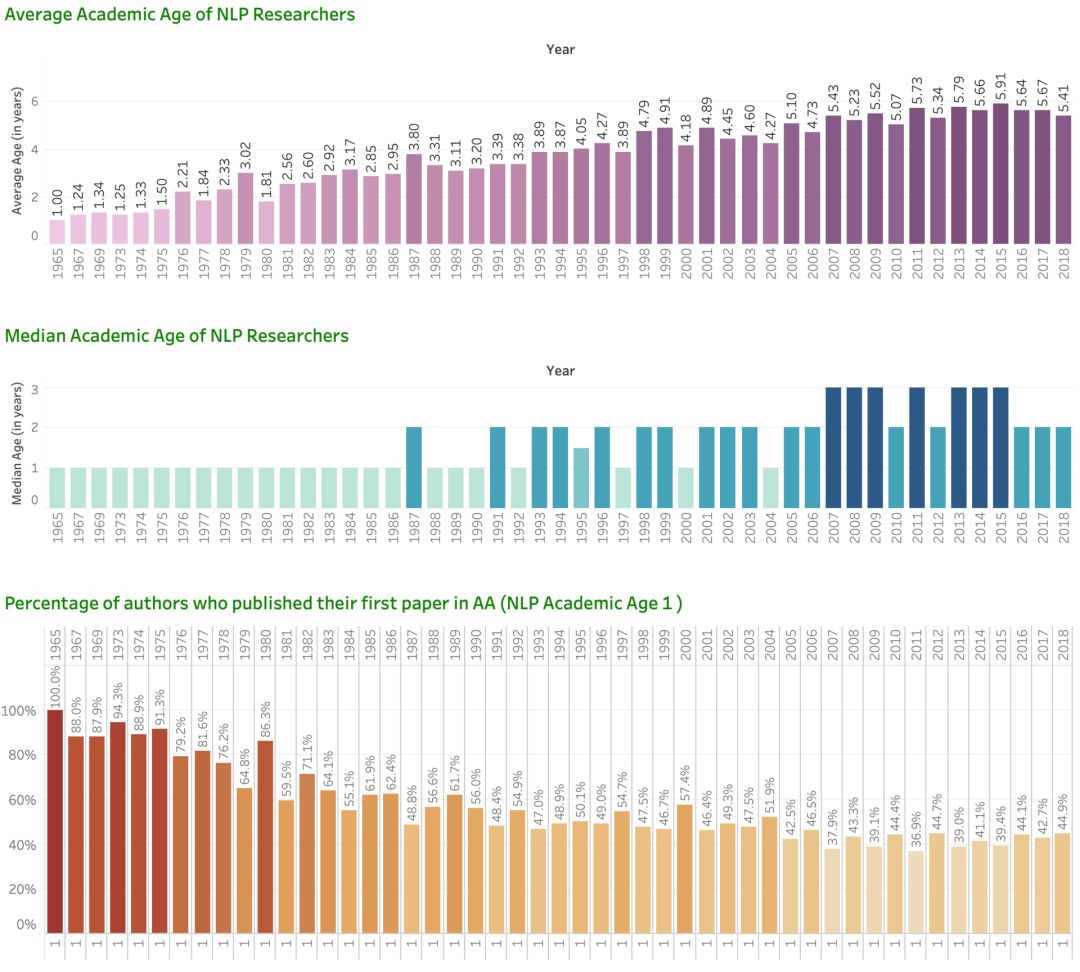
历年来首次在 AA 文章发布者的平均学龄、平均学龄和比例
有一个问题是:语言模型可以学习语法吗?通过结构探索,这项工作旨在表明可以使用上下文表示法和查找树结构的方法来实现这一目标:https://nlp.stanford.edu/~johnhew/structural-probe.html
Andrej Karpathy 写了一篇博客文章,总结了有效训练神经网络的最佳实践和秘诀:https://karpathy.github.io/2019/04/25/recipe/
为提高对使用BERT模型的搜索的理解,Google AI 研究人员和其他研究人员合作。像 BERT 这样的上下文化方法足以理解搜索查询背后的意图:https://www.blog.google/products/search/search-language-understanding-bert
RAdam(Rectified Adam)是一种基于亚当优化器的新优化技术,可帮助改善 AI 架构。为了找到更好、更稳定的优化器,我们付出了许多努力,但作者表示应该把重点放在优化的其他方面,这些方面对于改进收敛性来说同样重要:https://medium.com/@lessw/new-state-of-the-art-ai-optimizer-rectified-adam-radam-5d854730807b
随着近来机器学习工具的迅速发展,关于如何实现能够解决实际问题的机器学习系统的讨论也很多。Chip Huyen 的一篇有趣的文章讨论了机器学习系统设计,重点关注诸如超参数调整和数据管道等:https://github.com/chiphuyen/machine-learning-systems-design/blob/master/build/build1/consolidated.pdf
NVIDIA 创造了通过数十亿个参数训练的最大语言模型的记录:https://techcrunch.com/2019/08/13/nvidia-breaks-records-in-training-and-inference-for-real-time-conversational-ai/?guccounter=1&guce_referrer=aHR0cHM6Ly9tZWRpdW0uY29tL2RhaXItYWkvbmxwLXllYXItaW4tcmV2aWV3LTIwMTktZmI4ZDUyM2JjYjE5&guce_referrer_sig=AQAAAE_F3K6WB0wyWhWbqWGJT2vkLdEwj9xHCY-D75V6X8Flw_aZ2uIBp_ZvO0Xv_ceEWCITkC7CjTCkvSAdVKGviGpCkburbws1EGKipL0FJ2ToGD2hmM63Z4_R6qMFnQGTlG5Kqhs0xsQhd0fQw2_xOV2auWbdx0aChx7Nyv4YgTz
