stypora-copy-images-to: img
typora-root-url: ./
Spark Day01:Spark 基础环境
预习视频:
https://www.bilibili.com/video/BV1uT4y1F7ap
Spark:基于Scala语言
Flink:基于Java语言
01-[了解]-Spark 课程安排
总的来说分为Spark 基础环境、Spark 离线分析和Spark实时分析三个大的方面,如下图所示:
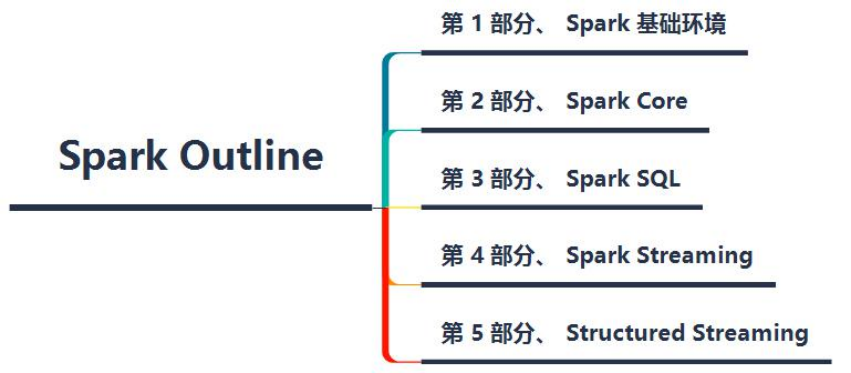
目前在企业中使用最多Spark框架中模块:SparkSQL(离线分析)和StructuredStreaming(实时流式分析)。
02-[了解]-今日课程内容提纲
主要讲解2个方面内容:Spark 框架概述和Spark 快速入门。
1、Spark 框架概述
是什么?
四个特点
模块(部分组成)
框架运行模式
2、Spark 快速入门
环境准备
Spark 本地模式运行程序
大数据经典程序:词频统计WordCount
提供WEB UI监控界面
03-[掌握]-Spark 框架概述【Spark 是什么】
Spark 是加州大学伯克利分校AMP实验室(Algorithms Machines and People Lab)开发的通用大数据出来框架。
Spark的发展历史,经历过几大重要阶段,如下图所示:
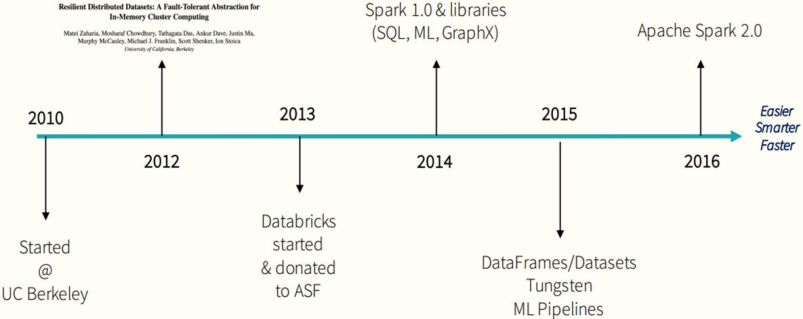
Spark 是一种快速、通用、可扩展的大数据分析引擎,2009 年诞生于加州大学伯克利分校AMPLab,2010 年开源, 2013年6月成为Apache孵化项目,2014年2月成为 Apache 顶级项目,用 Scala进行编写项目框架。

官方文档定义:

1、分析引擎
类似MapReduce框架,分析数据
2、统一(Unified)分析引擎
离线分析,类似MapReduce
