目录
- 爬取有道翻译,获取翻译结果
- 项目最终的效果
- 本次爬虫所用到的库
- 开始爬虫!!!
- 变动参数进行获取
- 到这里需要提交的参数就收集完毕了,附上代码
- 附上主爬虫程序的代码
- 制作窗口
- 最后一步,附上源代码包括所用到的库;
- 最后实现的效果!
爬取有道翻译,获取翻译结果
通过python爬虫代码,结合tkinter模块,将爬虫的内容进行窗口化显示
项目最终的效果
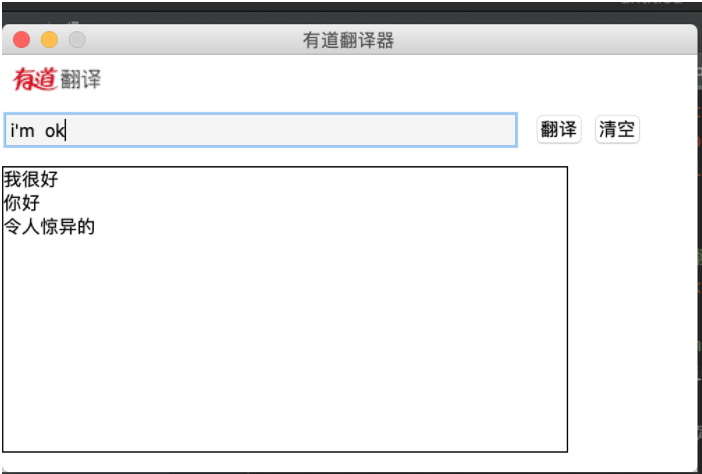
本次爬虫所用到的库
import requests
import time
import random
import hashlib
import tkinter as tk
开始爬虫!!!
第一步进入:有道翻译界面:http://fanyi.youdao.com/
使用谷歌浏览器,右击鼠标点击检查,点击Network
输入内容点击翻译后查看XHR,这里有向服务器发送的表单内容
获取向服务器提交的表单Form,后续通过向服务器提交Form 获取翻译结果
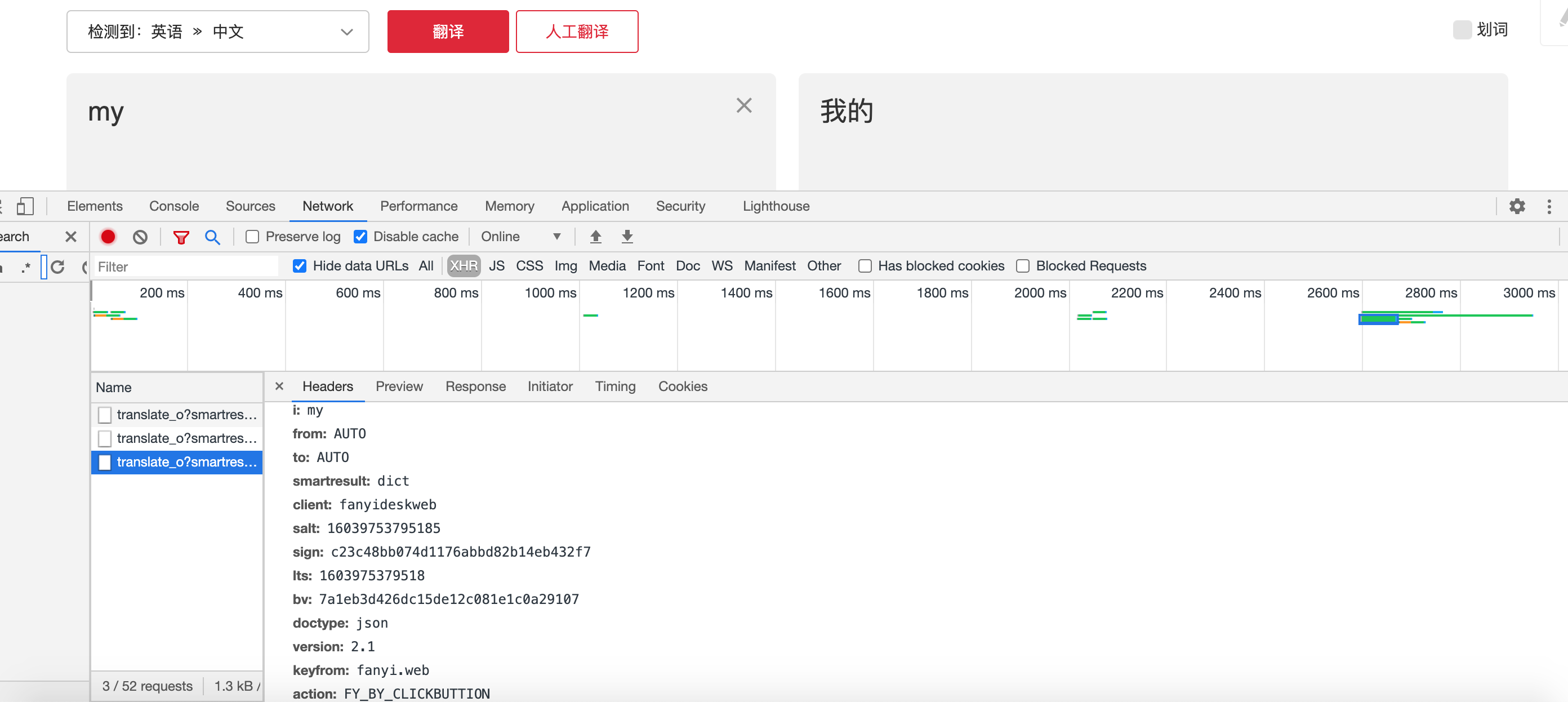
多次尝试翻译不同内容,每翻译一次都会出现一个表单,表示浏览器向服务器提交过我们翻译的内容
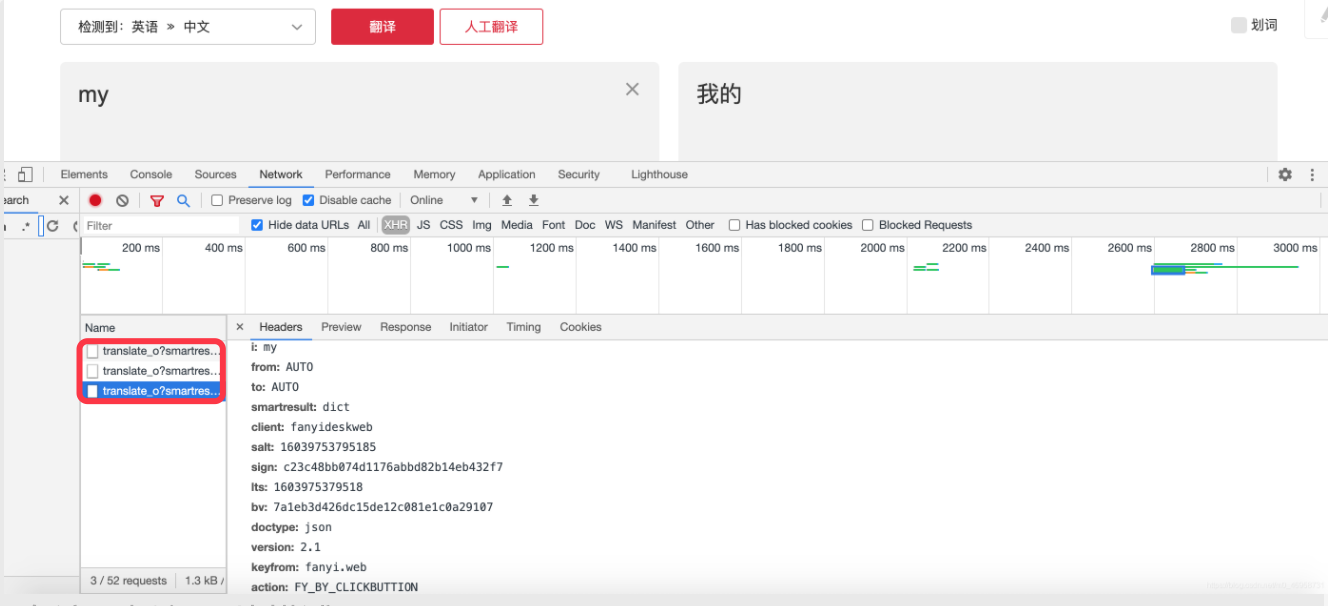
结果打开每一个表单,查看下面的内容,发现有3个参数不断在变化,那么我们就需要对这3个参数进行获取后,就可以通过爬虫和浏览器一样对服务器发送表单请求,最终获取翻译结果
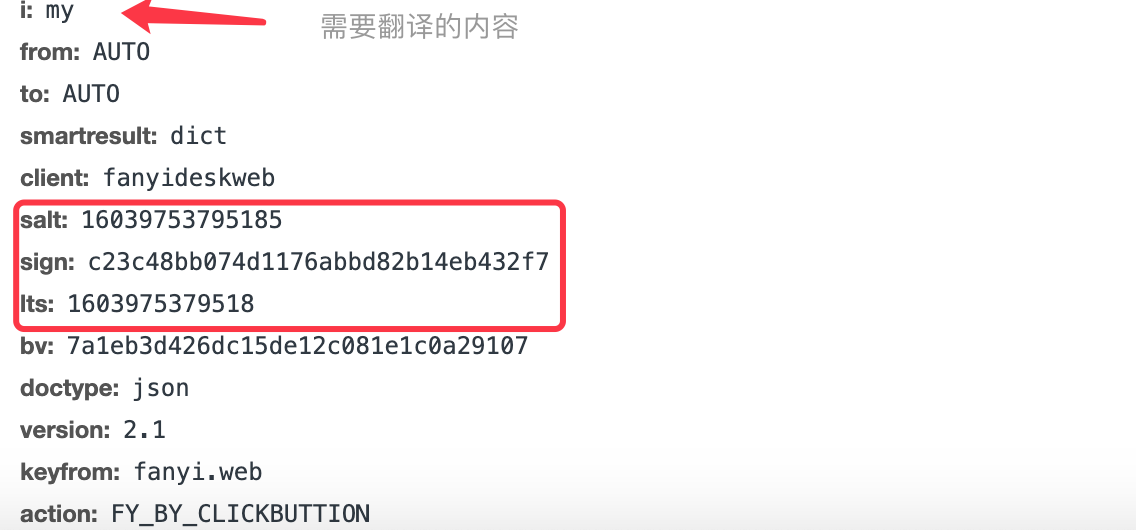
变动参数进行获取
先对salt参数进行搜索,发现以下:
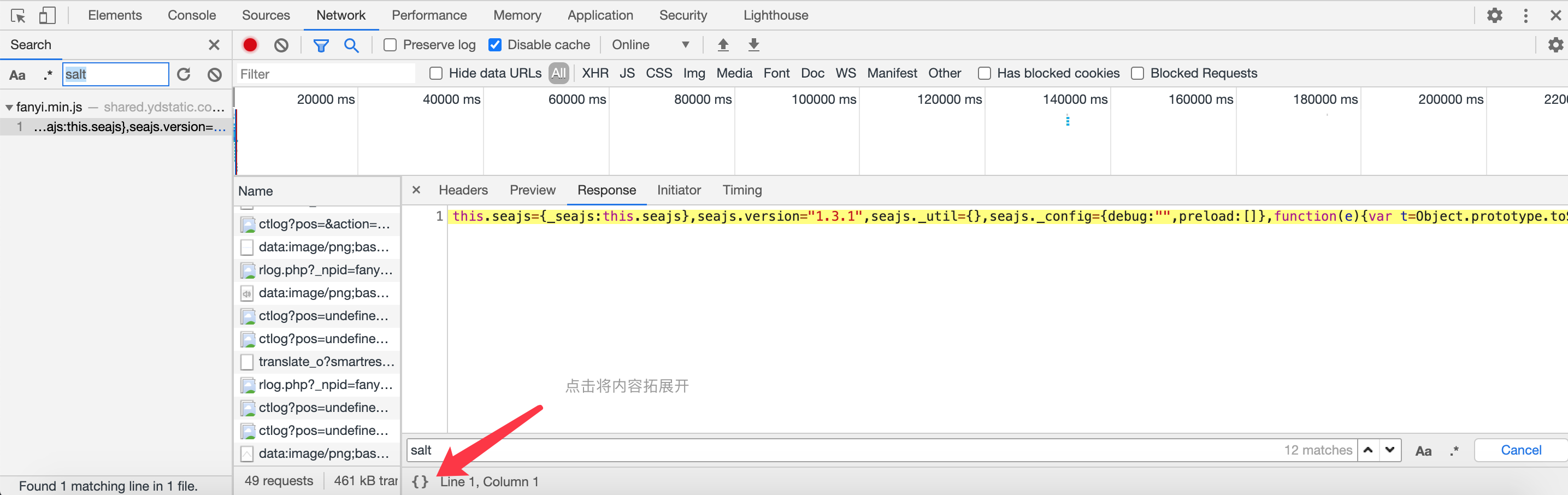
查询到 salt 参数的来源,观察下面的salt 它来自一个叫 i的变量
这里我们还发现一个叫ts ,对!它就是前面表单里面变动的3个参数之一 lts,它来自变量r,那么我们根据它们的写法,我们通过python实现出来