Abigail See 撰写了一篇出色的博客文章,内容是关于如何在自然语言生成系统中提高对话能力:http://www.abigailsee.com/2019/08/13/what-makes-a-good-conversation.html
Google AI 发布了两个自然语言对话数据集,想要通过更复杂和自然的对话数据集来改善数字助理等对话应用程序个性化:https://ai.googleblog.com/2019/09/announcing-two-new-natural-language.html
深度强化学习仍然是 AI 领域中讨论最广泛的话题之一,它甚至引起了心理学和神经科学领域的兴趣。可以看一下发表在《认知科学趋势》上的这篇文章,了解更多有关重点信息:https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(19)30061-0
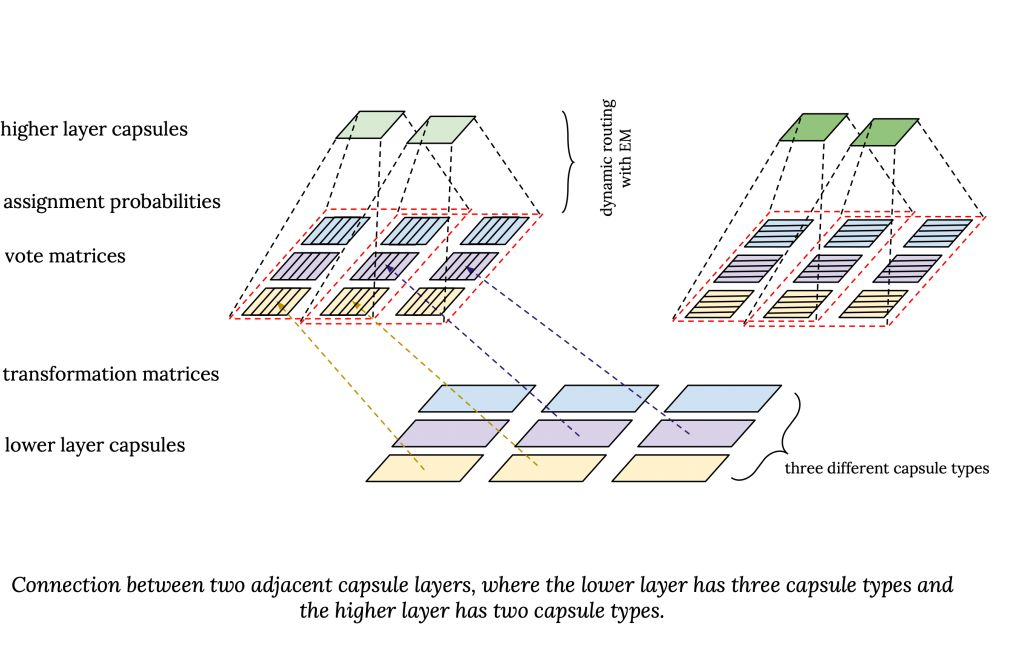
Samira Abner 在文章中总结了 transfomer 和胶囊网络及其连接背后的主要构建模块:https://staff.fnwi.uva.nl/s.abnar/?p=108
Adam Kosiorek 还写了这篇关于胶囊自动编码器(胶囊网络的无监督版本)的文章,用于物体检测:http://akosiorek.github.io/ml/2019/06/23/stacked_capsule_autoencoders.html
研究人员在 Distill 上发表了一篇颇具互动性的文章,用视觉化的方式展示了高斯过程:https://distill.pub/2019/visual-exploration-gaussian-processes/
通过这篇在 Distill 上发布的文章,Augustus Odena 呼吁研究人员解决有关GAN的几个重要的开放性问题:https://distill.pub/2019/gan-open-problems/
这是图卷积网络(GCN)的 PyTorch 实现,用于对垃圾邮件发送者和非垃圾邮件发送者进行分类:https://github.com/zaidalyafeai/Notebooks/blob/master/Deep_GCN_Spam.ipynb
2019 年初,VentureBeat 发布了由Rumman Chowdury、Hilary Mason、Andrew Ng 和 Yan LeCun 等专家做出的 2019 年预测清单。回顾一下,看看他们的预测是否正确吧:https://venturebeat.com/2019/01/02/ai-predictions-for-2019-from-yann-lecun-hilary-mason-andrew-ng-and-rumman-chowdhury/
