前言
各位,七夕快到了,想好要送什么礼物了吗?
昨天有朋友私信我,问我能用Python分析下网上小猫咪的数据,是想要送一只给女朋友,当做礼物。
Python从零基础入门到实战系统教程、源码、视频
网上的数据太多、太杂,而且我也不知道哪个网站的数据比较好。所以,只能找到一个猫咪交易网站的数据来分析了
地址:
http://www.maomijiaoyi.com/
爬虫部分
请求数据
import requests
url = f'http://www.maomijiaoyi.com/index.php?/chanpinliebiao_c_2_1--24.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
解析数据
# 把获取到的 html 字符串数据转换成 selector 对象 这样调用
selector = parsel.Selector(response.text)
# css 选择器只要是根据标签属性内容提取数据 编程永远不看过程 只要结果
href = selector.css('.content:nth-child(1) a::attr(href)').getall()
areas = selector.css('.content:nth-child(1) .area .color_333::text').getall()
areas = [i.strip() for i in areas] # 列表推导式
提取标签数据
for index in zip(href, areas):
# http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_224383.html
index_url = 'http://www.maomijiaoyi.com' + index[0]
response_1 = requests.get(url=index_url, headers=headers)
selector_1 = parsel.Selector(response_1.text)
area = index[1]
# getall 取所有 get 取一个
title = selector_1.css('.detail_text .title::text').get().strip()
shop = selector_1.css('.dinming::text').get().strip() # 店名
price = selector_1.css('.info1 div:nth-child(1) span.red.size_24::text').get() # 价格
views = selector_1.css('.info1 div:nth-child(1) span:nth-child(4)::text').get() # 浏览次数
# replace() 替换
promise = selector_1.css('.info1 div:nth-child(2) span::text').get().replace('卖家承诺: ', '') # 浏览次数
num = selector_1.css('.info2 div:nth-child(1) div.red::text').get() # 在售只数
age = selector_1.css('.info2 div:nth-child(2) div.red::text').get() # 年龄
kind = selector_1.css('.info2 div:nth-child(3) div.red::text').get() # 品种
prevention = selector_1.css('.info2 div:nth-child(4) div.red::text').get() # 预防
person = selector_1.css('div.detail_text .user_info div:nth-child(1) .c333::text').get() # 联系人
phone = selector_1.css('div.detail_text .user_info div:nth-child(2) .c333::text').get() # 联系方式
postage = selector_1.css('div.detail_text .user_info div:nth-child(3) .c333::text').get().strip() # 包邮
purebred = selector_1.css(
'.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(1) .c333::text').get().strip() # 是否纯种
sex = selector_1.css(
'.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(4) .c333::text').get().strip() # 猫咪性别
video = selector_1.css(
'.xinxi_neirong div:nth-child(2) .item_neirong div:nth-child(4) .c333::text').get().strip() # 能否视频
worming = selector_1.css(
'.xinxi_neirong div:nth-child(2) .item_neirong div:nth-child(2) .c333::text').get().strip() # 是否驱虫
dit = {
'地区': area,
'店名': shop,
'标题': title,
'价格': price,
'浏览次数': views,
'卖家承诺': promise,
'在售只数': num,
'年龄': age,
'品种': kind,
'预防': prevention,
'联系人': person,