交互式分析,类似Hive
流式分析,类似Storm、Flink或者双11大屏统计
科学分析,Python和R
机器学习
图计算
3、对大规模海量数据进行统一分析引擎
大数据分析引擎
【分布式计算,分而治之思想】
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5Rk9bK5g-1625406507847)(/img/image-20210419160056620.png)]
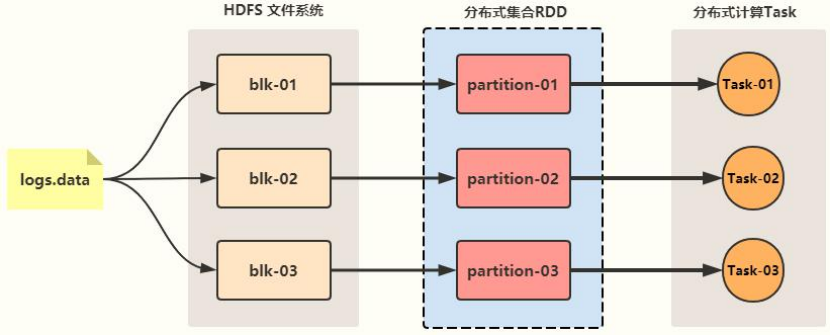
Spark框架优秀在原因在于:核心数据结构【
RDD:ResilientDistributed Datasets】,可以认为集合。
04-[了解]-Spark 框架概述【Spark 四大特点】
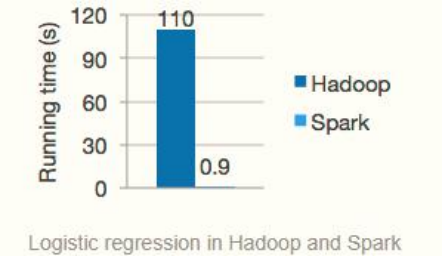
Spark具有运行速度快、易用性好、通用性强和随处运行等特点。

官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
- 其一、Spark处理数据时,可以将中间处理结果数据存储到内存中;
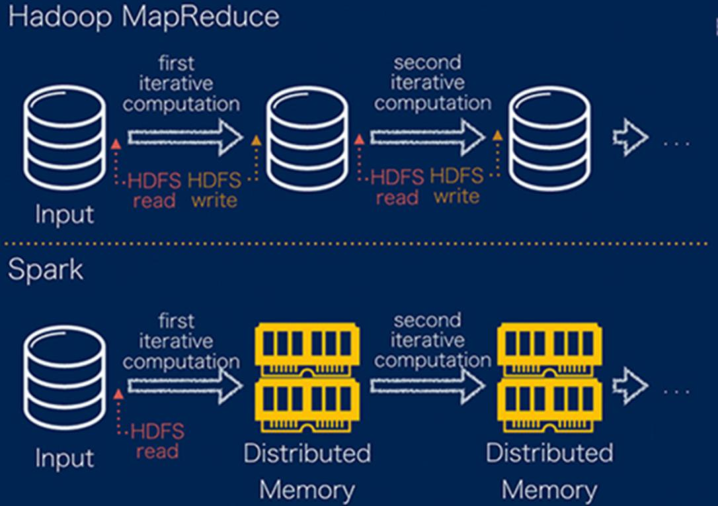
- 其二、Spark Job调度以DAG方式,并且每个任务Task执行以线程(Thread)方式,并不是像MapReduce以进程(Process)方式执行。
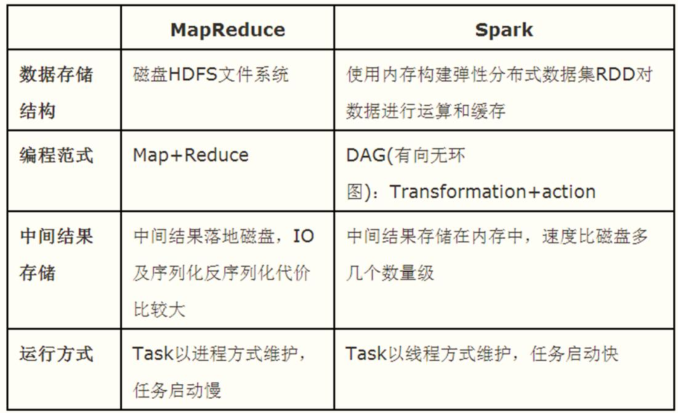
思考:Spark框架仅仅处理分析数据引擎(框架),那么问题:
- 第一、处理的数据存储在哪里???
- 任意存储设备(存储引擎),比如HDFS、HBase、Redis、Kafka、Es等等
- 处理文本数据textfile、JSON格式数据、列式存储等
- 第二、Spark处理数据程序运行在哪里???
