Gradle是用Groovy编写的构建工具,通过编写build.gradle脚本文件对项目进行设置,再根据这个脚本对项目进行构建(复杂的项目也有其他文件)。
Groovy是JVM衍生的与JAVA语法高度兼容的动态强类型语言。当执行Groovy脚本时,Groovy会先将其编译成Java类字节码,然后通过Jvm来执行这个Java类。
一)GVM(the Groovy enVironment Manager)
GVM,简单来说,就是管理groovy开发环境的工具。用这个工具可以很方便的查询,下载多个不同版本的groovy,指定需要用的版本,也可以下载管理grails,gradle等等。
用GVM搭建groovy开发环境仅仅需要如下2步:
1.curl -s get.gvmtool.net | bash
此命令在系统里部署gvm。需要重新source一下shell配置文件,使得一些配置生效(source"$HOME/.gvm/bin/gvm-init.sh")
2.gvm install groovy
此命令安装最近稳定版的groovy,并指明此groovy为当前使用的groovy版本。
上述安装在Ubuntu及centos试验均没有成功,我是按照
http://www.cnblogs.com/frankM/p/4604202.html
做的安装。
以下关于Groovy语法和数据类型等内容节选自:http://www.infoq.com/cn/articles/android-in-depth-gradle/
二)Groovy语法
Groovy语句可以不用分号结尾
Groovy中支持动态类型,即定义变量的时候可以不指定其类型。Groovy中,变量定义可以使用关键字def。注意,虽然def不是必须的,但是为了代码清晰,建议还是使用def关键字
def variable1 =
1
函数定义时,参数的类型也可以不指定。比如
StringtestFunction(arg1,arg2){//无需指定参数类型
...
}
除了变量定义可以不指定类型外,Groovy中函数的返回值也可以是无类型的。比如:
//无类型的函数定义,必须使用def关键字
def nonReturnTypeFunc(){ last_line //最后一行代码的执行结果就是本函数的返回值} //如果指定了函数返回类型,则可不必加def关键字来定义函数String getString(){ return "I am a string"}函数返回值:Groovy的函数里,可以不使用return xxx来设置xxx为函数返回值。如果不使用return语句的话,则函数里最后一句代码的执行结果被设置成返回值。比如
//下面这个函数的返回值是字符串"getSomething return value"
defgetSomething(){
"getSomething return value"//如果这是最后一行代码,则返回类型为String
1000//如果这是最后一行代码,则返回类型为Integer
}
注意,如果函数定义时候指明了返回值类型的话,函数中则必须返回正确的数据类型,否则运行时报错。如果使用了动态类型的话,你就可以返回任何类型了。
Groovy对字符串支持相当强大,充分吸收了一些脚本语言的优点:
1 单引号''中的内容严格对应Java中的String,不对$符号进行转义
def singleQuote='I am $ dolloar' //输出就是I am $ dolloar2 双引号""的内容则和脚本语言的处理有点像,如果字符中有$号的话,则它会$表达式先求值。
def doubleQuoteWithoutDollar = "I am one dollar" //输出 I am one dollar def x = 1 def doubleQuoteWithDollar = "I am $x dolloar" //输出I am 1 dolloar3 三个引号'''xxx'''中的字符串支持随意换行 比如
def multieLines = ''' begin line 1 line 2 end '''
最后,除了每行代码不用加分号外,Groovy中函数调用的时候还可以不加括号。比如:
println("test") ---> println "test"注意,虽然写代码的时候,对于函数调用可以不带括号,但是Groovy经常把属性和函数调用混淆。比如
def getSomething(){ "hello"}getSomething() //如果不加括号的话,Groovy会误认为getSomething是一个变量。
三)Groovy的数据类型
几种和Java不太一样的:
· 一个是Java中的基本数据类型。
· 另外一个是Groovy中的容器类。
· 最后一个非常重要的是闭包。1)基本数据类型
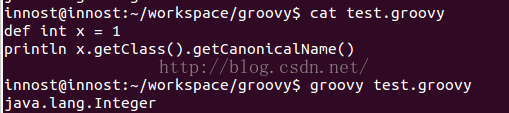
作为动态语言,Groovy世界中的所有事物都是对象。所以,int,boolean这些Java中的基本数据类型,在Groovy代码中其实对应的是它们的包装数据类型。比如int对应为Integer,boolean对应为Boolean。比如下图中的代码执行结果:
2)容器类
Groovy中的容器类很简单,就三种:
· List:链表,其底层对应Java中的List接口,一般用ArrayList作为真正的实现类。
· Map:键-值表,其底层对应Java中的LinkedHashMap。
· Range:范围,它其实是List的一种拓展。
对容器而言,我们最重要的是了解它们的用法。下面是一些简单的例子:
1. List类
变量定义:List变量由[]定义,比如 def aList = [5,'string',true] //List由[]定义,其元素可以是任何对象 变量存取:可以直接通过索引存取,而且不用担心索引越界。如果索引超过当前链表长度,List会自动往该索引添加元素 assert aList[1] == 'string'assert aList[5] == null //第6个元素为空aList[100] = 100 //设置第101个元素的值为10assert aList[100] == 100 那么,aList到现在为止有多少个元素呢? println aList.size ===>结果是1012. Map类
容器变量定义 变量定义:Map变量由[:]定义,比如 def aMap = ['key1':'value1','key2':true] Map由[:]定义,注意其中的冒号。冒号左边是key,右边是Value。key必须是字符串,value可以是任何对象。另外,key可以用''或""包起来,也可以不用引号包起来。比如 def aNewMap = [key1:"value",key2:true] //其中的key1和key2默认被处理成字符串"key1"和"key2" 不过Key要是不使用引号包起来的话,也会带来一定混淆,比如 def key1="wowo"def aConfusedMap=[key1:"who am i?"] aConfuseMap中的key1到底是"key1"还是变量key1的值“wowo”?显然,答案是字符串"key1"。如果要是"wowo"的话,则aConfusedMap的定义必须设置成: def aConfusedMap=[(key1):"who am i?"] Map中元素的存取更加方便,它支持多种方法: println aMap.keyName <==这种表达方法好像key就是aMap的一个成员变量一样println aMap['keyName'] <==这种表达方法更传统一点aMap.anotherkey = "i am map" <==为map添加新元素3. Range类
Range是Groovy对List的一种拓展,变量定义和大体的使用方法如下:
def aRange = 1..5 <==Range类型的变量 由begin值+两个点+end值表示 左边这个aRange包含1,2,3,4,5这5个值 如果不想包含最后一个元素,则 def aRangeWithoutEnd = 1..<5 <==包含1,2,3,4这4个元素println aRange.fromprintln aRange.to
3)闭包
闭包,英文叫Closure,是Groovy中非常重要的一个数据类型。
闭包,是一种数据类型,它代表了一段可执行的代码。其外形如下:
def aClosure = {//闭包是一段代码,所以需要用花括号括起来.. String param1, int param2 -> //这个箭头很关键。箭头前面是参数定义,箭头后面是代码 println "this is code" //这是代码,最后一句是返回值, //也可以使用return,和Groovy中普通函数一样 } 简而言之,Closure的定义格式是:
def xxx = {paramters -> code} //或者 def xxx = {无参数,纯code} 这种case不需要->符号说实话,从C/C++语言的角度看,闭包和函数指针很像。闭包定义好后,要调用它的方法就是:
闭包对象.call(参数) 或者更像函数指针调用的方法:
闭包对象(参数)
比如:
aClosure.call("this is string",100) 或者 aClosure("this is string", 100) 上面就是一个闭包的定义和使用。在闭包中,还需要注意一点:
如果闭包没定义参数的话,则隐含有一个参数,这个参数名字叫it,和this的作用类似。it代表闭包的参数。
比如:
def greeting = { "Hello, $it!" }assert greeting('Patrick') == 'Hello, Patrick!'等同于:
def greeting = { it -> "Hello, $it!" }assert greeting('Patrick') == 'Hello, Patrick!'但是,如果在闭包定义时,采用下面这种写法,则表示闭包没有参数!
def noParamClosure = { -> true }这个时候,我们就不能给noParamClosure传参数了!
noParamClosure ("test") <==报错喔!
