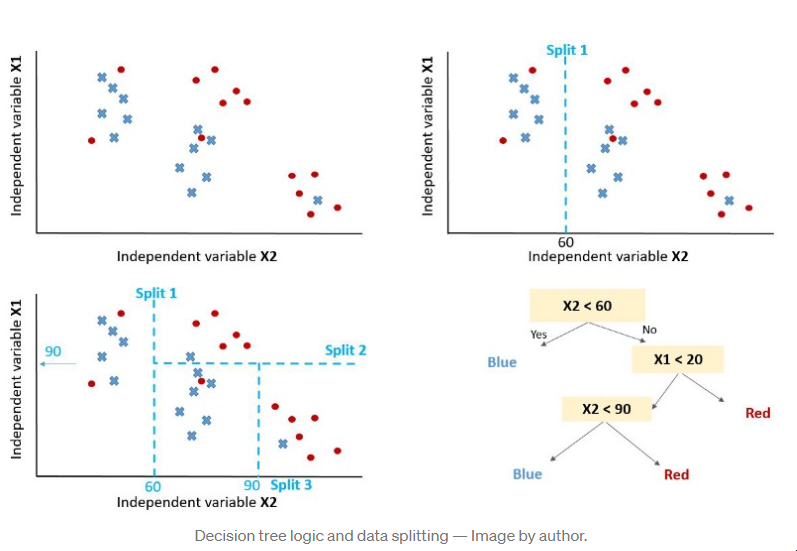
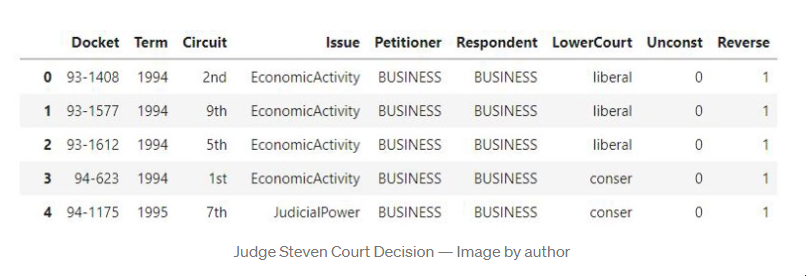
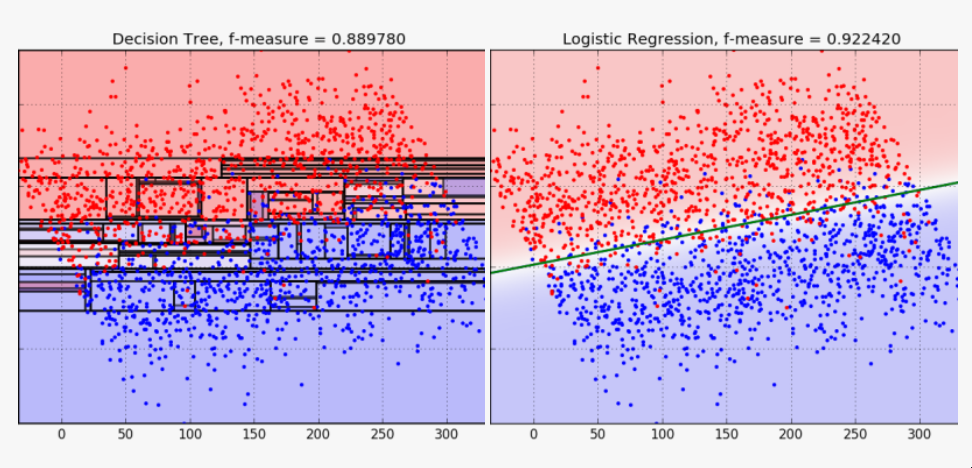
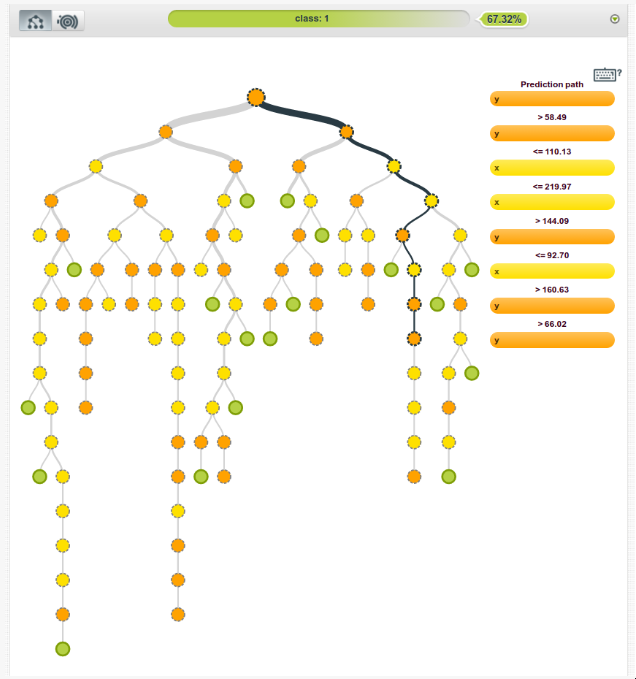
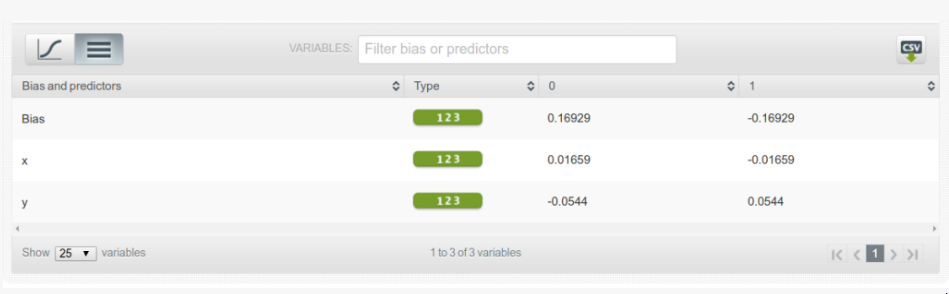
Python中的决策树模型--构建、可视化、评估 来自MITx Analytics Edge的使用Python的指南和实例 分类和回归树(CART)可以转化为预测分类的图形或规则集。当逻辑回归模型不能提供足够的决策边界来预测标签时,它们会有所帮助。此外,决策树模型更具有可解释性,因为它们模拟了人类的决策过程。此外,决策树回归可以捕捉到非线性关系,从而允许建立更复杂的模型。 CART模型是如何工作的? 考虑两个独立变量X1和X2的情况。我们想预测结果是红色还是蓝色。CART试图将这个数据分割成子集,使每个子集尽可能地纯洁或同质。 决策树逻辑和数据拆分 第一个分割(split1)以一种方式分割数据,如果变量X2小于60,将导致一个蓝色的结果,如果不是,将导致看第二个分割(split2)。当X1>20时,考虑到X2<60,Split2指导预测红色。如果X2<90,Split3将预测蓝色,否则预测红色。 如何控制模型的性能? 在你通过学科知识或特征选择过程为模型选择了要考虑的变量后,你需要定义最佳的分割数量。 拆分的目标是增加每个节点的结果的同质性。增加其对数据进行分类的能力。换句话说,在每次分裂后增加纯度。如果我们预测的是蓝色和红色,如果可能的话,选择能给出所有蓝色和所有红色的拆分数量。选择能产生纯净结果的拆分数量。 一个纯粹的节点是一个能产生完美预测的节点。 但如何量化拆分后的纯度,以确保我们有尽可能多的纯净节点。 我们的目标是在每次拆分后减少不确定性。一个糟糕的分割会使结果是50%的蓝色和50%的红色。完美的分割会给出100%的蓝色,例如。 为了衡量拆分后信息量的增加情况,我们可以依靠以下措施。 