- 本地模式Local
- Hadoop YARN 集群
- Stand alone集群,类似YARN集群
- 容器中,比如K8s中
05-[了解]-Spark 框架概述【Spark 框架模块】
Spark框架是一个统一分析引擎,可以针对任何类型分析都可以处理数据,类似Hadoop框架,包含很多模块Module。
Spark 1.0开始,模块如下所示:基础模块Core、高级模块:SQL、Streaming、MLlib及GraphX等

1、Core:核心模块
数据结构:RDD
将数据封装到RDD集合,调用集合函数处理数据
2、SQL:结构化数据处理模块
数据结构:DataFrame、DataSet
将数据封装DF/DS中,采用SQL和DSL方式分析数据
3、Streaming:针对流式数据处理模块
数据结构:DStream
将流式数据分化为Batch批次,封装到DStream中
4、MLlib:机器学习库
包含基本算法库实现,直接调用即可
基于RDD和DataFrame类库API
5、GraphX:图计算库
目前使用不多,被Java领域框架:Neo4J
6、Structured Streaming:从Spark2.0提供针对流式数据处理模块
将流式数据封装到DataFrame中,采用DSL和SQL方式处理数据
7、PySpark:支持Python语音
可以使用Python数据分析库及Spark库综合分析数据
8、SparkR:支持R语言
http://spark.apache.org/docs/2.4.5/sparkr.html

06-[理解]-Spark 框架概述【Spark 运行模式】
Spark 框架编写的应用程序可以运行在本地模式(Local Mode)、集群模式(Cluster Mode)和云服务(Cloud),方便开发测试和生产部署。
开发程序时往往采用:本地模式LocalMode,测试生产环境使用集群模式,其中最为常用Hadoop YARN集群
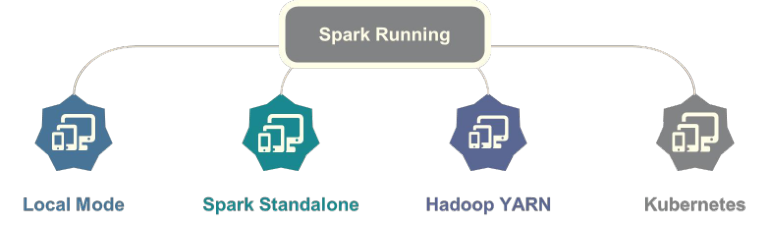
