摘要: 日志服务支持的两种搜索方式 通过设置分词字符(通常是标点符号),把一段文本划分成不同的单词。分词字符只能是单字节ascii字符这种方式适合于切分英文单词。这种方式对于中文日志,必须要搜索中文语句整体。
点此查看原文:http://click.aliyun.com/m/42944/
搜索引擎背后的原理和日志检索
当我们在搜索引擎搜索一个词的时候,背后是上千台机器在为我们工作。那么搜索引擎是如何从数万亿的网页中瞬间查找到我们想要的词的呢?这里要介绍一个概念叫倒排索引。
倒排索引
倒排索引指的是,把文档拆分成一个个单词,每个单词指向包含该单词的文档ID。在查询时,根据关键字,找到包含该关键字的文档ID列表。再根据ID读取具体的数据。
以英文为例,下面是要被索引的文本:
T0 = "it is what it is"
T1 = "what is it"
T2 = "it is a banana"我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}查询what这个词时,我们找到了0,1这两个ID,然后知道了T0和T1这两个文档包含what这个词。
由上文的介绍可知,创建倒排索引的关键在于分词。对于英文和中文,分词方式又有区别。
英文分词
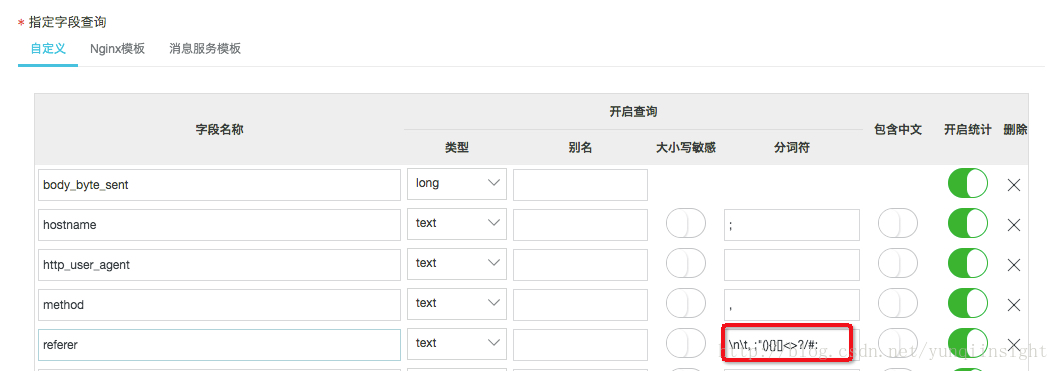
英文语句,每个单词之间有标点符号分割,因此我们把标点符号设置为分词字符,标点符号之间的字符串即为一个单词。
例如语句
it is what it is.what is it?it is a banana!
如果分词字符是空格和. ? ! 那么能够得到的单词依次是it,is,what,it,is,what,is,it,it,is,a,banana
如果分词字符是空格和.? 不包含! 那么能够得到的单词依次是it,is,what,it,is,what,is,it,it,is,a,banana!