4)Closure使用中的注意点
1. 省略圆括号
闭包在Groovy中大量使用,比如很多类都定义了一些函数,这些函数最后一个参数都是一个闭包。比如:
public static <T> List<T> each(List<T> self, Closure closure)上面这个函数表示针对List的每一个元素都会调用closure做一些处理。这里的closure,就有点回调函数的感觉。但是,在使用这个each函数的时候,我们传递一个怎样的Closure进去呢?比如:
def iamList = [1,2,3,4,5] //定义一个ListiamList.each{ //调用它的each,这段代码的格式看不懂了吧?each是个函数,圆括号去哪了? println it}上面代码有两个知识点:
· each函数调用的圆括号不见了!原来,Groovy中,当函数的最后一个参数是闭包的话,可以省略圆括号。比如
def testClosure(int a1,String b1, Closure closure){ //do something closure() //调用闭包}那么调用的时候,就可以免括号!testClosure (4, "test", { println "i am in closure"} ) //红色的括号可以不写..注意,这个特点非常关键,因为以后在Gradle中经常会出现下图这样没有圆括号的代码:
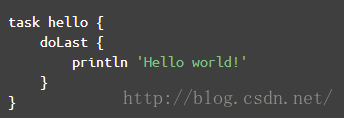
省略圆括号虽然使得代码简洁,看起来更像脚本语言,但是它这经常会让我confuse(不知道其他人是否有同感),以doLast为例,完整的代码应该按下面这种写法:
doLast({ println 'Hello world!'})有了圆括号,你会知道 doLast只是把一个Closure对象传了进去。很明显,它不代表这段脚本解析到doLast的时候就会调用println'Hello world!' 。
但是把圆括号去掉后,就感觉好像println 'Hello world!'立即就会被调用一样!
2. 如何确定Closure的参数
另外一个比较让人头疼的地方是,Closure的参数该怎么搞?还是刚才的each函数:
public static <T> List<T> each(List<T> self, Closure closure)如何使用它呢?比如:
def iamList = [1,2,3,4,5] //定义一个List变量iamList.each{ //调用它的each函数,只要传入一个Closure就可以了。 println it}看起来很轻松,其实:
· 对于each所需要的Closure,它的参数是什么?有多少个参数?返回值是什么?
我们能写成下面这样吗?
iamList.each{String name,int x -> return x} //运行的时候肯定报错!所以,Closure虽然很方便,但是它一定会和使用它的上下文有极强的关联。要不,作为类似回调这样的东西,我如何知道调用者传递什么参数给Closure呢?
此问题如何破解?只能通过查询API文档才能了解上下文语义。比如下图: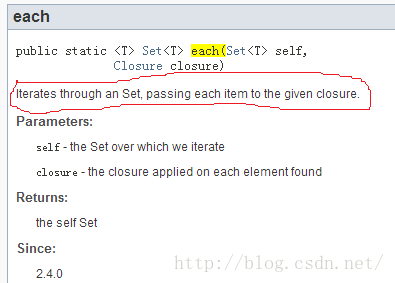
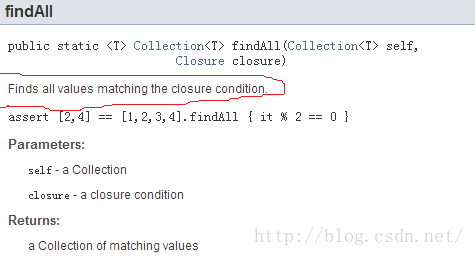
· each函数说明中,将给指定的closure传递Set中的每一个item。所以,closure的参数只有一个。
· findAll中,绝对抓瞎了。一个是没说明往Closure里传什么。另外没说明Closure的返回值是什么.....。
对Map的findAll而言,Closure可以有两个参数。findAll会将Key和Value分别传进去。并且,Closure返回true,表示该元素是自己想要的。返回false表示该元素不是自己要找的。示意代码如下图所示:

Closure的使用有点坑,很大程度上依赖于你对API的熟悉程度,所以最初阶段,SDK查询是少不了的。
四)Groovy API
Groovy的API文档位于http://www.groovy-lang.org/api.html
以上文介绍的Range为例,我们该如何更好得使用它呢?
