在MCMC(三)MCMC采样和M-H采样中,我们讲到了M-H采样已经可以很好的解决蒙特卡罗方法需要的任意概率分布的样本集的问题。但是M-H采样有两个缺点:一是需要计算接受率,在高维时计算量大。并且由于接受率的原因导致算法收敛时间变长。二是有些高维数据,特征的条件概率分布好求,但是特征的联合分布不好求。因此需要一个好的方法来改进M-H采样,这就是我们下面讲到的Gibbs采样。
1. 重新寻找合适的细致平稳条件
在上一篇中,我们讲到了细致平稳条件:如果非周期马尔科夫链的状态转移矩阵PP和概率分布π(x)π(x)对于所有的i,ji,j满足:
π(i)P(i,j)=π(j)P(j,i)π(i)P(i,j)=π(j)P(j,i)
则称概率分布π(x)π(x)是状态转移矩阵PP的平稳分布。
在M-H采样中我们通过引入接受率使细致平稳条件满足。现在我们换一个思路。
从二维的数据分布开始,假设π(x1,x2)π(x1,x2)是一个二维联合数据分布,观察第一个特征维度相同的两个点A(x(1)1,x(1)2)A(x1(1),x2(1))和B(x(1)1,x(2)2)B(x1(1),x2(2)),容易发现下面两式成立:
π(x(1)1,x(1)2)π(x(2)2|x(1)1)=π(x(1)1)π(x(1)2|x(1)1)π(x(2)2|x(1)1)π(x1(1),x2(1))π(x2(2)|x1(1))=π(x1(1))π(x2(1)|x1(1))π(x2(2)|x1(1))
π(x(1)1,x(2)2)π(x(1)2|x(1)1)=π(x(1)1)π(x(2)2|x(1)1)π(x(1)2|x(1)1)π(x1(1),x2(2))π(x2(1)|x1(1))=π(x1(1))π(x2(2)|x1(1))π(x2(1)|x1(1))
由于两式的右边相等,因此我们有:
π(x(1)1,x(1)2)π(x(2)2|x(1)1)=π(x(1)1,x(2)2)π(x(1)2|x(1)1)π(x1(1),x2(1))π(x2(2)|x1(1))=π(x1(1),x2(2))π(x2(1)|x1(1))
也就是:
π(A)π(x(2)2|x(1)1)=π(B)π(x(1)2|x(1)1)π(A)π(x2(2)|x1(1))=π(B)π(x2(1)|x1(1))
观察上式再观察细致平稳条件的公式,我们发现在x1=x(1)1x1=x1(1)这条直线上,如果用条件概率分布π(x2|x(1)1)π(x2|x1(1))作为马尔科夫链的状态转移概率,则任意两个点之间的转移满足细致平稳条件!这真是一个开心的发现,同样的道理,在在x2=x(1)2x2=x2(1)这条直线上,如果用条件概率分布π(x1|x(1)2)π(x1|x2(1))作为马尔科夫链的状态转移概率,则任意两个点之间的转移也满足细致平稳条件。那是因为假如有一点C(x(2)1,x(1)2)C(x1(2),x2(1)),我们可以得到:
π(A)π(x(2)1|x(1)2)=π(C)π(x(1)1|x(1)2)π(A)π(x1(2)|x2(1))=π(C)π(x1(1)|x2(1))
基于上面的发现,我们可以这样构造分布π(x1,x2)π(x1,x2)的马尔可夫链对应的状态转移矩阵PP:
P(A→B)=π(x(B)2|x(1)1)ifx(A)1=x(B)1=x(1)1P(A→B)=π(x2(B)|x1(1))ifx1(A)=x1(B)=x1(1)
P(A→C)=π(x(C)1|x(1)2)ifx(A)2=x(C)2=x(1)2P(A→C)=π(x1(C)|x2(1))ifx2(A)=x2(C)=x2(1)
P(A→D)=0elseP(A→D)=0else