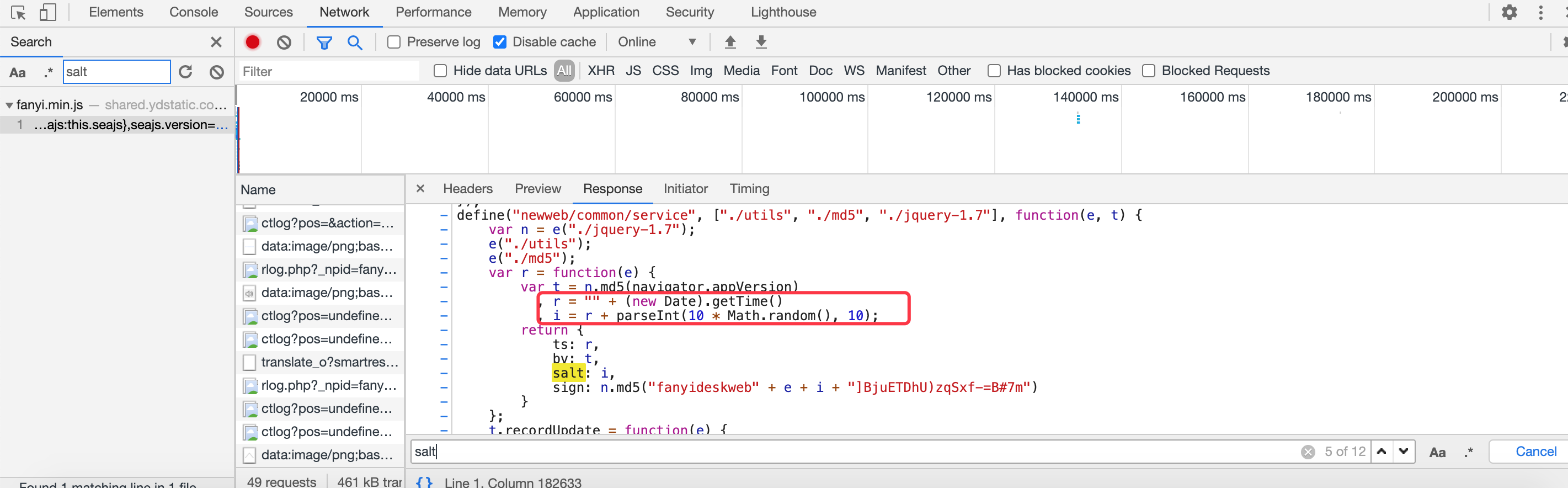
使用python代码进行实现 get_ts这个函数 r变量模拟出来
# 获取时间戳
def get_ts(): # lts 参数
return str(int(time.time()) * 1000) # 它获取的就是一个时间戳
# 获取salt参数
def get_salt(ts): # 模拟网页的写法,
return str(int(ts) + 10 * int(random.random() * 10))
ts = get_ts()
salt = get_salt(ts)
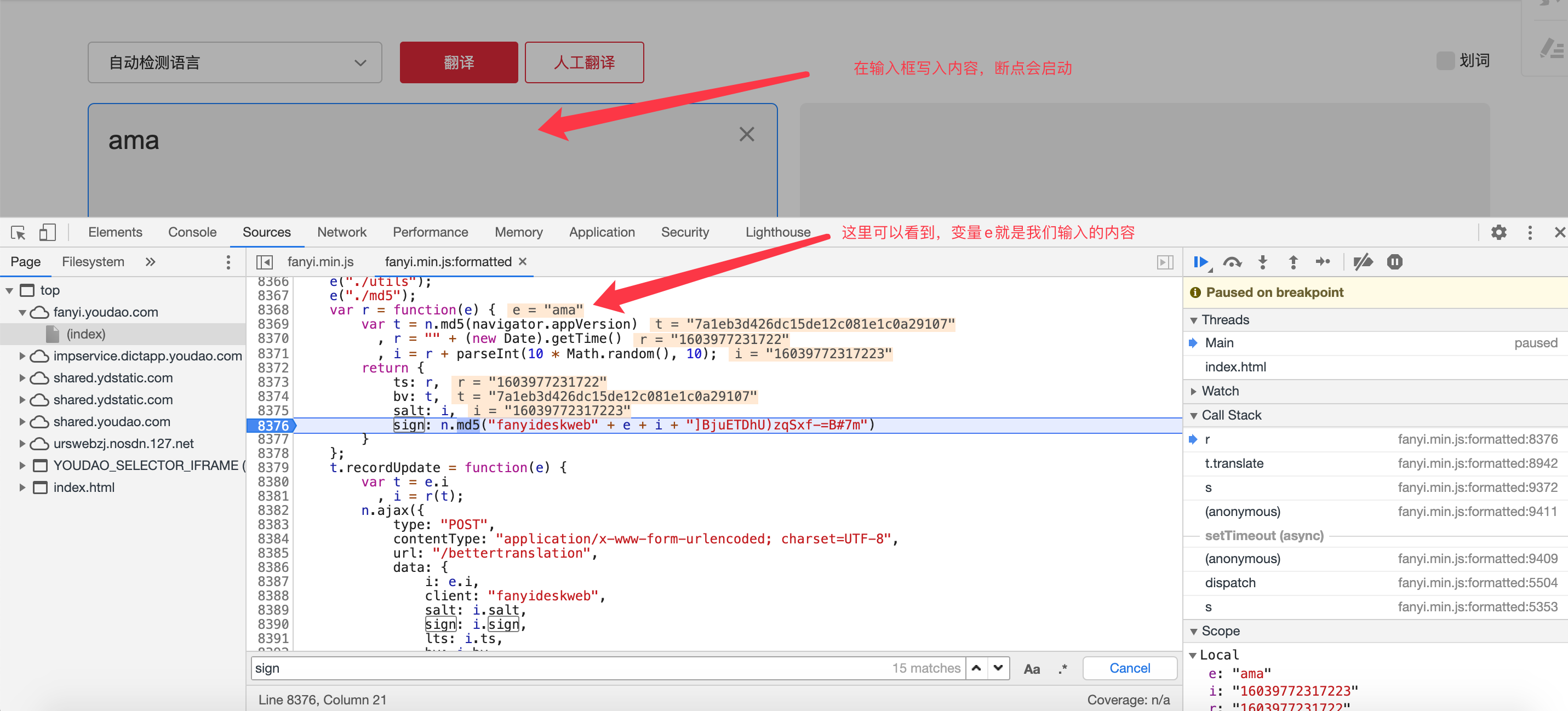
目前只需要获取sign就完成了参数的收集,sigin 里面的变量 i 我们已经获取出来,那么就差获取变量e了,

只要找到变量e 按照它的写法可以完成拼接
通过查询找到相关文件以后,右击鼠标打开它的源码
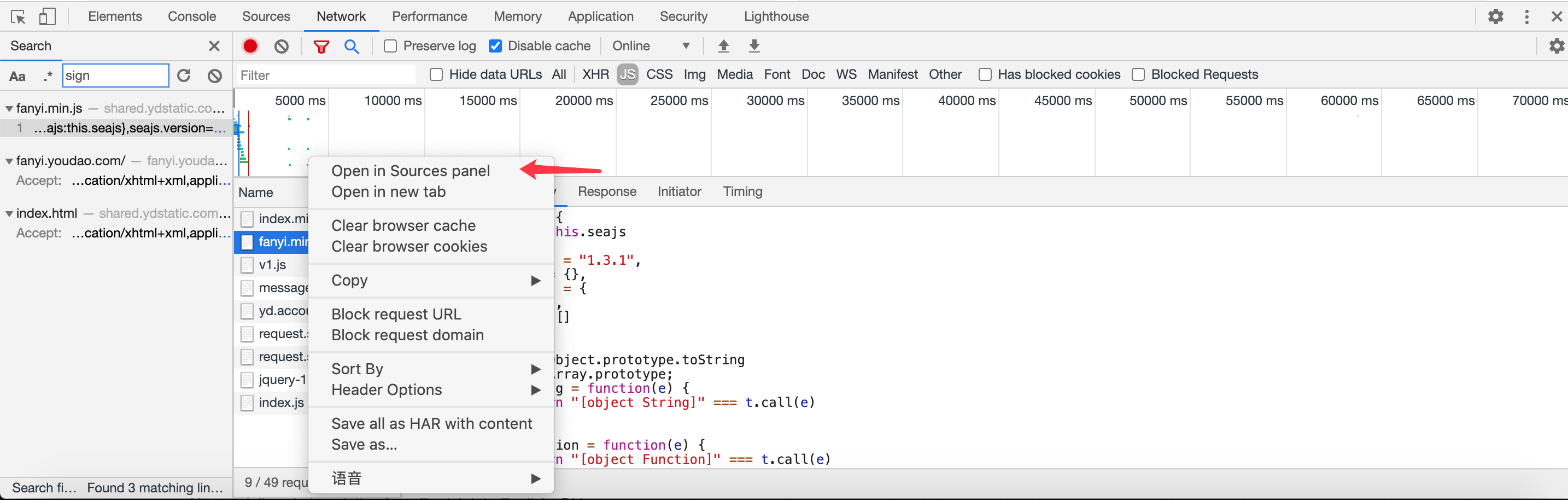
这里获取变量e 需要进入断点模式
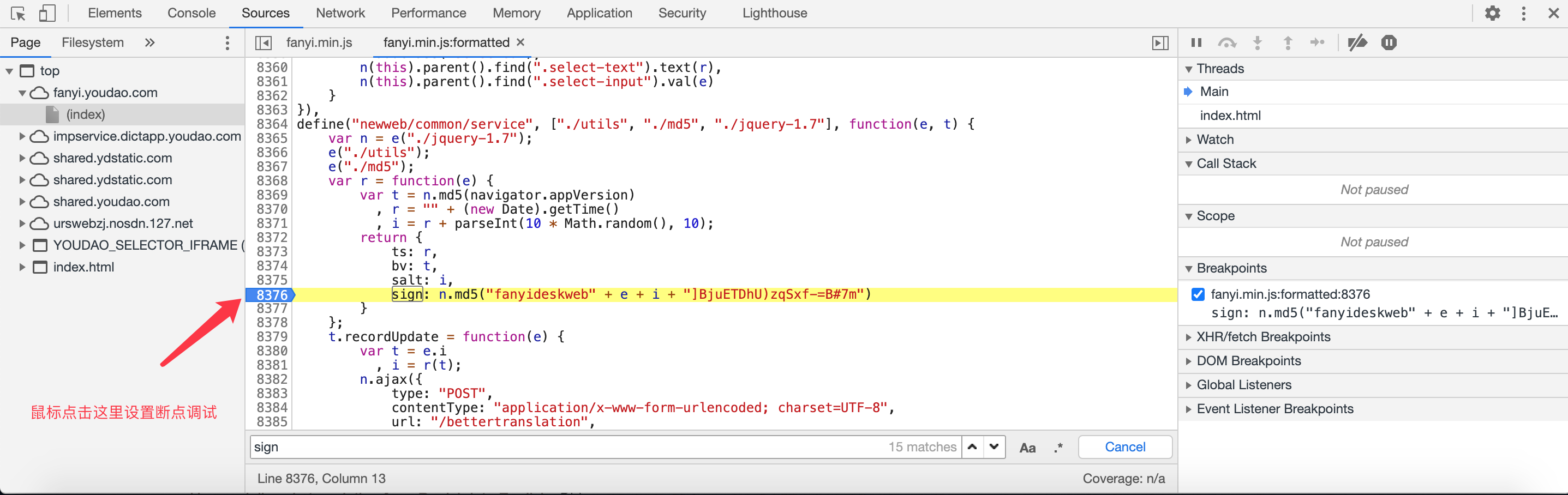
会根据网页变动,随后自动进入断点模式
到这里需要提交的参数就收集完毕了,附上代码
# 获取时间戳
def get_ts():
return str(int(time.time()) * 1000)
# 获取salt参数
def get_salt(ts):
return str(int(ts) + 10 * int(random.random() * 10))
# 获取sign参数
def get_sign(salt):
str1 = text1.get() # 待会我们手动输入的内容
# 根据网页一样对数据进行拼接,将我们知道的参数放进去
str_data = "fanyideskweb" + str(str1) + str(salt) + "]BjuETDhU)zqSxf-=B#7m"
m = hashlib.md5() # 和web一样,通过md5加密
