鲁棒算法
--有噪声也可以产生可接受的结果。
使用【特征、变量】替代【属性】。
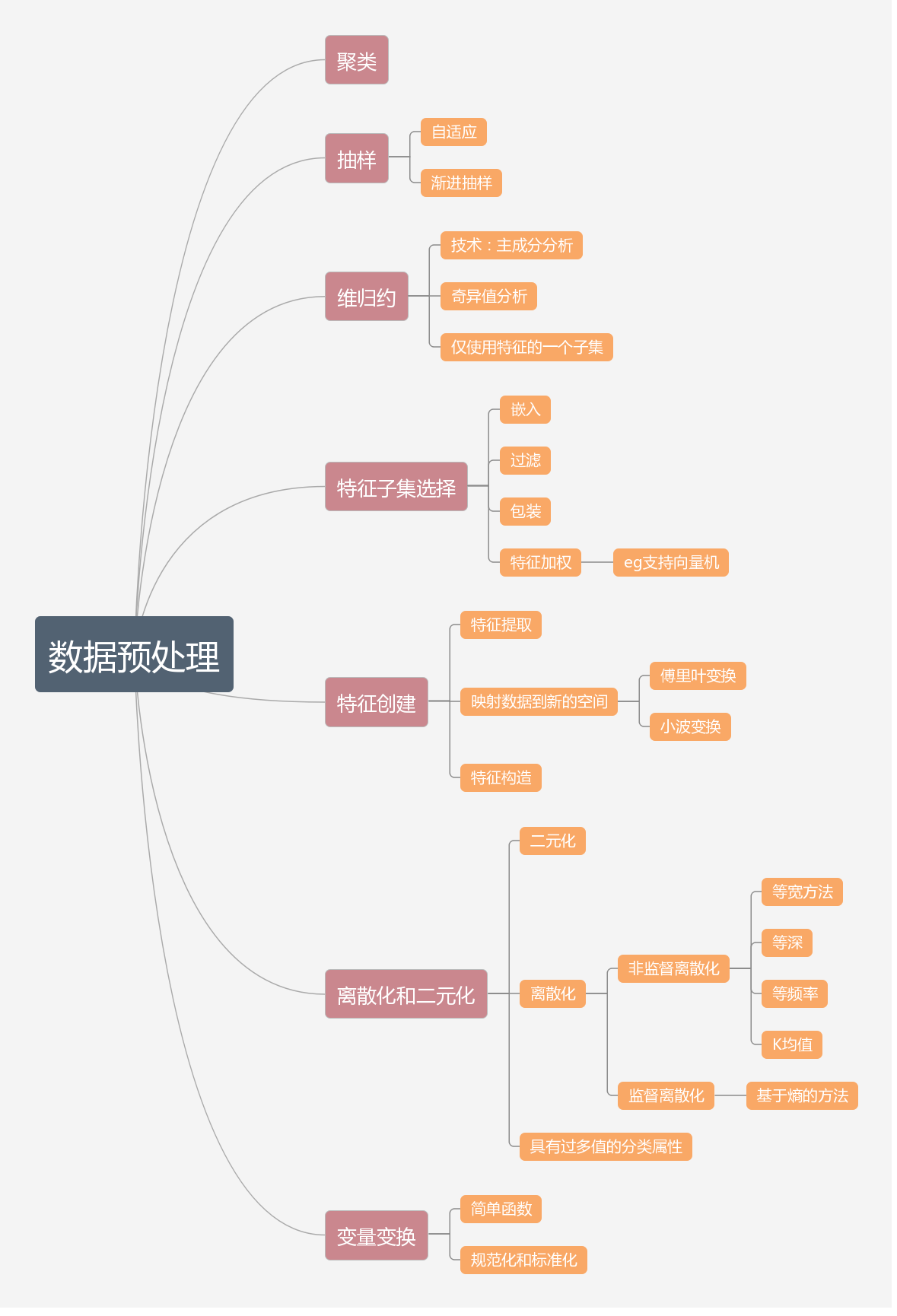
数据预处理
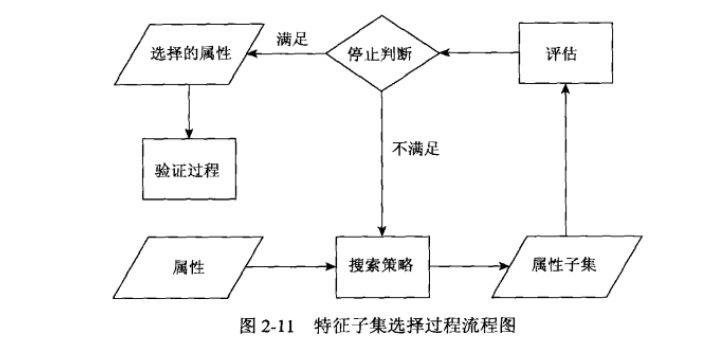
1.特征子集选择


