加起来:
正如文档所说,重命名列的方法已经很聪明了:
Examples
Assembling a datetime from multiple columns of a DataFrame. The keys
can be common abbreviations like [‘year’, ‘month’, ‘day’, ‘minute’,
‘second’, ‘ms’, ‘us’, ‘ns’]) or plurals of the same
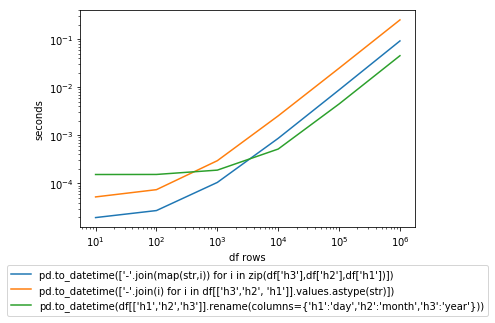
但是,还有其他选择.以我的经验,使用zip进行列表理解非常快(对于小集合).随着大约3000行数据的重命名,列变得最快.从图中可以看出,重命名的惩罚对于小集合来说很难,但对于大集合则可以弥补.
备择方案
pd.to_datetime(['-'.join(map(str,i)) for i in zip(df['h3'],df['h2'],df['h1'])])
pd.to_datetime(['-'.join(i) for i in df[['h3', 'h2', 'h1']].values.astype(str)])
df[['h3','h2','h1']].astype(str).apply(lambda x: pd.to_datetime('-'.join(x)), 1)
pd.to_datetime(df[['h1','h2','h3']].rename(columns={'h1':'day', 'h2':'month','h3':'year'}))
时间Win10:
#df = pd.concat([df]*1000)
2.74 ms ± 33.7 ?s per loop (mean ± std. dev. of 7 runs, 100 loops each)
8.08 ms ± 158 ?s per loop (mean ± std. dev. of 7 runs, 100 loops each)
158 ms ± 472 ?s per loop (mean ± std. dev. of 7 runs, 10 loops each)
2.64 ms ± 104 ?s per loop (mean ± std. dev. of 7 runs, 100 loops each)
MacBook Air的计时:
100 loops, best of 3: 6.1 ms per loop
100 loops, best of 3: 12.7 ms per loop
1 loop, best of 3: 335 ms per loop
100 loops, best of 3: 4.7 ms per loop
使用我编写的代码进行更新(如果您有改进的建议或任何可以帮助您的库,请感到高兴):
import pandas as pd
import numpy as np
import timeit
import matplotlib.pyplot as plt
from collections import defaultdict
df = pd.DataFrame({
'h1': np.arange(1,11),
'h2': np.arange(1,11),
'h3': np.arange(2000,2010)
})
myfuncs = {
"pd.to_datetime(['-'.join(map(str,i)) for i in zip(df['h3'],df['h2'],df['h1'])])":
lambda: pd.to_datetime(['-'.join(map(str,i)) for i in zip(df['h3'],df['h2'],df['h1'])]),
"pd.to_datetime(['-'.join(i) for i in df[['h3','h2', 'h1']].values.astype(str)])":
lambda: pd.to_datetime(['-'.join(i) for i in df[['h3','h2', 'h1']].values.astype(str)]),
"pd.to_datetime(df[['h1','h2','h3']].rename(columns={'h1':'day','h2':'month','h3':'year'}))":
lambda: pd.to_datetime(df[['h1','h2','h3']].rename(columns={'h1':'day','h2':'month','h3':'year'}))
}
d = defaultdict(dict)
step = 10
cont = True
while cont:
lendf = len(df); print(lendf)
for k,v in mycodes.items():
iters = 1
t = 0
while t < 0.2:
ts = timeit.repeat(v, number=iters, repeat=3)
t = min(ts)
iters *= 10
d[k][lendf] = t/iters
if t > 2: cont = False
df = pd.concat([df]*step)
pd.DataFrame(d).plot().legend(loc='upper center', bbox_to_anchor=(0.5, -0.15))
plt.yscale('log'); plt.xscale('log'); plt.ylabel('seconds'); plt.xlabel('df rows')
plt.show()
返回值:
最后
以上就是等待宝马最近收集整理的关于python to datetime_python-pandas to_datetime()未检测到列的全部内容,更多相关python内容请搜索靠谱客的其他文章。








发表评论 取消回复