Spark 应用程序运行在集群模式下时,有3种:
- 第一种:Spark Standalone 集群,类似Hadoop YARN集群
- 第二种:Hadoop YARN 集群
- 第三种:Apache Mesos框架,类似Hadoop YARN集群
hadoop 2.2.0 在2013年发布,release版本:YARN 版本
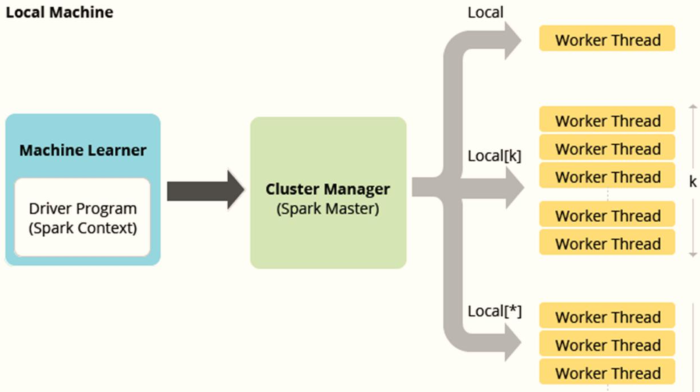
本地模式:
Local Mode将Spark 应用程序中任务Task运行在一个本地JVM Process进程中,通常开发测试使用。
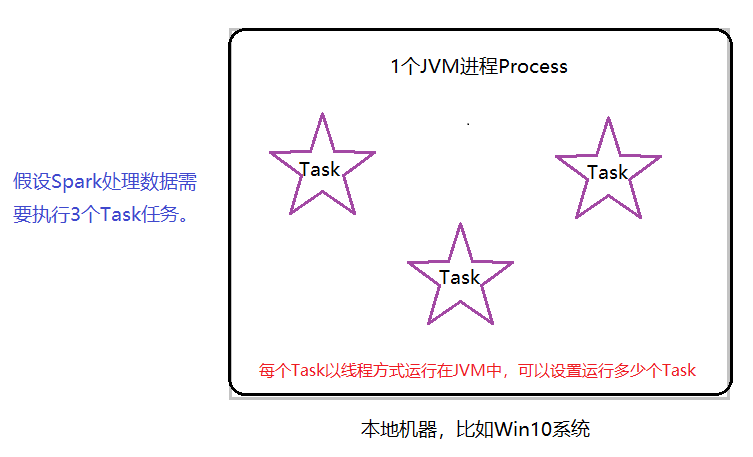
本地模式运行Spark应用程序时,可以设置同时最多运行多少个Task任务,称为并行度:
parallelism
07-[了解]-Spark 快速入门【环境准备】
目前Spark最新稳定版本:
2.4.x系列,官方推荐使用的版本,也是目前企业中使用较多版本,网址:https://github.com/apache/spark/releases
本次Spark课程所使用的集群环境为3台虚拟机,否则就是1台虚拟机,安装CentOS 7.7系统:
[按照【附录二】导入拷贝虚拟机到VMWare软件中即可。
- 系统用户及密码
超级管理员用户:root/123456
普通用户:itcast/itcast
- 虚拟机安装环境及快照
- 在node1虚拟机中很多快照
- 软件安装目录为:【
/export/server】,Hadoop离线框架使用CDH-5.16.2版本
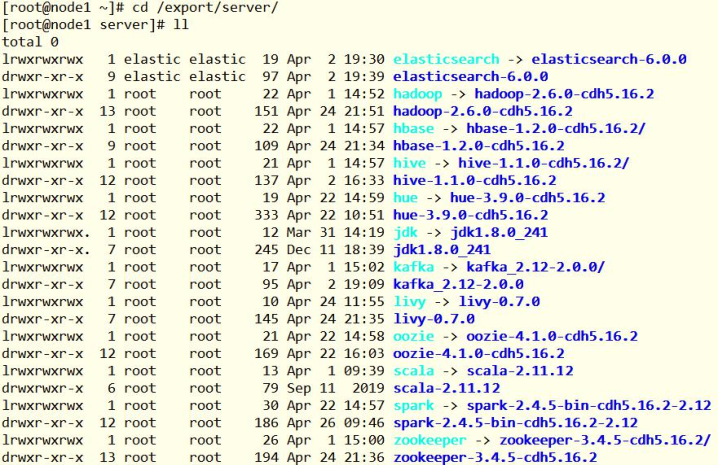
提供虚拟机中,已经针对Spark 2.4.5进行编译,说明如下:
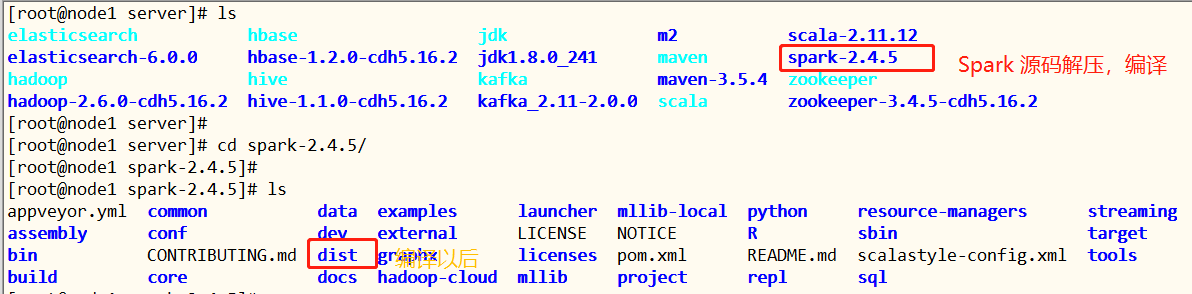
将编译以后tar文件拷贝到【
/export/software】目录中

08-[掌握]-Spark 快速入门【本地模式】