· 先定位到Range类。它位于groovy.lang包中:
有了API文档,你就可以放心调用其中的函数了。不过,不过,不过:我们刚才代码中用到了Range.from/to属性值,但翻看Range API文档的时候,其实并没有这两个成员变量。
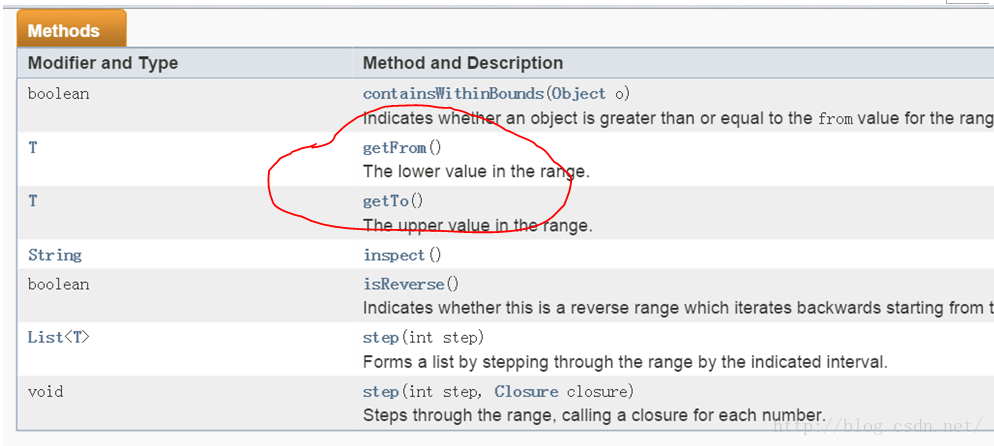
文档中并没有说明Range有from和to这两个属性,但是却有getFrom和getTo这两个函数。Whathappened?原来:
根据Groovy的原则,如果一个类中有名为xxyyzz这样的属性(其实就是成员变量),Groovy会自动为它添加getXxyyzz和setXxyyzz两个函数,用于获取和设置xxyyzz属性值。
注意,get和set后第一个字母是大写的
所以,当你看到Range中有getFrom和getTo这两个函数时候,就得知道潜规则下,Range有from和to这两个属性。当然,由于它们不可以被外界设置,所以没有公开setFrom和setTo函数。
五)脚本类、文件I/O和XML操作
Java中,我们最熟悉的是类。但是我们在Java的一个源码文件中,不能不写class(interface或者其他....),而Groovy可以像写脚本一样,把要做的事情都写在xxx.groovy中,而且可以通过groovyxxx.groovy直接执行这个脚本。这到底是怎么搞的?
既然是基于Java的,Groovy会先把xxx.groovy中的内容转换成一个Java类。比如:
test.groovy的代码是:
println 'Groovy world!' Groovy把它转换成这样的Java类:
执行 groovyc -dclasses test.groovy
groovyc是groovy的编译命令,-dclasses用于将编译得到的class文件拷贝到classes文件夹下
下图是test.groovy脚本转换得到的java class。用jd-gui反编译它的代码:
