coroutine库是云风大佬以前写的一个协程库,短小精悍,源码分析在这(https://github.com/theanarkh/read-coroutine-code)。今天就分析一下这个库的原理。话不多说,直接开始。
首先了解一下数据结构。
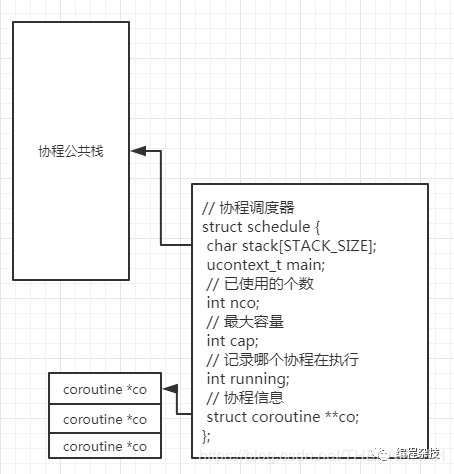
// 记录协程公共数据的结构体
struct schedule {
// 协程的公共栈
char stack[STACK_SIZE];
// 主上下文,不是协程的
ucontext_t main;
// 已使用的个数
int nco;
// 最大容量
int cap;
// 记录哪个协程在执行
int running;
// 协程信息
struct coroutine **co;
};
和进程一样,协程可以用一个结构体来表示。看看协程的表示。
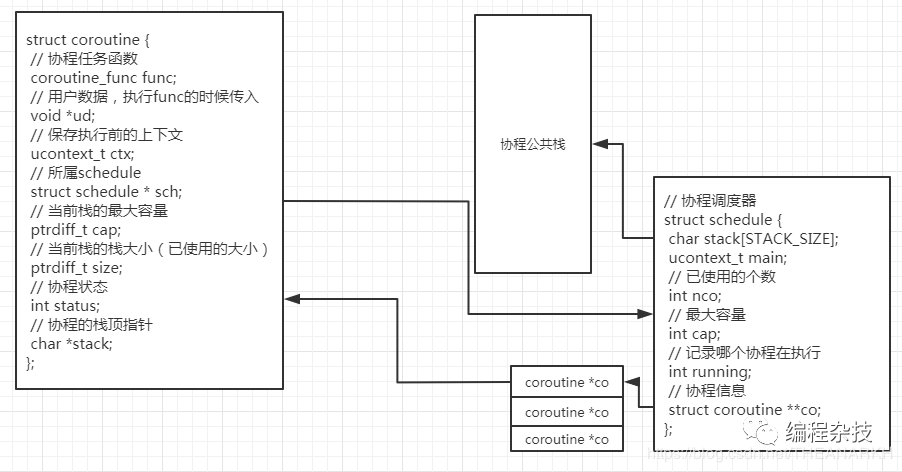
// 协程的表示
struct coroutine {
// 协程任务函数
coroutine_func func;
// 用户数据,执行func的时候传入
void *ud;
// 保存执行前的上下文
ucontext_t ctx;
// 所属schedule
struct schedule * sch;
// 当前栈的最大容量
ptrdiff_t cap;
// 当前栈的栈大小(已使用的大小)
ptrdiff_t size;
// 协程状态
int status;
// 协程的栈顶指针
char *stack;
};
了解了数据结构,下面我们开始分析具体的实现。首先是创建一个schedule。
// 创建一个调度器,准备开始执行协程
struct schedule *
coroutine_open(void) {
struct schedule *S = malloc(sizeof(*S));
// 协程个数
S->nco = 0;
// 最大协程数
S->cap = DEFAULT_COROUTINE;
// 哪个协程在跑,初始化时还没有协程在跑
S->running = -1;
// 分申请了一个结构体指针数组,指向协程结构体的信息
S->co = malloc(sizeof(struct coroutine *) * S->cap);
memset(S->co, 0, sizeof(struct coroutine *) * S->cap);
return S;
}
就是申请了一个结构体。内存视图如下。
然后我们再来看一下如何创建一个协程。
// 申请一个表示协程的结构体
struct coroutine *
_co_new(struct schedule *S , coroutine_func func, void *ud) {
// 在堆上申请空间
struct coroutine * co = malloc(sizeof(*co));
co->func = func;
co->ud = ud;
co->sch = S;
co->cap = 0;
co->size = 0;
co->status = COROUTINE_READY;
co->stack = NULL;
return co;
}
// 新建一个协程
in
t
coroutine_new(struct schedule *S, coroutine_func func, void *ud) {
// 申请一个协程结构体
struct coroutine *co = _co_new(S, func , ud);
// 协程数达到上限,扩容
if (S->nco >= S->cap) {
int id = S->cap;
// 扩容两倍