将编译完成spark安装包【
spark-2.4.5-bin-cdh5.16.2-2.11.tgz】解压至【/export/server】目录:
## 解压软件包
tar -zxf /export/software/spark-2.4.5-bin-cdh5.16.2-2.11.tgz -C /export/server/
## 创建软连接,方便后期升级
ln -s /export/server/spark-2.4.5-bin-cdh5.16.2-2.11 /export/server/spark
其中各个目录含义如下:
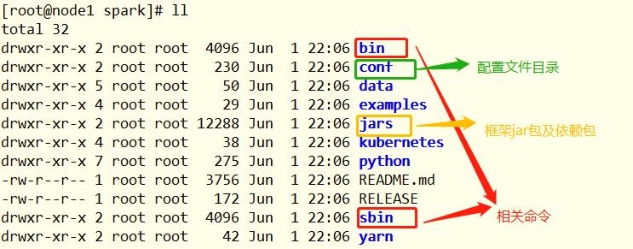
针对Spark进行基本配置

修改配置文件名称以后,进行基本环境变量设置
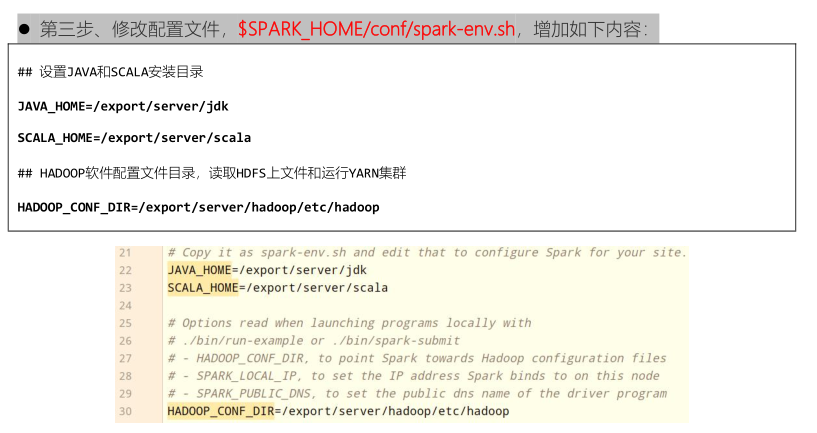
启动HDFS集群,从HDFS上读取数据文件
# 启动NameNode
hadoop-daemon.sh start namenode
# 启动DataNode
hadoop-daemon.sh start datanode
09-[掌握]-Spark 快速入门【运行spark-shell】
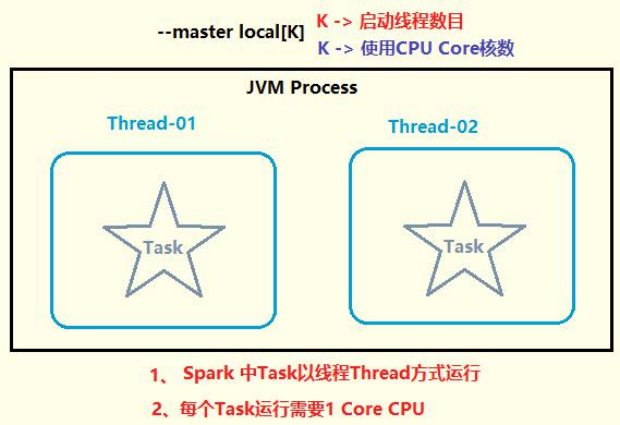
本地模式运行Spark框架提供交互式命令行:spark-shell,其中本地模式LocalMode含义为:启动一个JVM Process进程,执行任务Task,使用方式如下:

1、--master local
JVM进程中启动1个线程运行Task任务
此时没有并行计算概念
2、--master local[K]
K 大于等于2正整数
表示在JVM进程中可以同时运行K个Task任务,都是线程Thread方式运行
3、--master local[*]
表示由程序获取当前运行应用程序机群上CPU Core核数
本地模式启动spark-shell:
## 进入Spark安装目录
cd /export/server/spark