1 - 熵 [熵=-1sum(plog(p)) ] 1 — Entropy [entropy = -1sum(plog(p)) ] 2 — Gini impurity [Gini = sum(p(1-p)), 2 - 基尼不纯度[Gini = sum(p(1-p)), 其中p是子分区内错误分类的观察比例] 。 例子,预测史蒂文斯法官的决定 目标是预测史蒂文斯法官是否投票推翻法院的判决,1表示投票推翻判决,0表示他维持法院的判决。 代码和数据都可以在GitHub上找到。 数据框架如下所示,目标变量为 "逆转"。 史蒂芬法官的法庭裁决 重要提示:决策树(DT)可以处理连续变量和数字变量。但如果你使用的是Python Scikit Learn,你可能会得到一个关于分类的ValueError。 特征中有许多分类值,我们将使用下面的函数将其转换为数值。 将数据分成训练和测试 在训练数据上建立一个决策树模型 绘制决策树模型 决策树模型 使用分类报告来评估该模型。 参考资料 MITx的分析课程 逻辑回归与决策树的比较 发布者:Cheesinglee 鉴于文献中存在大量的算法,将哪种模型类型应用于机器学习任务可能是一个令人生畏的问题。要比较两种方法的相对优势是很困难的,因为一种方法在某一类问题上可以胜过另一种方法,而在另一类问题上却始终落后。在这篇文章中,也就是我们关于逻辑回归系列文章的最后一篇,我们将探讨决策树和逻辑回归在分类问题上的区别,并试图强调在哪些情况下可能会推荐使用其中一种。 决策边界 逻辑回归和树的不同之处在于它们产生决策边界的方式,也就是用来区分不同类别的线条。为了说明这种差异,让我们看看这两种模型类型在以下2类问题上的结果。 model_boundary_radiallr_boundary_radial 决策树将空间划分为越来越小的区域,而逻辑回归则拟合出一条线,将空间准确划分为两个。当然对于更高维的数据,这些线会概括为平面和超平面。单一的线性边界有时会对Logistic回归产生限制。 在这个例子中,两个类被一个明显的非线性边界分开,我们看到树可以更好地捕捉到这种划分,从而导致卓越的分类性能。然而,当类没有被很好地分开时,树很容易对训练数据进行过度拟合,因此Logistic回归的简单线性边界概括性更好。 model_boundary_linear_boundary_linear 最后,这些图的背景颜色代表预测置信度。