“探索与利用”机制是在“探索新数据”和“利用旧数据”之间进行平衡,使系统既能够利用旧数据进行推荐,达到推荐系统的商业目标,又能高效地探索冷启动的物品是否是“优质”物品,使得冷启动物品获得曝光的倾向,快速收集冷启动数据。
解决“探索与利用”主要有三大类方法:
- 传统的探索与利用方法:主要有ε-greedy、汤普森采样和UCB(Upper Confidence Bound,置信区间上界)。该类解决方法着重解决新物品的探索和利用,方法中并不考虑用户、上下文等因素,因此是非个性化的探索与利用方法。
- 个性化的探索与利用方法:该类方法有效地结合了个性化推荐特点和探索与利用的思想,在考虑用户、上下文等因素的基础上进行探索与利用的权衡。
- 基于模型的探索与利用方法:将深度学习模型和探索与利用的思想有效结合。
一、传统的探索与利用方法
多臂老虎机问题:假设我们有一个K臂老虎机,每一个臂(action)的回报率(reward_i)都是固定的,但是agent并不知道这个回报率是多少,agent如何在T回合内最大化自己的回报
1. ε-greedy算法
ε-greedy算法的主要流程是:选一个[0,1]的数ε,每次以ε的概率在所有老虎机中进行随机选择,以(1-ε)的概率选择截止当前平均收益最大的老虎机,在摇臂后,根据回报值对老虎机的回报期望进行更新。
这里的ε代表对探索的偏好程度,每次以ε去探索,以(1-ε)的概率来利用,基于被选择的物品的回报更新该物品的回报期望。本质上讲,探索的过程是一个收集未知信息的过程,而利用的过程是对已知信息的贪心利用过程。
ε-greedy算法的缺点是:在进行了一段时间的探索之后,再进行探索的收益已经没有之前大了,这时应该逐渐减小ε的值,增加利用部分的占比;另外,对每个老虎机进行完全随机的探索也不是高效的探索策略,例如有的老虎机已经积累了丰富的信息,不用再进行探索来收集信息了,这时就应该让探索的机会偏向于那些不常被选择的老虎机,为了改进ε-greedy算法的这些缺陷,启发式探索与利用算法被提出。
2. 汤普森采样算法
该算法假设每个老虎机能够赢钱的概率是p,同时概率p的分布符合beta(win,lose)分布,每个老虎机都维护一组beta分布的参数,每次实验后,选中一个老虎机,摇臂后,有收益则该老虎机的win参数增加1,否则该老虎机的lose参数增加1.
每次选择老虎机的方式是:利用每个老虎机现有的beta分布产生一个随机数b,逐一生成每个老虎机的随机数,选择随机数中最大的那个老虎机进行尝试。