## 启动spark-shell
bin/spark-shell --master local[2]
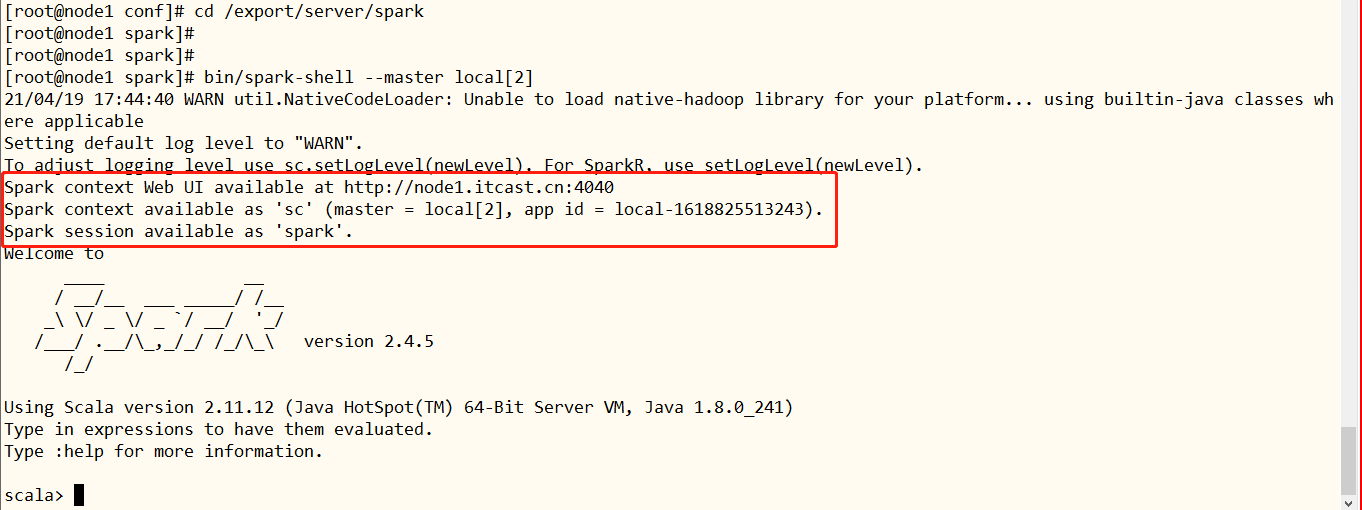
其中创建SparkContext实例对象:
sc、SparkSession实例对象:spark和启动应用监控页面端口号:4040,详细说明如下:每个Spark 应用运行时,都提供WEB UI 监控页面:4040端口号

## 上传HDFS文件
hdfs dfs -mkdir -p /datas/
hdfs dfs -put /export/server/spark/README.md /datas
## 读取文件
val datasRDD = sc.textFile("/datas/README.md")
## 条目数
datasRDD.count
## 获取第一条数据
datasRDD.first
10-[掌握]-Spark 快速入门【词频统计WordCount】
大数据框架经典案例:词频统计WordCount,从文件读取数据,统计单词个数。
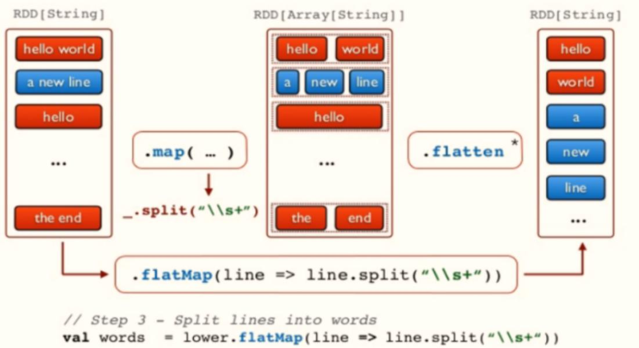
使用Spark编程实现,分为三个步骤:
1、第一步、从HDFS读取文件数据,
sc.textFile方法,将数据封装到RDD中
2、第二步、调用RDD中高阶函数,
进行处理转换处理,函数:flapMap、map和reduceByKey
3、第三步、将最终处理结果
RDD保存到HDFS或打印控制台
Scala集合类中高阶函数flatMap与map函数区别**,map函数:会对每一条输入进行指定的func操作,然后为每一条输入返回一个对象;flatMap函数:先映射后扁平化;**
Scala中
reduce函数使用案例如下:
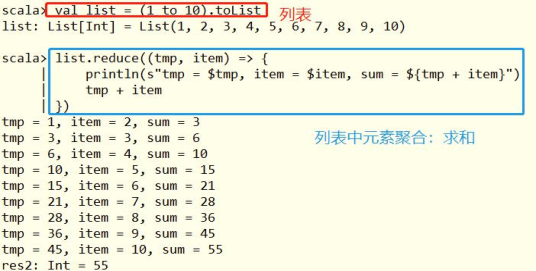
面试题:
Scala集合类List列表中,高级函数:reduce、reduceLeft和reduceRight区别????