m.update(str_data.encode('utf-8')) # 转换编码格式
return m.hexdigest()
# 提交表单
def get_form_date():
i = text1.get() # 这里是获取我们待会手动输入的内容
ts = get_ts() # lts参数的内容
salt = get_salt(ts) # salt参数的内容
sign = get_sign(salt) # sign参数的内容
# 只需要将其它的参数复制进来,通过字典存好,再将变动的参数放入进去
form_date = { # 提交表单需要的参数
"i":i,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt, # 将这些变动的参数携带进去
"sign": sign,
"lts": ts,
"bv": "7a1eb3d426dc15de12c081e1c0a29107",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_CLICKBUTTION",
}
return form_date
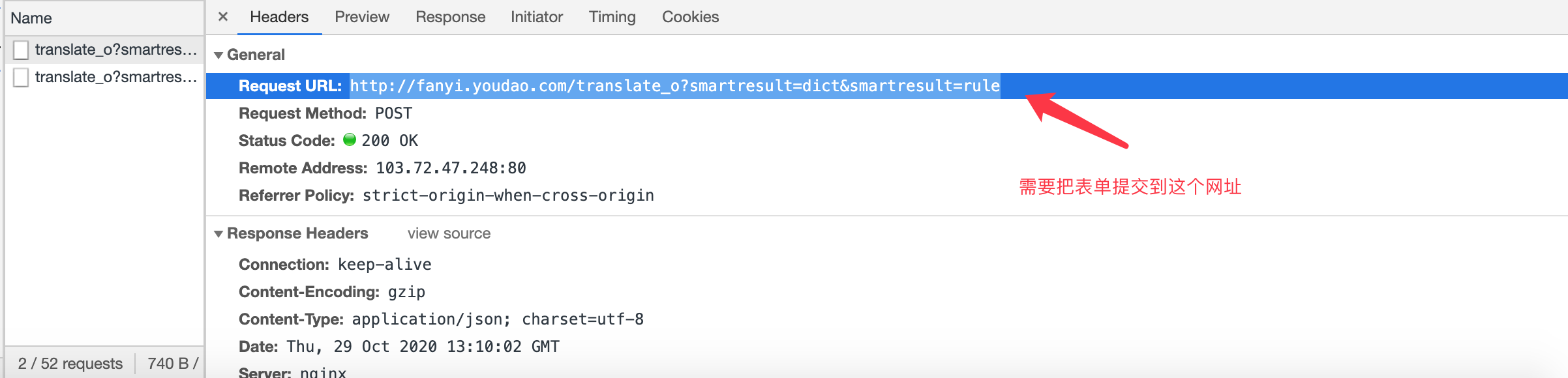
表单提交的地址:
http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
附上主爬虫程序的代码
# 爬虫程序
def translation():
try: # url为表单提交的地址
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Referer': 'http://fanyi.youdao.com/',
'Cookie': 'OUTFOX_SEARCH_USER_ID=-8708981@10.169.0.84; JSESSIONID=aaayNmYzh0w30eikOe-px; OUTFOX_SEARCH_USER_ID_NCOO=1193613658.5619643; ___rl__test__cookies=1597714436900'