我们得到banana!这样一个特殊的词,在查询时如果查询banana是无结果的,比如查询banana!才行
配置分词字符,请在查询分析属性中配置:
中文分词
中文分词的困难
中文语句不同于英文语句,英文的每个单词之间有标点符号分割,中文的单词和单词之间是连接在一起的。中文单个字没有意义,只有和相邻的字组成词汇时,才有意义。例如语句:
中国是一个伟大的国家,中国共产党是一个伟大的政党每个字表达的含义没有意义,只有组合成词汇,才能理解其中的含义。中文博大精深,不同的字有不同的组合方式,在不同的语境下,词的长度也不一样。人类能够快速的分析出这句话所包含的词:
中国 是 一个 伟大 的 国家 中国共产党 是 一个 伟大 的 政党两句话中的中国,在前一句中是单独一个词,在后一句中要和之后的共产党组成一个词。
中英文混合日志
针对包含中文的日志,例如debug message:登录成功号是中文冒号,配置的分词字符是空格。如果只采用分词字符的方式分词,那么得到的词有:
debug message:登录成功无法单独搜索登录或成功,只有完整输入message:登录成功才能搜索到日志。
智能化中文分词
为了解决中文的分词问题,我们引入了智能化的分词算法。
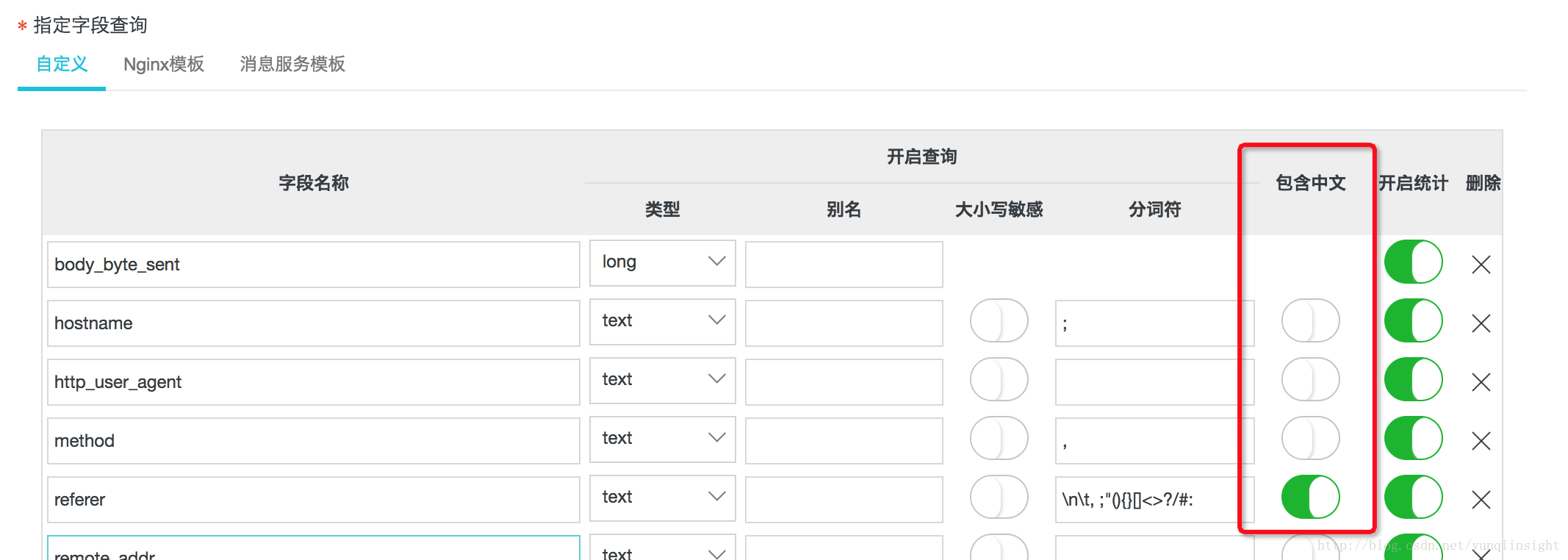
如果日志中包含中文,那么需要打开开关,引入智能化分词,才能够搜索中文单词。
打开后中文开关后,我们分别可以查询debug,message,登录,成功。
中文搜索效果: 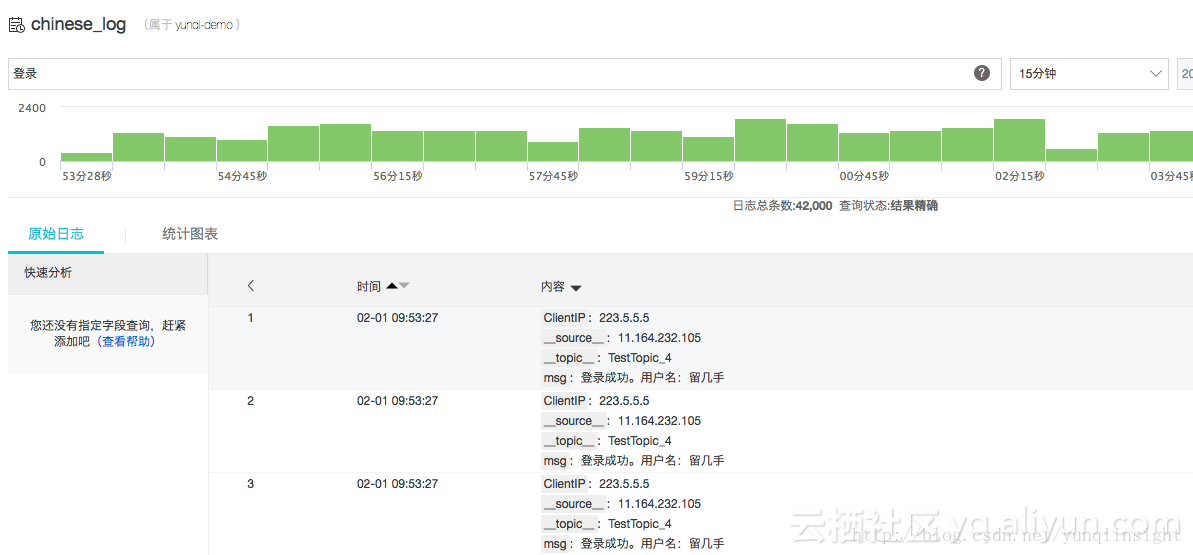
最后
以上就是感动小丸子最近收集整理的关于搜索引擎背后的原理和中文日志检索的全部内容,更多相关搜索引擎背后内容请搜索靠谱客的其他文章。








发表评论 取消回复