了解如何优化 BERT 以执行多标签文本分类:https://medium.com/huggingface/multi-label-text-classification-using-bert-the-mighty-transformer-69714fa3fb3d
由于 BERT 的流行,在过去的几个月中,许多研究人员开发了一些方法来“压缩” BERT,其思想是构建更快、更小且内存效率更高的版本。 Mitchell A. Gordon 总结了围绕此目标开发的压缩类型和方法:http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
超级智能仍然是专家们争论的话题。超级智能需要对框架、政策和正确的观察有正确的理解。我发现一系列有趣的综合性文章(K. Eric Drexler 以技术报告的形式撰写),这对于理解有关超级智能的一些问题和注意事项很有用:https://www.fhi.ox.ac.uk/wp-content/uploads/Reframing_Superintelligence_FHI-TR-2019-1.1-1.pdf
Eric Jang 在一篇不错的博客文章中介绍了元学习的概念,旨在建立和训练预测和学习能力都很强的机器学习模型:https://blog.evjang.com/2019/02/maml-jax.html
Sebastian Ruder 撰写的 AAAI 2019 重点摘要:https://ruder.io/aaai-2019-highlights/
图神经网络今年受到了广泛的关注。David Mack 撰写了一篇不错的视图文章,介绍了他们如何使用此技术,且非常注意执行最短路径计算:https://medium.com/octavian-ai/finding-shortest-paths-with-graph-networks-807c5bbfc9c8
贝叶斯方法仍然是一个有趣的主题,尤其是如何将它们应用于神经网络,以避免诸如过度拟合之类的常见问题,推荐读一下 Kumar Shridhar 的这些文章:https://medium.com/neuralspace/bayesian-neural-network-series-post-1-need-for-bayesian-networks-e209e66b70b2
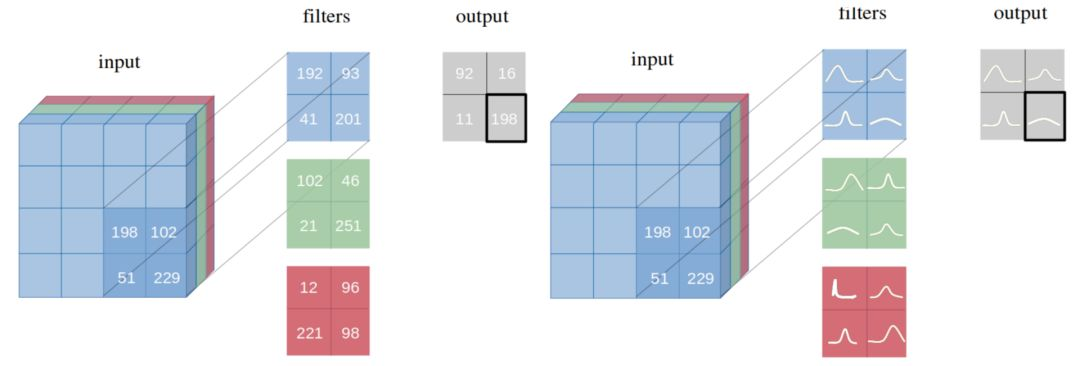 以点估计为权重的网络 VS. 以概率分布为权重的网络
以点估计为权重的网络 VS. 以概率分布为权重的网络
AI道德????
