朋友们,我年前在朋友圈分享了一个拉勾信息爬取,不过那个代码写的呢就是有点low~~,那个代码是一次性的,意思是:
代码爬取的只能是一样内容,无法爬取更多的职业信息,而且对于那些对Python不是很了解的同学,使用今天的代码就可以输入想要输入的关键词,然后我们的代码就会爬取相应的职位信息!
Pycharm运行的截图是:
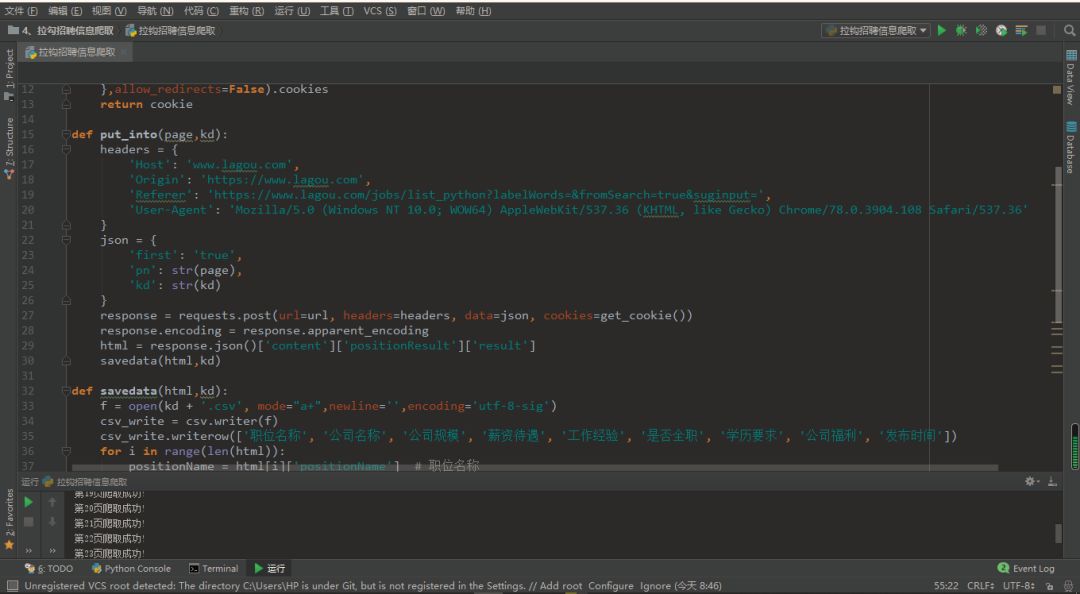

-
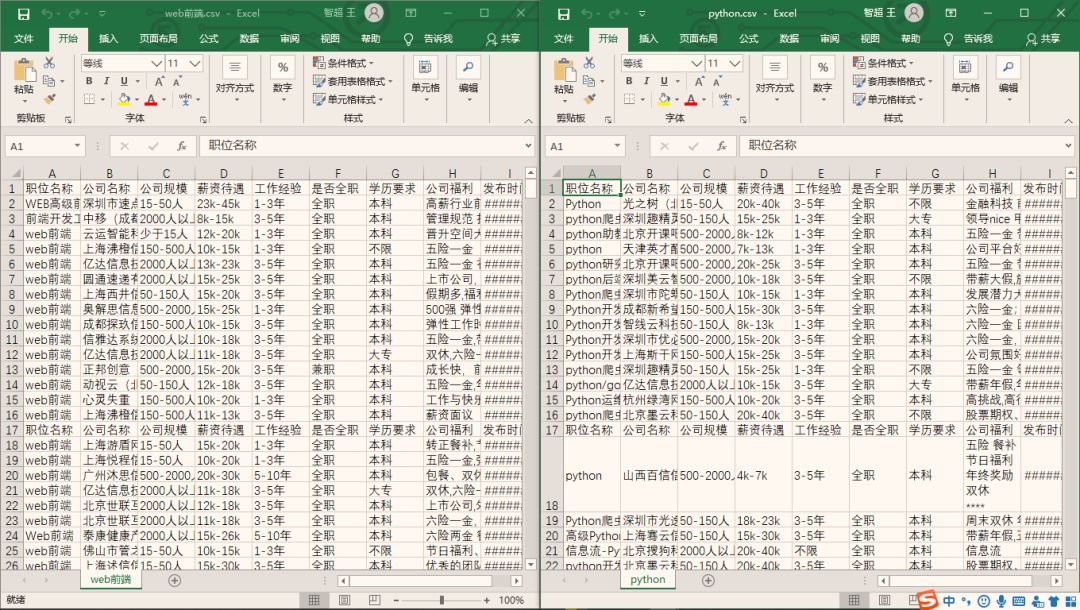
爬取的职业信息,有些是不足30页的,比如:我搜索'敛财'的时候,就会显示5个职业信息,所以我想说的是:大家就不要输入一些奇怪的名词了~~选择职业专有名词就好!