}
# 向服务端提交post请求,data携带表单数据
response = requests.post(url,data=get_form_date(),headers=headers)
# 获取翻译的最终结果,类似于对字典取值
response = response.json()['translateResult'][0][0]['tgt']
display_info.insert(0,response) # 后续结果放到窗口界面
return response
except:
display_info.insert(0,'未找到内容')
制作窗口
# 窗口删除内容
def delete():
text1.delete(0,'end') # 清空输入框内容
display_info.delete(0,'end') # 清空文本框内容
if __name__ == '__main__':
window = tk.Tk() # 定义窗口界面
window.title("有道翻译器") # 窗口标题
window.geometry('500x300') # 图形窗口的大小
window.resizable(width=False, height=False)
text1 = tk.Entry(window,width=40,bg='whitesmoke') # 定义输入文本框
display_info = tk.Listbox(window, width=45, height=12) # 翻译结果文本框的大小
# 定义翻译按钮
t_button = tk.Button(window,text='翻译',command=translation) # 调用爬虫程序
clear_button = tk.Button(window,text='清空',command=delete) # 清除窗口内容
img_gif = tk.PhotoImage(file = 'you_img.gif') # 图片的定义
label_img = tk.Label(window,image=img_gif) # 图片的显示
label_img.place(x=0,y=0) # 图片位置定义
text1.place(x=0,y=40,anchor='nw') # 输入框位置的定义
t_button.place(x=400,y=43,anchor='n') # 按钮位置的定义
clear_button.place(x=460,y=43,anchor='ne') # 清除按钮位置的定义
display_info.place(x=0,y=80) # 翻译结果文本框的位置
window.mainloop() # 将窗口显示出来
注意:图片必须是gif格式的,附上图片转换的网页:http://pic.55.la/
最后一步,附上源代码包括所用到的库;
import requests
import time
import random
import hashlib
import tkinter as tk
# 程序所用到的库
# 获取时间戳
def get_ts():
return str(int(time.time()) * 1000)
# 获取salt参数
def get_salt(ts):
return str(int(ts) + 10 * int(random.random() * 10))
# 获取sign参数
def get_sign(salt):
str1 = text1.get() # 待会我们手动输入的内容
# 根据网页一样对数据进行拼接,将我们知道的参数放进去
str_data = "fanyideskweb" + str(str1) + str(salt) + "]BjuETDhU)zqSxf-=B#7m"
m = hashlib.md5() # 和web一样,通过md5加密
m.update(str_data.encode('utf-8')) # 转换编码格式
return m.hexdigest()
# 提交表单
def get_form_date():
i = text1.get() # 这里是获取我们待会手动输入的内容
ts = get_ts() # lts参数的内容
