文章目录
- 引入
- 1 填充
- 2 步幅
引入
一般来说,对于输入为
n
h
×
n
w
n_h times n_w
nh×nw的矩阵,以及
k
h
×
k
w
k_h times k_w
kh×kw的核矩阵,互相关运算后,输出的形状将会是:
(
n
h
−
k
h
+
1
)
×
(
n
w
−
k
w
+
1
)
.
(1)
(n_h - k_h + 1) times (n_w - k_w + 1). tag{1}
(nh−kh+1)×(nw−kw+1).(1) 因此,卷积层的输出形状是由输入形状和卷积核矩阵形状决定。
本节主要介绍卷积层的两个超参数,即填充和步幅:可以对给定形状的输入和卷积核改变输出形状。
1 填充
填充 (padding)是指在输入高和宽的两侧填充元素 (通常为
0
0
0)。例如下图中 (图片源自原书),对输入矩阵的两侧分别添加了
0
0
0值,使得输入由
3
×
3
3 times 3
3×3变为
5
×
5
5 times 5
5×5,从而导致输出由
2
×
2
2 times 2
2×2变为
4
×
4
4 times 4
4×4。
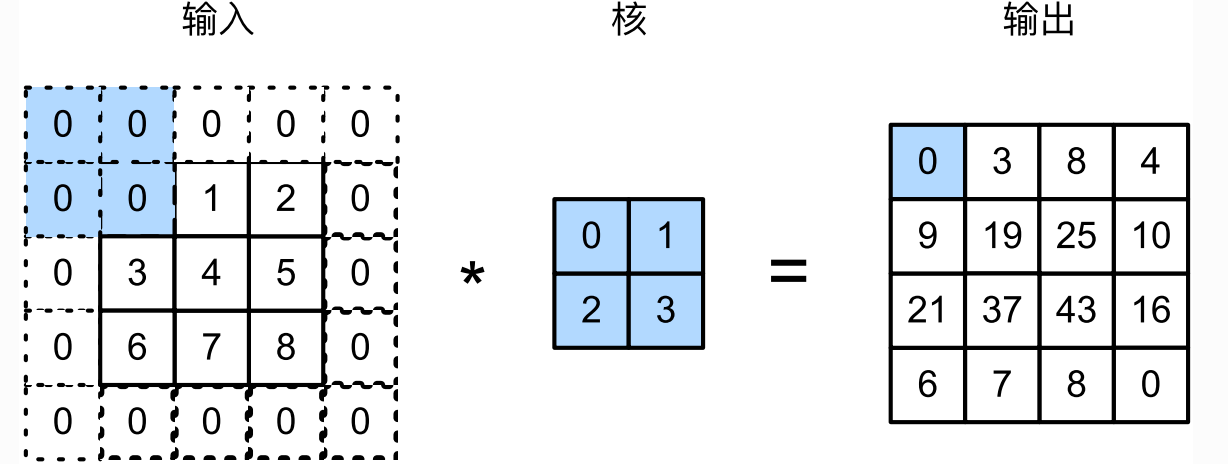
一般来说,如果在高的两侧一共填充
p
h
p_h
ph行,在宽的两侧一共填充
p
w
p_w
pw列,那么输出形状将会是:
(
n
h
−
k
h
+
p
h
+
1
)
×
(
n
w
−
k
w
+
p
w
+
1
)
.
(2)
(n_h - k_h + p_h + 1) times (n_w - k_w + p_w + 1). tag{2}
(nh−kh+ph+1)×(nw−kw+pw+1).(2) 很多情况下,会设置
p
h
=
k
h
−
1
p_h = k_h -1
ph=kh−1、
p
w
=
k
w
−
1
p_w = k_w - 1
pw=kw−1来使得输入输出具有相同的形状。这样做的好处为,在构造网络时可以推测每个层的输出形状。
具体的,假设
k
h
k_h
kh是奇数,会在输入上下分别填充
p
h
/
2
p_h / 2
ph/2行;偶数,则在输入的顶端填充
⌈
p
h
/
2
⌉
lceil p_h / 2 rceil
⌈ph/2⌉,在输入的下端填充
⌊
p
h
/
2
⌋
lfloor p_h / 2 rfloor
⌊ph/2⌋行。
k
w
k_w
kw同理。
在卷积神经网络中,经常使用奇数高宽的卷积核,如
1
1
1、
3
3
3、
5
5
5和
7
7
7等,所有在两端的填充个数相等。
对于任意的二维数组
x
=
[
x
i
j
]
x = [x_{ij}]
x=[xij],荡两端的填充个数相等,且使输入和输出具有相同的高和宽时,就能知道输出
y
=
[
y
i
j
]
y = [y_{ij}]
y=[yij]是由输入以
x
x
x为中心的窗口同卷积核进行互相关计算得到的。
import torch
import warnings
import torch.nn as nn
warnings.filterwarnings('ignore')
def comp_conv2d(conv2d, x):
# 1, 1: Single batch and single channel.
x = x.view((1, 1) + x.shape)
y = conv2d(x)
return y.view(y.shape[2:]) # Do not consider the batch and channel.