还有就是前面说了,有些职业信息是不足30页的,这时候,你们可以打开官网:
https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=
然后,先查询一下你要查询的职位的页数到底是多少,然后只需把代码的:
for page in range(2,31):
31改成页数-1就ok了!
待改进的内容:
①一个就是一些关键词需要加进去进一步缩小范围(加上下面的一些内容)
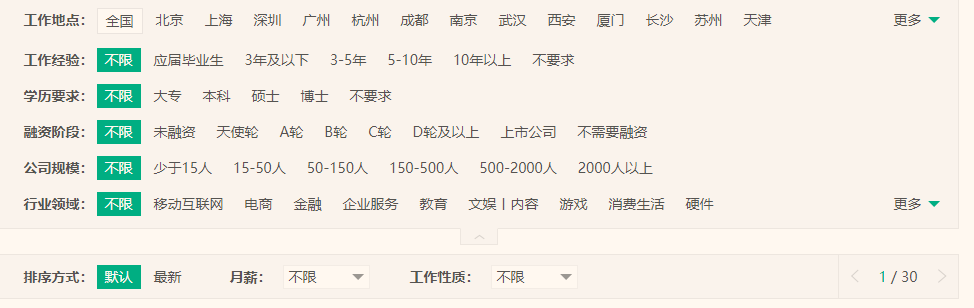
②加上程序爬虫前先查询到该职业有的页数,然后就默认到最高页
最后的最后:"""拉勾是一个典型的ajax异步加载的网站,我们需要找到它的真实url地址在xhr接口那进行分析,真实的url地址,preview或response的时候会显示职位的信息"""import requestsimport csv,timeurl = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'def get_cookie(): cookie = requests.get('https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' },allow_redirects=False).cookies return cookiedef put_into(page,kd): headers = { 'Host': 'www.lagou.com', 'Origin': 'https://www.lagou.com', 'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' } json = { 'first': 'true', 'pn': str(page), 'kd': str(kd) } response = requests.post(url=url, headers=headers, data=json, cookies=get_cookie()) response.encoding = response.apparent_encoding html = response.json()['content']['positionResult']['result'] savedata(html,kd)def savedata(html,kd): f = open(kd + '.csv', mode="a+",newline='',encoding='utf-8-sig') csv_write = csv.writer(f) csv_write.writerow(['职位名称', '公司名称', '公司规模', '薪资待遇', '工作经验', '是否全职', '学历要求', '公司福利', '发布时间']) for i in range(len(html)): positionName = html[i]['positionName'] # 职位名称 companyFullName = html[i]['companyFullName'] # 公司名称 companySize = html[i]['companySize'] # 公司规模 salary = html[i]['salary'] # 薪资待遇 workYear = html[i]['workYear'] # 工作经验 jobNature = html[i]['jobNature'] # 是否全职 education = html[i]['education'] # 学历要求 positionAdvantage = html[i]['positionAdvantage'] # 公司福利 lastLogin = html[i]['lastLogin'] # 发布时间 # print(positionName,companyFullName,companySize,salary,workYear,jobNature,education,positionAdvantage,lastLogin) csv_write.writerow([positionName, companyFullName, companySize, salary, workYear, jobNature, education, positionAdvantage,lastLogin]) f.close()if __name__ == '__main__': kd = str(input('请输入您想爬取的职业方向的关键词:')) for page in range(2,31): put_into(page,kd) print('第'+str(page-1)+'页爬取成功!') time.sleep(2)
关注【空谷小莜蓝】,解锁更多信息!
最后
以上就是狂野篮球最近收集整理的关于i问财 python 爬取_拉勾招聘信息爬取改良版——以后实习就方便啦~的全部内容,更多相关i问财内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复