决策树的每个节点都为它所跨越的整个区域分配一个恒定的置信度值,导致整个空间的置信度值看起来相当拼凑。另一方面,Logistic回归的预测置信度可以以闭合形式计算任何任意输入坐标,因此我们有一个无限细化的结果,可以对我们的预测置信度值更加自信。 可解释性 尽管最后一个例子是为了让Logistic回归具有性能优势,但其得出的f-measure并没有完全以巨大的优势击败决策树的。那么,还有什么值得推荐的Logistic回归呢?让我们来看看BigML网络界面中的树状模型视图。 模型 | BigMLcom - Chromium_056 当一棵树由大量的节点组成时,它可能需要大量的脑力劳动来理解导致一个特定预测的所有分割点。相比之下,Logistic Regression模型只是一个系数列表。 选择_057 一目了然,我们能够看到一个实例的y坐标对于确定其类别的重要性是其x坐标的三倍多,这一点被上一节中的决策边界的斜率所证实。这方面的一个重要注意事项是关于尺度的问题。例如,如果x和y分别以米和公里为单位,我们应该期望它们的系数相差1000倍,以便在现实世界的物理意义上代表同等重要性。由于逻辑回归模型完全由其系数描述,它们对那些对其数据有一定了解的用户很有吸引力,并且对了解特定输入字段对目标的影响感兴趣。 源代码 这篇博文的代码包括一个训练和评估决策树和逻辑回归模型的WhizzML脚本,以及一个执行WhizzML并绘制图表的Python脚本。你可以在GitHub上查看它。 在我们的发布页面上了解更多关于Logistic回归的信息。你会发现关于如何使用Logistic回归与BigML仪表板和BigML API的文档。你还可以观看网络研讨会,查看幻灯片,并阅读本系列中关于Logistic回归的其他博文。 分享这个。
def convert_cat(df,col):
"""
输入:数据帧和分类列的col列表
输出:带有数值的数据框架
"""
for c in col:
item_list = df[c].unique().tolist()
enum=enumerate(item_list)
d = dict((j,i) for i,j in enum)
print(c)