2.特征提取:
由原始数据创建新的特征集。
3.将特征映射到新空间

4.特征构造:
由一个或者多个原始特征构造新的特征。
5.二元化
6.非监督离散化

7.具有过多值的分类属性

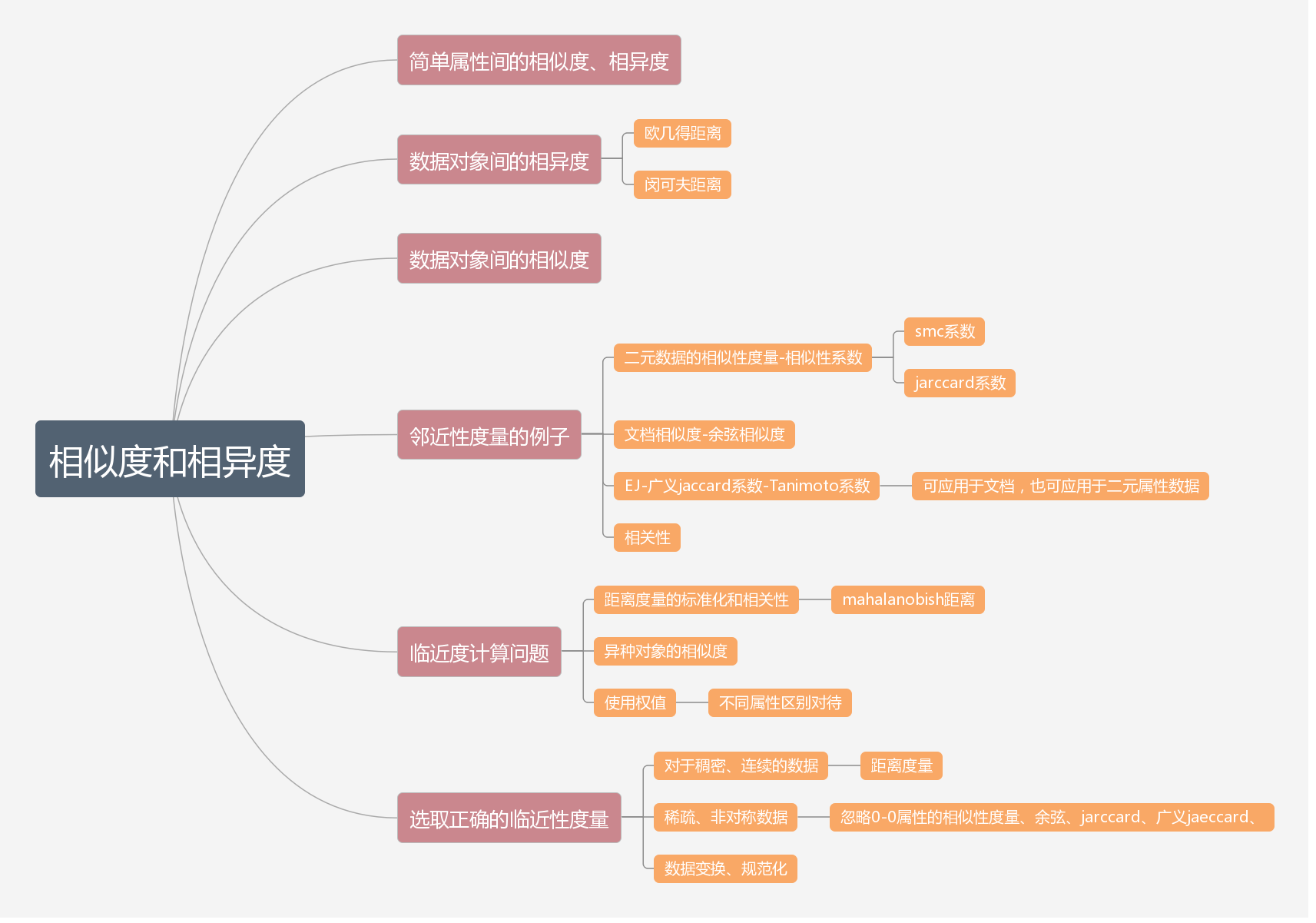
二、相似性和相异性的度量
1.距离
参考:数学中常见的距离
https://blog.csdn.net/Losteng/article/details/50893931
2.非度量的距离--集合差、时间
度量:
3.相关性
只能检查是否存在线性相关,(-1,1);若为0,则不存在线性相关,有可能由非线性相关。
4.相似系数
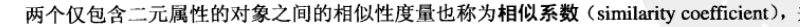
5.Bregman散度
6.mahalanobish距离


7.非对称属性
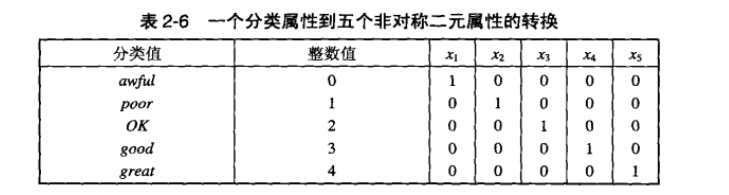
只有非零属性值才重要的属性称为非对称属性,比如二元属性,当考虑普通人的患癌情况时,健康时属性为0,患癌时为1,这样大部分情况下该属性都为0,因此我们一般只关注属性为1的情况,所以这个就是非对称的二元属性。
8.组合异种属性的相似度:
如果两个对象非对称属性上的值都为0,则计算相似度时忽略他们,可以很好地处理遗漏值

*不懂

最后
以上就是激昂大地最近收集整理的关于数据挖掘导论笔记1——第二章:数据的全部内容,更多相关数据挖掘导论笔记1——第二章内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复