在Spark数据结构RDD中reduceByKey函数,相当于MapReduce中shuffle和reduce函数合在一起:按照Key分组,将相同Value放在迭代器中,再使用reduce函数对迭代器中数据聚合。
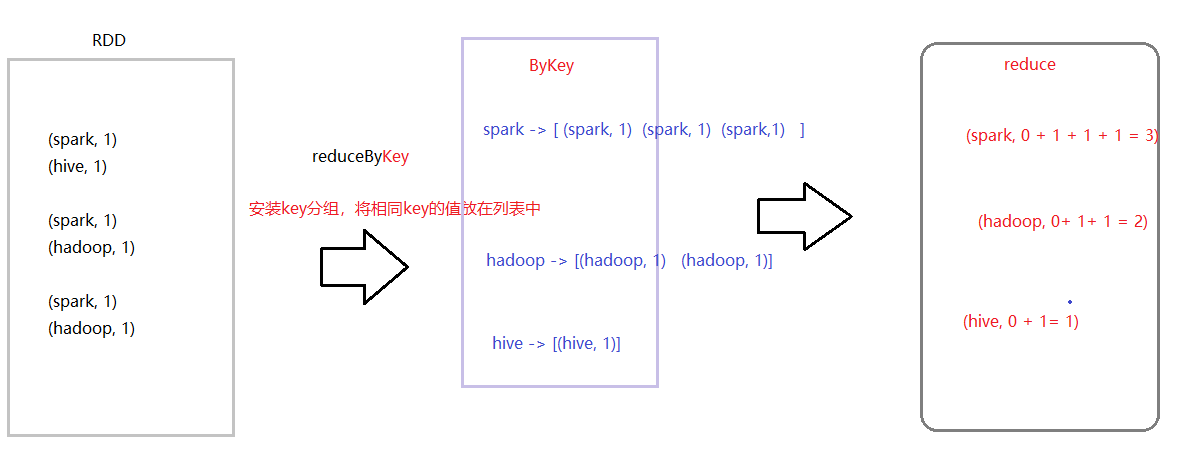
准备数据文件:wordcount.data,内容如下,上传HDFS目录【/datas/
## 创建文件
vim wordcount.data
## 内容如下
spark spark hive hive spark hive
hadoop sprk spark
## 上传HDFS
hdfs dfs -put wordcount.data /datas/
编写代码进行词频统计:
## 读取HDFS文本数据,封装到RDD集合中,文本中每条数据就是集合中每条数据
val inputRDD = sc.textFile("/datas/wordcount.data")
## 将集合中每条数据按照分隔符分割,使用正则:https://www.runoob.com/regexp/regexp-syntax.html
val wordsRDD = inputRDD.flatMap(line => line.split("\s+"))
## 转换为二元组,表示每个单词出现一次
val tuplesRDD = wordsRDD.map(word => (word, 1))
# 按照Key分组,对Value进行聚合操作, scala中二元组就是Java中Key/Value对
## reduceByKey:先分组,再聚合
val wordcountsRDD = tuplesRDD.reduceByKey((tmp, item) => tmp + item)
## 查看结果
wordcountsRDD.take(5)
## 保存结果数据到HDFs中
wordcountsRDD.saveAsTextFile("/datas/spark-wc")
## 查结果数据
hdfs dfs -text /datas/spark-wc/par*
11-[理解]-Spark 快速入门【WEB UI监控】
每个Spark Application应用运行时,启动WEB UI监控页面,默认端口号为4040,使用浏览器打开页面,如下:
如果4040端口号被占用,默认情况下,自动后推端口号,尝试4041,4042,。。。,直到可用
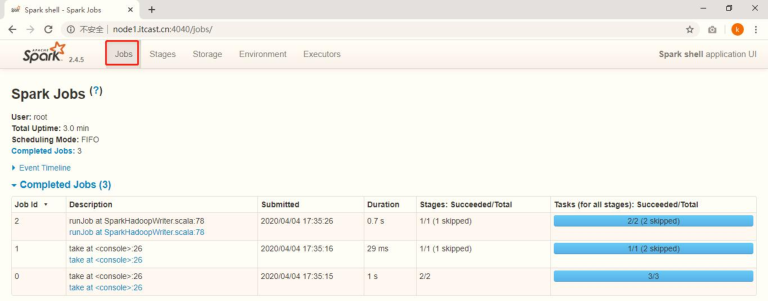
点击【Job 2】,进入到此Job调度界面,通过DAG图展示,具体含义后续再讲。
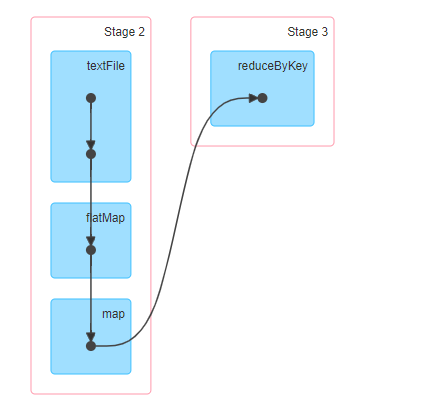
- 1)、第一点、黑色点,表示RDD数据集
- 2)、第二点、蓝色矩形框,表示调用函数,产出RDD
- 3)、第三点、有2中类型线,垂直向下直线和有向S型曲线:产生
Shuffle,意味着需要将数据写入磁盘
12-[了解]-Spark 快速入门【运行圆周率PI】
Spark框架自带的案例Example中涵盖圆周率PI计算程序,可以使用【
$PARK_HOME/bin/spark-submit】提交应用执行,运行在本地模式。
- 自带案例jar包:【/export/server/spark/examples/jars/spark-examples_2.11-2.4.5.jar】
- 提交运行PI程序
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit
--master local[2]
--class org.apache.spark.examples.SparkPi
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar
10
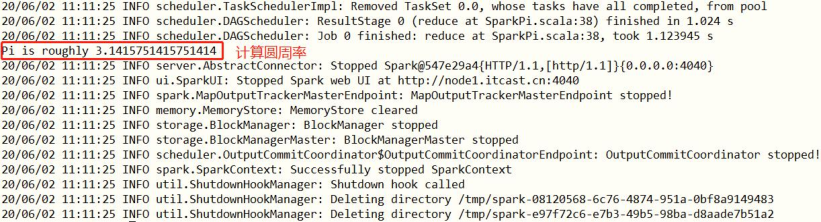
Spark中自带圆周率PI程序,采用蒙特卡洛估算算法计算的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IG5NRA7a-1625406507867)(/img/image-20210419183112123.png)]
附录一、创建Maven模块
1)、Maven 工程结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-merImWMx-1625406507868)(img/1595891933073.png)]