print(d)
df[c].replace(d, inplace=True)
return df
convert_cat(df,['Circuit', 'Issue', 'Petitioner', 'Respondent',
'LowerCourt'])X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0)clf = tree.DecisionTreeClassifier('gini', min_samples_leaf=30, random_state=0)
clf = clf.fit(X_train, y_train)from sklearn import tree # 用于决策树模型
plt.figure(figsize = (20,16))
tree.plot_tree(clf, fontsize = 16,rounded = True , filled = True)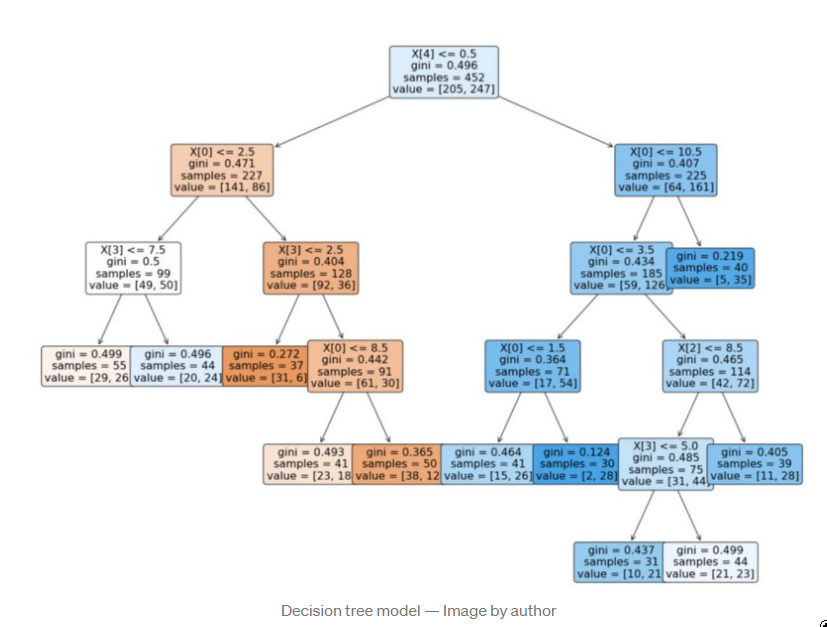
report = classification_report(predTree, y_test)
print(report)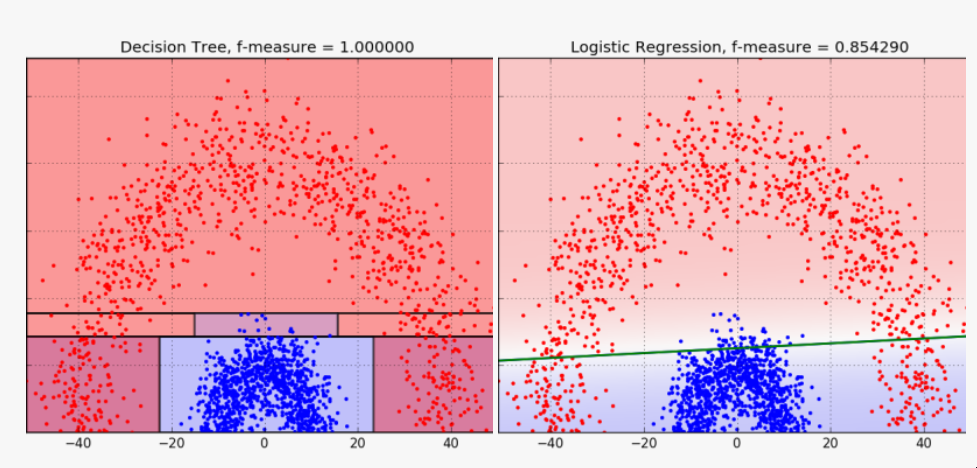
#!/usr/bin/python
import functools
import numpy as np
from matplotlib import pyplot as pp
from matplotlib.collections import PolyCollection
from matplotlib.cm import get_cmap
from bigml.api import BigML
api = BigML()
# random seed for data generation
np.random.seed(97330)
def fetch_or_create_whizzml():
"""
Fetch the ID of the model-vs-logistic whizzml script, or create it
if it does not exist.