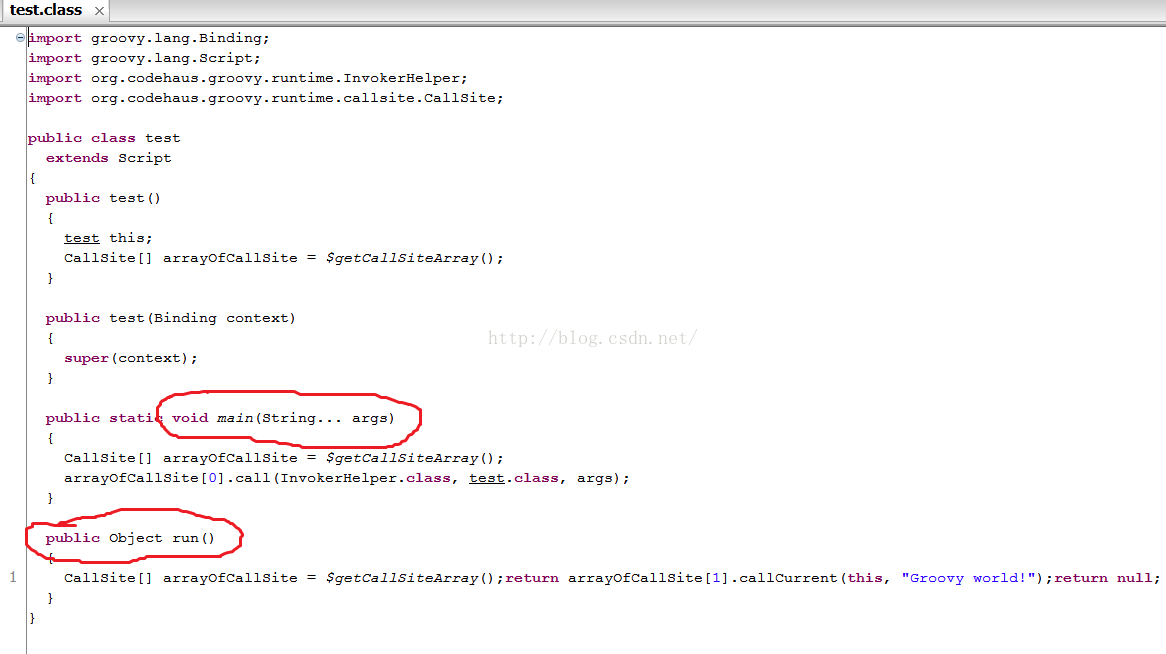
图中:
· test.groovy被转换成了一个test类,它从script派生。
· 每一个脚本都会生成一个static main函数。这样,当我们groovytest.groovy的时候,其实就是用java去执行这个main函数
· 脚本中的所有代码都会放到run函数中。比如,println'Groovy world',这句代码实际上是包含在run函数里的。
· 如果脚本中定义了函数,则函数会被定义在test类中。
groovyc是一个比较好的命令,读者要掌握它的用法。然后利用jd-gui来查看对应class的Java源码。
2) 脚本中的变量和作用域
前面说了,xxx.groovy只要不是和Java那样的class,那么它就是一个脚本。而且脚本的代码其实都会被放到run函数中去执行。那么,在Groovy的脚本中,很重要的一点就是脚本中定义的变量和它的作用域。举例:
def x = 1 <==注意,这个x有def(或者指明类型,比如 int x = 1) def printx(){ println x } printx() <==报错,说x找不到
为什么?继续来看反编译后的class文件。
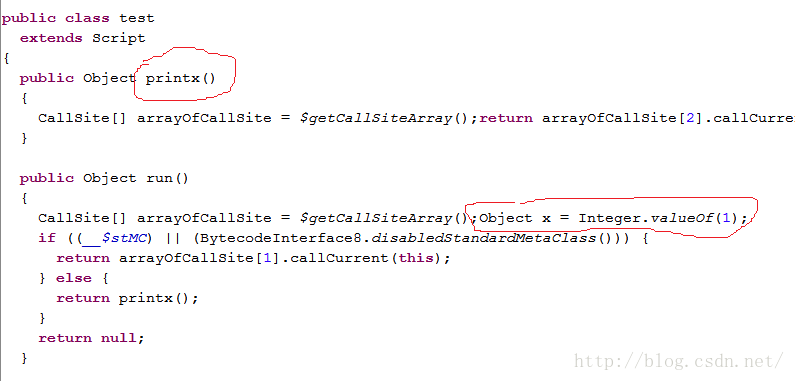
图中:
· printx被定义成test类的成员函数
· def x = 1,这句话是在run中创建的。所以,x=1从代码上看好像是在整个脚本中定义的,但实际上printx访问不了它。printx是test成员函数,除非x也被定义成test的成员函数,否则printx不能访问它。
那么,如何使得printx能访问x呢?很简单,定义的时候不要加类型和def。即:
x = 1 <==注意,去掉def或者类型def printx(){ println x}printx() <==OK这次Java源码又变成什么样了呢?