salt = get_salt(ts) # salt参数的内容
sign = get_sign(salt) # sign参数的内容
# 只需要将其它的参数复制进来,通过字典存好,再将变动的参数放入进去
form_date = { # 提交表单需要的参数
"i":i,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt, # 将这些变动的参数携带进去
"sign": sign,
"lts": ts,
"bv": "7a1eb3d426dc15de12c081e1c0a29107",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_CLICKBUTTION",
}
return form_date
# 爬虫程序
def translation():
try: # 表单提交的地址
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Referer': 'http://fanyi.youdao.com/',
'Cookie': 'OUTFOX_SEARCH_USER_ID=-8708981@10.169.0.84; JSESSIONID=aaayNmYzh0w30eikOe-px; OUTFOX_SEARCH_USER_ID_NCOO=1193613658.5619643; ___rl__test__cookies=1597714436900'
}
# 向服务端提交post请求,data携带表单数据
response = requests.post(url,data=get_form_date(),headers=headers)
# 获取翻译的最终结果,类似于对字典取值
response = response.json()['translateResult'][0][0]['tgt']
display_info.insert(0,response) # 后续结果放到窗口界面
return response
except:
display_info.insert(0,'未找到内容')
# 窗口删除内容
def delete():
text1.delete(0,'end') # 清空输入框内容
display_info.delete(0,'end') # 清空文本框内容
if __name__ == '__main__':
window = tk.Tk() # 定义窗口界面
window.title("有道翻译器") # 窗口标题
window.geometry('500x300') # 图形窗口的大小
window.resizable(width=False, height=False)
text1 = tk.Entry(window,width=40,bg='whitesmoke') # 定义输入文本框
display_info = tk.Listbox(window, width=45, height=12) # 翻译结果文本框的大小
# 定义翻译按钮
t_button = tk.Button(window,text='翻译',command=translation) # 调用爬虫程序
clear_button = tk.Button(window,text='清空',command=delete) # 清除窗口内容
img_gif = tk.PhotoImage(file = 'you_img.gif') # 图片的定义
label_img = tk.Label(window,image=img_gif) # 图片的显示
label_img.place(x=0,y=0) # 图片位置定义
text1.place(x=0,y=40,anchor='nw') # 输入框位置的定义
t_button.place(x=400,y=43,anchor='n') # 按钮位置的定义
clear_button.place(x=460,y=43,anchor='ne') # 清除按钮位置的定义
display_info.place(x=0,y=80) # 翻译结果文本框的位置
window.mainloop() # 将窗口显示出来
最后实现的效果!
