一、ELK 是什么?
ELK = Elasticsearch Logstash Kibana
- Elasticsearch:后台分布式存储以及全文检索。
- Logstash: 数据导入导出的工具。
- Kibana:数据可视化展示界面。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
注意: ELK技术栈有 version check,软件大版本号需要一致,本文以 6.4.0 版本为例。
二、Elasticsearch
源码下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
2.1、下载 Elasticsearch 源码
mkdir /usr/local/elk/es1
wget https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-4-02.2、创建 es 用户
useradd es 2.3、解压源码并修改其所有者
tar zxvf elasticsearch-6.4.0.tar.gz
chown -R es:es elasticsearch-6.4.0 2.4、修改 Elasticsearch 的配置文件
修改Elasticsearch的配置文件:/usr/local/elk/elasticsearch-6.4.0/config/elasticsearch.yml
cluster.name: elasticsearch
node.name: es-1
path.data: /data/elasticsearch/es1/data
bootstrap.memory_lock: true
network.host: 192.168.167.205
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["node205.data:9300","node205.data:9301","node205.data:9302"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 1
action.destructive_requires_name: true2.5、后台启动 Elasticsearch
Elasticsearch 不能以 root 用户启动,所以改用 es 用户启动。
su – es
cd /usr/local/elk/es/es1/elasticsearch-6.4.0
./bin/elasticsearch –d可根据 logs/elasticsearch.log 文件来监测 Elasticsearch 服务运行状况。
注意:如果Elasticsearch服务启动失败,可参考 第五章 FAQ 处理问题。
2.6、停止Elasticsearch
根据 Elasticsearch 的端口号来停止该服务:
netstat -ntlp | grep 9200 | awk '{print $7}' | awk -F '/' '{print $1}' | xargs kill -9 三、Logstash
Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。logstash收集日志基本流程为:
Input –> filter –> output
源码下载地址:https://www.elastic.co/cn/downloads/logstash
1.1、下载Logstash源码
cd /usr/local/elk
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.4.2.tar.gz 1.2、创建 es 用户(如已创建,请略过该步骤)
useradd es 1.3、解压源码并修改其所有者
tar zxvf logstash-6.4.0.tar.gz
chown -R es:es logstash-6.4.0 1.4、示例:将mysql表数据导入到Elasticsearch
1.4.1、创建配置文件
su - es
cp -r config/logstash-sample.conf config/face.conf修改 face.conf 配置文件如下所示:
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
jdbc{
jdbc_connection_string => "jdbc:mysql://192.168.167.204:3316/db0?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&tinyInt1isBit=false"
jdbc_user => "mycat"
jdbc_password => "mycat123"
jdbc_driver_library => "/usr/local/mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
jdbc_default_timezone =>"Asia/Shanghai"
statement_filepath => "./sql/face.sql"
schedule => "* * * * *"
# type => "mycat"
# 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
# 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => true
# 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键
tracking_column => "id"
tracking_column_type => "numeric"
last_run_metadata_path => "./face_last_id"
lowercase_column_names => false
}
}
filter {
if [sex] == 1 {
mutate {
add_field => { "tags" => "男"}
}
}
if [sex] == 2 {
mutate {
add_field => { "tags" => "女"}
}
}
if [sex] == 0 {
mutate {
add_field => { "tags" => "未知"}
}
}
}