有了上面这个状态转移矩阵,我们很容易验证平面上的任意两点E,FE,F,满足细致平稳条件:
π(E)P(E→F)=π(F)P(F→E)π(E)P(E→F)=π(F)P(F→E)
2. 二维Gibbs采样
利用上一节找到的状态转移矩阵,我们就得到了二维Gibbs采样,这个采样需要两个维度之间的条件概率。具体过程如下:
1)输入平稳分布π(x1,x2)π(x1,x2),设定状态转移次数阈值n1n1,需要的样本个数n2n2
2)随机初始化初始状态值x(0)1x1(0)和x(0)2x2(0)
3)for t=0t=0 to n1+n2−1n1+n2−1:
a) 从条件概率分布P(x2|x(t)1)P(x2|x1(t))中采样得到样本xt+12x2t+1
b) 从条件概率分布P(x1|x(t+1)2)P(x1|x2(t+1))中采样得到样本xt+11x1t+1
样本集{(x(n1)1,x(n1)2),(x(n1+1)1,x(n1+1)2),...,(x(n1+n2−1)1,x(n1+n2−1)2)}{(x1(n1),x2(n1)),(x1(n1+1),x2(n1+1)),...,(x1(n1+n2−1),x2(n1+n2−1))}即为我们需要的平稳分布对应的样本集。
整个采样过程中,我们通过轮换坐标轴,采样的过程为:
(x(1)1,x(1)2)→(x(1)1,x(2)2)→(x(2)1,x(2)2)→...→(x(n1+n2−1)1,x(n1+n2−1)2)(x1(1),x2(1))→(x1(1),x2(2))→(x1(2),x2(2))→...→(x1(n1+n2−1),x2(n1+n2−1))
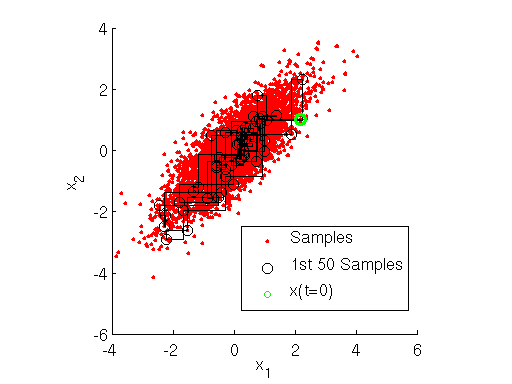
用下图可以很直观的看出,采样是在两个坐标轴上不停的轮换的。当然,坐标轴轮换不是必须的,我们也可以每次随机选择一个坐标轴进行采样。不过常用的Gibbs采样的实现都是基于坐标轴轮换的。
3. 多维Gibbs采样
上面的这个算法推广到多维的时候也是成立的。比如一个n维的概率分布π(x1,x2,...xn)π(x1,x2,...xn),我们可以通过在n个坐标轴上轮换采样,来得到新的样本。对于轮换到的任意一个坐标轴xixi上的转移,马尔科夫链的状态转移概率为P(xi|x1,x2,...,xi−1,xi+1,...,xn)P(xi|x1,x2,...,xi−1,xi+1,...,xn),即固定n−1n−1个坐标轴,在某一个坐标轴上移动。
具体的算法过程如下:
1)输入平稳分布π(x1,x2,...,xn)π(x1,x2,...,xn)或者对应的所有特征的条件概率分布,设定状态转移次数阈值n1n1,需要的样本个数n2n2
2)随机初始化初始状态值(x(0)1,x(0)2,...,x(0)n(x1(0),x2(0),...,xn(0)
3)for t=0t=0 to n1+n2−1n1+n2−1:
a) 从条件概率分布P(x1|x(t)2,x(t)3,...,x(t)n)P(x1|x2(t),x3(t),...,xn(t))中采样得到样本xt+11x1t+1
b) 从条件概率分布P(x2|x(t+1)1,x(t)3,x(t)4,...,x(t)n)P(x2|x1(t+1),x3(t),x4(t),...,xn(t))中采样得到样本xt+12x2t+1
c)...
d) 从条件概率分布P(xj|x(t+1)1,x(t+1)2,...,x(t+1)j−1,x(t)j+1...,x(t)n)P(xj|x1(t+1),x2(t+1),...,xj−1(t+1),xj+1(t)...,xn(t))中采样得到样本xt+1jxjt+1
e)...