伦理学可能是今年人工智能系统中争论最多的一个话题,其中包括围绕偏见、公平和透明等方面的讨论。在本节中,我将列出相关话题的有趣故事和论文:
题为《减轻ML的影响差异是否需要差别对待吗?》的论文讨论了通过对真实数据集进行实验而应用不同学习过程的结果:http://papers.nips.cc/paper/8035-does-mitigating-mls-impact-disparity-require-treatment-disparity
HuggingFace 发表了一篇文章,讨论了在对话式 AI 的开源 NLP 技术背景下的道德规范:https://medium.com/huggingface/ethical-analysis-of-the-open-sourcing-of-a-state-of-the-art-conversational-ai-852113c324b2
随着我们继续引入基于 AI 的技术,能够量化伦理学在 AI 研究中的作用是一项重要的工作。本文对这些措施和“在领先的AI、机器学习和机器人技术场景中与道德相关的研究的使用”进行了广泛的分析:https://arxiv.org/abs/1809.08328
在 NAACL 2019 上发表的这项工作讨论了去偏方法如何掩盖词嵌入中的性别偏见:https://arxiv.org/abs/1903.03862
Zachary Lipton 提交的论文“机器学习奖学金陷入困境的趋势”,我还为它写了一篇有趣的论文摘要:https://medium.com/dair-ai/an-overview-of-troubling-trends-in-machine-learning-scholarship-582df3caa518?source=false---------0
Gary Marcus 和 Ernest Davis 发表了他们的书《重启人工智能:建立我们可以信赖的人工智能》。本书的主题是讨论实现强大的人工智能必须采取的步骤:https://www.amazon.com/Rebooting-AI-Building-Artificial-Intelligence/dp/1524748250
关于 AI 进步的话题,FrançoisChollet 也写了一篇令人印象深刻的论文,为更好地量化智能提供了依据:https://arxiv.org/abs/1911.01547
优达学城上,Andrew Trask 开设了有关差异化隐私、联邦学习和加密 AI 等主题的课程:https://www.udacity.com/course/secure-and-private-ai--ud185
关于隐私主题,Emma Bluemke 撰写了一篇很棒的文章,讨论了如何在保护患者隐私的前提下训练机器学习模型:https://blog.openmined.org/federated-learning-differential-privacy-and-encrypted-computation-for-medical-imaging/
在今年年初,Mariya Yao 发布了一份涉及 AI 伦理的综合研究论文摘要清单。尽管论文参考清单是 2018 年的,但我相信它们在今天仍然有意义:https://www.topbots.com/most-important-ai-ethics-research/
ML / NLP学习资源????