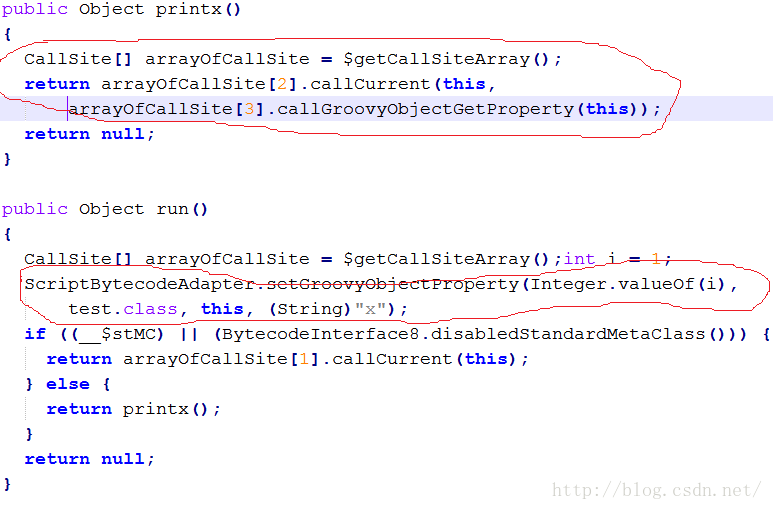
图中,x也没有被定义成test的成员函数,而是在run的执行过程中,将x作为一个属性添加到test实例对象中了。然后在printx中,先获取这个属性。
注意,Groovy的文档说 x = 1这种定义将使得x变成test的成员变量,但从反编译情况看,这是不对的.....
虽然printx可以访问x变量了,但是假如有其他脚本却无法访问x变量。因为它不是test的成员变量。
比如,我在测试目录下创建一个新的名为test1.groovy。这个test1将访问test.groovy中定义的printx函数:
这种方法使得我们可以将代码分成模块来编写,比如将公共的功能放到test.groovy中,然后使用公共功能的代码放到test1.groovy中。
执行groovy test1.groovy,报错。说x找不到。这是因为x是在test的run函数动态加进去的。怎么办?
import groovy.transform.Field; //必须要先import@Field x = 1 <==在x前面加上@Field标注,这样,x就彻彻底底是test的成员变量了。查看编译后的test.class文件,得到:
这个时候,test.groovy中的x就成了test类的成员函数了。如此,我们可以在script中定义那些需要输出给外部脚本或类使用的变量了!
2) 文件I/O操作
整体说来,Groovy的I/O操作是在原有Java I/O操作上进行了更为简单方便的封装,并且使用Closure来简化代码编写。主要封装了如下一些了类:

1. 读文件
Groovy中,文件读操作简单到令人发指:
def targetFile = new File(文件名) <==File对象还是要创建的。
然后打开http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/File.html
看看Groovy定义的API:
1 读该文件中的每一行:eachLine的唯一参数是一个Closure。Closure的参数是文件每一行的内容
其内部实现肯定是Groovy打开这个文件,然后读取文件的一行,然后调用Closure...
targetFile.eachLine{ String oneLine -> println oneLine <==是不是令人发指??! 2 直接得到文件内容
targetFile.getBytes() <==文件内容一次性读出,返回类型为byte[] 注意前面提到的getter和setter函数,这里可以直接使用targetFile.bytes //....