f) 从条件概率分布P(xn|x(t+1)1,x(t+1)2,...,x(t+1)n−1)P(xn|x1(t+1),x2(t+1),...,xn−1(t+1))中采样得到样本xt+1nxnt+1
样本集{(x(n1)1,x(n1)2,...,x(n1)n),...,(x(n1+n2−1)1,x(n1+n2−1)2,...,x(n1+n2−1)n)}{(x1(n1),x2(n1),...,xn(n1)),...,(x1(n1+n2−1),x2(n1+n2−1),...,xn(n1+n2−1))}即为我们需要的平稳分布对应的样本集。
整个采样过程和Lasso回归的坐标轴下降法算法非常类似,只不过Lasso回归是固定n−1n−1个特征,对某一个特征求极值。而Gibbs采样是固定n−1n−1个特征在某一个特征采样。
同样的,轮换坐标轴不是必须的,我们可以随机选择某一个坐标轴进行状态转移,只不过常用的Gibbs采样的实现都是基于坐标轴轮换的。
4. 二维Gibbs采样实例
这里给出一个Gibbs采样的例子。假设我们要采样的是一个二维正态分布Norm(μ,Σ)Norm(μ,Σ),其中:
μ=(μ1,μ2)=(5,−1)μ=(μ1,μ2)=(5,−1)
Σ=(σ21ρσ1σ2ρσ1σ2σ22)=(1114)Σ=(σ12ρσ1σ2ρσ1σ2σ22)=(1114)
而采样过程中的需要的状态转移条件分布为:
P(x1|x2)=Norm(μ1+ρσ1/σ2(x2−μ2),(1−ρ2)σ21)P(x1|x2)=Norm(μ1+ρσ1/σ2(x2−μ2),(1−ρ2)σ12)
P(x2|x1)=Norm(μ2+ρσ2/σ1(x1−μ1),(1−ρ2)σ22)P(x2|x1)=Norm(μ2+ρσ2/σ1(x1−μ1),(1−ρ2)σ22)
具体的代码如下:

from mpl_toolkits.mplot3d import Axes3D
from scipy.stats import multivariate_normal
samplesource = multivariate_normal(mean=[5,-1], cov=[[1,0.5],[0.5,2]])
def p_ygivenx(x, m1, m2, s1, s2):
return (random.normalvariate(m2 + rho * s2 / s1 * (x - m1), math.sqrt(1 - rho ** 2) * s2))
def p_xgiveny(y, m1, m2, s1, s2):
return (random.normalvariate(m1 + rho * s1 / s2 * (y - m2), math.sqrt(1 - rho ** 2) * s1))
N = 5000
K = 20
x_res = []
y_res = []
z_res = []
m1 = 5
m2 = -1
s1 = 1
s2 = 2
rho = 0.5
y = m2
for i in xrange(N):
for j in xrange(K):
x = p_xgiveny(y, m1, m2, s1, s2)
y = p_ygivenx(x, m1, m2, s1, s2)
z = samplesource.pdf([x,y])
x_res.append(x)
y_res.append(y)
z_res.append(z)
num_bins = 50
plt.hist(x_res, num_bins, normed=1, facecolor='green', alpha=0.5)
plt.hist(y_res, num_bins, normed=1, facecolor='red', alpha=0.5)
plt.title('Histogram')
plt.show()
输出的两个特征各自的分布如下:
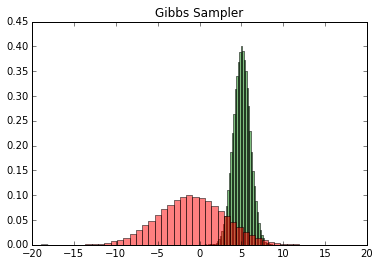
然后我们看看样本集生成的二维正态分布,代码如下:
fig = plt.figure() ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=30, azim=20) ax.scatter(x_res, y_res, z_res,marker='o') plt.show()
输出的正态分布图如下:
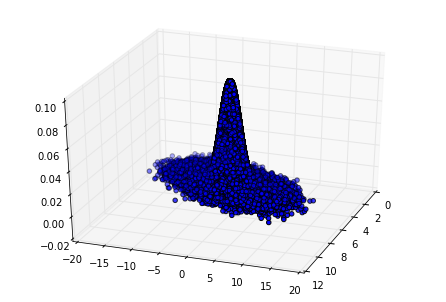
5. Gibbs采样小结
由于Gibbs采样在高维特征时的优势,目前我们通常意义上的MCMC采样都是用的Gibbs采样。当然Gibbs采样是从M-H采样的基础上的进化而来的,同时Gibbs采样要求数据至少有两个维度,一维概率分布的采样是没法用Gibbs采样的,这时M-H采样仍然成立。
有了Gibbs采样来获取概率分布的样本集,有了蒙特卡罗方法来用样本集模拟求和,他们一起就奠定了MCMC算法在大数据时代高维数据模拟求和时的作用。MCMC系列就在这里结束吧。
最后
以上就是干净水壶最近收集整理的关于Gibbs采样1. 重新寻找合适的细致平稳条件2. 二维Gibbs采样3. 多维Gibbs采样4. 二维Gibbs采样实例5. Gibbs采样小结的全部内容,更多相关Gibbs采样1.内容请搜索靠谱客的其他文章。








发表评论 取消回复