S->co = realloc(S->co, S->cap * 2 * sizeof(struct coroutine *));
// 初始化空闲的内存
memset(S->co + S->cap , 0 , sizeof(struct coroutine *) * S->cap);
S->co[S->cap] = co;
S->cap *= 2;
++S->nco;
return id;
} else {
int i;
// 有些slot可能是空的,这里从最后一个索引开始找,没找到再从头开始找
for (i=0;i<S->cap;i++) {
int id = (i+S->nco) % S->cap;
// 找到可用的slot,记录协程信息
if (S->co[id] == NULL) {
S->co[id] = co;
// 记录已使用的slot个数,即协程数
++S->nco;
return id;
}
}
}
assert(0);
return -1;
}
这时候的内存布局如下。
这样就完成了协程的创建。接下来就是执行协程。
struct coroutine *C = S->co[id]
首先拿到当前需要执行协程的结构体。id是创建协程的时候返回的。接着保存当前执行的上下文。
// 保存当前执行的上下文到ctx
getcontext(&C->ctx);
getcontext函数在之前的文章分析过,他主要是保存当前执行的上下文,即getcontext函数下一条执行的地址和寄存器等信息。接着设置协程的信息。
// 设置协程执行时的栈信息,真正的esp在makecontext里会修改成ss_sp+ss_size-一定的大小(用于存储额外数据的)
C->ctx.uc_stack.ss_sp = S->stack;
C->ctx.uc_stack.ss_size = STACK_SIZE;
// 记录下一个协程,即执行完执行他
C->ctx.uc_link = &S->main;
// 记录当前执行的协程
S->running = id;
// 协程开始执行
C->status = COROUTINE_RUNNING;
// 协程执行时的入参
uintptr_t ptr = (uintptr_t)S;
继续设置协程的信息。
// 设置协程(ctx)的任务函数和入参,makecontext的入参是32位,在64位系统上有问题,所以兼容处理一下,把64位分为高低地址两部分
makecontext(&C->ctx, (void (*)(void)) mainfunc, 2, (uint32_t)ptr, (uint32_t)(ptr>>32));
makecontext是设置协程的任务函数是mainfunc函数(即设置eip寄存器为mainfunc的地址),后面的几个参数是执行mainfunc的入参。设置完了,开始执行。
// 保存当前上下文到main,然后切换到ctx对应的上下文执行,即执行上面设置的mainfunc,执行完再切回这里
swapcontext(&S->main, &C->ctx);
swapcontext函数首先保存当前执行的上下文到main字段,然后切换到ctx中执行。这样就启动了一个协程。假设协程的工作函数如下。
static void
foo(struct schedule * S, void *ud) {
struct args * arg = ud;
int start = arg->n;
int i;
for (i=0;i<5;i++) {
printf("coroutine %d : %dn",coroutine_running(S) , start + i);
coroutine_yield(S);
}
}
协程执行到一个地方,执行coroutine_yield函数让出执行权。实现协程的切换,我们看看coroutine_yield的实现。