在这里,我将列出一系列教育资源、作家和正在做一些在教育传播 ML / NLP 晦涩概念/知识的人:
CMU 发布了“ NLP 神经网络”课程的材料和课程提纲:http://phontron.com/class/nn4nlp2019/
Elvis Saravia 和 Soujanya Poria 发布了一个名为 NLP-Overview 的项目,该项目旨在帮助学生和从业人员获得应用于NLP的现代深度学习技术的简要概述,包括理论,算法,应用程序和最新成果,链接:
https://nlpoverview.com/
https://github.com/omarsar/nlp_overview
 NLP-Overview
NLP-Overview
Microsoft Research Lab 发布了有关数据科学基础的免费电子书,其主题从 马尔可夫链蒙特卡尔理论到随机图均有涉猎:https://www.datasciencecentral.com/profiles/blogs/new-book-foundations-of-data-science-from-microsoft-research-lab
“机器学习数学”是一本免费的电子书,介绍了机器学习中最重要的数学概念。它还包括一些描述机器学习部分的 Jupyter 笔记本教程。Jean Gallier 和 Jocelyn Quaintance 还撰写了很多免费电子书,内容涉及机器学习中使用的数学概念:
https://mml-book.github.io/
https://www.cis.upenn.edu/~jean/math-deep.pdf
斯坦福大学发布“自然语言理解”课程视频:https://www.youtube.com/playlist?list=PLoROMvodv4rObpMCir6rNNUlFAn56Js20
在学习方面,OpenAI 汇总了有关如何继续学习和提高机器学习技能的大量建议。显然,他们的员工每天都使用这些方法来学习和扩展知识: https://openai.com/blog/learning-day/

Adrian Rosebrock 发布了长达 81 页的指南,介绍如何使用 Python 和 OpenCV 进行计算机视觉:https://www.pyimagesearch.com/start-here/
Emily M. Bender 和 Alex Lascarides 出版了一本书,书名为“ NLP 语言基础”。这本书的主要思想是通过打下语义和语用学的基础,讨论在 NLP 领域中“含义”是什么:http://www.morganclaypoolpublishers.com/catalog_Orig/product_info.php?products_id=1451
Elad Hazan 发布了一份关于“机器学习优化”的演讲笔记,旨在用优美的数学和符号将机器训练作为优化问题呈现出来:https://drive.google.com/file/d/1GIDnw7T-NT4Do3eC0B5kYJlzwOs6nzIO/view
Deeplearning.ai 还发表了一篇很棒的文章,讨论了使用更直观和交互式的方法来优化神经网络中的参数:https://www.deeplearning.ai/ai-notes/optimization/?utm_source=social&utm_medium=twitter&utm_campaign=BlogAINotesOptimizationAugust272019
Andreas Mueller 发布了一系列“应用机器学习”新课程视频:https://www.youtube.com/playlist?list=PL_pVmAaAnxIQGzQS2oI3OWEPT-dpmwTfA
