突然发现之前遇到的问题是容易反复遇到的,那就随手做一个整理吧~
1. 在feature层到classifier层中,若出现如下错误:

- 则需要改变FC层的入口参数,如此图中可以改为:
x = x.view(out.size(0), -1)
self.linear = nn.Linear(320, 10) # 320为入口参数
2. 训练中training accuracy有变化,但test accuracy始终为10%(图片分类):
- 可能是由于learning rate太大导致的,如lr=0.1。可能是由于learning rate太大导致的,如lr=0.1。
- 尝试加入BN层之后优化效果明显,loss不再上下跳动,开始下降。
3.Loss过大,大到几十Billion
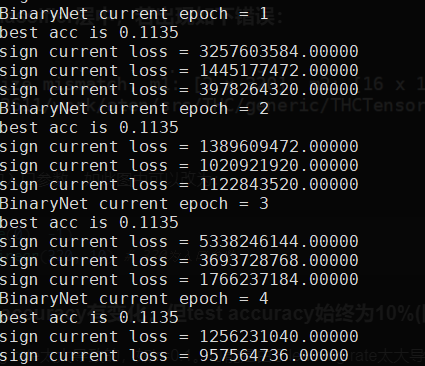
最后发现是构建网络的时候忘记加激活函数了,常用的有ReLU和Sigmoid函数。不加的话将是一个线性的网络。
4.准确率突然跳水到某一固定值
调小lr,试试1e-5.考虑这个问题是由于梯度爆炸引起的,但尚未确定,改动weight_decay未产生明显影响。
5.model出现sizes must be non-negative报错

应该计算一下图的大小,可能是图的大小不足以支持convolution的操作了,需要改变conv参数,增加padding等。
6. loss下降,但test acc几乎不变化
- 调整学习率,可能是由于学习率过大导致
- 尝试更换更复杂的模型,以确定程序本身没有问题
7. Caffe转Pytorch中,bn+scale层=bn层,
class torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
其中,affine决定了要不要α和β超参数。
8.报错:ValueError: can’t optimize a non-leaf Tensor
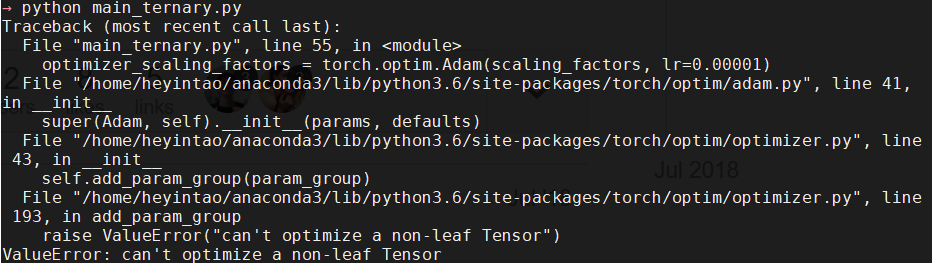
找到报错语句所对应的变量,此处为scaling_factors, 在torch.ones()函数中添加device=“cuda”
改动前:
scaling_factors = [torch.ones(2, requires_grad=True).to(device) for _ in range(len(weights_to_be_quantized))]
改动后:
scaling_factors = [torch.ones(2, requires_grad=True, device = "cuda").to(device) for _ in range(len(weights_to_be_quantized))]
即可。
9.报错checkpoint directory found!’ AssertionError: Error: no checkpoint directory found
原因是把默认的参数放到了需指定参数的前面,调整save_model的函数入口参数顺序即可
10.load模型时报错RuntimeError: Error(s) in loading state_dict for ConvNet:

解决方案:原因是保存模型的时候使用了nn.DataParallel(会把模型保存到.module里),但是load的时候没有使用。把nn.DataParallel定义在load模型之前即可。
11.加载数据集时报错OSError: Not a gzipped file (b’<h’)
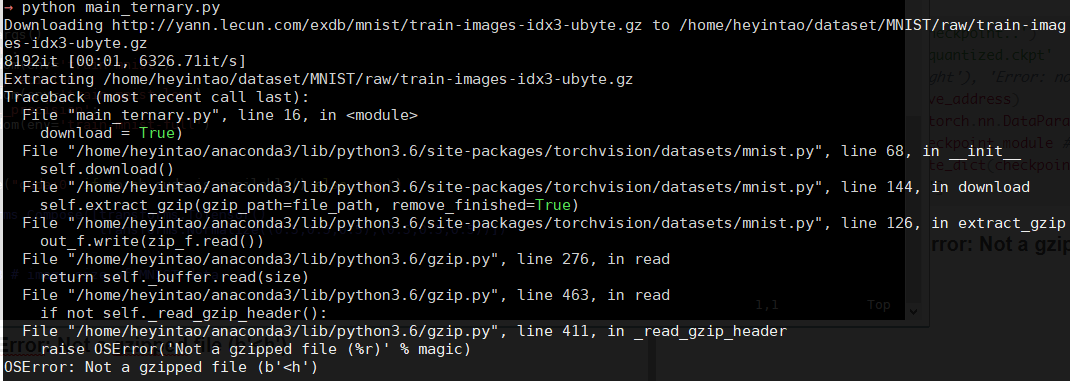
实际上检测的不是MNIST/raw里面的.gz文件,而是MNIST/processed里面的training.pt和test.pt文件,从其他编译好的project里面copy即可。
12.运行时报错AttributeError: ‘builtin_function_or_method’ object has no attribute ‘numpy’
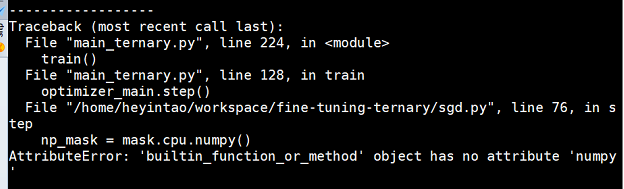 改动前:
改动前:
np_mask = mask.cpu.numpy()
改动后:
np_mask = mask.cpu().numpy()
即可。
12.运行时报错RuntimeError: output with shape [1, 28, 28] doesn’t match the broadcast shape [3, 28, 28]

其实是在把跑cifar10的网络改成了mnist,其中数据预处理需要修改,如图

应为2维而非3维
13.torch.where()的用法
由于在torch中使用for循环遍历速度太慢,采用torch.where()是更好的选择,其用法为
torch.where(a>0,b,c)
torch.where()是一个element-wise的操作,遍历a中每个element,若满足则取b中元素赋值,否则取c。
根据官网,tensor a应该与b和c是broadcasting的,但维度可以不一样。其中的broadcasting需要满足两个条件:
- 每个 tensor 至少有一维
- 遍历所有的维度,从尾部维度开始,每个对应的维度大小要么相同,要么其中一个是 1,要么其中一个不存在。
因此,在对2D的conv层进行操作时,假设要对out channel进行操作,则可以写成:
# weight.size() = (out_channel, in_channel, kernel_size, kernel_size) in conv2D layer
flags = torch.tensor(2, out_channel, 1, 1, 1) # define flags for first and second slices of in_channel
weight_pos = torch.where(flags[0].detach()>0, self.weight[:, :slipt, :, :], torch.tensor(0.).type(torch.cuda.FloatTensor))
14.tensorboard突然报错ImportError: libcudnn.so.7: cannot open shared object file: No such file or directory
之前一直可以正常显示,突然报错,是环境变量的问题:
source ~/.bashrc
source ~/.zshrc #if using zsh
15.报错RuntimeError: arguments are located on different GPUs at /pytorch/aten/src/THC/generic/THCTensorMathCompareT.cu:15
一般load模型之后,对weights进行一些自定义函数的操作,函数内部可能会出现这个错误,可以
print(weight.device)
print(shift.device)
就会发现weight和shift两个tensor分别在cuda(0)和cuda(1)上,直接
shift = shift.cuda(0)
即可。
16.发现loss和val_acc完全被stuck住了,一直不动,而train_acc会变化
可能是因此计算图断开,在自己定义forward的过程中,要注意避免先定义一个tensor,然后再修改其值的操作,容易导致计算图断开,因此在backward里面无法自动求导更新。
记录一下这次的解决方法,很神奇,在改完以上的东西之后,还将
weight_pos = torch.zeros(out_num)
改为了
weight_pos = torch.randn(out_num) #requires_grad=True
17.以mnist为数据集,加载了pretrain model之后,训练过程中出现一些奇怪的现象,比如val_loss一直不动,而且准确率很低,或者报“Warning: NaN or Inf found in input tensor”
原因可能是学习率设置过大,可以调整为1e-7试一试。
18.报错RuntimeError: expected Double tensor (got Float tensor)
x = x.double() #added
y = f(x)
19. 已安装tensorboard,运行时报错command not found: tensorboard
最简单的方法卸载tensorboard然后重新装,装的时候注意版本问题
我使用的是pytorch 1.1.0古早版本,对应于tensorboard==1.15.0和tensorflow-gpu==1.15.0可用。安装2.x以上的tensorboard会出现兼容问题。
最后
以上就是和谐蚂蚁最近收集整理的关于记录Pytorch中遇到的问题的全部内容,更多相关记录Pytorch中遇到内容请搜索靠谱客的其他文章。








发表评论 取消回复