// 协程主动让出执行权,切换到main
void
coroutine_yield(struct schedule * S) {
int id = S->running;
assert(id >= 0);
struct coroutine * C = S->co[id];
assert((char *)&C > S->stack);
_save_stack(C,S->stack + STACK_SIZE);
C->status = COROUTINE_SUSPEND;
// 当前协程已经让出执行权,当前没有协程执行
S->running = -1;
// 切换到main执行
swapcontext(&C->ctx , &S->main);
}
其中最重要的是_save_stack函数。从前面的代码中我们知道,协程执行的时候使用的是一个公共的栈,即所有协程共享的。那么如果协程让出执行权后,其他协程执行时就会覆盖栈里的信息。所以让出执行权之前,协程有个很重要的事情要做,那就是保存当前栈的信息,以便再次执行时,能恢复栈的上下文。我们看看_save_stack的实现。
// 保存当前栈信息,top是协程的栈顶最大值
static void
_save_stack(struct coroutine *C, char *top) {
// dummy用于计算出当前的esp,即栈顶地址
char dummy = 0;
assert(top - &dummy <= STACK_SIZE);
// top-&dummy算出协程当前的栈上下文有多大,如果比当前的容量大,则需要扩容
if (C->cap < top - &dummy) {
free(C->stack);
C->cap = top-&dummy;
C->stack = malloc(C->cap);
}
// 记录当前的栈大小
C->size = top - &dummy;
// 复制公共栈的数据到私有栈
memcpy(C->stack, &dummy, C->size);
}
这个函数的实现比较巧妙。假设当前的栈布局如下。
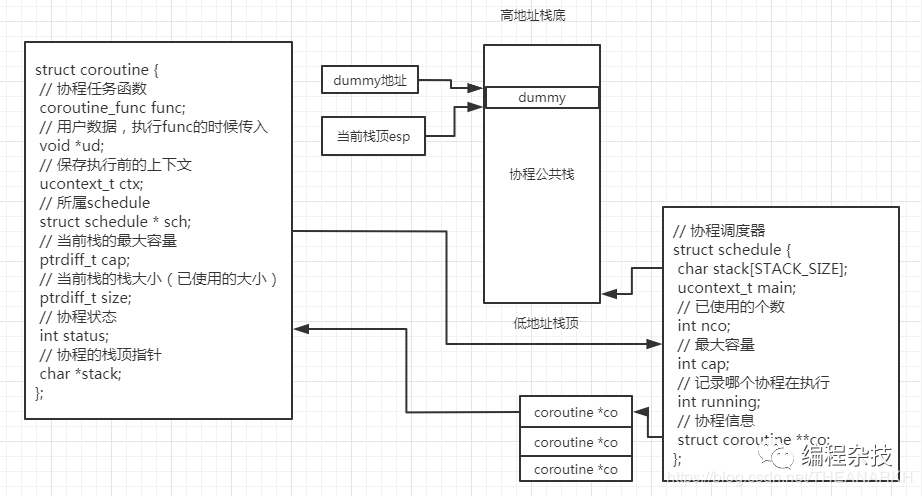
从图中我们可以知道dummy变量的地址之前的(即高地址到dummy地址部分)是当前协程用到的栈空间(栈的上下文)。而这个栈是公共的栈,即其他协程也会使用。那么当前协程让出执行权后,需要保存这部分上下文,否则他就被覆盖了。做法就是在堆上申请一块空间(如果还没有或者大小不够的话)。然后保存公共栈里的上下文。这样其他协程执行的时候就可以覆盖里面的数据了。布局如下。
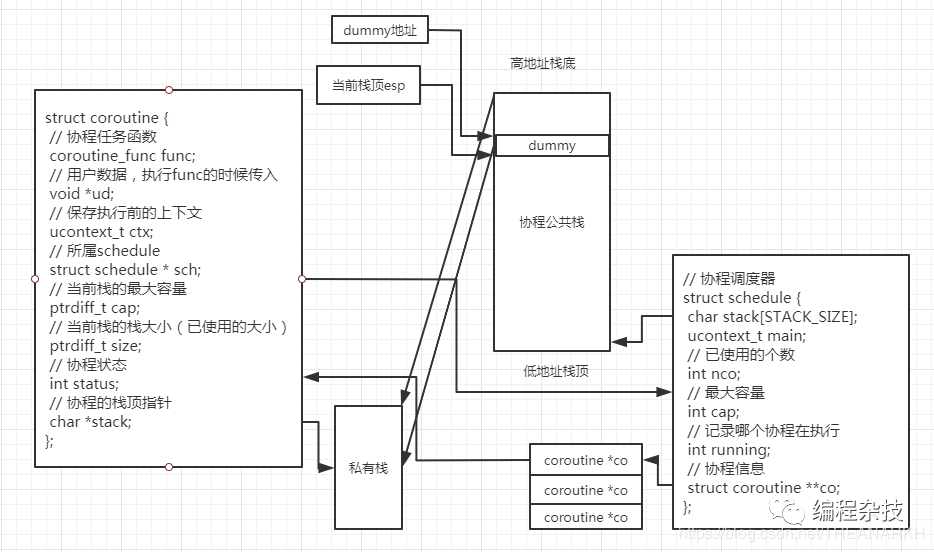
然后等到该协程再被执行时,我们看看是怎么恢复这个栈上下文的。
memcpy(S->stack + STACK_SIZE - C->size, C->stack, C->size);
S->running = id;
C->status = COROUTINE_RUNNING;
swapcontext(&S->main, &C->ctx);
就把把私有栈C->stack开始,大小为C->size的字节复制到公共栈中。达到恢复上下文的目的
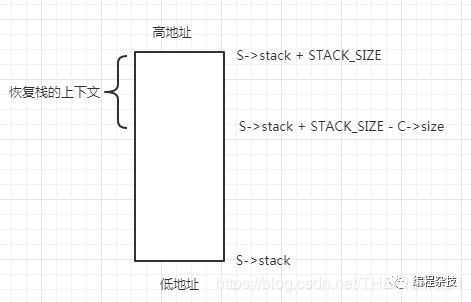
然后调用swapcontext继续执行协程,即从上次挂起的地方继续执行。
总结:本文大致分析了一个协程的创建,执行,挂起,恢复执行的过程。
转自https://mp.weixin.qq.com/s/bOHD8AUdM6WbCN2R0a3p0Q
最后
以上就是无辜麦片最近收集整理的关于云风coroutine库源码分析的全部内容,更多相关云风coroutine库源码分析内容请搜索靠谱客的其他文章。








发表评论 取消回复