Fast.ai 发布了其新的 MOOC,标题为 Deep Learning from the Foundations。
麻省理工学院发布了有关“深度学习入门”课程的所有视频和课程提纲:https://www.youtube.com/playlist?list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI
Chip Huyen 在推特上发布了一系列令人印象深刻的机器学习入门免费在线课程:https://twitter.com/chipro/status/1157772112876060672
Andrew Trask 出版了名为《图解深度学习》(Grokking Deep Learning)的书。这本书是理解神经网络体系结构基本组成部分的一个很好的入门书籍:https://github.com/iamtrask/Grokking-Deep-Learning
Sebastian Raschka 上传了 80 份笔记,介绍了如何实现不同的深度学习模型,如 RNN 和CNN。很棒的是,所有模型都用 PyTorch 和 TensorFlow 实现:https://github.com/rasbt/deeplearning-models
这是一个深入了解 TensorFlow 工作原理的很棒的教程:https://medium.com/@d3lm/understand-tensorflow-by-mimicking-its-api-from-scratch-faa55787170d
这是 Christian Perone 为 PyTorch 设计的教程:http://blog.christianperone.com/2018/03/pytorch-internal-architecture-tour/
Fast.ai 还发布了一个名为“NLP简介”的课程,并附带了一个播放列表。主题范围从情感分析到主题建模再到 Transformer 都有:https://www.youtube.com/playlist?list=PLtmWHNX-gukKocXQOkQjuVxglSDYWsSh9
Xavier Bresson 在本演讲中讲解了用于模块生成的图卷积神经网络。
幻灯片:http://helper.ipam.ucla.edu/publications/glws4/glws4_16076.pdf。
这是一篇讨论如何预训练 GNN 的论文:https://arxiv.org/abs/1905.12265
下面是图网络有关主题,一些工程师使用图网络来预测分子和晶体的特性:https://www.eurekalert.org/pub_releases/2019-06/uoc--eug060719.php
Google AI 团队还发表了一篇出色的博客文章,解释了他们如何使用 GNN 进行气味预测:https://ai.googleblog.com/2019/10/learning-to-smell-using-deep-learning.html
如果你对使用图神经网络感兴趣,这里是各种 GNN 及其应用的全面概述:https://arxiv.org/pdf/1812.08434.pdf
这是一些无监督学习方法相关的视频,例如约翰·霍普金斯大学的 Rene Vidal 的 PCA(主成分分析法)。
如果你对将预训练的 TensorFlow 模型转换为 PyTorch 感兴趣,可以看一下 Thomas Wolf 在这片博客文章中的介绍:https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28
想了解生成型深度学习吗?David Foster 写了一本很棒的书 Generative Deep Learning