3 使用InputStream.InputStream的SDK在 http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/InputStream.html
def ism = targetFile.newInputStream() //操作ism,最后记得关掉 ism.close 注:实际操作中发现发生如下异常:Caught: groovy.lang.MissingPropertyException: No such property: close for class: java.io.BufferedInputStream
Possible solutions: class
groovy.lang.MissingPropertyException: No such property: close for class: java.io.BufferedInputStream修改为ism.close()后异常消失,疑因把close误认为是属性引起的。4 使用闭包操作inputStream,以后在Gradle里会常看到这种搞法
targetFile.withInputStream{ism->
操作ism.不用close。Groovy会自动替你close
}
确实够简单,令人发指。我当年死活也没找到withInputStream是个啥意思。所以,请各位开发者牢记GroovyI/O操作相关类的SDK地址:
· java.io.File: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/File.html
· java.io.InputStream: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/InputStream.html
· java.io.OutputStream: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/OutputStream.html
· java.io.Reader: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/Reader.html
· java.io.Writer: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/Writer.html
· java.nio.file.Path: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/nio/file/Path.html
2. 写文件
和读文件差不多。不再啰嗦。这里给个例子,告诉大家如何copy文件。
defsrcFile=newFile(源文件名)
deftargetFile=newFile(目标文件名)
targetFile.withOutputStream{os->
srcFile.withInputStream{ins->
os<<ins//利用OutputStream的<<操作符重载,完成从inputstream到OutputStream
//的输出
}
}
关于OutputStream的<<操作符重载,查看SDK文档后可知:
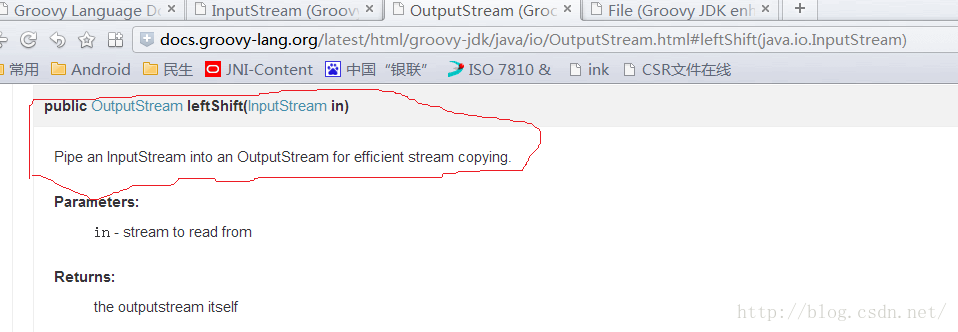
3) XML操作
除了I/O异常简单之外,Groovy中的XML操作也极致得很。Groovy中,XML的解析提供了和XPath类似的方法,名为GPath。这是一个类,提供相应API。关于XPath,请看Wiki。
GPath功能包括:给个例子好了,来自Groovy官方文档。
test.xml文件:
<response version-api="2.0">
<value>
<books>
<book available="20"id="1">
<title>Don Xijote</title>
<author id="1">Manuel De Cervantes</author>
</book>
<book available="14"id="2">
<title>Catcher in the Rye</title>
<author id="2">JD Salinger</author>
</book>
<book available="13"id="3">
<title>Alice in Wonderland</title>
<author id="3">Lewis Carroll</author>
</book>
<book available="5"id="4">
<title>Don Xijote</title>
<author id="4">Manuel De Cervantes</author>
</book>
</books>
</value>
</response>
· 现在来看怎么玩转GPath:
//第一步,创建XmlSlurper类
defxparser=newXmlSlurper()
deftargetFile=newFile("test.xml")
//轰轰的GPath出场
gpathResult=xparser.parse(targetFile)
//开始玩test.xml。现在我要访问id=4的book元素。
//下面这种搞法,gpathResult代表根元素response。通过e1.e2.e3这种
//格式就能访问到各级子元素....
defbook4=gpathResult.value.books.book[3]
//得到book4的author元素
defauthor=book4.author
//再来获取元素的属性和textvalue
assertauthor.text()=='Manuel De Cervantes'
获取属性更直观
author.@id=='4'或者author['@id']=='4'
属性一般是字符串,可通过toInteger转换成整数
author.@id.toInteger()==4
再看个例子。我在使用Gradle的时候有个需求,就是获取AndroidManifest.xml版本号(versionName)。有了GPath,一行代码搞定,请看:
defandroidManifest=newXmlSlurper().parse("AndroidManifest.xml")
println androidManifest['@android:versionName']
或者
println androidManifest.@'android:versionName'
最后
以上就是刻苦丝袜最近收集整理的关于Gradle----Groovy的全部内容,更多相关Gradle----Groovy内容请搜索靠谱客的其他文章。








发表评论 取消回复