MAVEN工程GAV三要素:
<parent>
<artifactId>bigdata-spark_2.11</artifactId>
<groupId>cn.itcast.spark</groupId>
<version>1.0.0</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>spark-chapter01_2.11</artifactId>
2)、POM 文件内容
Maven 工程POM文件中内容(依赖包):
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
IDEA中配置远程连接服务器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e2fJeQzR-1625406507869)(/img/1605688796757.png)]
附录二、导入虚拟机
步骤一:设置VMWare 网段地址
【编辑】->【虚拟网络编辑器】
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-niQYA1mY-1625406507869)(img/1599709639408.png)]
更改设置:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lkEpAzEd-1625406507870)(img/1599709683354.png)]
最后确定即可。
步骤二:导入虚拟机至VMWare
注意:VMWare 虚拟化软件版本:12.5.5
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3g6kDbgC-1625406507870)(img/1599709239714.png)]
虚拟机解压目录:D:NewSparkLectureSparkLinux
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HoAlszUG-1625406507871)(img/1599709323673.png)]
选择虚拟机中vmx文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0tAt5oyb-1625406507871)(img/1599709367924.png)]
步骤三:启动虚拟机
当启动虚拟机时,弹出如下对话框,选择【我已移动改虚拟机】
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pYAV82Qn-1625406507872)(img/1599696341000.png)]
步骤四:配置主机名和IP地址映射
文件路径:
C:WindowsSystem32driversetchosts内容如下:
192.168.88.100 node1.itcast.cn node1 192.168.88.101 node2.itcast.cn node2 192.168.88.102 node3.itcast.cn node3
可。
步骤二:导入虚拟机至VMWare
注意:VMWare 虚拟化软件版本:12.5.5
[外链图片转存中…(img-3g6kDbgC-1625406507870)]
虚拟机解压目录:D:NewSparkLectureSparkLinux
[外链图片转存中…(img-HoAlszUG-1625406507871)]
选择虚拟机中vmx文件
[外链图片转存中…(img-0tAt5oyb-1625406507871)]
步骤三:启动虚拟机
当启动虚拟机时,弹出如下对话框,选择【我已移动改虚拟机】
[外链图片转存中…(img-pYAV82Qn-1625406507872)]
步骤四:配置主机名和IP地址映射
文件路径:
C:WindowsSystem32driversetchosts内容如下:
192.168.88.100 node1.itcast.cn node1 192.168.88.101 node2.itcast.cn node2 192.168.88.102 node3.itcast.cn node3
最后
以上就是魔幻石头最近收集整理的关于Note_Spark_Day01:Spark 基础环境Spark Day01:Spark 基础环境的全部内容,更多相关Note_Spark_Day01:Spark内容请搜索靠谱客的其他文章。








发表评论 取消回复