"""
scrs = api.list_scripts('name=model-vs-logistic')['objects']
if len(scrs) > 0:
print('Found script: %s' % scrs[0]['resource'])
return api.get_script(scrs[0])
else:
print('Creating script: model-vs-logistic')
libs = api.list_libraries('name=split-dataset')['objects']
if len(libs) > 0:
print('Found split-dataset library: %s' % libs[0]['resource'])
split_dataset = api.get_library(libs[0])
else:
print('Creating library: split-dataset')
with open('split-dataset.whizzml') as fid:
split_dataset = api.create_library(fid.read(),
{'name':'split-dataset'})
with open('model-vs-logistic.whizzml') as fid:
return api.create_script(fid.read(),
{'name':'model-vs-logistic',
'inputs':[{'name':'input-source',
'type':'source-id',
'description':'identifier for input source'}],
'outputs':[{'name':'result',
'type':'list',
'description':'list of ids for created model and logistic regression, followed by respective f-measures'}],
'imports':[split_dataset['resource']]})
def linear_data(mu,sigma,n=1000,cx=-1,cy=1,intercept=0,xmin=0,xmax=100):
"""
Two classes separated by a straight line.
"""
# normal vector
nx = -cy
ny = cx
normal = np.array([[nx,ny]])
# normally distributed displacments in normal direction
yes_dists = np.random.normal(mu,sigma,[n,1])
no_dists = np.random.normal(-mu,sigma,[n,1])
# sample points along boundary and add displacements
yes_points = (np.random.uniform(xmin,xmax,[n,1])*np.array([[cx,cy]])
+ yes_dists*normal)
no_points = (np.random.uniform(xmin,xmax,[n,1])*np.array([[cx,cy]])
+ no_dists*normal)
# labels
yes_points = np.column_stack([yes_points, np.ones(n)])
no_points = np.column_stack([no_points, np.zeros(n)])
data = np.row_stack([yes_points,no_points])
np.savetxt('linsep.csv',data,header='x,y,class',
fmt='%.5f, %.5f, %d',comments='')
return [data,api.create_source('linsep.csv')]
def radial_data(mu0,sigma0,mu1,sigma1,n=1000):
"""
Two classes arranged in concentric semi-circular segments
"""
r0 = np.random.normal(mu0,sigma0,[n,1])
r1 = np.random.normal(mu1,sigma1,[n,1])
theta0 = np.random.uniform(0,np.pi,[n,1])
theta1 = np.random.uniform(0,np.pi,[n,1])
p0 = r0*np.column_stack([np.cos(theta0),np.sin(theta0)])
p0 = np.column_stack([p0, np.zeros(n)])
p1 = r1*np.column_stack([np.cos(theta1),np.sin(theta1)])
p1 = np.column_stack([p1, np.ones(n)])
data = np.row_stack([p0,p1])
np.savetxt('radsep.csv',data,header='x,y,class',
fmt='%.5f, %.5f, %d', comments='')
return [data,api.create_source('radsep.csv')]
def draw_data(data):
p0 = np.array([row for row in data if row[2] == 0])
p1 = np.array([row for row in data if row[2] == 1])
x0,y0,_ = np.hsplit(p0,[1,2])
x1,y1,_ = np.hsplit(p1,[1,2])
pp.plot(x0,y0,'b.',x1,y1,'r.')
pp.axis('tight')
def draw_node(node,xmin=None,xmax=None,ymin=None,ymax=None,last_output=None):
"""
Find the extent and fill-color for a decision tree node.