'联系方式': phone,
'异地运费': postage,
'是否纯种': purebred,
'猫咪性别': sex,
'驱虫情况': worming,
'能否视频': video,
'详情页': index_url,
}
保存数据
import csv # 内置模块
f = open('猫咪1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['地区', '店名', '标题', '价格', '浏览次数', '卖家承诺', '在售只数',
'年龄', '品种', '预防', '联系人', '联系方式', '异地运费', '是否纯种',
'猫咪性别', '驱虫情况', '能否视频', '详情页'])
csv_writer.writeheader() # 写入表头
csv_writer.writerow(dit)
print(title, area, shop, price, views, promise, num, age,
kind, prevention, person, phone, postage, purebred, sex, video, worming, index_url, sep=' | ')
得到数据
数据可视化部分
词云图
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
from pyecharts.globals import ThemeType
words = [(i,1) for i in cat_info['品种'].unique()]
c = (
WordCloud(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add("", words,shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title=""))
)
c.render_notebook()

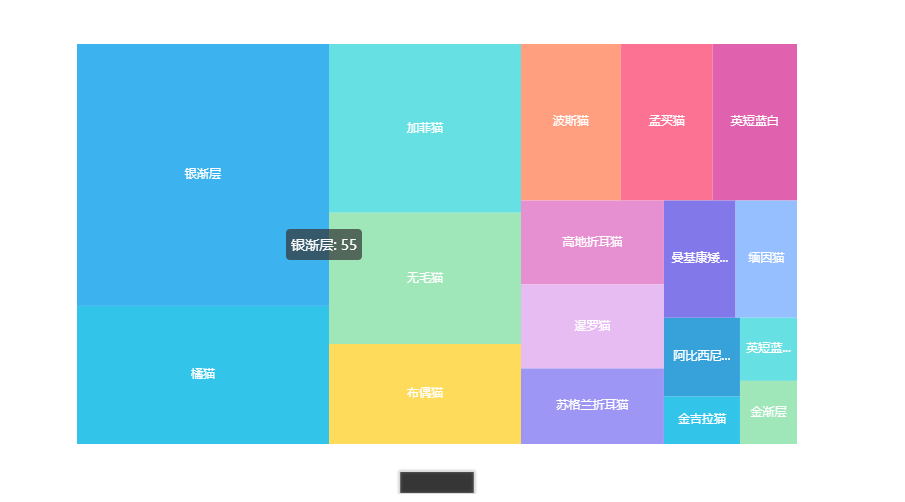
交易品种占比图
from pyecharts import options as opts
from pyecharts.charts import TreeMap
pingzhong = cat_info['品种'].value_counts().reset_index()
data = [{'value':i[1],'name':i[0]} for i in zip(list(pingzhong['index']),list(pingzhong['品种']))]
c = (
TreeMap(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add("", data)
.set_global_opts(title_opts=opts.TitleOpts(title=""))
.set_series_opts(label_opts=opts.LabelOpts(position="inside"))
)
c.render_notebook()
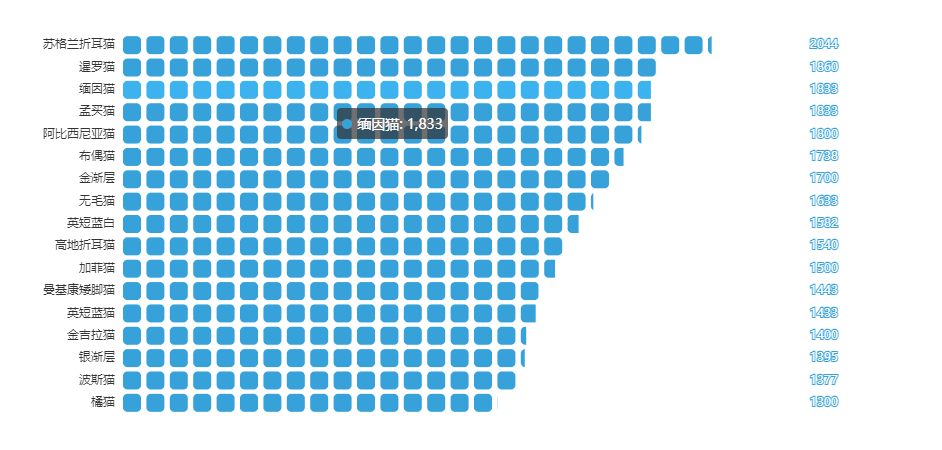
均价占比图
from pyecharts import options as opts
from pyecharts.charts import PictorialBar
from pyecharts.globals import SymbolType
location = list(price['品种'])
values = list(price['价格'])
c = (
PictorialBar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(location)
.add_yaxis(
"",
values,
label_opts=opts.LabelOpts(is_show=False),
symbol_size=18,
symbol_repeat="fixed",
symbol_offset=[0, 0],
is_symbol_clip=True,
symbol=SymbolType.ROUND_RECT,
)
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title="均价排名"),
xaxis_opts=opts.AxisOpts(is_show=False),
yaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(opacity=0),
),
),
)
.set_series_opts(
label_opts=opts.LabelOpts(position='insideRight')
)
)
c.render_notebook()
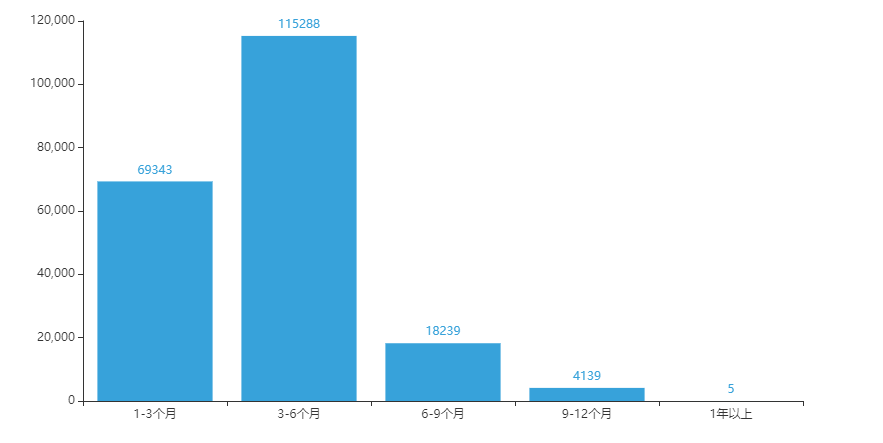
猫龄柱状图
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
x = ['1-3个月','3-6个月','6-9个月','9-12个月','1年以上']
y = [69343,115288,18239,4139,5]
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(x)
.add_yaxis('', y)
.set_global_opts(title_opts=opts.TitleOpts(title="猫龄分布"))
)
c.render_notebook()
最后
以上就是健忘蓝天最近收集整理的关于Python爬虫+数据可视化教学:分析猫咪交易数据前言爬虫部分数据可视化部分的全部内容,更多相关Python爬虫+数据可视化教学内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复