if __name__ == '__main__':
torch.manual_seed(1)
temp_conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=1)
temp_x = torch.rand(2, 2)
print(temp_x)
print(comp_conv2d(temp_conv2d, temp_x))
输出如下:
tensor([[0.6387, 0.5247],
[0.6826, 0.3051]])
tensor([[-0.0065, -0.1006],
[-0.3219, 0.0027]], grad_fn=<ViewBackward>)
该设置下,输入与输出将是等大小。
当然,当核矩阵的高与宽不同时,也可设置不同的填充数:
if __name__ == '__main__':
torch.manual_seed(1)
temp_conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 5), padding=(1, 2))
temp_x = torch.rand(2, 2)
print(temp_x)
print(comp_conv2d(temp_conv2d, temp_x))
输出如下:
tensor([[0.5725, 0.4980],
[0.9371, 0.6556]])
tensor([[ 0.0922, 0.0855],
[ 0.1551, -0.0771]], grad_fn=<ViewBackward>)
2 步幅
步幅 (stride)用于控制每次窗口滑动的行数和列数。一个例子如下图。
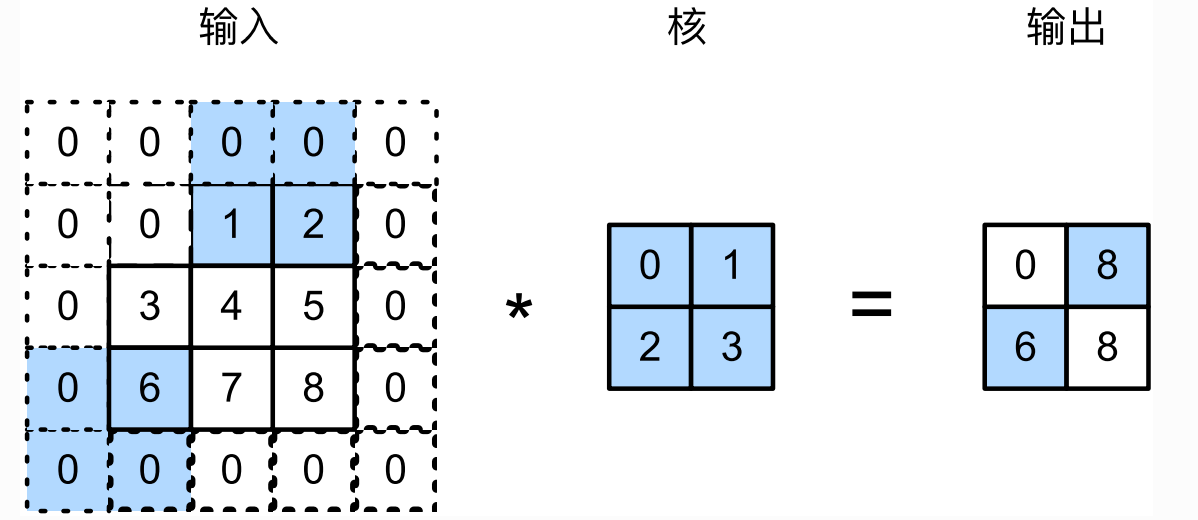
一般来说,当高上步幅为
s
h
s_h
sh,宽上步幅为
s
w
s_w
sw时,输出的形状为
⌊
(
n
h
−
k
h
+
p
h
+
s
h
)
/
s
h
⌋
×
⌊
(
n
w
−
k
w
+
p
w
+
s
w
)
/
s
w
⌋
.
(3)
lfloor (n_h - k_h + p_h + s_h) / s_h rfloor times lfloor (n_w - k_w + p_w + s_w) / s_w rfloor. tag{3}
⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋.(3) 进一步,如果设置
p
h
=
k
h
−
1
p_h = k_h - 1
ph=kh−1和
p
W
=
k
w
−
1
p_W = k_w - 1
pW=kw−1,那么输出的形状将为
⌊
(
n
h
+
s
h
−
1
)
/
s
h
⌋
×
⌊
(
n
w
+
s
w
−
1
)
/
s
w
⌋
.
(4)
lfloor (n_h + s_h - 1) / s_h rfloor times lfloor (n_w + s_w - 1) / s_w rfloor. tag{4}
⌊(nh+sh−1)/sh⌋×⌊(nw+sw−1)/sw⌋.(4) 更进一步,如果输入的高和宽能分别被高和宽上的步幅整除,则输出形状为
(
n
h
/
s
h
)
×
(
n
w
/
s
w
)
(n_h / s_h) times (n_w / s_w)
(nh/sh)×(nw/sw)。
torch中,只需设置stride参数:
if __name__ == '__main__':
torch.manual_seed(1)
temp_conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 5), padding=(1, 2), stride=2)
temp_x = torch.rand(2, 2)
print(temp_x)
print(comp_conv2d(temp_conv2d, temp_x))
输出如下:
tensor([[0.5725, 0.4980],
[0.9371, 0.6556]])
tensor([[0.0922]], grad_fn=<ViewBackward>)
参考文献
[1] 李沐、Aston Zhang等老师的这本《动手学深度学习》一书。
最后
以上就是虚拟缘分最近收集整理的关于torch学习 (十七):填充和步幅引入1 填充2 步幅的全部内容,更多相关torch学习内容请搜索靠谱客的其他文章。








发表评论 取消回复