"""
pred = node['predicate']
if pred is not True:
xlim = pp.xlim()
ylim = pp.ylim()
xmin = xmin or xlim[0]
xmax = xmax or xlim[1]
ymin = ymin or ylim[0]
ymax = ymax or ylim[1]
value = pred['value']
field = pred['field']
operator = pred['operator']
output = node['output']
confidence = node['confidence']
if field == '000000':
verts_node = [[value,ymin],[value,ymax]]
if operator[0] == '<':
verts_node.extend([[xmin,ymax],[xmin,ymin]])
xmax = value
elif operator[0] == '>':
verts_node.extend([[xmax,ymax],[xmax,ymin]])
xmin = value
elif field == '000001':
verts_node = [[xmin,value],[xmax,value]]
if operator[0] == '<':
verts_node.extend([[xmax,ymin],[xmin,ymin]])
ymax = value
elif operator[0] == '>':
verts_node.extend([[xmax,ymax],[xmin,ymax]])
ymin = value
bwr = get_cmap('bwr')
if output == last_output:
fill_node = 'none'
elif output == '0':
fill_node = bwr(1-confidence)
elif output == '1':
fill_node = bwr(confidence)
verts = [verts_node]
fills = [fill_node]
else:
output = None
verts = []
fills = []
if 'children' in node:
for c in node['children']:
vs,fs = draw_node(c,xmin,xmax,ymin,ymax,output)
verts.extend(vs)
fills.extend(fs)
return verts, fills
def draw_model_splits(res):
model = api.get_model(res)['object']['model']
root = model['root']
verts,fills = draw_node(root)
pc = PolyCollection(verts,facecolors=fills,edgecolors='k',
alpha=0.4,lw=2)
pc.set_cmap('bwr')
ax = pp.gca()
ax.add_collection(pc)
def logistic(cx,cy,intercept,x,y):
return 1/(1 + np.exp(-(cx*x + cy*y + intercept)))
def draw_logistic_boundaries(res):
lr = api.get_logistic_regression(res)['object']['logistic_regression']
coeffs = lr['coefficients']
xs = np.array(pp.xlim())
for label,cs in coeffs:
cx = cs[0][0]
cy = cs[1][0]
intercept = cs[2][0]
ys = (cx*xs + intercept)/-cy
pp.plot(xs,ys,lw=2)
ys = np.array(pp.ylim())
logistic_fn = functools.partial(logistic,cx,cy,intercept)
x_grid,y_grid = np.meshgrid(np.linspace(xs[0],xs[1]),
np.linspace(ys[0],ys[1]))
probs = logistic_fn(x_grid,y_grid)
if label == '0': probs = 1-probs
print(xs)
print(ys)
pp.imshow(probs,alpha=0.2,cmap='bwr',aspect='auto',
extent=(xs[0],xs[1],ys[0],ys[1]),origin='lower')
def make_plots(data,src,script,name):
src_id = src['resource']
print('Running model-vs-logistic script with source ID %s' % src_id)
ex = api.create_execution(script,
{'inputs':[['input-source',src_id]]})
api.ok(ex)
[model,lr,model_f,lr_f] = ex['object']['execution']['result']
pp.figure()
draw_data(data)
draw_logistic_boundaries(lr)
pp.title('Logistic Regression, f-measure = %f' % lr_f)
pp.grid()
pp.savefig('lr_boundary_%s.png' % name,transparent=True)
pp.figure()
draw_data(data)
draw_model_splits(model)
pp.grid()
pp.title('Decision Tree, f-measure = %f' % model_f)
pp.savefig('model_boundary_%s.png' % name,transparent=True)
if __name__=='__main__':
script = fetch_or_create_whizzml()
[ldata,lsrc] = linear_data(20,15,cx=3)
[rdata,rsrc] = radial_data(10,3,40,5)
make_plots(ldata,lsrc,script,'linear')
make_plots(rdata,rsrc,script,'radial')
pp.show();; Generate an 80/20 training/test split from input data, train and
;; evaluate decision tree, and logistic regression. Return ids for
;; generated models, and f-measures from evaluations.
(define (model-vs-logistic sourcefile)
(let (src (create-and-wait-source sourcefile)
ds (create-and-wait-dataset src)
ids (split-dataset ds 0.8)
ds-train (nth ids 0)
ds-test (nth ids 1)
m (create-and-wait-model ds-train)
lr (create-and-wait-logisticregression ds-train)
m-eval (create-and-wait-evaluation {"model" m "dataset" ds-test})
lr-eval (create-and-wait-evaluation {"logisticregression" lr "dataset" ds-test}))
(list m lr)))(define (sample-dataset ds-id rate oob)
(create-and-wait-dataset {"sample_rate" rate
"origin_dataset" ds-id
"out_of_bag" oob
"seed" "whizzml-example"}))
(define (split-dataset ds-id rate)
(list (sample-dataset ds-id rate false)
(sample-dataset ds-id rate true)))
本文由 mdnice 多平台发布
最后
以上就是美丽小蚂蚁最近收集整理的关于Python中的决策树模型--构建、可视化、评估的全部内容,更多相关Python中内容请搜索靠谱客的其他文章。








发表评论 取消回复