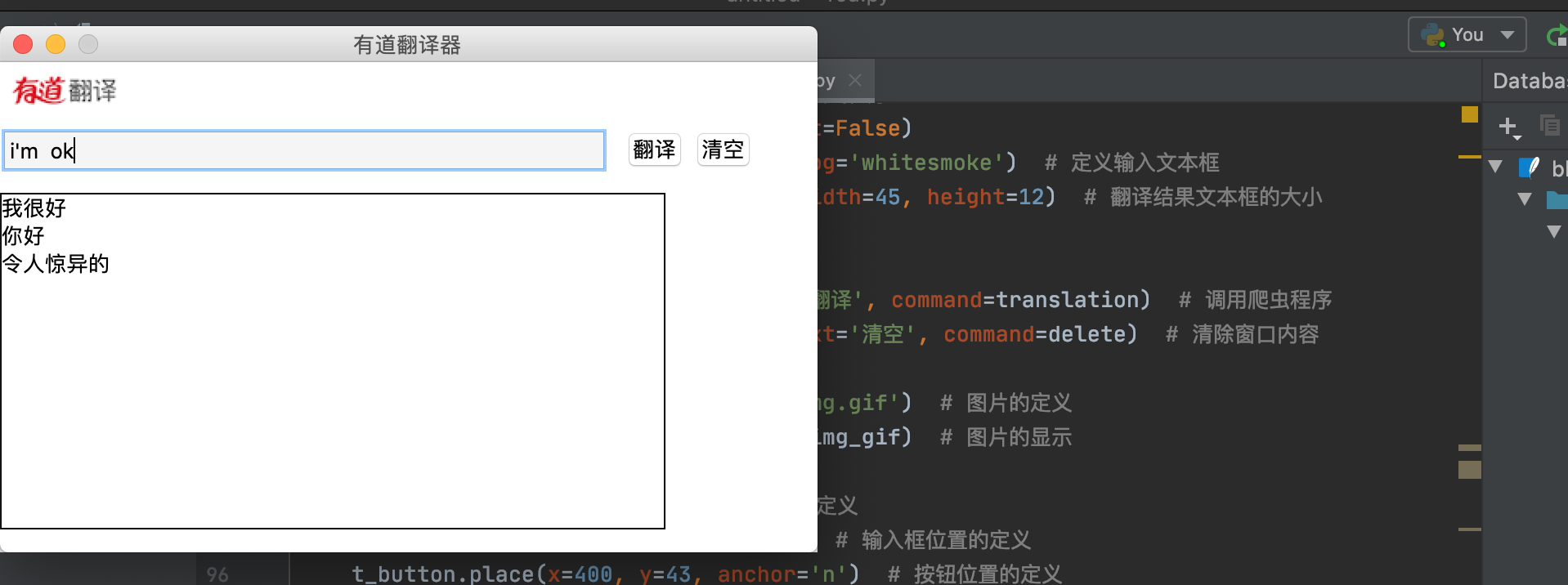
快动手操作一下吧!
技术小白记录学习过程,有错误或不解的地方请指出,如果这篇文章对你有所帮助请
点赞收藏+关注谢谢支持!
最后
以上就是光亮外套最近收集整理的关于Python爬虫实战:爬取有道翻译(窗口化显示)爬取有道翻译,获取翻译结果的全部内容,更多相关Python爬虫实战:爬取有道翻译(窗口化显示)爬取有道翻译内容请搜索靠谱客的其他文章。








发表评论 取消回复