,教数据科学家如何应用 GAN 和编码器/解码器模型学画画、写作和音乐创作等任务。
Generative Deep Learning:https://www.oreilly.com/library/view/generative-deep-learning/9781492041931/
本书随附官方存储库,其中包含 TensorFlow 代码:https://github.com/davidADSP/GDL_code
以及将代码转换为 PyTorch:https://github.com/MLSlayer/Generative-Deep-Learning-Code-in-Pytorch
包含代码块的 Colab 笔记,用于练习和学习因果推理概念,例如干预措施、反事实:https://colab.research.google.com/drive/1rjjjA7teiZVHJCMTVD8KlZNu3EjS7Dmu#scrollTo=T9xtzFTJ1Uwf
这是 Sebastian Ruder、Matthew Peters、Swabha Swayamdipta 和 Thomas Wolf 提供的NAACL 2019“自然语言处理中的迁移学习”相关材料:https://github.com/huggingface/naacl_transfer_learning_tutorial,以及随附的 Google Colab 上手笔记:https://colab.research.google.com/drive/1iDHCYIrWswIKp-n-pOg69xLoZO09MEgf
Jay Alammar 的另一篇很棒的博客文章 https://jalammar.github.io/visual-numpy/,主题是数据表示。他还写了许多其他有趣的插图指南,包括 GPT-2 和 BERT。Peter Bloem 还发表了一篇非常详细的博客文章,解释了构成 Transfomer 的所有要素。
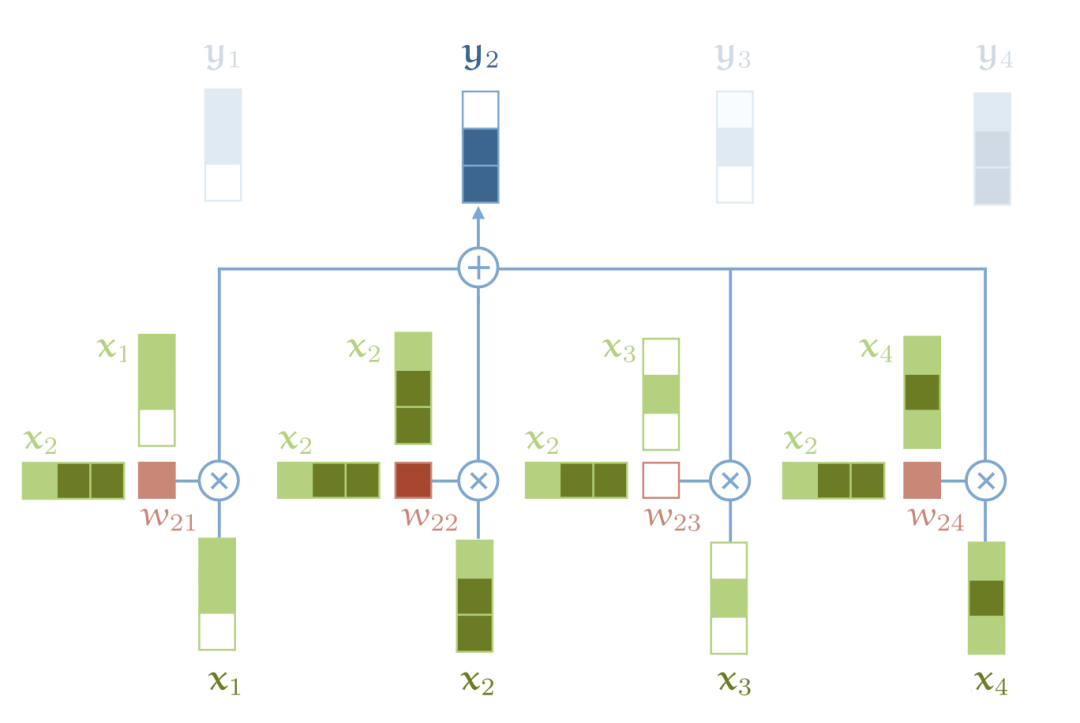 基本的自我注意力的图示
基本的自我注意力的图示
这是 Mihail Eric 撰写的 ACL 2019 上 NLP趋势的概述,还不错。其中一些主题包括将知识图谱引入 NLP 体系结构、可解释性和减少偏见等。如果你有兴趣,这里还有一些概述:
https://medium.com/@mgalkin/knowledge-graphs-in-natural-language-processing-acl-2019-7a14eb20fce8
http://noecasas.com/post/acl2019/
斯坦福大学发布了 CS231n 2019 版的完整课程大纲:http://cs231n.stanford.edu/syllabus.html
David Abel 为 ICLR 2019 写了一些笔记,还为 NeurIPS 2019 写下了令人印象深刻的摘要:
https://david-abel.github.io/notes/iclr_2019.pdf
https://david-abel.github.io/notes/neurips_2019.pdf
这是一本很棒的书,是一本适合深度学习的入门书籍,附带笔记:http://d2l.ai/

一份 BERT、ELMo 和迁移学习 NLP co. 的插图指南:http://jalammar.github.io/illustrated-bert/
Fast.ai 发布了其 2019 版的“面向程序员的实用深度学习”课程:https://www.fast.ai/2019/01/24/course-v3/
由 Pieter Abbeel 和其他人讲授的奇妙课程,深入了解无监督学习:https://sites.google.com/view/berkeley-cs294-158-sp19/home