output {
elasticsearch {
hosts => ["http://192.168.167.205:9200"]
#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{ YYYY.MM.dd}"
index => "face_card"
document_id => "%{id}"
#user => "elastic"
#password => "changeme"
}
stdout {
codec => json_lines
}
}1.4.2、添加 sql 文件
创建 face.sql 文件
su - es
mkdir sql
touch face.sql修改 face.sql 文件内容如下所示
select * from face_card where id > :sql_last_value order by id limit 10001.4.3、创建索引
打开postman,执行PUT请求来创建Elasticsearch索引,索引名称为face_card,指定分片数为5,副本数为2:
PUT http://192.168.167.205:9200/face_card
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 2
}
}1.4.4、执行导数程序
su - es
cd /usr/local/elk/logstash-6.4.0
./bin/logstash -f ./config/face.conf1.4.5、查询索引内容
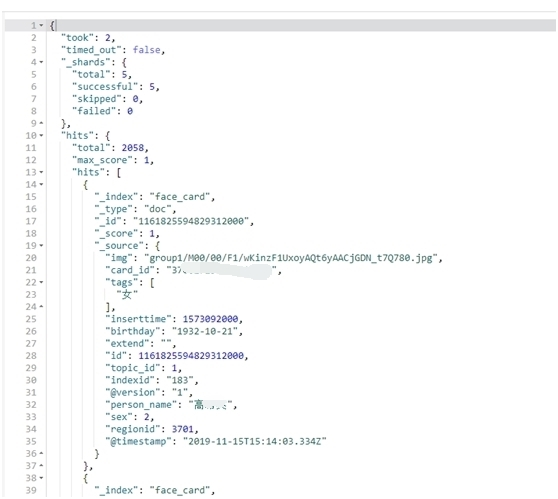
使用postman工具,执行GET请求来查看索引内容:
GET /face_card/_search返回示例如下图所示:
四、Kibana
源码下载地址:https://www.elastic.co/cn/downloads/past-releases#kibana
4.1、下载 Kibana 源码
cd /usr/local/elk
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.4.0-linux-x86_64.tar.gz 4.2、创建 es 用户(如已创建,请略过该步骤)
useradd es 4.3、解压源码并修改其所有者
tar zxvf kibana-6.4.0-linux-x86_64.tar.gz
chown -R es:es kibana-6.4.0-linux-x86_64 4.4、修改kibana.yml配置文件
修改Kibana配置:config/kibana.yml
server.port: 5601
server.host: "node205.data"
elasticsearch.url: "http://node205.data:9200"
logging.dest: /usr/local/elk/kibana-6.4.0-linux-x86_64/logs/kibana.log4.5、后台启动Kibana
用es用户后台启动Kibana
su - es
cd /usr/local/elk/kibana-6.4.0-linux-x86_64
nohup ./bin/kibana > /dev/null 2>&1 & 可根据 logs/kibana.log 文件来监测Kibana服务运行状况。
五、FAQ
5.1、max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
修改 /etc/security/limits.conf 文件,增加配置,来改变用户 es 每个进程最大同时打开文件数的大小:
es soft nofile 65535
es hard nofile 65537可切换到es用户下,然后通过下面2个命令查看当前数量:
- ulimit -Hn
- ulimit -Sn
注意:用户退出重新登录后配置才会刷新生效。
1.2. max number of threads [3818] for user [es] is too low, increase to at least [4096]
最大线程个数太低。修改配置文件 /etc/security/limits.conf ,增加配置:
es - nproc 4096
# 或者
es soft nproc 4096
es hard nproc 4096可切换到es用户下,然后通过下面2个命令查看当前最大线程数:
- ulimit -Hu
- ulimit –Su
注意:用户退出重新登录后配置才会刷新生效。
1.3. max virtual memory areas vm.maxmapcount [65530] is too low, increase to at least [262144]
修改 /etc/sysctl.conf 文件,在文末增加配置
vm.max_map_count=262144执行命令sysctl -p生效。
1.4. memory locking requested for elasticsearch process but memory is not locked
修改 /etc/security/limits.conf 文件,增加配置:
* soft memlock unlimited
* hard memlock unlimited1.5. 启动Elasticsearch服务,显示被killed
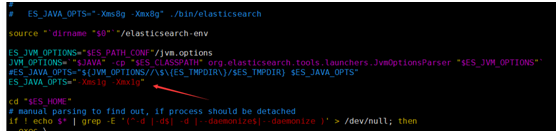
可能Elasticsearch所在的机器内存不足。
修改 bin/elasticsearch 文件,将 ESJAVAOPTS 修改为:ES_JAVA_OPTS="-Xms1g -Xmx1g",如下图所示:
1.6. 服务启动后,在浏览器访问不了9200端口
关闭防火墙:
systemctl stop firewalld点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是 人才。
白嫖不好,创作不易。 各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !

最后
以上就是孝顺银耳汤最近收集整理的关于Elasticsearch 6.4.0 Logstash Kibana 安装(全)的全部内容,更多相关Elasticsearch内容请搜索靠谱客的其他文章。








发表评论 取消回复