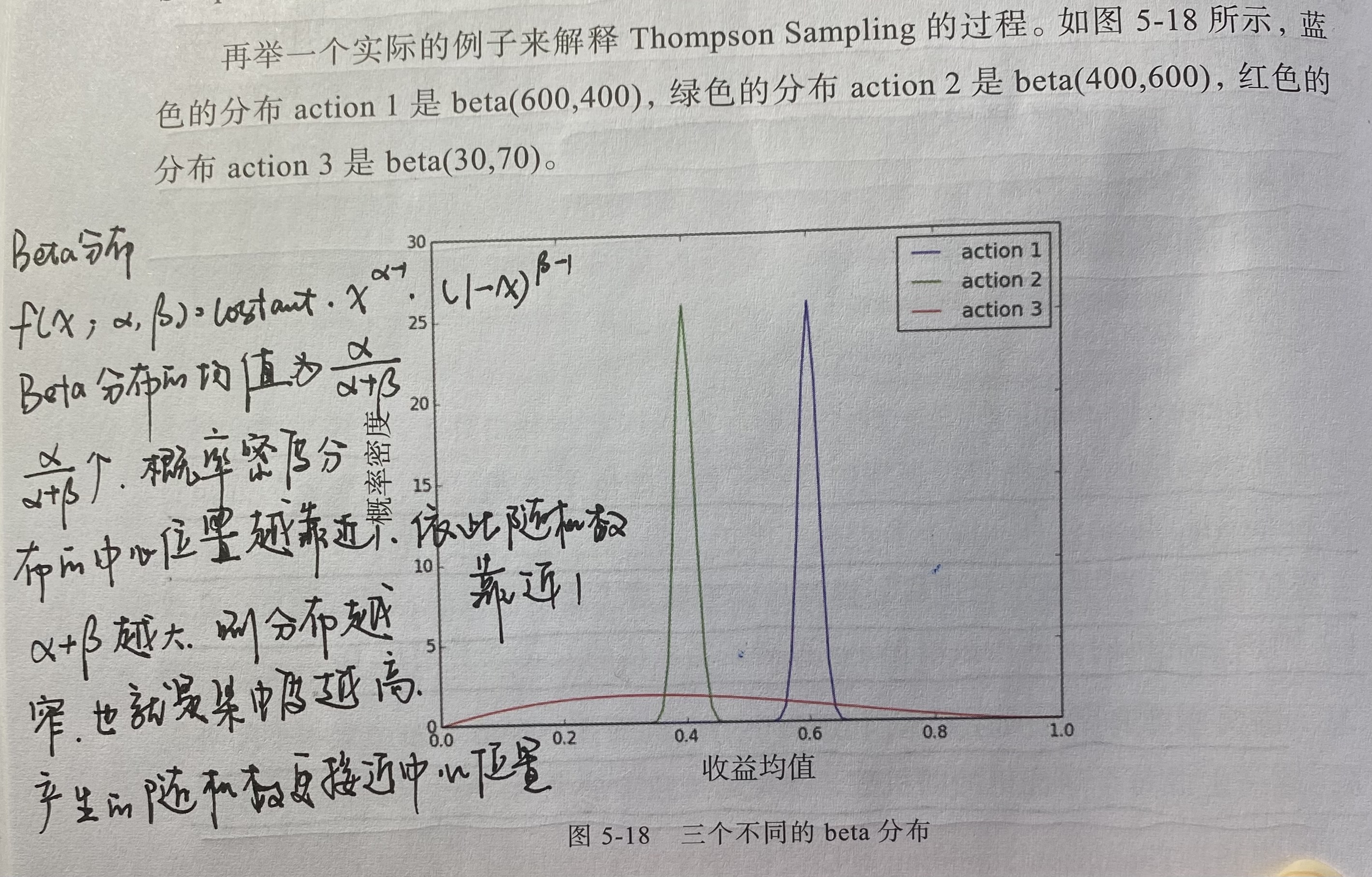
由于1和2已经各进行了总数1000次的尝试,积累了足够的数据,不确定性已经非常小,可以看出1和2的图形是非常陡峭的,其峰值在收益的经验期望附近,而对3来说,由于只进行了100次尝试,不确定性很大,分布图形非常平缓。
通过汤普森采样选择下一次行动时,3的收益期望是三者中最低的,如果按照纯“利用”的思路,是不应该选择3的;但是基于3的beta分布图形,可以很明显的看出其概率分布有一部分落在1和2概率分布右侧,而且概率并不小(10%-20%)。也就是说,通过汤普森采样选择3的机会并不少,这就利用了汤普森采样对新物品的倾向性。
3. UCB算法
UCB(Upper Confidence Bound, 置信区间上界)的计算方法为:
U
C
B
(
j
)
=
x
j
ˉ
=
2
l
n
n
n
j
UCB(j)=bar{x_j}=sqrt{frac{2ln n}{n_j}}
UCB(j)=xjˉ=nj2lnn
其中,
x
j
ˉ
bar{x_j}
xjˉ是观测到的第j个物品的平均回报(可以是点击率、转化率、播放率等),
n
j
n_j
nj是目前为止向用户曝光第j个物品的次数,n是到目前为止曝光所有物品的次数之和。
由此,当物品的平均回报高时,UCB的得分会高;同时,当物品的曝光次数低时,UCB的得分也会高。也就是说,使用UCB方法进行推荐,推荐系统会倾向于推荐效果好或者冷启动的物品。那么,随着冷启动的物品有倾向性的被推荐,冷启动物品快速收集反馈数据,使之能够快速通过冷启动阶段。
二、个性化的探索与利用方法
LinUCB算法
三、基于模型的探索与利用方法
DRN算法:对于已经训练好的当前网络Q,通过对其模型参数W添加一个较小的随机扰动△W,得到新的模型参数 W ~ widetilde{W} W ,这里称 W ~ widetilde{W} W 对应的网络为探索网络 Q ~ widetilde{Q} Q 。再通过系统的实时效果反馈决定时保留探索网络 Q ~ widetilde{Q} Q 还是沿用当前网络Q。
参考资料
- 深度学习推荐系统 王喆编著 中国工信出版集团
- 多臂老虎机问题
最后
以上就是眼睛大哑铃最近收集整理的关于【推荐算法】探索与利用一、传统的探索与利用方法二、个性化的探索与利用方法三、基于模型的探索与利用方法参考资料的全部内容,更多相关【推荐算法】探索与利用一、传统内容请搜索靠谱客的其他文章。








发表评论 取消回复