Gilbert Strang 出版了一本有关线性代数和神经网络的新书:http://math.mit.edu/~gs/learningfromdata/'
加州理工学院为“机器学习基础”课程提供了完整的教学大纲,讲义幻灯片和视频:http://tensorlab.cms.caltech.edu/users/anima/cs165.html
“ Scipy 讲义”是一系列教程,教你如何掌握 matplotlib、NumPy 和 SciPy 等工具。
这是一个关于理解高斯过程的不错教程(附笔记):https://peterroelants.github.io/posts/gaussian-process-tutorial/
这是一篇必读文章,Lilian Weng 深入探讨了通用语言模型,例如 ULMFit、OpenAI GPT-2 和BERT:https://lilianweng.github.io/lil-log/2019/01/31/generalized-language-models.html
Papers with Code 网站上有精选的附有代码和最新结果的机器学习论文:https://paperswithcode.com/
Christoph Molnar 发布了第一版《可解释性机器学习》,该书涉及用于更好地解释机器学习算法的重要技术:https://christophm.github.io/interpretable-ml-book/
David Bamman 发布了伯克利大学开设的自然语言处理课程的完整课程大纲和幻灯片:http://people.ischool.berkeley.edu/~dbamman/nlp18.html
伯克利发布其“ 应用自然语言处理”课程的所有材料:https://github.com/dbamman/anlp19
Aerin Kim 是微软的高级研究工程师,撰写了有关应用数学和深度学习主题的文章。其中一些主题包括条件独立性、伽玛分布、困惑度等:https://towardsdatascience.com/@aerinykim
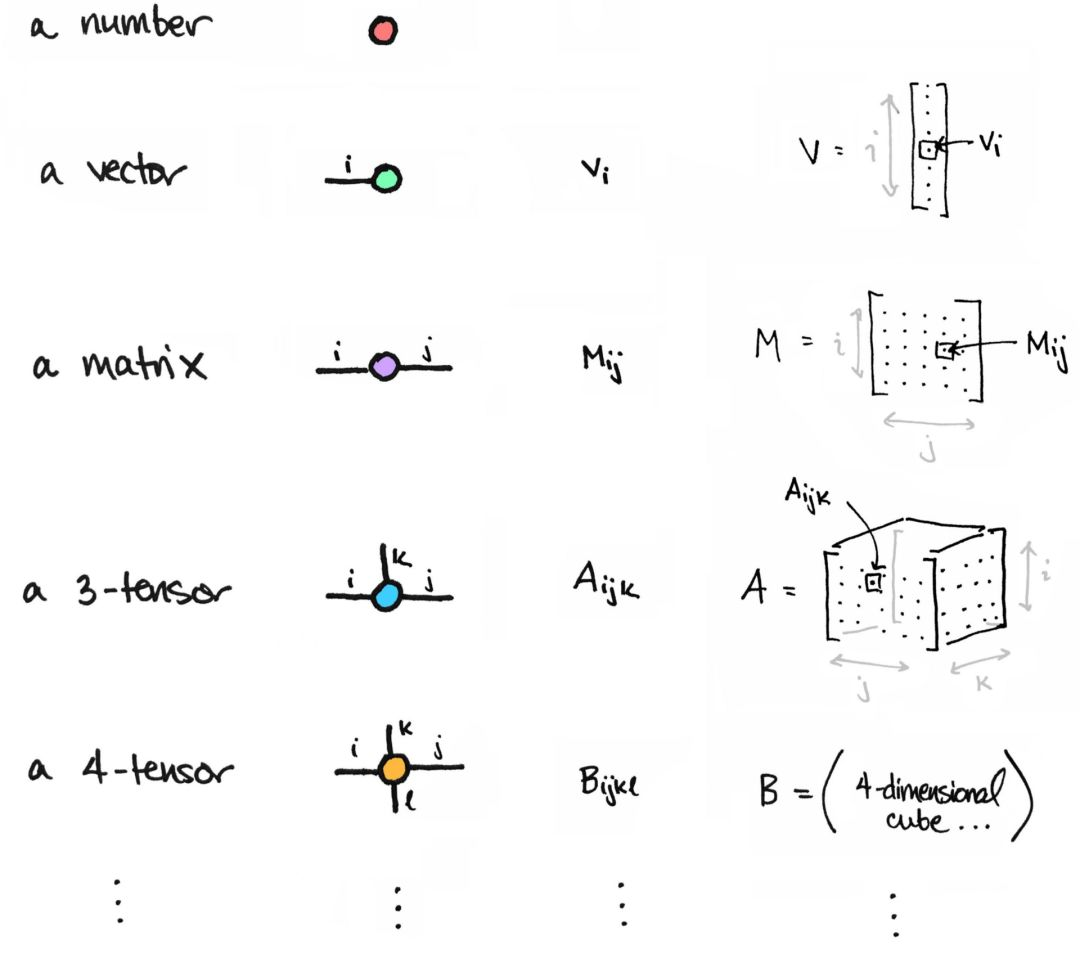
Tai-Danae Bradley 在此博客文章中讨论了如何考虑矩阵和张量的方法。本文有很棒的图示,有助于读者更好地理解在矩阵上执行的某些转换和操作。
希望这些链接可以帮到你。祝你在 2020 年成功、健康!
原文链接:
https://medium.com/dair-ai/nlp-year-in-review-2019-fb8d523bcb19
(*本文为AI科技大本营编译文章,转载请微信联系1092722531)
◆
精彩推荐
◆
点击阅读原文,或扫描文首贴片二维码
所有CSDN 用户都可参与投票和抽奖活动
加入福利群,每周还有精选学习资料、技术图书等福利发送

推荐阅读
“一百万行Python代码对任何人都足够了”
GitHub标星1.5w+,从此我只用这款全能高速下载工具
中国工程师在美遭抢劫电脑遇害,数百人悼念
跟风 Google 只是东施效颦?!
召回→排序→重排:技术演进趋势的深度之旅,2020 必备!
如何写出让同事膜拜的漂亮代码?
同样是写代码,你和大神究竟差在哪里?
互联网公司=21世纪的国营大厂
详解CPU几个重点基础知识
DeFi行业2019全年呈爆炸式增长,8.5亿美元资产锁定在DeFi生态中;行业市值主要由头部项目瓜分 | 报告

你点的每个“在看”,我都认真当成了AI
最后
以上就是愤怒酸奶最近收集整理的关于2019,不可错过的NLP“高光时刻”的全部内容,更多相关2019,不可错过内容请搜索靠谱客的其他文章。








发表评论 取消回复